NMI 2024 | PepFlow: 通过超网络调控扩散直接采样肽类能量景观的构象
今天介绍的是发表在 Nature Machine Intelligence 的PepFlow。这是一种基于深度学习的全原子多肽构象采样方法。相比传统只预测单一静态结构的工具,PepFlow更关注多肽在生物过程中的构象多样性。研究团队以扩散模型为核心,引入超网络生成序列特异性参数,并通过模块化架构逐步建模主链、侧链和质子,从而实现直接从能量景观进行采样。结果显示,PepFlow不仅在单结构预测上优于现有方法,还能高效再现实验中的多肽集合,尤其是在短线性基序与大环化等复杂约束条件下表现突出。这一框架为多肽对接与药物设计提供了新的思路,也展示了深度学习在分子建模领域的潜力。

获取详情及资源:
0 摘要
深度学习方法在生物分子结构的单态预测方面推动了显著进展。然而,生物分子的功能依赖于其能够呈现的一系列构象。这一点在肽类分子中尤为突出,肽作为一类高度柔性的分子,参与了大量生物学过程,同时在治疗应用中具有重要价值。该研究提出PepFlow,一种可迁移的生成模型,能够从输入肽分子的允许构象空间中直接进行全原子采样。该模型基于扩散框架进行训练,随后利用等价的流式过程来完成构象采样。为解决通用全原子建模成本过高的问题,研究将生成过程模块化,并引入超网络来预测序列特异性的网络参数。PepFlow能够高精度预测肽结构,并以远低于传统方法运行时间的代价,有效再现实验观测到的肽构象集合。此外,PepFlow还可以用于采样满足特定约束的构象,例如大环化结构。
1 引言
蛋白–肽相互作用在分子通路中普遍存在,是许多细胞功能的核心。据估计,多达40%的蛋白–蛋白相互作用是通过肽结合介导的。这类相互作用通常表现为球状蛋白与局域于无序区域的短片段结合。短肽还具有多种特性,使其极具治疗开发潜力。与小分子相比,肽通常具有更高的特异性,毒性风险更低;与大型生物制剂相比,肽的生产成本更低,免疫原性也更弱。因此,肽类药物已占据制药市场的重要份额,例如胰高糖素样肽1(GLP1)类似物长期位列畅销药物。
