Nat. Mach. Intell. 2025 | TopoDiff: 基于全局几何感知潜在编码的扩散式蛋白质主链生成改进方法
TopoDiff 是一种基于全局几何感知潜在编码的扩散式蛋白质主链生成新方法,旨在突破现有 de novo 蛋白质设计中对特定拓扑结构生成的限制。该框架在无监督条件下,将蛋白质的全局几何信息映射到固定维度、连续的潜在空间,并通过条件扩散模型实现高效可控生成。与传统依赖残基级条件或长度相关潜在扩散的方法不同,TopoDiff 的设计不仅提升了天然折叠类型的覆盖率,尤其是在 mainly β 类蛋白生成上表现突出,还支持多种灵活的潜在空间操作,如基于属性的采样、潜在插值与 motif 骨架等。研究在 PDB 与 CATH 数据集上验证了其在多样性、新颖性与设计性等指标上的竞争力,并通过湿实验成功获得多种热稳定、结构新颖的 β 蛋白,其中部分结构经 X 射线晶体学确认与预测高度一致,显示了该方法在探索蛋白质折叠空间与推动结构生物设计方面的潜力。

获取详情及资源:
下面是该段内容的中文翻译与整理:
0 摘要
蛋白质的整体结构特征(如形状、折叠方式与拓扑结构)对其功能具有重要影响。尽管近年来基于扩散模型的生成方法在 de novo 蛋白质设计方面取得了显著突破,尤其在生成多样且逼真的结构上表现突出,但在缺乏残基级拓扑细节控制的情况下,实现特定几何形态的蛋白设计依然充满挑战。为了能够在生成结构中自上而下地规定二级结构单元的整体几何布局,该研究提出 TopoDiff ——一种无监督框架,可学习并利用全局几何感知的潜在表示,从而支持无条件与可控的扩散式蛋白质生成。
TopoDiff 基于 Protein Data Bank 与 CATH 数据集训练,结构编码器将蛋白质的全局几何嵌入到一个 32 维潜在空间中,潜在采样器生成的潜码作为信息丰富的条件输入扩散式主链解码器。在与现有基线模型的对比中,TopoDiff 在设计性、多样性和新颖性等既有指标上表现相当,同时在 CATH 数据集的天然蛋白折叠类型覆盖率上显著提升。更重要的是,潜在条件控制使得在全局几何层面对生成结构进行多样化操控成为可能,研究由此生成并验证了多个以 β 蛋白为主的新型折叠结构,并进行了全面的实验验证。
1 引言
