Nature | FlowER: 电子流匹配用于生成式反应机制预测
在化学反应预测中,质量与电子守恒是基本且关键的物理约束,但多数数据驱动模型常忽略这一原则,导致生成结果缺乏机制合理性。近日发表于 Nature 的研究**《Electron Flow Matching for Generative Reaction Mechanism Prediction》提出全新框架 FlowER,通过 flow matching 与 键-电子(BE)矩阵表示,将反应建模为电子重分布过程**,实现严格的守恒性与高度可解释性。FlowER 在结构有效性、守恒性、top-k 准确率等方面均优于或媲美主流模型(如 G2S、MT),并展现出极高的数据效率,可在仅 32 个样本下快速适配未见反应类型。同时,其预测结果与教科书规律一致,可无缝连接 DFT 等后续计算流程。作为一种结合生成建模与物理化学机制的框架,FlowER 不仅提升了预测准确性,更增强了模型对反应过程的理解能力,为机制可解释的反应建模奠定了新基础。
获取详情及资源:

0 | 摘要
对化学反应性的理解核心在于质量守恒原则,它不仅对确保物理一致性和反应方程平衡至关重要,也为反应设计提供了基本指导。然而,用于反应产物预测等任务的数据驱动计算模型却很少遵循这一最基本的约束。本文将反应预测问题重新表述为一个电子重分布问题,并引入现代深度生成框架中的流匹配(flow matching)方法,借助键-电子(bond-electron, BE)矩阵表示显式地实现了质量和电子的守恒。所提出的模型 FlowER 克服了以往方法中固有的限制,通过强制执行质量守恒,解决了虚假预测的失败模式,能够还原未知底物骨架的反应机制序列,并且在极低数据量下对域外反应类别实现良好泛化。FlowER 同时也支持对反应热力学或动力学可行性的后续评估,并在反应预测任务中展现出一定的化学直觉。这一具有高度可解释性的框架,标志着数据驱动反应预测领域在连接预测准确性与机制理解之间迈出了重要一步。
1 | 引言
质量守恒是化学中的基本原理,是对化学反应进行准确建模的重要约束条件。该原则由拉瓦锡(Antoine Lavoisier)在18 世纪提出,其核心观点是:反应物的总质量等于产物的总质量,为化学计量和平衡化学方程式奠定了基础。尽管这一原理既简单又至关重要,但许多基于化学反应数据训练的机器学习模型并未内在地强制遵守质量守恒原则。
