Chem. Sci. 2025 | PepINVENT: 超越天然氨基酸的生成式肽设计
今天介绍发表在《Chemical Science》上的阿斯利康团队(MolecularAIs)工作——PepINVENT。该框架以transformer为核心,结合强化学习实现de novo多肽设计,直接在原子层面提出非天然氨基酸(NNAA)并可引入主链与立体化学修饰。借助化学感知的CHUCKLES表示法与多参数优化(MPO),模型既能在广阔化学空间中高效探索,又能按目标收敛到特定拓扑(如大环肽),最终生成有效、新颖、可合成且具备高溶解性与高通透性的候选肽,展示出在肽类药物发现与先导优化中的实用价值。

获取详情及资源:
0 摘要
肽类在药物设计与发现中扮演着关键角色,既可以作为治疗手段,也可以作为递送载体。非天然氨基酸(NNAAs)的引入被广泛用于提升肽的性能,如结合亲和力、血浆稳定性和透膜性。通过加入新颖的NNAAs,可以设计出性质更优的肽分子。
现有的生成模型主要集中在肽序列空间的探索,这一序列空间由预定义氨基酸集合的组合构成。然而,仍然缺乏一种工具能够突破这一有限空间,从而有效地实现新氨基酸的de novo设计,并真正扩展肽分子的可能性。
为深入探索肽的理论化学空间,该研究提出了PepINVENT,一种基于生成式人工智能的新工具,它作为小分子生成设计平台REINVENT的扩展而开发。PepINVENT能够在天然和非天然氨基酸的广阔空间中导航,生成有效、新颖且多样化的肽设计。该生成模型并非针对具有特定性质或拓扑结构的肽进行训练,而是学习肽的结构颗粒度,并具备在肽序列中填充掩码位置的氨基酸设计能力。
结合强化学习,PepINVENT可以实现目标导向的肽设计,利用其化学信息驱动的生成能力,探索独特而创新的肽空间,并在治疗相关肽的性质优化中展现出潜力。该工具可应用于多参数学习目标、拟肽分子(peptidomimetics)、先导化合物优化以及其他多种肽相关任务,展示了在未来肽药物研发中的广阔前景。
1 引言
肽类在药物研发中占据着独特的位置。相较于小分子,肽覆盖的表面更大,但又比蛋白质更小,这种特性使其成为极具潜力的药物分子。凭借高特异性、强亲和力和低毒性,肽类正逐渐受到药物发现与开发领域的广泛关注。它们能够与更大的蛋白质表面区域结合,从而有效靶向蛋白口袋、浅沟或蛋白–蛋白相互作用界面,包括那些被认为小分子药物无法成药的靶点。
以20种蛋白质氨基酸为基本单元,肽类的序列空间呈指数级扩展,范围覆盖
传统方法如展示技术、拟肽分子(peptidomimetics)设计以及基于结构的计算研究,在肽类药物发展中起到了重要作用。然而,这些方法通常受限于天然氨基酸,即便包含立体化学修饰,其可及的设计空间仍远小于NNAAs所能提供的潜力。同时,虚拟化学空间的探索也受限于设计-合成-测试-分析(DMTA)循环的效率。