De novo 蛋白质设计是一个充满吸引力且不断扩展的研究领域,具有探索未知折叠空间的潜力,为定制蛋白质在生物医药、催化性能提升以及新型生物电路等方面的应用提供了无限机会。然而,由于蛋白质数据高度结构化,以及几何约束条件极为严格,这一任务长期以来被认为具有高度挑战性。
近年来,扩散模型的引入显著推动了该领域的发展,凭借生成新颖、多样且物理合理结构的能力,改变了传统方法的局限。早期工作多依赖一维或二维的蛋白质表示,而后续研究借鉴了蛋白质结构预测的成功经验,构建等变网络以在笛卡尔空间直接学习物理先验。尽管取得了显著进展,但仍存在未解决的问题。例如,有证据显示,一些模型即便在 PDB 或 CATH 等无偏数据集上训练,仍难以生成某些特定折叠类型的蛋白质主链。在已实验验证的结构中,这些模型生成的结果主要集中在 mainly α 或 α+β 类别,而 mainly β 类的覆盖明显不足。
此外,当前常用的设计性(designability)、新颖性(novelty)和多样性(diversity)等指标并不能反映模型对天然蛋白质空间的覆盖程度,这使得问题难以被发现与解决。为提升特定折叠类型的覆盖率,已有方法尝试通过残基级一维/二维条件生成配合微调,来生成具变异环区的免疫球蛋白结构,或通过训练分类器对特定蛋白类进行引导。然而,这些策略高度依赖于目标类别的明确定义和足够的标注数据,而受限于蛋白质折叠注释的稀缺、不平衡及主观性,这类方法往往难以实现既无偏覆盖训练集折叠模式,又能扩展折叠空间的双重目标。
针对这一问题,该研究聚焦于一个重要且通用的无监督设定:如何在无需显式标注或先验知识的条件下,使扩散模型准确捕捉任意数据集的潜在分布。为此提出 TopoDiff 框架:首先,采用编码器-解码器结构并行训练扩散式结构生成模型与结构编码器,编码器学习固定维度、连续的潜在空间以捕获蛋白质的高层次全局几何,而生成模块在残基级别执行可控采样,并以预定义的潜在编码作为条件。随后,训练一个简单的潜在扩散模型,从该潜在分布中无偏采样全局几何,再引导原子级蛋白质结构生成。这一机制不仅显著提升了折叠类型的覆盖率,还为结构可控生成开辟了新维度。
研究中还提出了新的覆盖率指标,并在 TopoDiff 与多种先进模型之间进行了系统评测。实验结果表明,该方法在 mainly β 类蛋白生成上实现了显著改进,并通过生物学实验验证了其有效性,显示出在扩展蛋白质折叠空间与实现全局拓扑控制方面的强大潜力。
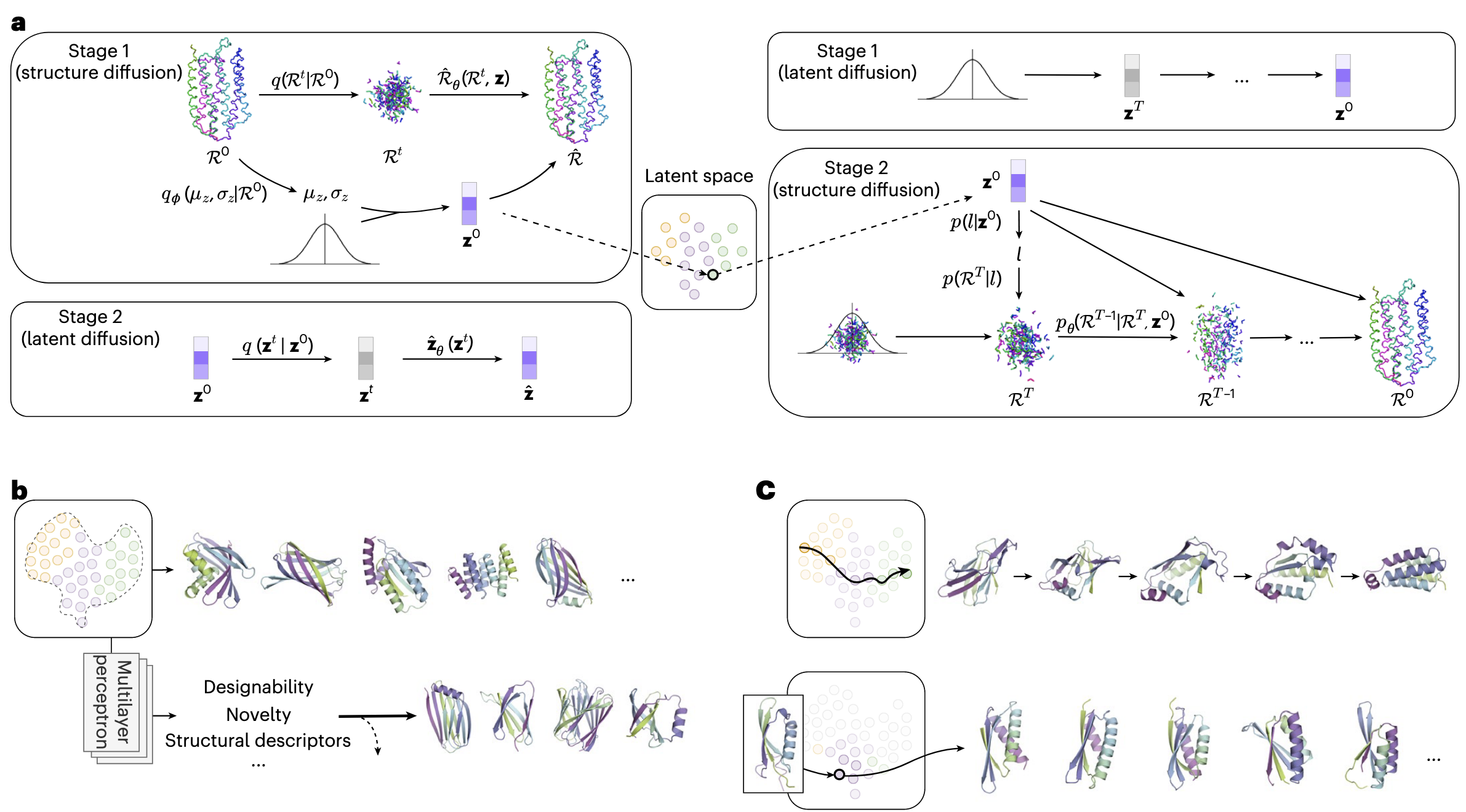