反应结果预测已成为监督式机器学习中的一个热门任务。常见方法包括:预测分子图上的编辑操作,或在 SMILES 字符串的语言中直接将反应物“翻译”为产物。尽管化学家通常通过箭头推动(arrow-pushing)机制图示来构思、可视化和传达化学反应的理解,但大多数数据驱动模型却绕过了这一形式,采用端到端的方式或伪机制流程来预测主要产物。这些“黑箱”模型不仅难以解释为何预测出某个产物,还可能在外推或分布外情境中表现不稳定。
目前,基于单个机制步骤训练的预测模型仍属少数。Baldi 团队的开创性工作开发了多种方法,能对电子供体和受体对进行排序,其训练数据多来自教科书中的反应。我们自己此前的研究也尝试将端到端模型改编并重新训练于机制反应数据上。然而,深度学习模型容易产生“原子或电子幻想”(hallucination)现象,近乎“炼金术”般的错误;除了 Baldi 团队的工作外,大多数方法并不遵循基本的物理定律,这一点暴露出现有反应预测方法中的关键缺陷。
生成建模作为学习复杂数据分布的强大框架,有望缓解上述问题。在各类生成方法中,**基于打分的模型(score-based)以及去噪扩散概率模型(denoising diffusion probabilistic models)**表现尤为突出。去噪模型通过从加噪训练数据中逐步去除噪声,将高斯噪声等易采样分布逐渐转化为感兴趣的复杂分布。这两类方法已在多个分子建模场景中获得成功,包括 从头蛋白设计、小分子生成、逆合成分析、过渡态预测 等。
Flow matching 作为扩散方法的广义推广,不再局限于从纯噪声开始,而是学习将任意先验分布转化为目标分布的过程。相比去噪方法,flow matching 通常推理速度更快,并在经验上能保持或提升样本质量。
本文提出的 FlowER(Flow Matching for Electron Redistribution)即是一种基于 flow matching 的电子重分布深度生成模型。该模型将化学反应建模为电子重新分布的生成过程,这一视角在概念上与传统的箭头推动机制相一致,从而具有良好的解释性。flow matching 的生成范式还能够刻画化学反应中存在的多种可能路径和分支机制网络,体现其概率性本质。
为保证质量守恒,FlowER 通过 BE(bond-electron)矩阵框架 显式追踪电子的流动,该方法最早由 Ugi 等人提出。FlowER 的训练目标是从反应物(先验分布)出发,预测电子如何重分布到产物(目标分布)。该模型具有广泛的应用潜力,适用于 药物化学、材料发现、燃烧反应、大气化学及电化学体系 中的反应预测任务。