为加速药物发现,近年来生成模型被引入肽类设计,能够进行de novo设计或基于目标性质的分子优化。已有研究利用生成建模探索不同性质的肽,如抗菌活性、细胞穿透性、抗癌特性及免疫原性。这些研究在肽的特征表征和模型结构上有所差异,但共同目标是基于20种天然氨基酸设计肽序列。例如,Grisoni等人使用长短期记忆(LSTM)模型,在阳离子两亲性肽的基础上进行训练,再在已知抗癌肽上进行微调,最终生成的肽序列在实验中证实具备抗癌活性。在其他研究中,非天然氨基酸被引入生成模型的构建模块中,扩展了可探索的空间。Schissel等人提出的生成器–预测器–优化器循环,利用三种非天然氨基酸设计多肽载体,以改善反义寡核苷酸的递送效果,同时降低精氨酸含量。该学习循环模拟遗传算法的定向进化过程,能够提出具备目标特性的肽设计。
尽管这些研究显示出生成模型在肽序列空间的优势,但由于依赖预设的氨基酸集合,仍局限于序列层面。而真正意义上的肽设计需要覆盖完整的化学空间,能够灵活生成天然氨基酸与NNAAs。
针对这一需求,该研究提出了PepINVENT,基于REINVENT框架开发的全新工具。REINVENT作为小分子设计的前沿平台,利用强化学习与基于SMILES语言的生成模型进行多参数优化的de novo分子设计。与之类比,PepINVENT是一个开源框架,由化学信息感知的预训练生成模型与强化学习模块组成,能够生成新颖的NNAAs和多样化的肽拓扑结构。受核糖体翻译过程的启发,PepINVENT在氨基酸颗粒度水平上学习肽空间,并保持肽结构的细微特征。当生成模型提出新的氨基酸时,强化学习以目标导向方式引导整体肽设计。
PepINVENT展现了加速肽类药物研发流程的潜力,通过引入NNAAs扩展设计空间,具备de novo设计、拟肽分子构建、先导优化以及性质优化的能力。在该研究中,通过一系列实验展示了该工具的实用性,包括:(i)在肽化学空间中的导航能力;(ii)灵活生成多样肽拓扑结构的能力;(iii)在多参数优化(MPO)场景下提升肽性质的应用案例,例如增强环肽与REV结合蛋白的渗透性与溶解性。
2 方法
2.1 训练数据准备
由于涉及非天然氨基酸(NNAAs)的肽数据非常稀缺,研究团队构建了半合成肽数据集以扩展更大、更丰富的化学空间。在天然氨基酸的基础上,加入了Amarasinghe等人提出的虚拟氨基酸库,其中包含约38万种可合成的NNAAs,并公开了1万个代表性的α-氨基酸。利用CHUCKLES表示法将氨基酸转化为标准化的SMILES模式,从而保证生成的肽序列在语法上的正确性。