2 结果
2.1 TopoDiff 总览
TopoDiff 的整体框架如图 1 所示。蛋白质的全局结构特征(包括形状、折叠方式与拓扑结构)与其功能和动力学密切相关,同时也是理解分子机制的重要基础。然而,经典的扩散模型虽然生成能力强大,但其输入维度与数据维度紧密耦合,难以学习到对蛋白质全局几何进行有效压缩的低维潜在表示。因此,该方法的核心目标是建立并利用固定维度、低维度的潜在空间来编码蛋白质的全局结构特征,并在此基础上实现扩散式生成。
TopoDiff 的训练与采样过程分为两个阶段:在训练阶段的第一步(图 1a 左),采用**扩散–变分自编码器(VAE)**的混合结构,将扩散模型的生成能力与 VAE 压缩、连续潜在空间的表征能力相结合,实现统一训练。所得的结构编码器与条件扩散解码器共享同一个固定维度潜在空间,用蛋白质级的潜在编码
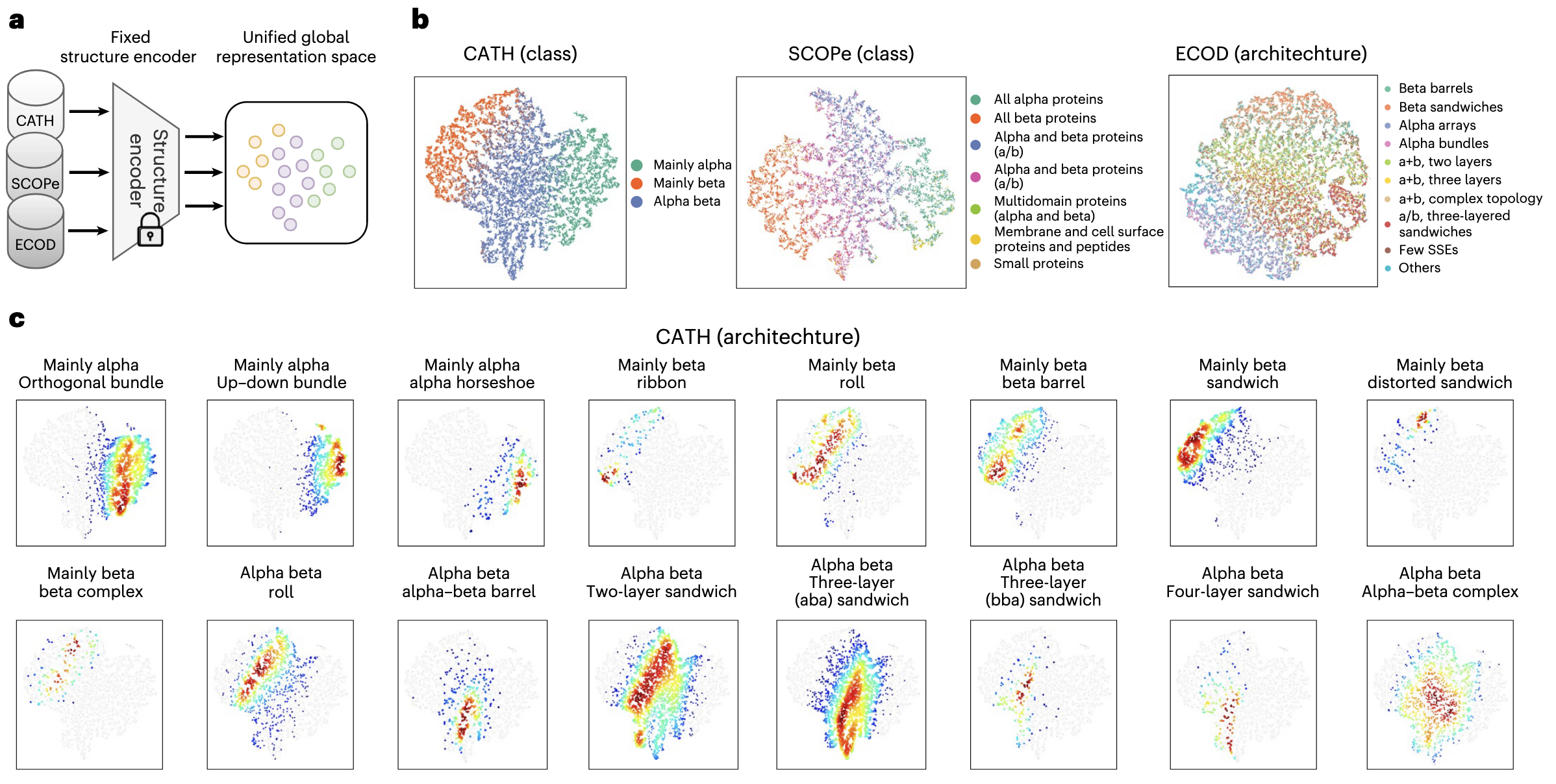
2.2 折叠空间的潜在表示学习
为理解 TopoDiff 所学习到的潜在空间特征,研究首先将 CATH-60 训练集中的所有结构编码到 32 维潜在空间,并使用 t-SNE 进行降维。结果(图 2b)显示,这些编码共同构成了一个紧凑且连续的流形。尤其值得注意的是,即使训练过程中未使用任何结构注释,潜在空间中的聚类依然与 CATH 分类体系中的人工标注高度一致,各类别在二维嵌入中清晰分离。此外,不同 CATH 架构类簇在空间中呈现明显可区分的分布特征(图 2c 与补充图 4)。蛋白质的多种内在属性,如二级结构组成、链长、回转半径等,也在该流形中表现出全局或局部的结构化分布模式(补充图 3)。这些结果表明,该模型能够在无监督的条件下,对训练数据进行高度可解释的自动划分。
接着,为评估编码方法在未见数据上的泛化能力,研究将同一基于 CATH 训练的编码器应用于另外两种分层结构分类数据集 SCOPe 和 ECOD(图 2a)。由于分类体系差异,这两个数据集在结构覆盖范围和结构域边界定义上存在显著差异。然而,编码器生成的潜在流形依然与两者的最高层级注释高度一致(图 2b 及补充图 5、6)。这一现象与先前分析一致,说明不同分类体系的层级组织差异,本质上可能只是同一结构空间中结构域划分和类别离散化方式的不同。