2 | 结果
2.1 | FlowER 模型中的电子重分布建模
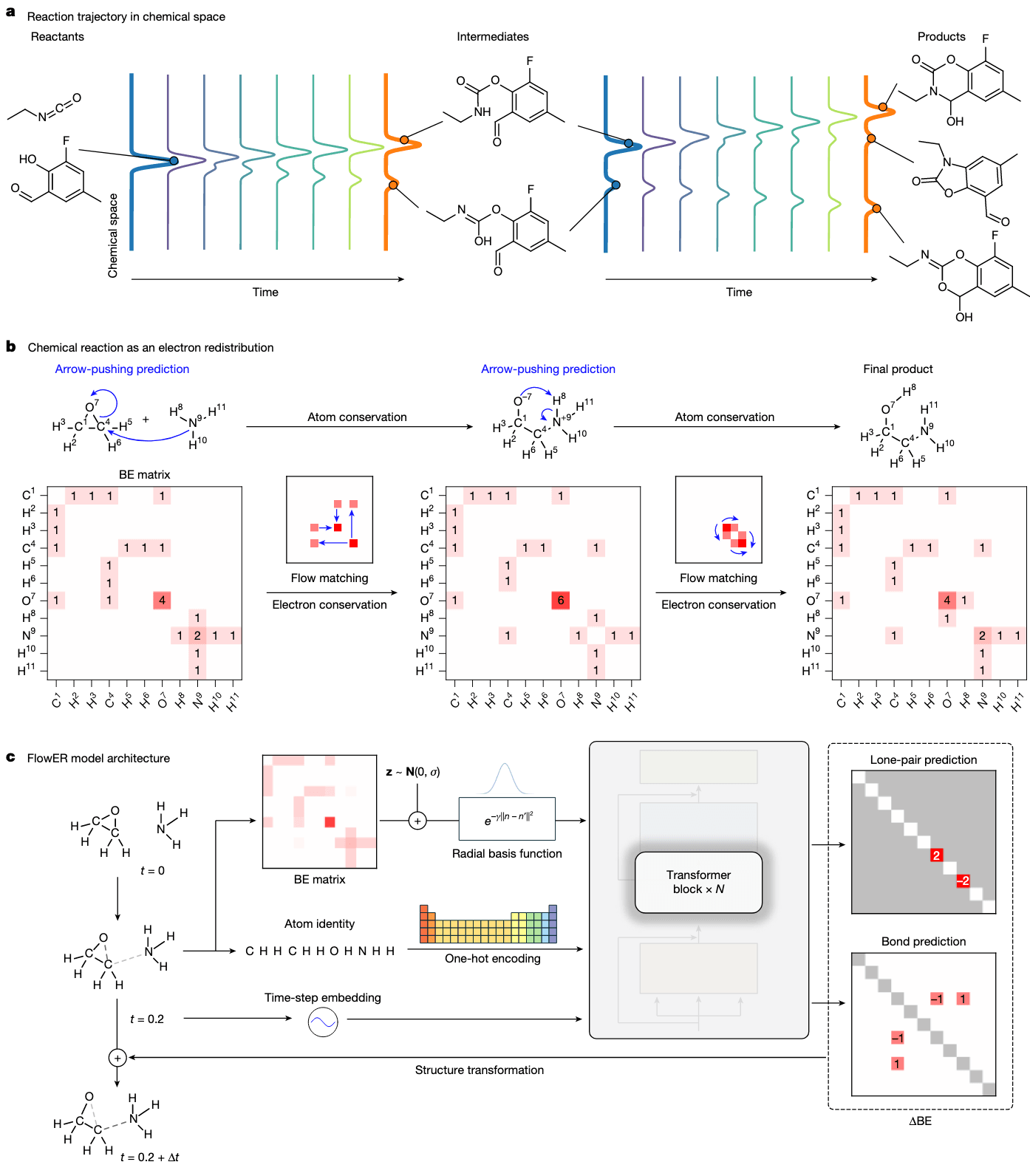
FlowER 将电子的移动建模为一个连续过程。反应体系的状态由固定的一组原子以及 BE(bond-electron)矩阵 所定义,后者能够自然地表达共价键以及孤电子对。在该框架中,每一个基本反应步骤都对应 BE 矩阵的一个变化过程(见图 1b)。为了保证模型的可解释性,并使关键中间体能够如有机化学家绘图般被还原,所使用的数据集中仅包含离散且具有标准键级的化学定义明确的反应步骤(见补充信息第2节)。
整个电子在反应过程中的流动,被形式化为一个电子局域概率分布的变换过程,即从反应物状态向产物状态的分布演化(见扩展数据图 1a)。这种设计本质上避免了反应预测中原子或电子的凭空创造或消失。
为了预测反应物与产物之间的电子重分布,FlowER 学习了一个定义在 BE 矩阵插值反应状态上的条件向量场。这些插值状态被赋予伪时间标签,并通过图结构的 Transformer 架构进行处理(见图 1c)。模型会递归地预测每一步,逐步构建完整反应机制,并保证每个中间状态都严格遵守质量和电子守恒原则(见扩展数据图 1b)。模型架构与推理的具体细节见 Methods 部分。
在训练阶段,作者从包含约 110 万个实验反应的 USPTO-full 专利数据集 中,推断出部分反应的机制路径。针对 252 个定义清晰的反应类别,共构建了 1,220 个专家策划的反应模板,总计获得 约 140 万个基本反应步骤。在条件 flow matching 的标准训练程序下,采样反应物与产物之间 BE 矩阵的插值轨迹作为模型输入,更多训练细节见 Methods。
为了评估 FlowER 的性能,作者将其与典型的序列生成模型 Molecular Transformer (MT) 和结构输入相似但以 SMILES 字符串作为输出的 Graph2SMILES (G2S) 模型进行比较,其中 G2S 还包括基于 Kekulé 表示并显式显示氢原子的变体(G2S+H)。
2.2 | 电子重分布确保质量守恒
