Science 2018 | AlphaZero: 一种通过自我对弈精通国际象棋、日本将棋和围棋的通用强化学习算法
在2025年回望,AlphaGo与AlphaZero依旧是人工智能史上的经典。AlphaZero凭借自我对弈与强化学习,在棋类博弈中展现了通用算法的力量,预示着AI从专用走向通用的方向。
真正让这一方向全面爆发的,是大语言模型的崛起。从GPT到Gemini,再到Grok,它们以统一的框架实现跨领域、跨模态的能力,奠定了类通用智能的基础。而AlphaFold则在科学前沿完成突破,用AI破解了蛋白质结构预测这一世纪难题,推动生命科学进入新阶段。
这些跃迁共同描绘出人工智能的轨迹:从博弈到语言,再到科学,AI正不断改写经典,并加速迈向通用智能的未来。

获取详情及资源:
- 📄 论文: https://doi.org/10.1126/science.aar6404
- 💻 Playground: https://github.com/suragnair/alpha-zero-general.git
0 摘要
国际象棋是人工智能历史上研究时间最长的领域之一。最强的国际象棋程序通常依赖复杂的搜索技术、领域特定的改进以及经过专家多年打磨的人工评估函数。然而,AlphaGo Zero在围棋中仅通过自我对弈的强化学习便取得了超人水准的表现。本文提出的AlphaZero算法将这种方法进一步推广,在多个复杂博弈中展现出超人水平。AlphaZero从零开始,仅凭规则而无任何额外领域知识,便击败了国际象棋与将棋(日本象棋)的世界冠军程序,同时在围棋中也展现出卓越表现。
1 引言
计算机国际象棋的研究几乎与计算机科学本身同龄。巴贝奇、图灵、香农和冯·诺依曼早期便提出了硬件、算法和理论,用以分析和对弈。自此,国际象棋成为一代人工智能研究者的重要挑战任务,并最终催生出能够达到超人水平的高性能国际象棋程序。然而,这些系统往往经过深度领域化的优化,难以推广至其他游戏,而通用博弈系统至今仍相对薄弱。人工智能的长期目标之一,是能够从第一原理出发自我学习的程序。AlphaGo Zero便通过深度卷积神经网络来表征围棋知识,并仅依靠自我对弈的强化学习,取得了超人表现。