通过学习连续的无监督表示,TopoDiff 有效绕过了不同数据集之间的注释不一致问题。这种连续的全局潜在空间还为蛋白折叠空间提供了不同于既有分层、离散组织体系的替代视角。在补充结果 2 中,作者进一步探讨了其潜在优势,包括揭示折叠类别之间的连续关系,以及识别可能存在不一致或模糊的注释。
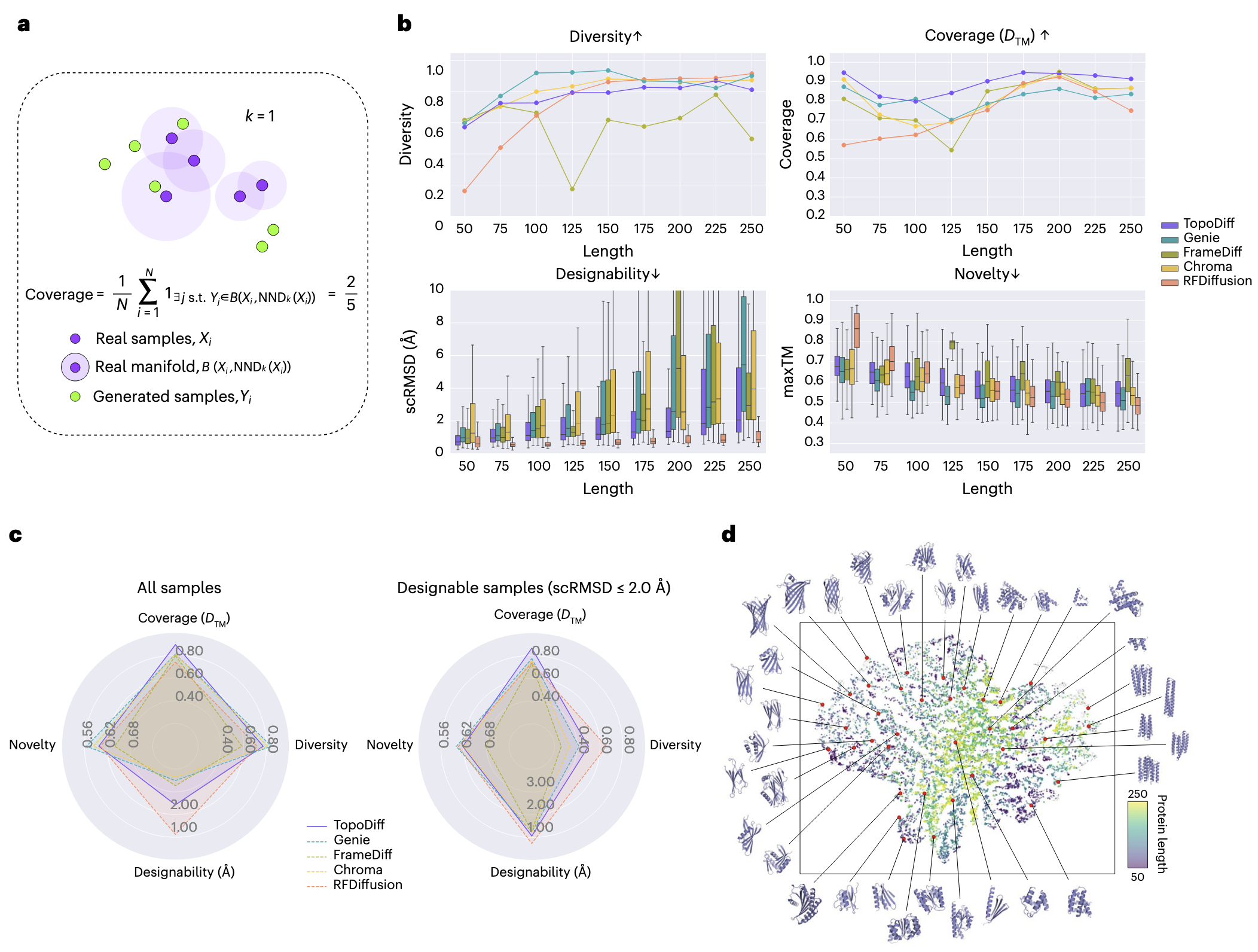
2.3 无条件采样的基准测试
TopoDiff 在无条件采样任务中与多种最新的扩散式生成模型进行了对比,包括 Genie、FrameDiff、Chroma 和 RFDiffusion。为保证评测的全面性与稳健性,每个模型在固定长度集合 {50, 75, 100, 125, 150, 175, 200, 225, 250} 上各随机生成 500 个样本,该长度区间均匀覆盖了训练数据的范围。这种设计可以揭示模型在不同链长下的性能变化趋势,而这种长度依赖性在常规测试中容易被忽略。
现有指标多用于度量单个样本的质量(如 designability 与 novelty)或样本集内部的多样性(diversity),但并不能反映模型生成样本对已知折叠空间的覆盖程度。然而,覆盖率是衡量模型是否能在数据分布中无偏采样的重要指标。如果忽视该指标,容易产生选择性偏差,使得模型倾向于牺牲多样性而集中生成高质量但分布受限的样本。事实上,过去十多年,de novo 蛋白质设计在结构类型上主要集中在 α 螺旋束和 α–β 三明治结构,扩散模型并未根本改变这一趋势。
为此,该研究引入了覆盖率(coverage)指标,用于量化生成样本覆盖天然蛋白折叠类型的比例(图 3a)。结果(图 3b 第一行)显示,TopoDiff 在多样性方面与其他模型相当,但在覆盖率上全面领先。特别是,TopoDiff 对 mainly β 类折叠的覆盖显著高于其他方法,而这是其他模型普遍表现不足的类别。
在 designability(以 scRMSD 衡量)方面,除 RFDiffusion(参数规模更大)外,TopoDiff 在全链长范围内均优于其他模型。在 novelty(以 maxTM 衡量)方面,TopoDiff 表现出稳定的中间值,体现了在已知折叠覆盖与生成新结构之间的平衡。进一步地,将各链长的指标取平均(图 3c)后,无论是全部样本,还是仅考虑高设计性样本(scRMSD ≤ 2 Å),TopoDiff 的覆盖率均显著提升,且提升来源于具设计性的样本。