FlowER 预测机制的核心是 ΔBE 矩阵,它描述电子配置的变化,其元素总和为零,从而强制实现电子守恒。ΔBE 的表示方式与化学家常用的箭头推动机制高度一致,使得模型预测结果直观易懂,并便于化学机制解释。
为了更准确捕捉电子在化学键和反应性中的微妙作用,模型进一步区分了孤电子对与 BE 分布。这一设计确保了预测结果既符合物理规律,又具备高度可解释性,构建出一个可用于机制理解的稳健框架。
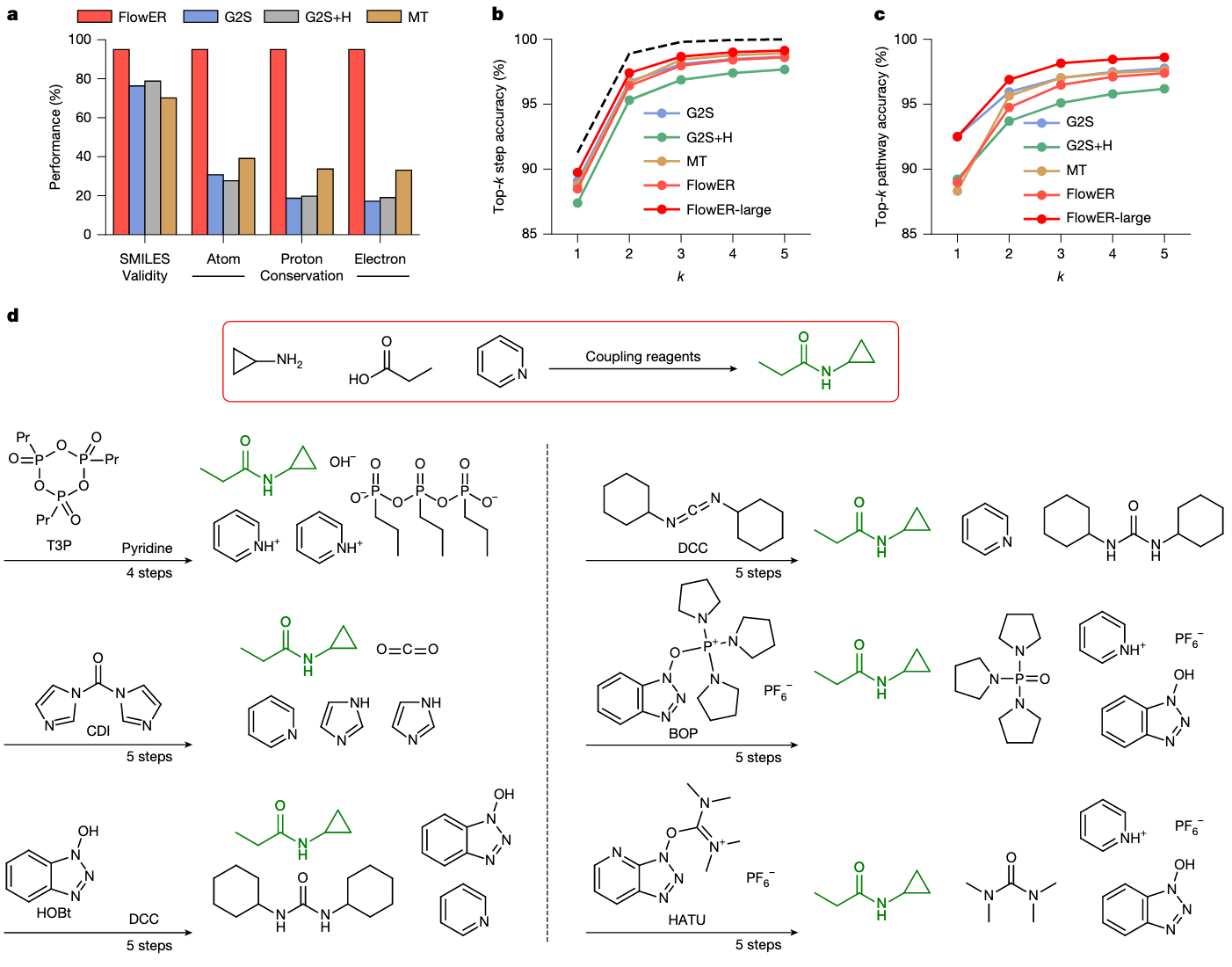
为了验证 FlowER 对质量守恒原则的遵守能力,作者在单一反应步骤层面评估模型预测的中间体与产物。结果表明,约 95% 的测试反应能生成有效的中间体或产物 SMILES 表达式。值得注意的是,FlowER 并非硬性执行价态规则,而是通过学习获得,因此在结构上仍可能出现如“四键氧”等罕见异常(详见补充信息第 5 节)。
相比之下,直接生成 SMILES 字符串的模型无效表达式比例更高(G2S 仅有 76.3% 有效,MT 为 70.2%),而使用 Kekulé 表示和显式氢原子的 G2S+H 模型在有效率上略有提升(78.8%),可能是因为更长的序列为学习语法提供了更多线索。尽管使用 DeepSMILES 或 SELFIES 可避免语法错误,但大多数“幻想性”错误仍能生成语法合法的 SMILES 字符串,因而不能从根本上解决质量与电子守恒问题。
尽管 FlowER 在生成过程中没有强制每个原子的价态,但其 BE 矩阵表示方式确保了重原子、质子和电子守恒。相比之下,尽管 G2S、G2S+H 和 MT 都在平衡机制数据集上训练(已体现守恒规律),但它们在大多数预测中仍然违反质量守恒原则:
- 仅有 30.7%(G2S)、27.7%(G2S+H)和 39.1%(MT) 的预测保持重原子守恒;
- 当同时考虑质子与电子守恒时,累计守恒率进一步下降至 17.2%、19.0% 和 33.0%。
这一结果凸显了序列生成模型在物理一致性方面的根本性缺陷,即使其训练集已充分体现质量守恒,模型结构本身仍难以避免“幻想性”错误,削弱了其在化学应用中的可靠性。
最终,FlowER 通过其架构设计内在地满足守恒律,提供了更高的可靠性、更强的用户信任,并能直接用于对质量与电子精度要求极高的后续任务,如 自动量子化学计算(详见后文)。
2.3 | 守恒性并不以牺牲准确性为代价