当前亟需计算工具来加速肽的建模与工程。深度学习已推动生物分子建模取得重大进展,其中最突出的例子是AlphaFold2(AF2)在蛋白质单态结构预测上的成功。尽管AF2主要以蛋白质为训练对象,但它在线性肽、环肽以及肽–蛋白复合物建模方面已超越了以往的最佳方法。然而,AF2存在一定的失败案例,且无法捕捉肽可能呈现的全部构象。已有尝试通过利用预测流程中固有的随机性扩展AF2以实现构象采样,但仍有局限。与此同时,一些生成建模方法则通过已知结构集直接采样蛋白或小分子的构象。
Boltzmann生成器代表了深度学习在构象采样中的另一类重要范式。它们利用归一化流(normalizing flows)学习分子体系的构象分布,突破了基于轨迹方法的局限。归一化流的优势在于能够进行精确似然计算,这使得模型能够通过能量驱动的方式训练,即优化模型以匹配特定分子力场给出的状态分布。该分布即Boltzmann分布,其形式为
在此基础上,有研究利用扩散模型在已知分子构象上进行训练,并借助对应的ODE流实现基于能量的训练。基于这一思路,该研究提出了一种能够直接进行肽类构象全原子采样的方法。即便是短肽,实现既精确又高效的全原子采样依然是巨大挑战。为此,开发了PepFlow,一种模块化、由超网络调控的生成模型,能够对任意输入肽序列预测全原子构象。PepFlow在已知分子构象上以连续时间扩散模型进行训练,并使用相应的概率流ODE进行采样和能量驱动训练。结果表明,PepFlow不仅能够高效预测肽的单态结构,还能再现短线性基序(SLiMs)的构象集合,并可通过潜在空间的构象搜索对大环化等约束条件下的肽结构进行建模。

图1 | PepFlow架构示意图 a,超网络生成一部分序列特异性的网络参数,这些参数由基于EGNN的得分网络(score network)使用,用于促进主链的生成。b,基于EGNN的得分网络结合质心守恒过程生成侧链重原子坐标,同时保持侧链质心约束。c,基于EGNN的得分网络根据输入的重原子坐标对肽进行质子化,图中的边由重原子之间的成对距离决定。其中,
2 结果
2.1 模块化的超网络调控构象采样