研究还验证了覆盖率计算对结构距离定义的鲁棒性——无论使用 TM-score 还是第三方模型计算距离,TopoDiff 的相对优势均保持一致(补充图 12)。总体而言,尽管在长链长度下略逊于 RFDiffusion,但 TopoDiff 在设计性上优于除 RFDiffusion 之外的所有模型,并且生成速度至少快三倍,能在相同时间内产出更多多样且可设计的主链结构。
此外,TopoDiff 还与 FoldFlow、Genie2、FoldFlow2 等近期方法进行了对比(详见补充结果 4)。在进一步探索采样空间时,从 22,500 对潜在结构样本中筛选出 12,613 个高设计性与高新颖性样本(scRMSD ≤ 2 Å 且 maxTM < 0.7),并将其投射到基于 CATH 编码的 t-SNE 子空间(图 3d)。结果显示,这些潜在编码在流形上分布广泛,对应生成的结构在二级结构元素的空间排列上与其潜在编码位置高度相关,充分反映出 CATH 训练样本的原始分布。这说明,在联合训练中,编码器能够捕捉全局几何信息,而扩散解码器则利用这些信息生成空间特征匹配的结构,从而奠定了 TopoDiff 提升天然折叠空间覆盖率的基础。
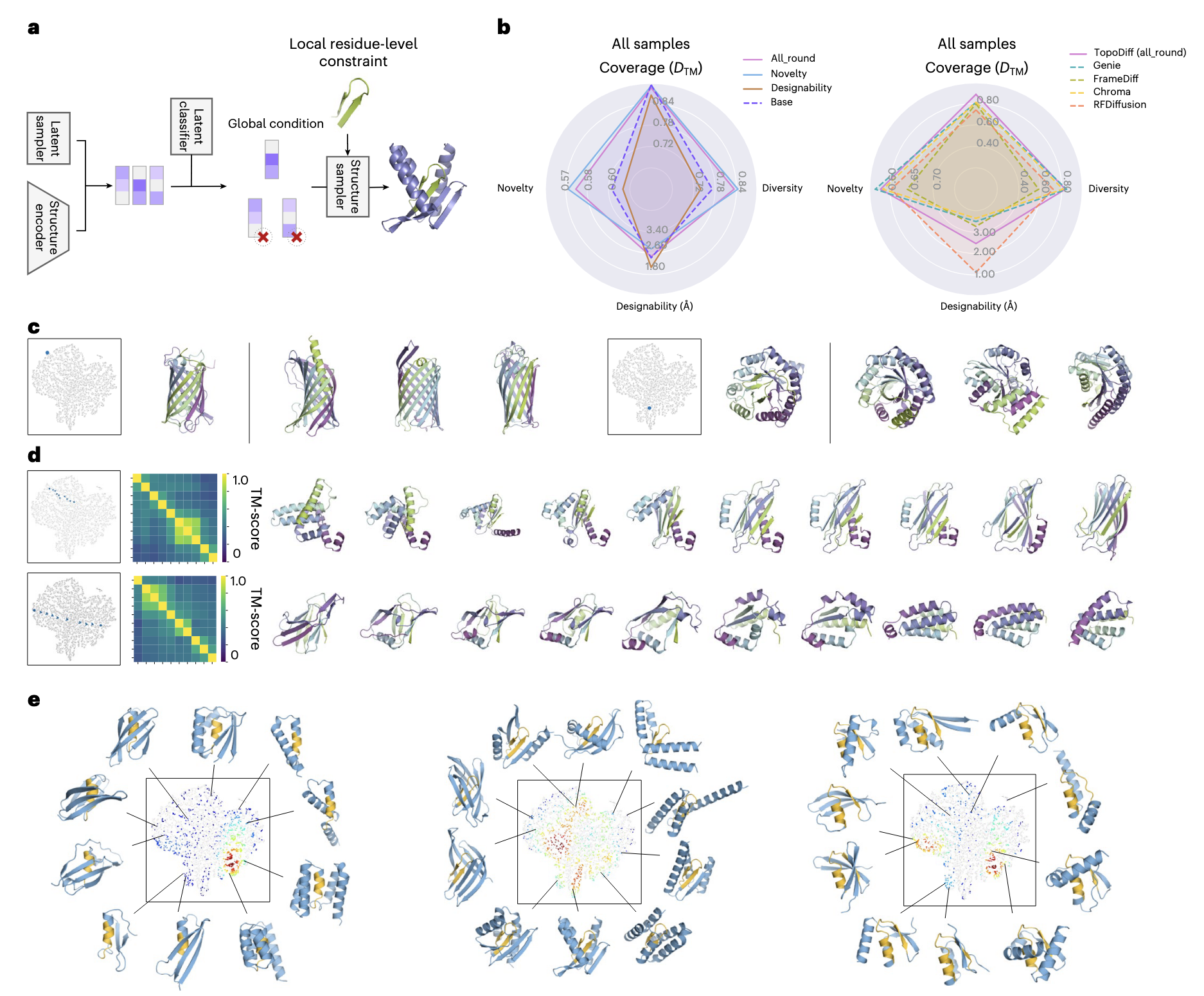
2.4 利用潜在空间实现可控生成
图 4a 展示了本研究中不同模块如何组合,从而增强结构采样的可控性。潜在编码既可以来自前一节介绍的潜在采样器,也可以直接通过编码器在给定输入结构上的后验分布获取。此外,还可以训练额外的潜在分类器预测感兴趣的属性,并通过分类器引导或拒绝采样对潜在分布进行调节。一旦选定潜在编码,结构生成即可在该编码的条件下进行,并可选择性地结合残基级别信息,实现对全局几何和局部原子细节的同步约束。
许多生成样本的可测属性(如二级结构元素比例、新颖性与设计性)在潜在空间中表现出明显的空间分布模式,这表明它们与蛋白质全局几何存在内在关联。因此,本研究探索了通过重新加权潜在采样区域并结合预训练分类器预测目标属性的方式来调整模型性能。这种策略可以在低维潜在空间中简单操作即可微调模型性能,相比在笛卡尔坐标空间原子级的穷举采样,几乎不增加额外计算成本。
研究重点考察了设计性与新颖性之间的权衡关系,并通过拒绝采样(实现细节见方法部分)创建了三种模型变体:
- 设计性优先(使用设计性分类器)
- 新颖性优先(使用新颖性分类器)