尽管遵循守恒原则有助于预测合理的反应机制,但这一点并不能完全保证预测结果的正确性。因此,作者以 top-k 步骤准确率 和 top-k 路径准确率 为指标,从多个化学路径上评估模型对中间体和最终产物的预测性能(具体定义见 Methods)。
需要再次强调,条件 flow matching 本质上是一个分布式生成方法,即对相同反应物进行多次采样可得到多个可能结果,再按出现频率排序(采样细节见 Methods)。在这一框架下,FlowER 在 top-k 步骤准确率和 top-k 路径准确率上均表现出与 G2S+H 和 MT 相当的定量预测能力(见图 2b 和 2c),且三者在步骤准确率方面接近上限,仅在 top-1 路径准确率上略低于 G2S。
值得注意的是,图中展示的 FlowER 模型仅包含 700 万参数,而 G2S 和 MT 分别拥有 1800 万 和 1200 万参数。当模型规模扩大至 1600 万参数(FlowER-large) 后,在所有评估指标上均能匹配或超越现有模型,尤其在
此外,这一基于守恒的结构归纳偏置(inductive bias)还提高了模型在训练数据极度稀缺情况下的鲁棒性(见扩展数据图 5)。当训练集仅包含 500 个均匀采样的基本反应步骤时,FlowER 仍能实现约 35% 的 top-1 和 40% 的 top-10 步骤准确率,而 G2S 的表现则几乎为零。正如后文“FlowER 在低资源下的微调能力”所展示,这种数据效率优势也扩展到了对未知反应类型的微调场景中,仅需极少额外训练即可取得良好效果。
2.4 | FlowER 能反映反应条件的影响
除定量指标外,FlowER 还在机制推理过程中捕捉到了反应条件的影响,展现出良好的化学直觉。反应条件在控制反应结果、选择性及产率方面具有关键作用。尽管 FlowER 并未显式考虑温度、浓度或溶剂极性等连续变量,但模型将催化剂、溶剂和其他反应组分视作 BE 矩阵中的参与者,可在机制预测中体现它们的作用。
如图 2d 所示,在预测羧酸与胺在碱性吡啶和缩合试剂存在下的缩合反应时,FlowER 给出了两种不同的反应机制(4 步或 5 步),均生成相同的酰胺产物,但副产物和中间体不同。这一预测结果显示:FlowER 能根据试剂组合细微变化区分反应路径,同时保持主要产物的一致性。
此外,当训练集中包含相关样本时,FlowER 也能预测 自由基反应(见扩展数据图 2),表现出对单电子机制的兼容性。
2.5 | FlowER 捕捉教科书中的反应性规律