PepFlow架构具有两个关键特征:(1)由三个逐步建模肽类构象的网络组成;(2)通过超网络生成部分序列特异性的参数(图1a)。
第一个网络用于建模主链原子以及侧链原子的质心。输入的肽分子坐标被表示为一个全连接图,并传递至一组E(3)等变图神经网络(EGNN)层。其中一部分参数由基于注意力机制的超网络预测,另一部分为通用的EGNN层参数,直接通过优化获得(图1a)。超网络的引入显著提升了模型的表达能力,而不会成比例地增加动力学网络的规模。PepFlow最初作为扩散模型进行训练,预测得分以便从噪声分布中生成数据。与其对主链原子的绝对坐标去噪不同,该模型选择去噪相对坐标:即每个原子与其N端邻居之间的相对位置,侧链质心的位置则相对于Cα原子进行编码。虽然网络层仍作用于绝对坐标,但这种噪声过程逐渐将肽主链推向理想链结构,更好地反映肽的结构特性(补充信息)。
第二个网络在已生成的主链和质心基础上建模侧链的重原子(图1b)。输入图的边仅限于那些侧链质心间距小于8 Å的残基。为了保证在真实肽原子坐标(不包括侧链质心)上的似然计算可行,模型强制满足条件
其中,
最后一个网络在重原子坐标的基础上建模氢原子的位置(图1c)。该模型对氢原子相对于其所结合的重原子的相对位置进行去噪。处理后的图包含两类边:一类是连接与同一重原子共价结合的氢原子,另一类是氢原子与其结合重原子4 Å范围内其他重原子之间的连接。
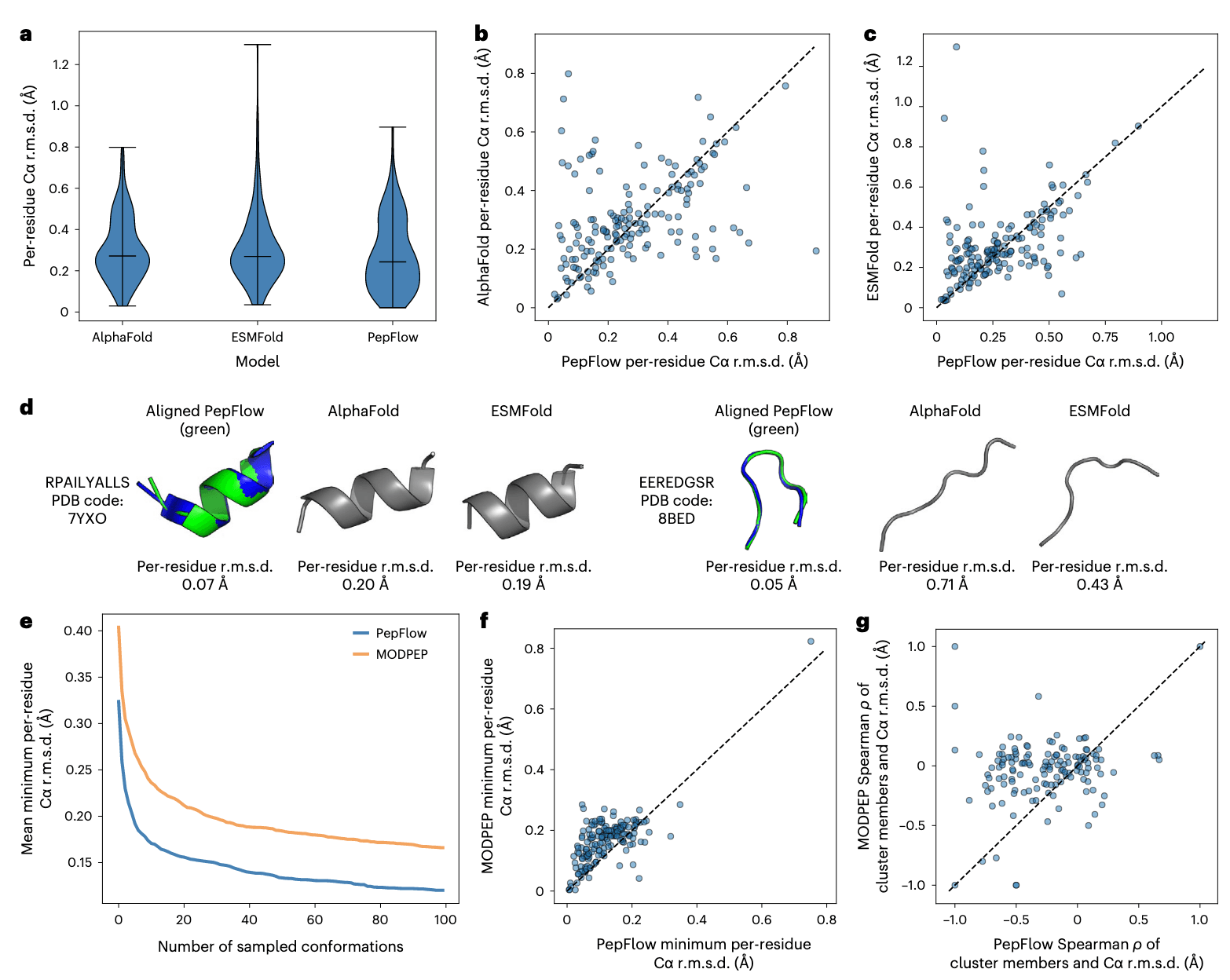
图2 | PepFlow对实验解析结构的预测 a,PepFlow、AF2和ESMFold在肽测试集上的Cα均方根偏差(r.m.s.d.)分布。b,c,PepFlow在已解析肽结构测试集上的预测结果分别与AF2 (b) 和ESMFold (c)进行比较。d,PepFlow优于AF2和ESMFold的肽结构预测实例。e,随着生成构象数量的增加,PepFlow与MODPEP在采样中得到的最小r.m.s.d.比较。f,PepFlow与MODPEP各生成100个构象时,其最小r.m.s.d.与已解析肽结构的比较。g,PepFlow与MODPEP在簇大小与Cα r.m.s.d.相关性上的比较。