- 均衡型(同时使用两类分类器)
结果显示,设计性优先模型提升了设计性但牺牲了新颖性;新颖性优先模型则相反;而均衡型模型在新颖性与多样性显著提升的同时保持了设计性与覆盖率(图 4b 及补充图 17)。
除在潜在空间中进行一般性无条件采样外,还可从任意局部区域采样潜在编码。例如,研究基于某个查询结构的潜在编码周围的局部分布进行采样生成结构。从训练集中选取多种结构架构的代表性查询蛋白质,每个各随机生成 5 个结构(未进行额外挑选)。对比结果(图 4c 及补充图 18)表明,生成结构在二级结构元素空间布局上通常与查询结构高度相似,且有时二级结构比例更优,但在连接方式与拓扑细节上保持较高多样性。
进一步地,研究还实现了基于查询潜在编码对的插值生成控制。选取潜在空间中距离较远的编码对,在两者之间进行线性插值生成 10 个中间潜在编码。结果(图 4d)显示,生成结构沿潜在轨迹逐渐变化,每行对应一对潜在编码。例如,第二行展示了从主要 β 卷到全 α 螺旋束的平滑过渡,邻近结构间 TM-score > 0.45,而起止结构的 TM-score = 0.27,说明尽管终端结构的 SSE 排列完全不同,过渡过程仍相对平滑;第一行则展示了从正交螺旋到 β 三明治的插值过程(更多示例见补充图 19)。
由于潜在编码提供了对全局几何的粗粒度控制,还可在其基础上结合额外的残基级条件实现更精细的控制。研究通过motif 脚手架实验验证了这一能力,从 RFDiffusion 研究中选取了三种代表性结构片段(单螺旋、β 发夹、螺旋-链混合对),先无条件采样符合长度设计的潜在编码,再将这些编码与指定 motif 作为联合条件生成结构。结果(图 4e)显示,在潜在流形上的成功设计(scRMSD ≤ 2 Å 且 motif scRMSD ≤ 1 Å)呈现非均匀分布,集中于潜在信息与 motif 一致的区域。当潜在语义与 motif 自身冲突时,模型会尝试寻找折衷方案,但难度增加。例如,在主要 α 区域中偶尔能采样到 β 发夹嵌入螺旋的设计,且实现了多种全局形态。这表明,在结合局部约束时,潜在编码可作为全局提示引导模型探索多样的架构与拓扑,而不仅限于首选区域。
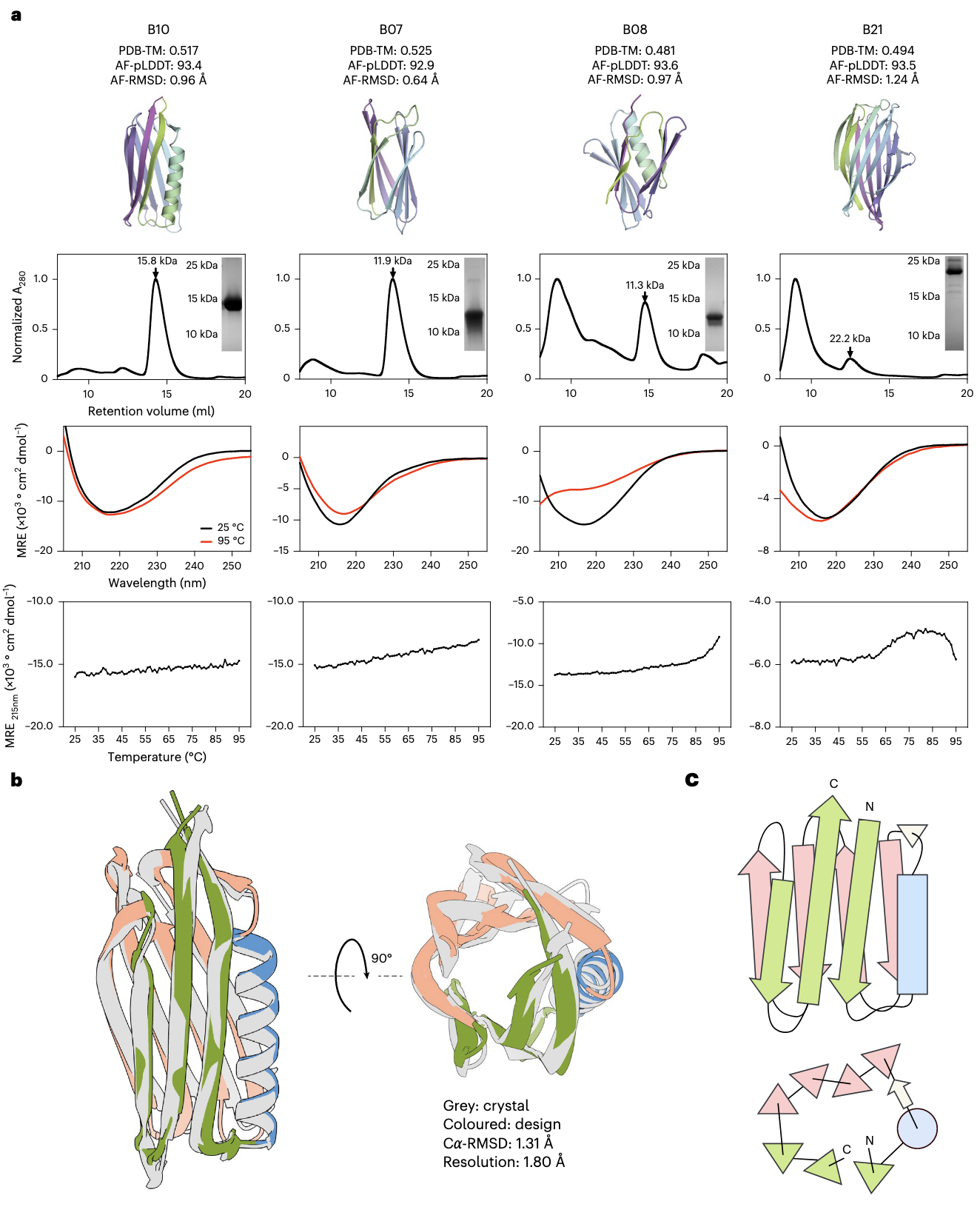
2.5 主要 β 类蛋白质的生成与实验验证