反应性趋势和启发式规则是化学教学与理解的重要工具,通常源于基本原理并通过实验验证。它们帮助化学家自下而上地推理反应结果。而机器学习模型则通过自上而下的数据驱动方式进行学习。因此,一个自然的问题是:模型是否能自动学出这些经典规则? 是否能体现化学家在启发式规则中编码的化学逻辑?
为此,作者对 FlowER 的基本反应步骤预测进行了后验分析,以检验其是否符合某一教科书级的经典规律。例如,酸碱化学在多数反应中都具有显著影响,而能否发生质子转移通常由反应物的
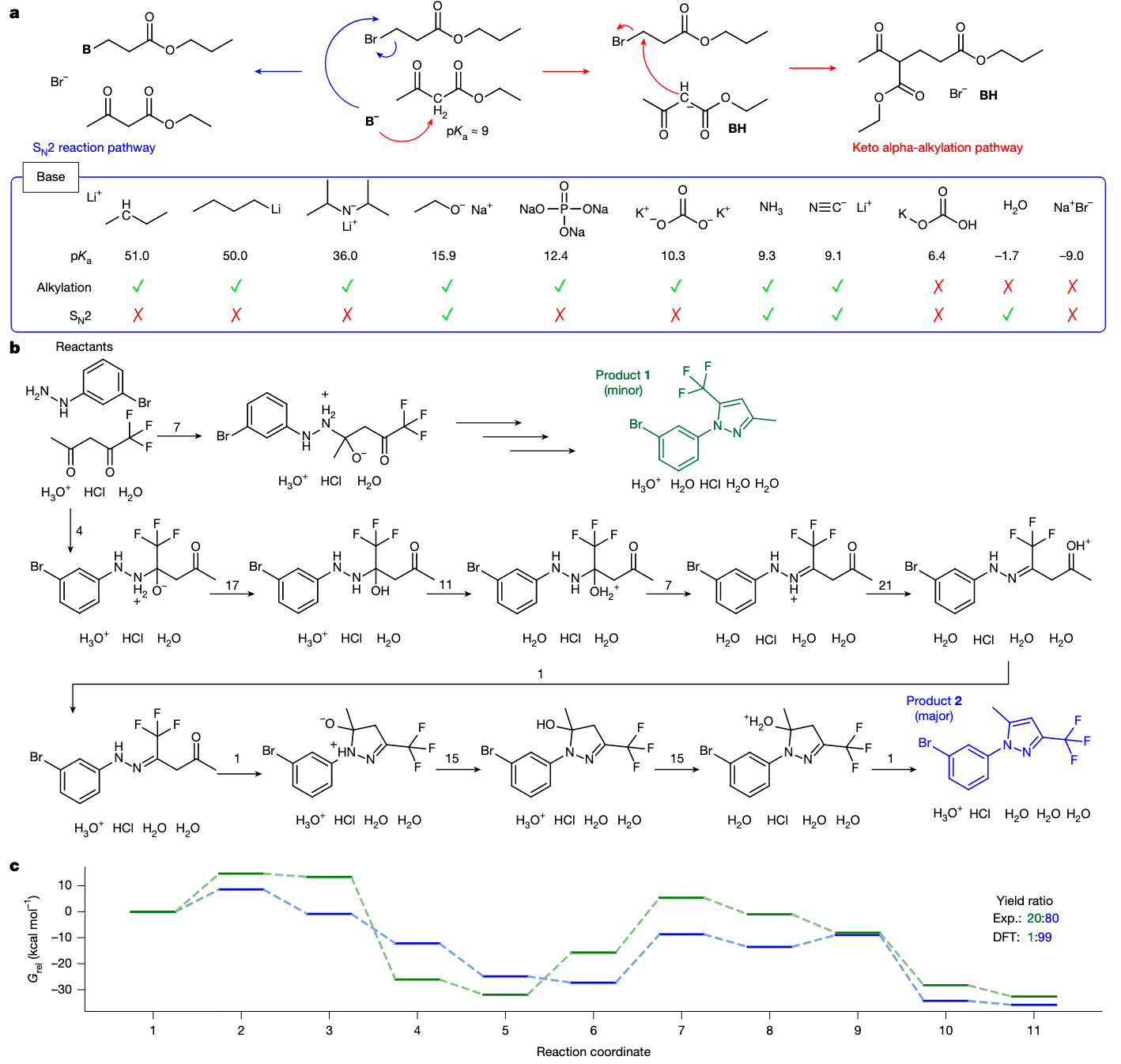
由于质量守恒要求对质子的来源与去向进行完整记录,该数据集在机制整理时就已充分体现酸碱反应,为模型建立起有关碱性强弱的统计认知(见图 3a)。例如:β-酮酸酯的 α-烷基化反应需要碱先去质子化,其 α-氢在数据中被统一设定为
作者测试了 FlowER 在 16 种碱性条件下的行为(见扩展数据表 1)。结果显示,在图 3a 展示的 11 种碱中,其共轭酸的
关于离子型与中性碱表示对模型预测的影响,详见补充信息第 6 节。
2.6 | FlowER 可泛化至未见反应类型
本研究的动机之一在于构建能够在机制步骤层面进行推理的预测模型,从而具备泛化能力,并能解释那些不属于标准训练反应类型的产物。为测试这一能力,作者选取了 Pistachio 数据集中 22,000 条 2024 年新专利反应,这些反应未被归入任何具体反应类别,可能包含多个已知反应串联或全新的机制路径。
在这些“未识别反应”上进行 窄束搜索(beam search, width=2, depth=9),成功复原了 351 个产物。相关预测路径示例详见补充信息第 9 节,其中包括 FlowER 必须对 **输入组分同时包含多个步骤中添加物(如猝灭试剂)**的复杂反应条件进行机制解释的情形。
图 3b 展示了一个典型示例,该反应在两份专利中有实验依据,被标记为“未知反应类别”,因其记录有两个产物。尽管两者均对应 吡唑的经典合成路线,FlowER 在训练中并未见过 Knorr 吡唑合成。由于原始数据中缺失试剂信息,作者根据专利描述的酸性水环境,补充了盐酸、水和水合氧鎓离子,并将束搜索扩展至 width=5, depth=10(见扩展数据图 4)。
这种能力在实验结果偏离预期时尤显重要。通过分析预测的逐步反应路径,化学家可以定位偏差出现的步骤,提出解释并优化实验条件。同时,质量守恒的内在保证使 FlowER 的预测路径可无缝对接量子化学评估(如 DFT 计算)。