2.2 PepFlow再现肽分子的结构特征
由于可用的肽结构数据有限,PepFlow首先在蛋白质数据库(PDB)中约4000万个蛋白片段上进行预训练。预训练完成后,评估其在输入蛋白片段序列下生成合理分子的能力。采样通过与训练好的扩散模型对应的ODE流完成,因为PepFlow的后续训练需要精确的似然计算。结果显示,这种采样方式生成的分子能够准确捕捉肽的分子特征。主链原子与侧链质心的键长、键角和扭转角均与实验解析的结构高度一致(补充图1)。
进一步评估了旋转异构体(rotamer)模型,结果表明其生成的侧链构象在验证集上表现出持续较低的均方根偏差(r.m.s.d.)(补充图2)。通过在潜在空间进行温度缩放,侧链的r.m.s.d.可进一步降低(补充图2b)。此外,不同残基的χ角分布与经验分布高度吻合,主要差异来自侧链末端原子标记的歧义性(补充图3)。这表明,即便与真实结构存在偏移,模型仍能生成合理的构象。
不同于片段训练,质子化模型直接在抗菌肽活性与结构数据库(DBAASP)的分子动力学模拟子集上训练,因为多数实验解析结构中缺乏氢原子。在训练完成后,该模型被用于对来源于分子动力学模拟的肽构象进行再质子化。结果发现,生成的构象与真实分子动力学模拟高度一致,能量和氢键数量均表现出强相关性(补充图4)。
2.3 PepFlow捕捉序列特异性的肽构象
在完成预训练后,PepFlow能够高效生成不同长度肽分子的全原子构象(补充图5)。接下来,评估了其生成序列特异性构象的能力,并探讨这种能力在多大程度上由超网络驱动。通过改变由超网络预测的层数训练模型,结果发现:对于螺旋片段和卷曲片段,不同模型间预测差异很小;随着超网络预测层数的增加,整体预测构象更趋于有序(补充图6a,b)。而在链状片段预测中差异更为显著,超网络参数数量增加显著提升了PepFlow生成链状构象的倾向,说明超网络在长程相互作用的预测中发挥了重要作用。