AlphaZero是AlphaGo Zero的通用版本,能够在不依赖特殊设定的前提下适配更广泛的游戏规则。研究者将AlphaZero应用于国际象棋、将棋以及围棋,并在三种游戏中均采用相同的算法与网络架构。结果表明,一种通用的强化学习算法可以在没有任何领域特定知识或数据的情况下“白纸化学习”,并在多个复杂博弈中实现超人表现。
人工智能的里程碑之一出现在1997年,当时“深蓝”战胜了人类世界国际象棋冠军。此后20年间,计算机国际象棋程序不断进步,早已稳定超越人类水平。这类程序通常通过手工设计的特征与精心调参的权重进行局面评估,并结合高性能的α-β搜索,大量使用启发式方法与领域适配扩展搜索树。以2016年TCEC第9赛季世界冠军Stockfish为例,其体系结构与深蓝等其他顶级程序极为相似。
从博弈树复杂度来看,将棋比国际象棋更难。它使用更大的棋盘,棋子种类更多,并且任何被俘获的棋子都可以转化为己方棋子并投放至棋盘任意位置。最强的将棋程序,如2017年CSA世界冠军Elmo,直到近年才击败人类冠军。这类程序与国际象棋程序相似,依旧依赖高度优化的α-β搜索与领域特定改进。
2 结果
AlphaZero则抛弃了传统博弈程序中依赖的人工知识与领域特定增强,转而使用深度神经网络、通用强化学习算法和通用树搜索算法。不同于手工设计的评估函数与走法排序启发式,AlphaZero采用一个神经网络
不同于依赖领域特定增强的α-β搜索,AlphaZero采用的是通用的蒙特卡罗树搜索(MCTS)算法。每次搜索由一系列模拟的自我对弈构成,这些对弈会从根节点
AlphaZero的神经网络参数
其中
AlphaZero算法与最初的AlphaGo Zero在多个方面有所不同。AlphaGo Zero估计并优化的是获胜概率,因为围棋只有胜负二元结果。而国际象棋与将棋可能出现平局,且普遍认为国际象棋的最优解应为平局。因此,AlphaZero优化的对象是期望结果。