为了在真实设计场景中验证 TopoDiff 的性能,研究将重点放在发现新型主要 β 类蛋白质这一目标上。这类蛋白在天然界广泛存在,但在现有 de novo 设计蛋白中显著欠缺(Extended Data Fig. 1 基于 Protein Design Archive 数据库的统计分析,以及补充结果 6 对其科学意义进行了详细讨论)。
按照方法部分描述的逐步筛选流程,最终获得 403 个主链结构 和 950 个序列设计,并在每个采样长度上选择 3 个设计,得到 21 个候选方案用于后续实验验证。补充图 20 显示,这些设计在 β 链排列方式上高度多样,与已知结构相比具有显著新颖性。所有设计中 β 链残基比例均 >50%,α 螺旋比例 <20%,且超过一半的设计仅由 β 链和卷曲区构成。这些设计的全局堆积主要依赖 β 片层的形成及大量非局域相互作用,使得人工蓝图设计极为困难。
在设计性方面,ESMFold 与 AlphaFold2 预测所有设计均具备良好的可折叠性。特别是 21 个设计中有 16 个 的 5 个 AlphaFold2 模型均达到 pLDDT > 85% 且 scRMSD < 1.75 Å,为成功设计的有力指标。通过计算筛选后,研究合成了这 21 个设计的基因并进行湿实验验证。结果有 9 个设计 在大肠杆菌中可溶性表达(补充图 21),并可通过镍亲和层析与凝胶过滤层析(SEC)纯化(补充图 22a)。其中 B07 与 B10 的 SEC 曲线呈现清晰的单体峰,其余样本为可溶性聚集体与单体的混合物(图 5a 及补充图 22b)。在这 9 个可表达设计中,有 6 个 展现了与富 β 片层蛋白一致的圆二色谱(CD)光谱(图 5a 及补充图 22c)。
作者特别强调了 4 个同时满足可分离单体状态和正确 CD 光谱的设计(B07、B08、B10、B21)。B07 与 B10 的热稳定性可达 95°C,B08 与 B21 也表现出良好耐热性,熔点分别约为 80°C 和 65°C。此外,它们的 PDB-TM 值(与 PDB 结构的最大 TM-score)均低于或接近 0.5,支持其在拓扑上的新颖性。