随后,PepFlow在PDB中3673个已解析的肽结构数据上进行了微调。与预训练模型相比,微调后的模型预测出更多的卷曲构象(补充图7a),这一点与肽分子天然的柔性特性相符。同时,微调模型在已解析肽结构的准确性上也优于仅基于片段训练的模型(补充图7b,c)。在一个由167个最新且无冗余的PDB肽结构组成的测试集上,PepFlow能够通过采样100个构象并聚类,以最大簇的质心作为预测结果。结果显示,簇的大小通常与Cα均方根偏差(r.m.s.d.)呈负相关(补充图8)。与目前肽结构预测领域的最佳方法AF2以及单序列预测方法ESMFold相比,PepFlow整体表现相当,且在许多情况下优于两者(图2a–c),涵盖了细微差异与大幅差异的预测场景(图2d)。进一步比较PepFlow生成的前五个簇与AF2预测的五个模型,结果显示PepFlow明显优于AF2(补充图9),提示其随机性在肽结构预测中反而是一种优势。
值得注意的是,PDB中的多数肽结构是以复合物形式解析的,肽在结合过程中常会发生构象变化。因此,单独预测在缺乏结合环境时必然存在不足。为此,进一步评估了PepFlow在高采样条件下预测结合态肽构象的能力,并与MODPEP方法进行对比。后者通过二级结构预测与片段组装生成结合态肽结构。结果表明,PepFlow在大多数情况下优于MODPEP,能够准确捕捉已解析的肽构象(图2e,f)。通过对生成的构象进行排名比较,PepFlow结果与真实结构表现出更强的相关性(图2g),说明其更频繁地产生准确的肽结构。
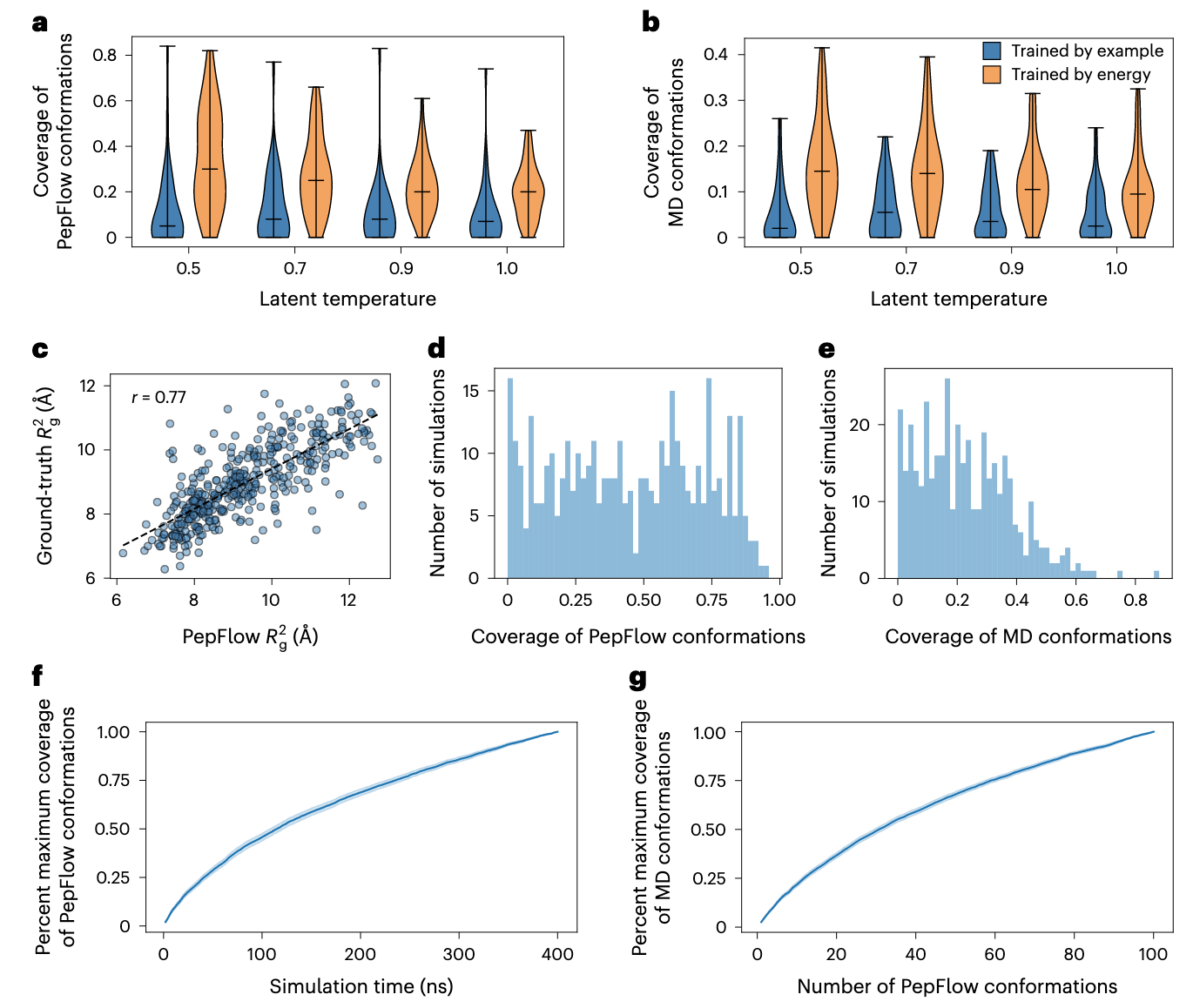
图3 | PepFlow生成的构象集合与分子动力学模拟的比较 a,能量驱动训练前后,在不同潜在温度下,PepFlow采样构象被验证用分子动力学(MD)构象覆盖的情况。b,能量驱动训练前后,在不同潜在温度下,验证用分子动力学构象被PepFlow采样构象覆盖的情况。c,PepFlow与测试用分子动力学构象的回转半径(
2.4 能量驱动训练实现肽构象集合预测
能量驱动训练通过对不同序列采样肽构象,并最小化模型分布与未归一化Boltzmann分布之间的Kullback–Leibler散度来实现。由于该损失函数先前被观察到会导致模式崩溃,训练中额外加入了基于DBAASP数据集子集分子动力学模拟构象的辅助得分匹配损失。整体上,能量驱动训练显著减少了物理上不合理构象的产生:能量小于0的合理构象比例从54.5%提高至93.6%(补充图10)。