此外,围棋规则在旋转与反射下保持不变,AlphaGo与AlphaGo Zero利用了这一点:其一,在训练数据中,每个局面都生成了八种对称形式;其二,在MCTS过程中,棋盘局面会在输入神经网络前随机旋转或反射,使蒙特卡罗评估在不同偏置下求平均。相比之下,为了适配更广泛的博弈规则,AlphaZero不再假设对称性。国际象棋和将棋的规则本身是不对称的(例如,兵只能前进,王车易位在王侧与后翼的规则不同)。因此,AlphaZero既不对训练数据做对称增强,也不在MCTS中对局面进行变换。
在AlphaGo Zero中,自我对弈棋局由历次迭代中的最佳棋手生成。每一轮训练结束后,新模型会与当时的最佳模型对弈,如果胜率超过55%,则替换为新的最佳棋手。相比之下,AlphaZero只维护一个神经网络并持续更新,无需等待完整的迭代结束,自我对弈始终使用该网络的最新参数。
AlphaGo Zero的超参数是通过贝叶斯优化确定的,而AlphaZero在国际象棋、将棋与围棋中完全复用了相同的超参数、算法设置和网络架构,并未针对特定游戏做调优,唯一的例外是探索噪声与学习率调度。研究者分别训练了独立的AlphaZero实例,每个实例从随机初始化参数开始,训练70万步(每批次包含4096个局面)。训练过程中,使用5000个第一代TPU生成自我对弈棋局,16个第二代TPU训练神经网络。训练时间约为国际象棋9小时、将棋12小时、围棋13天。
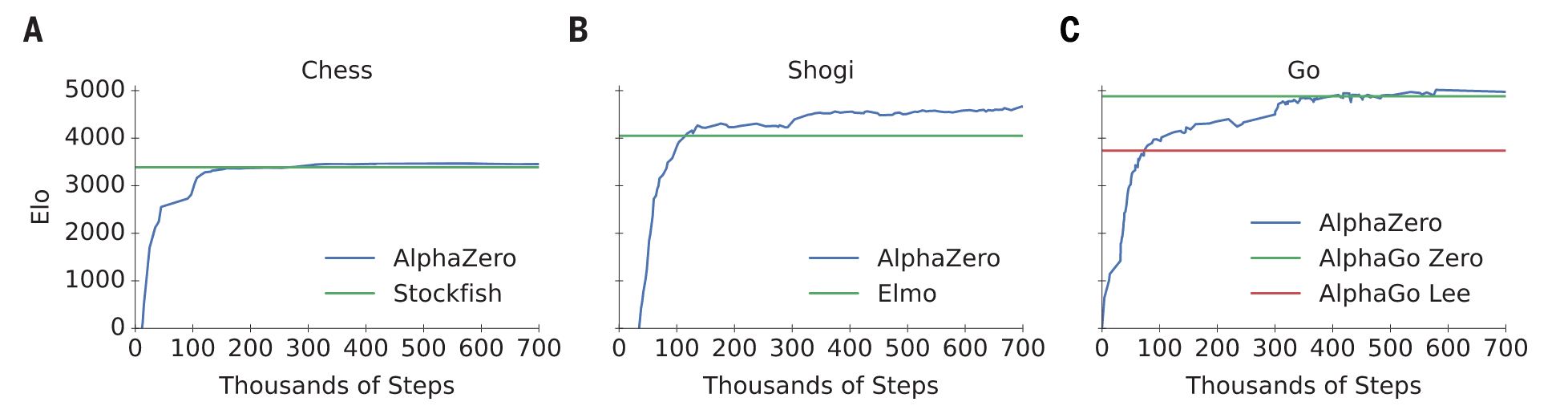
图1|AlphaZero训练70万步后的表现。Elo等级分通过不同棋手之间的对局计算,每位棋手在对局中每步限时1秒。(A) AlphaZero在国际象棋中的表现,与2016年TCEC世界冠军程序Stockfish比较。(B) AlphaZero在将棋中的表现,与2017年CSA世界冠军程序Elmo比较。(C) AlphaZero在围棋中的表现,与AlphaGo Lee和AlphaGo Zero(20层残差网络,训练3天)比较。