数据生成过程包括肽的长度、拓扑结构、NNAA比例以及常见修饰(如立体异构和主链N-甲基化)。肽长度在6–18之间,NNAAs的比例通过偏态分布控制在最多约30%,以保证合成可行性。拓扑结构涵盖线性肽、头尾环化、侧链环化以及二硫键桥联,不同结构通过特定氨基酸的选择和修饰来实现。其余氨基酸则在天然与非天然集合中按比例随机抽取,并进一步引入立体化学突变和N-甲基化修饰。
最终共生成100万个独特肽分子,其中40%为线性肽,其余三类拓扑各占20%。数据集按照90%训练、5%验证和5%测试集划分,并保持肽长和拓扑分布的一致性。此外,设计了两个测试子集:一个包含400条掩码肽序列,用于评估生成模型的预测能力;另一个包含40条不同拓扑的肽序列,用于检验模型是否能够正确理解肽的拓扑上下文。
图1|半合成数据的特征。 所生成的肽数据涵盖不同的肽链长度、天然与非天然氨基酸比例、肽的拓扑结构,并体现了立体化学与主链修饰。
2.2 预训练目标
该生成模型旨在为肽序列中指定位置提出合适的氨基酸,以实现结构修饰。研究团队基于半合成数据集构建了训练对,其中源字符串通过在肽序列中随机掩码约30%的氨基酸并以“?”替代,而目标字符串则保存这些被移除的氨基酸。训练任务类似于文本填充(infilling),参考了BART和Chemformer等模型在自然语言处理与化学信息学中的应用。
在掩码过程中,自然氨基酸与非天然氨基酸的比例被控制,其中自然氨基酸的掩码比例偏向于较低(均值约0.3),以避免模型过拟合天然氨基酸模式,从而增强对NNAAs的学习。模型的预训练目标是生成与掩码位置数目匹配的氨基酸集合,并将其正确映射回源序列,从而得到新的肽结构。整个过程要求生成的肽在化学表示上保持语法正确性,使模型能够逐步学习氨基酸与肽的化学规律。
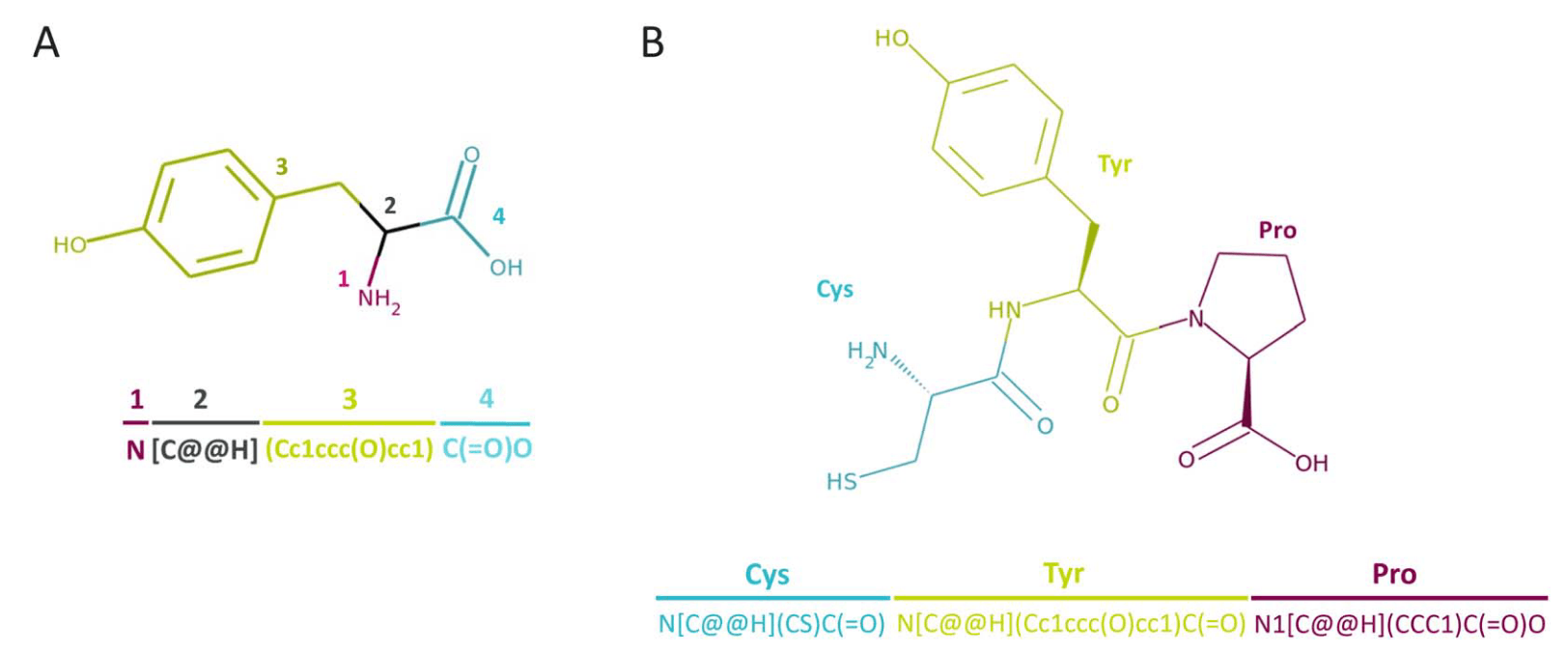
图2|CHUCKLES表示法。 (A) 单个氨基酸——酪氨酸(T);(B) 三肽——CTP(Cys-Tyr-Pro)。
2.3 模型结构与训练
该生成模型采用与REINVENT中transformer模型相同的实现与参数,包括编码器和解码器结构。输入输出序列均通过基于SMILES的分词器处理,模型通过最大似然损失函数进行训练,以预测被掩码位置的氨基酸。
训练过程中,使用约90万条掩码肽及对应填充氨基酸对,在NVIDIA V100(32GB)上运行,共训练24个epoch,批量大小为16,并采用Adam优化器(学习率0.0001,含4000步warm-up)。训练完成后,模型能够在源肽序列中逐位预测氨基酸,直到生成结束标记或达到预设长度(500)。为提升多样性,可采用多项式采样或束搜索。