为评估能量驱动训练在集合生成上的效果,在分子动力学验证集中(400 ns模拟,共200帧)选取序列,分别在训练前后用PepFlow采样100个构象。结果表明,经过能量驱动训练后的PepFlow生成的集合与分子动力学结果更为接近,并且在潜在空间温度缩放下性能进一步提升。回转半径(
为验证其泛化能力,在DBAASP中401个非冗余分子动力学模拟的测试集上进行基准测试,结果表现一致。预测构象的平均
进一步比较PepFlow与分子动力学生成的构象簇,发现两者的簇数呈相关性(补充图14a)。以质心距离或簇间最小距离计算的Jaccard相似度分别为0.130和0.192(补充图14i,j)。这种较低的覆盖率与相似度部分归因于肽分子的高度柔性,导致能量景观崎岖且构象极为多样。尽管如此,更细致的分析表明,即使在低覆盖率和低相似度下,PepFlow生成的整体分布仍能与分子动力学的结果保持一致。对不同二级结构倾向的肽分析显示,PepFlow采样能够再现多样化的肽结构(补充图15–17,质心Jaccard相似度为0.099、0.073和0.11)。PepFlow生成的离散模式对应于分子动力学集合中的不同区域。将PepFlow生成的坐标投影到基于分子动力学集合拟合的主成分空间,发现PepFlow捕捉到了分子动力学模拟中的大量变异(补充图15–17)。
这些结果表明,虽然PepFlow未能完全再现整个构象集合,但它提供了一种高效捕捉肽构象分布中不同模式的手段。这些生成的构象还可以作为分子动力学模拟的起始结构,以便更深入地探索能量景观。
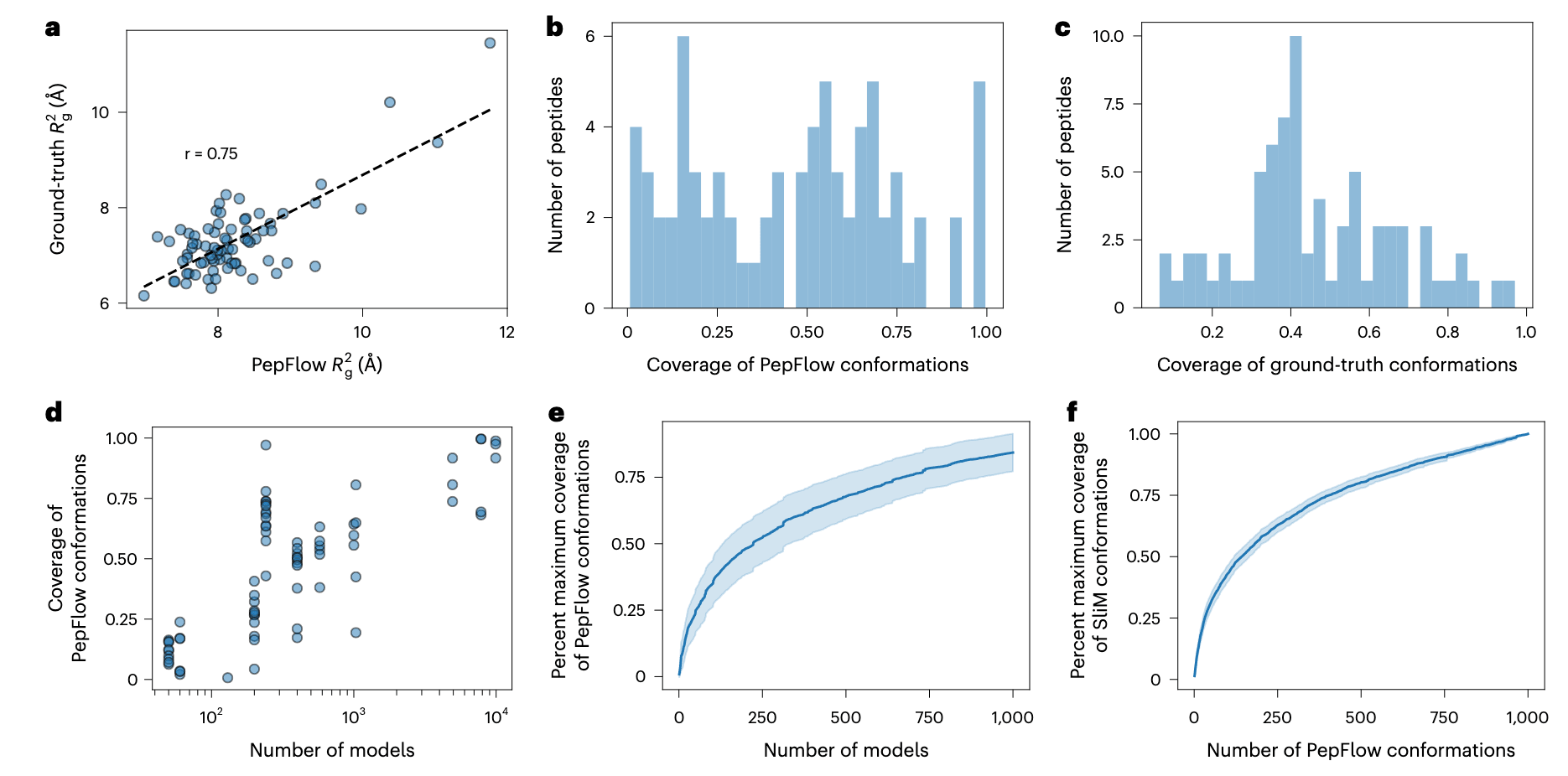
图4 | PepFlow在SLiM集合生成中的性能。 a,PepFlow与真实构象的
2.5 PepFlow高效再现实验集合