图1展示了AlphaZero在自我对弈强化学习中的表现(以Elo等级分衡量)。在国际象棋中,AlphaZero仅4小时(30万步)后便超越Stockfish;在将棋中,仅2小时(11万步)后便超越Elmo;在围棋中,30小时(7.4万步)后便超越AlphaGo Lee。这些结果在多次独立实验中均可复现,说明AlphaZero的训练算法性能稳定且可重复。
研究者随后评估了完全训练的AlphaZero实例,分别与国际象棋的Stockfish、将棋的Elmo以及旧版AlphaGo Zero对弈。每个程序均运行在其最佳硬件环境上:Stockfish与Elmo在44核CPU上运行(与TCEC锦标赛一致),AlphaZero与AlphaGo Zero运行在单机环境,配置为4个第一代TPU和44核CPU。国际象棋对局选择2016年TCEC(第9赛季)冠军Stockfish,将棋对局选择2017年CSA冠军版本Elmo,围棋对局则选择同样训练70万步的AlphaGo Zero。所有对局均采用每局3小时外加每步15秒的规则。
在围棋中,AlphaZero以61%的胜率战胜了AlphaGo Zero,这表明通用方法可以恢复甚至超越依赖棋盘对称性扩展数据的算法性能。在国际象棋中,AlphaZero对阵Stockfish的1000局比赛中取得155胜6负的压倒性战绩(图2)。为验证其稳健性,还进行了从常见人类开局出发的对局(图3),AlphaZero在所有开局中均取胜,表明它已掌握广泛的人类开局谱系。频率分布(图3)与时间线(图S2)显示,AlphaZero在自我博弈中独立发现并频繁使用了常见开局。即便在2016年TCEC锦标赛开局库下对局,AlphaZero依然轻松获胜(图S4)。此外,面对最新版Stockfish以及带有强大开局书的变体,AlphaZero仍然大比分获胜(图2)。
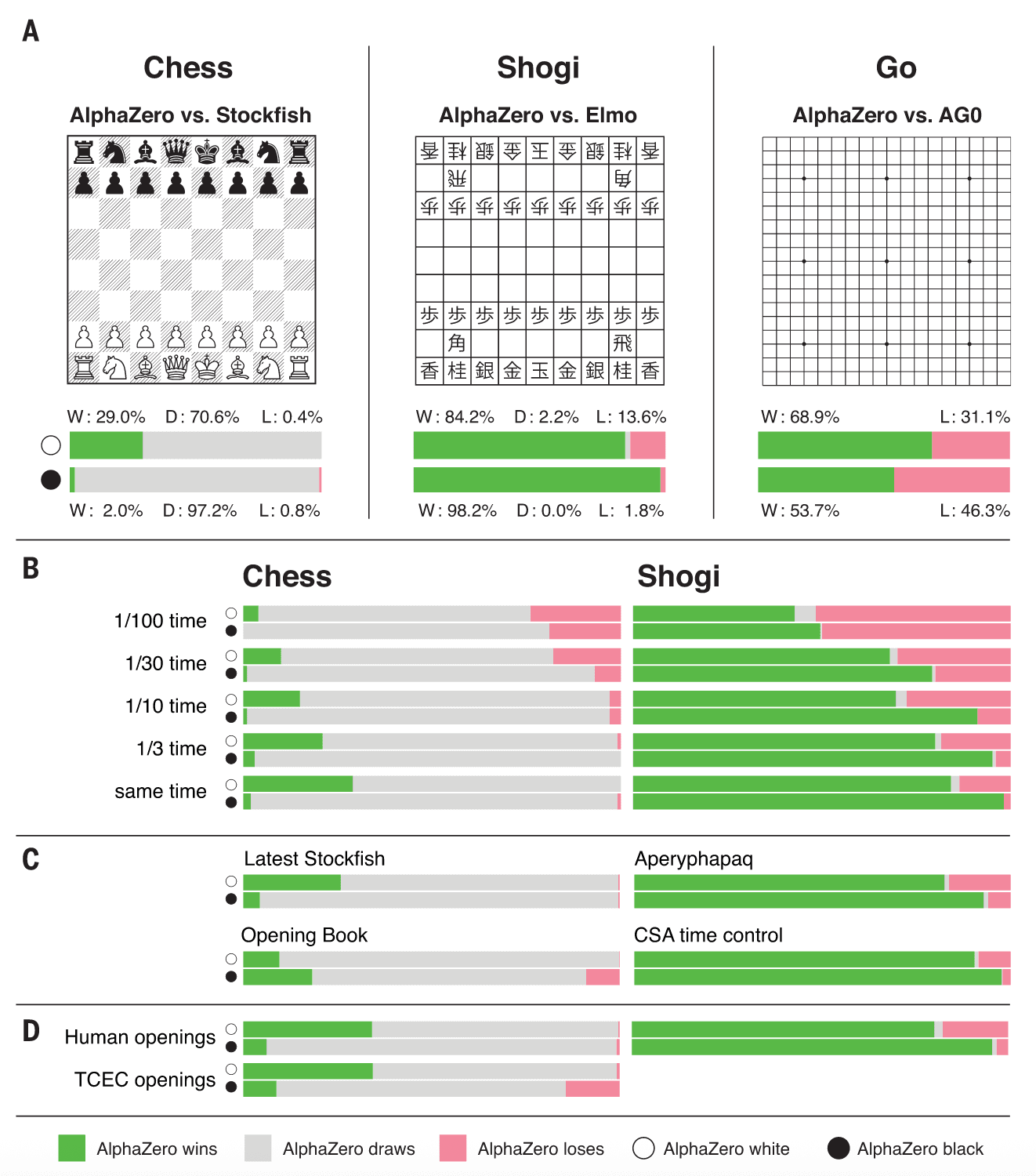