在学习过程中,模型掌握了肽的“化学语言”,不仅能够填充所需的氨基酸,还能生成新型氨基酸以及简单修饰(如主链N-甲基化和立体化学突变),从而展现出在化学空间中进行灵活生成的能力。
2.4 评估指标
生成模型的评估主要围绕能否生成与掩码位置数目一致的氨基酸展开,若生成数量不符即视为失败。在数量匹配的前提下,进一步采用以下指标:
-
有效性(Validity):生成肽的SMILES必须在化学规则上正确(如化合价、化学键),通过RDKit验证。
-
唯一性(Uniqueness):从两个层面进行考察:
-
肽水平:比较去除分隔符并标准化后的SMILES,确保同一输入生成的不同氨基酸组合被识别为独特肽序列。
-
氨基酸水平:细分为三类:
(i) 字符串唯一性:逐字符比较氨基酸字符串;
(ii) 同分异构SMILES唯一性:在保留手性的条件下,标准化SMILES后判定唯一性;
(iii) 规范化SMILES唯一性:去除立体化学信息后,以分子结构为准确保唯一性。
-
-
新颖性(Novelty):将生成的氨基酸分类为天然、训练集中已包含的非天然(NNAAs)、以及模型生成的全新NNAAs,并通过化学空间分析验证其多样性。为此,采用1024位Morgan指纹并结合t-SNE将氨基酸投射到二维空间,以直观展示天然、已知非天然和新颖氨基酸的分布差异。

图3|源–目标对示例,展示条件生成器所训练的文本填充任务。 在一个6肽中,第2位和第5位氨基酸被标记为可修饰残基。源序列通过在原始肽上掩码第2位和第5位氨基酸构建,而目标序列则给出填充这两个位置所需的氨基酸。模型在源–目标对上训练,从而学会生成与掩码位置数量相符的氨基酸,既能遵循CHUCKLES表示模式,又能理解肽序列上下文的复杂性。
2.5 实验设置
实验旨在展示生成模型在肽化学空间中的探索能力,以及在优化性质方面的应用潜力。在生成模型评估中,使用训练数据部分定义的第一个测试集,分别采用多项式采样和束搜索(beam size=1000),为每条掩码肽生成1000组填充氨基酸。多项式采样重复三次以保证可重复性,结果取平均。首先考察模型能否生成与掩码数目一致的氨基酸,随后再应用有效性、唯一性和新颖性等指标进行评估,并进一步分拓扑类别分析性能差异。此外,使用第二个测试集(40条肽)检验模型是否学会拓扑信息,尤其是宏环结构是否能正确完成。
在强化学习(RL)部分,PepINVENT基于REINVENT的框架,通过用户自定义的打分函数指导生成过程,以实现肽性质优化。RL环路中,生成的肽会被打分,并通过加权平均或几何平均整合多种打分指标。为避免重复生成,实验中使用了多样性过滤器,在环肽实验中尤其对相同Murcko骨架的肽进行惩罚。RL实验包括两个场景:其一是通过拓扑约束优化肽结构(如限制环的最大尺寸),其二是设计既具备溶解性和通透性,又保持环状结构的肽。