图 3c 展示了中间体的自由能分析结果。若假设 Bell–Evans–Polanyi 原理成立,则产物 2(蓝色)在热力学与动力学上都更优,符合实验中产物 2 与 1 的 8:2 比例。这一基于守恒原则的机制路径分析表明:FlowER 有望被整合进物理建模驱动的机制探索流程中。
特别地,那些将机制探索拆解为“步骤枚举 + 步骤评估”的流程,可用 FlowER 替代原始的枚举机制,为机制假设生成带来效率提升。
相比之下,G2S 模型在相同输入条件下的束搜索表现明显不佳(见扩展数据图 3b),未能预测出任何主要产物。即使是训练用于产物预测的 G2S 端到端模型,虽然 top-1 能命中主产物,却无法生成次要区域异构体或任何副产物(见扩展数据图 3c),而且其生成序列不满足质量守恒,无法支持热力学分析。例如其 top-2 路径在 E1 消除后就终止,未涵盖所有原子。此类问题在模型预测与训练数据分布差异较大时更为常见。
2.7 | FlowER 支持高效微调
预测反应机制的一个重要前提在于:未见反应类型中可能包含已知机制步骤。换言之,反应类型的外推可能是机制层面的内插。若反应包含模型未曾学习的步骤,则需通过微调来适配。
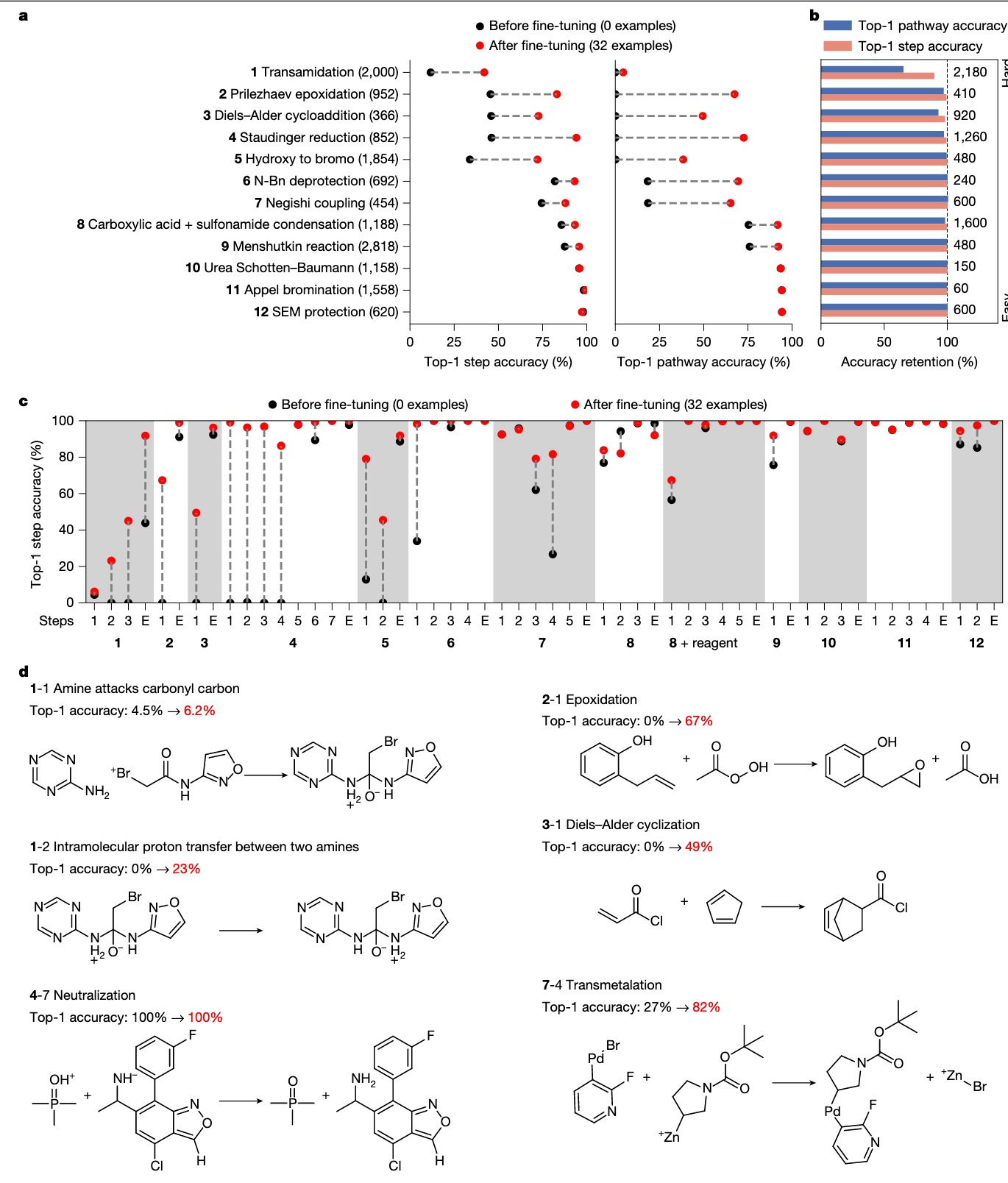
作者在 12 种 分布外反应类型上评估 FlowER(图 4a)。这些反应类型的性能差异显著:部分 top-1 路径准确率超过 90%,而有些低至 0%。准确率较高的通常对应其机制步骤与训练集中已有反应较为相似的情形。
传统的反应预测模型微调往往依赖 大量数据(如:25,000 条糖类反应、9,959 条 Heck 反应或 2,254 条 Baeyer–Villiger 反应)。而本文中,FlowER 在每种反应类型仅使用 32 条样本进行微调,其 top-1 路径准确率在 12 个反应类型中有 9 个超过 65%。这表明 FlowER 能利用少量新例子,类比已有机制知识,泛化到新 scaffold。
且值得注意的是:微调并未导致“灾难性遗忘”,即模型在原始测试集上的性能仍保持稳定(见图 4b),验证了模型在扩展新反应类型的同时,仍保留原有知识。