为了评估PepFlow预测实验构象集合的能力,研究使用了Protein Ensemble Database (PED),该数据库整合了多种实验方法生成的结构集合,其中包含大量富集短线性基序(SLiMs)的内在无序蛋白。利用Eukaryotic Linear Motif工具,对长度为8–15个氨基酸的SLiMs进行注释,发现部分基序位于高度有序区域,而另一些则处于高度无序区域(补充图18)。通过计算与序列中远端氨基酸的笛卡尔距离来估算三级接触数量,结果显示PepFlow性能与肽的三级接触数量呈负相关(补充图19)。在三级接触数低于每残基3个的75条序列上进一步验证,PepFlow每条序列采样1000个构象,其生成样本的回转半径(
2.6 潜在空间搜索实现环肽建模
大环化(macrocyclization)常用于治疗性肽的开发,以改善其药代学性质。线性肽在一定概率下会接近环肽构象,而Boltzmann生成器的潜在空间探索已被证明能够高效穿越构象景观。因此,研究在PepFlow中实现了基于潜在空间的马尔科夫链蒙特卡洛(MCMC)搜索,以识别大环肽构象。在PDB中的头尾环化肽测试集上,每个序列以25个起点运行MCMC,结果表明在500次迭代内稳定生成满足约束条件的构象(图5a),且比直接采样更接近真实结构(补充图22a)。进一步与AF2的环肽预测扩展版本比较,发现AF2的预测平均上更接近真实结构(图5b),但PepFlow也能稳定生成接近真实的构象(图5c),提示改进的排序方法将提升性能。PepFlow的优势在于其显式建模侧链原子,能够处理侧链环化的肽。MCMC搜索同样能找到满足目标约束的构象(图5d),而直接采样则生成与环化构象主链相似的结果,说明这些目标主链构象在热力学上更易获得(补充图22b,c)。在此类情况下,AF2预测明显失败,而PepFlow的结果则远优于AF2的线性肽预测(图5e,f)。
PepFlow的主要失败案例出现在套索肽(lasso peptides)上,该类肽具有罕见折叠方式。然而,PepFlow仍能准确预测其环状部分的结构,尽管整体生成的构象更为延展(补充图23)。
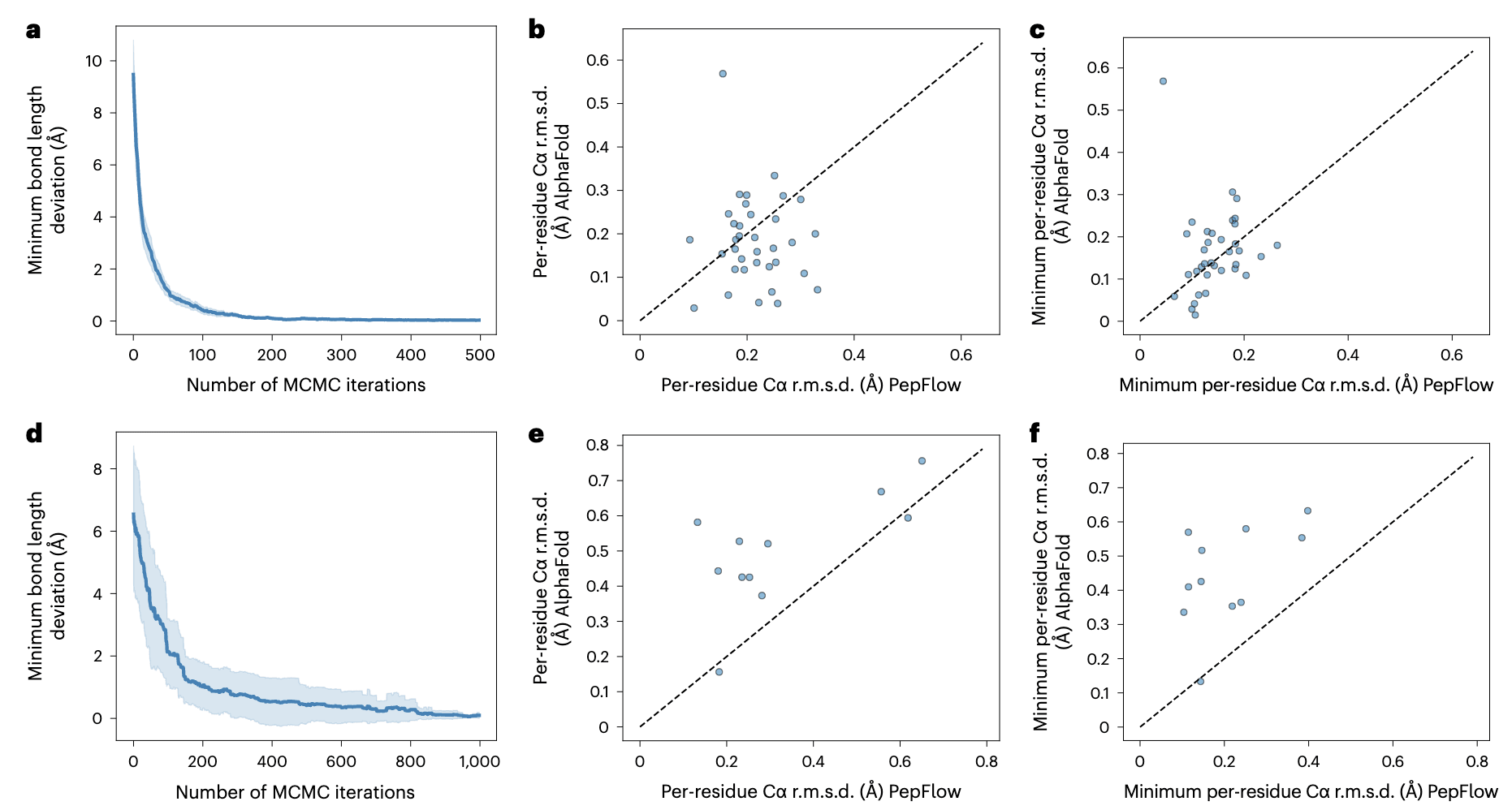