图2|与专业棋类程序的比较。(A) AlphaZero在国际象棋、将棋和围棋中的比赛结果,分别对阵Stockfish、Elmo以及训练3天的已发表版本AlphaGo Zero (AG0)。上方条带表示AlphaZero执白,下方条带表示AlphaZero执黑。每个条带均以AlphaZero的角度展示比赛结果:胜(W,绿色)、和(D,灰色)、负(L,红色)。(B) AlphaZero在不同思考时间下的可扩展性,与Stockfish和Elmo对比。Stockfish和Elmo始终使用完整思考时间(每局3小时外加每步15秒),AlphaZero的思考时间按图中所示比例缩减。(C) 在国际象棋中,AlphaZero额外对阵最新版的Stockfish (27),以及带有强大开局书的Stockfish (28)。在将棋中,AlphaZero额外对阵另一强力将棋程序Aperyqhapaq (29),采用完整时间控制;同时也在2017年CSA世界锦标赛的快棋时间控制下(每局10分钟外加每步10秒)对阵Elmo。(D) 国际象棋中从不同开局位置开始的对局平均结果,包括常见人类开局(见图3)以及2016年TCEC世界锦标赛开局(见图S4);将棋中从常见人类开局开始的对局平均结果(见图3)。CSA世界锦标赛的对局则从标准初始棋盘开始。比赛条件详见表S8和S9。
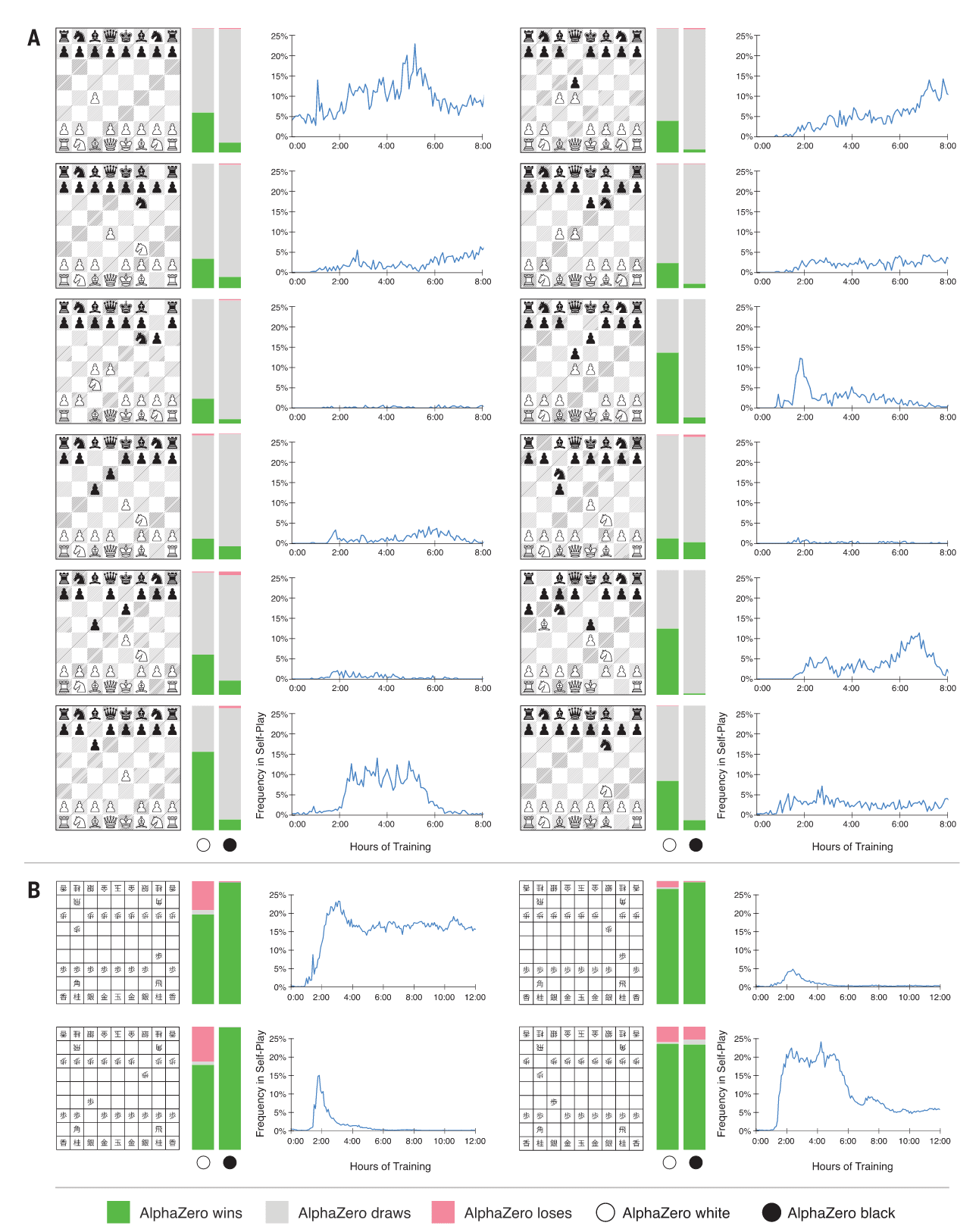
图3|从最常见人类开局开始的对局。(A) AlphaZero在国际象棋中对阵Stockfish;(B) AlphaZero在将棋中对阵Elmo。左侧条带表示AlphaZero执白并从指定开局开始,右侧条带表示AlphaZero执黑。每个条带均以AlphaZero的角度展示结果:胜(绿色)、和(灰色)、负(红色)。折线图展示了在自我博弈训练中,AlphaZero选择该开局的频率随训练时长(小时)的变化情况。
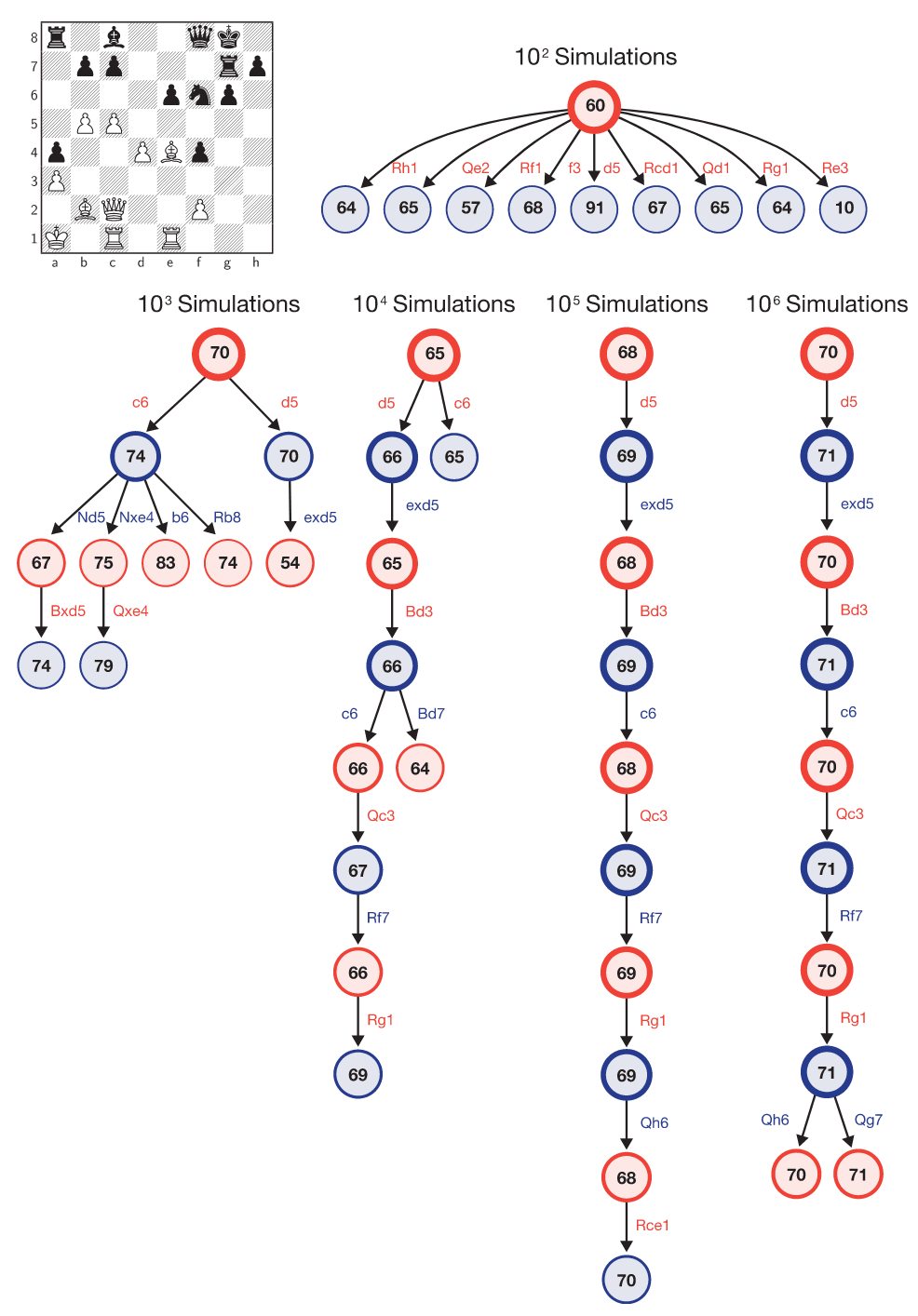