图 4c 展示了每个反应类型下的各机制步骤的 top-1 准确率。例如类型 5(Diels–Alder 反应)仅包含两个步骤:一是协同环加成,二是无变化终止反应。在微调前准确率较高的步骤,通常在训练集中由其他反应类型涵盖,如图 4d 中步骤 4-7 为 Staudinger 还原中的中和步骤,在微调前即达到了 100% 准确率。
但某些步骤则因缺乏训练数据支持而难以预测,如 Negishi 偶联反应中的锌-钯换位步骤(7-4),该反应中唯一含锌例子来自补充数据库 RMechDB 与 PMechDB,仅在微调前实现 27% 准确率。类似地,尽管模型熟悉二烯与亲二烯体,但在微调前对环加成(3-1)仍完全陌生。
12 种反应类型中唯一在微调后准确率仍低于 10% 的是 酰胺转化反应(transamidation)。这一三步机制包含:(1-1) 胺加成至酰胺羰基,(1-2) 胺间的分子内质子转移,(1-3) 原胺离去。模型难以掌握此路径的原因包括:
- 训练中频繁遇到酰胺与胺共存但无反应的情况;
- 模型虽学会胺阳离子转移质子,但大多转移至羟基,非其他胺;
- 四级碳结构中胺很少作为离去基团;
- 该类分子内质子转移在热力学上通常不可行(详见补充信息第11节)。
尽管如此,对于其余反应类型,FlowER 均能通过仅 32 条新样本,成功泛化至上百或上千个测试样本。
3 | 总结
本研究提出了一种严格遵守质量与电子守恒的新型反应预测任务建模方式。通过重访 Ugi 等人提出的 BE 矩阵形式,结合现代生成建模中的 flow matching 方法,作者将反应结果预测重新定义为一个 电子重分布生成过程。
FlowER 以机制步骤为核心建模单位,克服了序列生成模型中常见的幻想错误与守恒违背问题。实验表明,FlowER 在机制路径复现上可与现有模型相匹敌甚至超越,且具有显著的数据效率,能够通过极少量微调样本泛化至新反应类型。
其物理一致性设计使其能够无缝对接量子化学分析,可用于热力学与动力学可行性评估。更重要的是,FlowER 与教科书级化学知识对齐,在化学直觉上展现出优秀表现。
随着机制路径数据集的扩展,FlowER 的预测范围将进一步拓展。由于使用了专家模板而非端到端生成机制路径,模型预测所涉及的反应物、试剂与产物均来自已报道实验,确保了预测的现实可行性。当然,模板本身仍需持续优化,相关更新详见补充信息第11节,未来改进方向见第3.7节。
通过加强机器学习与机制化学之间的联系,FlowER 有望推动反应建模、机制验证与新反应发现等任务的发展,并在数据驱动化学设计中扮演关键角色。