在打分组件中,主要涉及三类:
- 拓扑约束:通过设定不同的打分窗口引导模型生成大环、特定环化类型(头尾环化/侧链环化)或线性肽。
- CAMSOL-PTM溶解性预测:用于评估天然氨基酸或NNAAs修饰后对肽溶解性的影响,得分通过Sigmoid函数归一化。
- 肽通透性模型:基于PAMPA实验数据构建的XGBoost分类器,预测宏环肽的通透性,输出为可渗透类别的概率分数。
综合来看,这些实验通过生成模型与RL的结合,展示了PepINVENT在拓扑控制、溶解性提升和膜通透性优化等方面的应用潜力。
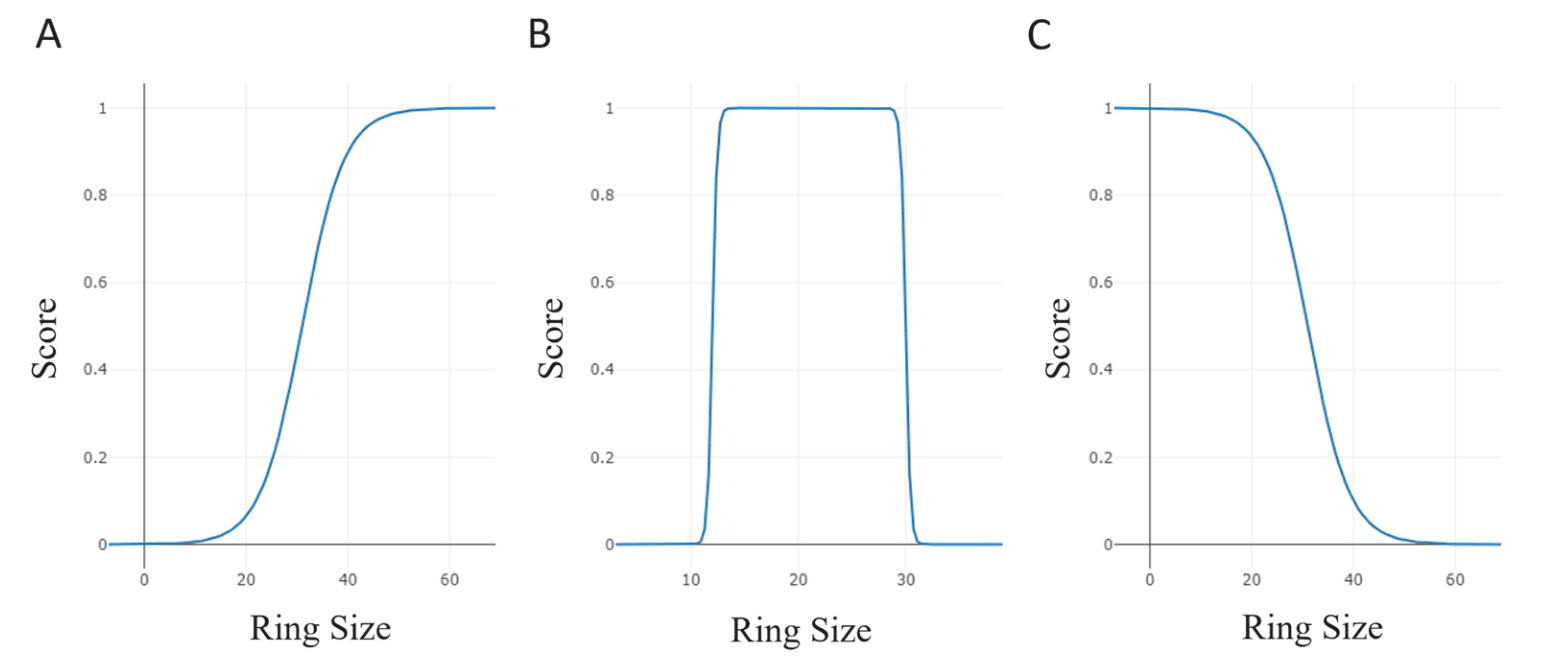
图4|用于环大小评分的分数变换。 (A) Sigmoid函数拟合于[0, 60个原子]区间,用于最大化主要环化的尺寸;(B) 双Sigmoid函数拟合于[0, 30个原子]区间,用于奖励小于或等于给定肽头尾环化尺寸的宏环;(C) 反向Sigmoid函数拟合于[0, 60个原子]区间,用于惩罚宏环生成并促进线性肽的生成。
3 结果
为评估模型的生成性能,研究基于不同测试集进行采样,成功标准定义为生成有效、新颖且多样化的肽。首先通过实验系统性分析了生成肽在氨基酸层面的特征,重点考察其多样性、新颖性以及在生成过程中对肽序列上下文的理解能力,以展示模型在天然氨基酸与NNAAs化学空间中的探索潜力。随后引入强化学习(RL)进行优化,验证了模型既能生成多样化拓扑结构,也能在约束条件下引导生成特定拓扑肽。最后,在多参数优化(MPO)场景中,展示了设计高溶解性与高通透性的环肽的实际应用,凸显了PepINVENT在治疗相关肽优化中的价值。
表1|通过束搜索与多项式采样方法生成肽的有效性与唯一性。 所报告的评估指标进一步按照肽的拓扑结构分类,并以400条测试肽的平均值(±标准差)形式呈现。

3.1 生成模型评估
在第10个epoch时,训练与验证损失曲线均已趋于平稳,避免了过拟合,因此选择该模型进行评估。结果显示:
在有效性与唯一性方面,两种采样方法(束搜索与多项式采样)均能几乎完全满足任务目标,生成的肽分子有效率极高,失败率不足0.3%。不同拓扑类型中,侧链-尾部环化肽的有效性略低,但整体仍保持在高水平。束搜索生成的序列具确定性,但模型仍能确保>99%的化学唯一性;多项式采样同样表现良好,但在非线性拓扑中波动更大,尤其是二硫键环化肽因训练集中硫元素样本有限而更难多样化。