图5 | PepFlow在大环肽结构预测中的性能。 a,头尾环化肽在MCMC迭代过程中的平均键长偏差,阴影表示90%置信区间;b,头尾环化肽中AF2与PepFlow的最佳预测结果r.m.s.d.比较;c,头尾环化肽中AF2与PepFlow预测的最小r.m.s.d.比较;d,侧链环化肽在MCMC迭代过程中的平均键长偏差,阴影表示90%置信区间;e,侧链环化肽中AF2与PepFlow的最佳预测结果r.m.s.d.比较。
3 讨论
本研究提出了一种能够显式建模生成构象中全部自由度的肽类构象集合预测方法——PepFlow。该模型利用超网络生成序列特异性参数,并包含三个逐步建模输入肽序列中全部原子的网络。结果显示,PepFlow不仅能有效生成肽构象,在肽的单结构预测上也优于现有的最佳方法,同时还能高效再现实验中观测到的短线性基序(SLiMs)构象集合。此外,通过潜在空间探索,PepFlow能够识别满足特定约束的肽类构象。总体而言,准确且高效地采样肽构象有望改进肽对接与设计。传统的肽对接方法通常需要从肽构象库开始,将其对接至靶蛋白,更准确的构象生成将显著提升这一过程。PepFlow还可用于评估不同序列形成特定蛋白–蛋白界面构象的倾向,从而用于抑制性肽的设计。
然而,PepFlow也存在局限性。与Boltzmann生成器不同,PepFlow缺乏对采样结果进行再加权以逼近真实Boltzmann分布的能力。虽然PepFlow能够对生成样本进行似然计算,但可行的计算依赖随机估计器,这会在计算值中引入噪声。此外,PepFlow偶尔会生成高能量构象,且未能完全覆盖分子动力学模拟中观察到的能量景观。潜在的改进方向是将PepFlow迁移到其他采样框架。例如,**归一化流(normalizing flows)已在条件采样环境中应用于Boltzmann分布的生成;而近期发展的流匹配(flow matching)**范式则提供了一种无需显式模拟即可训练连续归一化流模型的新途径。流匹配已成功应用于小分子和蛋白质等不同体系的结构采样,因此可能成为扩展PepFlow框架效能的重要方法。
综上,PepFlow框架具有高度灵活性,并作为一种深度学习驱动的全原子构象采样的概念验证展现了重要价值。