图4|AlphaZero的搜索过程。示例局面取自表S6第1局比赛,AlphaZero执白,Stockfish执黑,至29…Qf8之后。图中总结了AlphaZero的MCTS在第102次至第106次模拟后的内部状态,每次总结展示访问次数最多的10个局面。每个局面均标注了AlphaZero对其的价值估计(以白方视角,数值缩放至[0,100]范围)。各局面的访问次数相对于该搜索树根节点的比例由圆圈边框的粗细表示。AlphaZero在搜索过程中曾考虑过30.c6,但最终选择了30.d5。
表S6展示了AlphaZero在对阵Stockfish时的20局国际象棋棋谱。在多局比赛中,AlphaZero主动牺牲子力以换取长期的战略优势,这表明其局面评估更加灵活,并且能够根据具体语境进行判断,而不是像传统国际象棋程序那样依赖规则化的评估函数。
在将棋中,AlphaZero以压倒性优势击败了Elmo:执黑胜率高达98.2%,总体胜率为91.2%。研究者还在2017年CSA世界锦标赛的快棋规则下,以及面对另一款最先进的将棋程序时进行了测试,AlphaZero同样以大比分获胜(图2)。表S7展示了AlphaZero在对阵Elmo时的10局棋谱。频率分布(图3)与时间线(图S2)表明,AlphaZero常常选择人类棋手中最常见的两种开局之一,但对另一种常见开局却很少使用,甚至在第一步就走出了不同的变化。
在搜索效率上,AlphaZero在国际象棋和将棋中每秒仅搜索约6万个局面,而Stockfish可达6000万个,Elmo约2500万个(表S4)。AlphaZero能够弥补这一巨大差距的原因在于,其深度神经网络能更有选择性地聚焦于最具潜力的变例(图4给出了其对阵Stockfish时的例子),这种方式更接近香农最早提出的类人搜索思路。即便在思考时间仅为对手的1/10(约搜索
3 结论
长期以来,国际象棋一直被视为人工智能研究的巅峰任务。最先进的程序依赖强大的引擎,每秒搜索数百万局面,结合人工设计的领域知识与复杂的领域特定改进。而AlphaZero作为一种最初为围棋设计的通用强化学习与搜索算法,却在仅用数小时、搜索局面仅为传统引擎约
这些成果使人工智能距离实现长期目标更近一步:即构建出一个能够自学并精通任意游戏的通用博弈系统。