其中,B10 的结构还通过 X 射线晶体学测定(补充图 23 与补充表 12),解析结构与 TopoDiff 生成的原始主链高度一致,Cα-RMSD 为 1.31 Å。该蛋白由 125 个氨基酸组成,含有 8 条 β 链和 1 条 α 螺旋。一个新的结构特征是 α 螺旋嵌入两片 β 片层之间的交叉区域(图 5b),螺旋向外延伸并将两侧 β 链推开,从顶部观察形成独特的三角形几何布局(图 5c)。这一紧凑三角形布局在天然蛋白中未曾出现,PDB 中最相似的结构要么是 β 桶,要么是双层三明治(补充图 20)。其他单体设计的结构分析见补充结果 7.6。
3 讨论
本研究提出了一种无监督框架,在现有最先进的扩散生成模型基础上,能够同时学习编码器以捕获低维全局结构表示,并利用条件扩散模块将该信息用于可控生成。与部分依赖长度相关潜在扩散以促进结构生成的方法不同,TopoDiff 的潜在表示采用固定维度(类似部分计算机视觉模型),从而能在统一的潜在空间中对多种蛋白质全局几何进行采样与操作。这一固定维潜在编码的引入,不仅便于人工解释与理解数据分布与生成过程,还显著提升了蛋白质折叠空间的覆盖率,同时保持其他性能指标的竞争力。
通过 VAE 架构,TopoDiff 的潜在空间被限制在低维且具有良好连续性,从而在生成过程中对全局几何施加粗粒度约束,但又不妨碍新型折叠的发现。消融实验验证了这一独特设计的有效性(补充结果 8)。在此基础上,研究还提出了多种新颖灵活的潜在空间控制方案,仅需在潜在层面进行简单操作即可引导蛋白质结构生成。这种潜在层控制是对已有残基级约束(如 SSE 注释、成对邻接信息)的有益补充,后者虽然有价值,但依赖较强领域知识且可能限制采样空间。
在一个公认具有挑战性的设计任务——具有新型主链拓扑的主要 β 类蛋白设计中,TopoDiff 能够在无需人工预设计的情况下,生成并经实验验证主要为 β 类甚至全 β 的新型蛋白质。考虑到小型单结构域蛋白在当前实际蛋白质设计与工程中的广泛应用,本研究版本的 TopoDiff 聚焦于长度 ≤256 个残基的蛋白质结构生成。然而,由于框架本质上的无监督特性,其设计天然可推广至更长蛋白,潜在方式包括增加网络参数容量。补充结果 9 展示了在该模型中引入flow-matching 技术以及在参数规模上的可扩展性探索。另一方面,该框架也可根据用户自定义的蛋白类别进行定制化训练,从而学习类别特定的表示并配合专用生成模型。
与主流方法及本方法逐步生成主链坐标与蛋白质序列的方式不同,已有研究提出全原子蛋白质生成以提升设计蛋白的序列-结构一致性。尽管该方向尚不成熟,但相关成果已指示了 TopoDiff 未来可能的优化路径。