在氨基酸层面的唯一性、新颖性与多样性方面,模型在字符串、同分异构SMILES及规范化SMILES三个层面均表现稳定。去除手性信息后唯一性有所下降,说明立体化学修饰是提升多样性的重要因素。多项式采样显著优于束搜索,能生成超过1400种独特氨基酸,而束搜索约为200种。这意味着多项式采样在化学空间探索上更具广度。总体而言,模型平均实现了**相当于天然氨基酸集合10倍(束搜索)和70倍(多项式采样)**的化学空间扩展。
在氨基酸类别分布上,模型不仅提出新的NNAAs,也频繁生成训练集中的天然与非天然氨基酸。规范化水平下,非天然氨基酸的比例增加而新颖氨基酸的比例减少,进一步突出了立体化学修饰的贡献。值得注意的是,模型生成的新颖氨基酸数量庞大,单次输入平均可达200种,最高超过1200种。整体来看,模型生成了91,826种新颖氨基酸,并与训练集中天然及非天然氨基酸在化学复杂性指标上表现相似,说明这些新分子确实来源于模型学习到的化学空间。
在验证模型能够生成正确数量且有效、新颖的氨基酸后,进一步测试其对肽拓扑结构的理解能力。结果显示,即便输入的肽拓扑信息不完整,模型的有效性并未显著下降,仍能生成氨基酸补全所需结构。例如,当输入中包含提示二硫键形成的氨基酸时,模型会自动生成含有硫侧链的残基,并在CHUCKLES表示中加入桥接符号。这表明模型不仅能完成数量匹配任务,还能理解并利用肽的拓扑上下文信息来生成合理的结构。
综上,PepINVENT不仅能够高效生成有效且独特的肽,还显著拓展了氨基酸与肽的化学空间,为探索天然与非天然构建模块提供了强有力的工具。
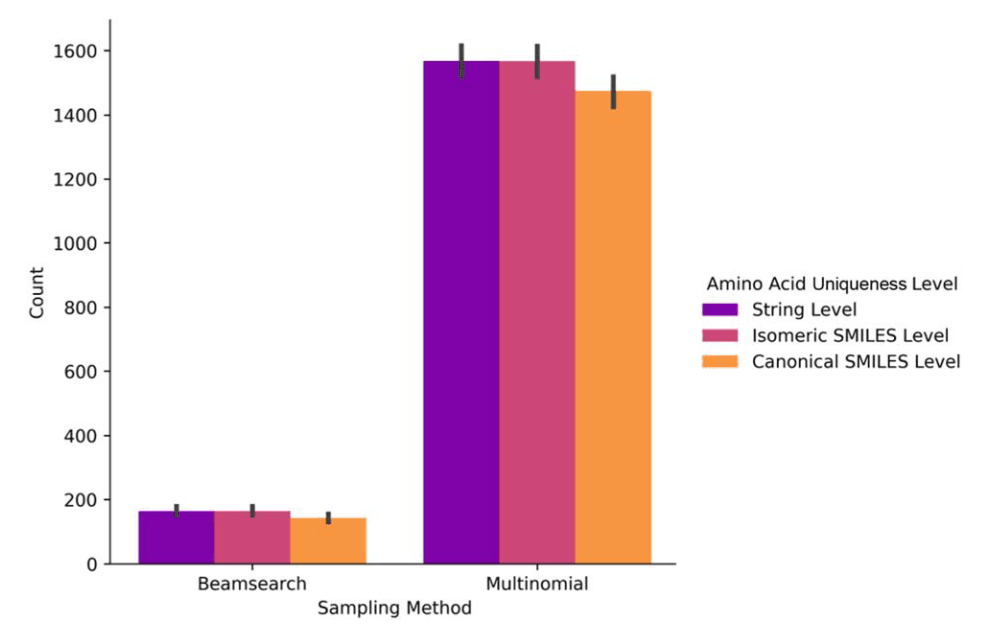
图5|氨基酸唯一性的三个层次。 在测试集的400条肽中,每条肽各采样1000次,分别采用束搜索(beam size=1000)与多项式采样方法。统计得到的唯一氨基酸数量包括所有天然与非天然氨基酸。
3.2 强化学习
在这一部分,研究通过强化学习(RL)展示了PepINVENT在引导肽生成与优化性质方面的能力。
在情景1中,以肽环尺寸为打分指标,通过不同分数变换成功驱动模型生成特定拓扑结构。结果显示,模型能够在不到50步内从探索阶段过渡到目标空间的利用阶段,实现对大环肽、头尾环化肽、线性肽等多样拓扑的灵活生成,并在此过程中保持超过90%的有效性。更为重要的是,模型还生成了双环肽等训练集中未出现过的新型拓扑,体现了对未知化学空间的探索能力。
在情景2中,研究以HIV相关的Rev结合肽(RBP)为案例,利用多参数优化(MPO)策略提升其溶解性和膜通透性。通过在RL环路中整合拓扑约束、通透性预测、溶解性预测及不良子结构惩罚四个打分组件,PepINVENT能够在保持环状结构和生物活性的同时,逐步提升RBP的理化性质。学习过程显示,溶解性优化在前100步内快速完成,而通透性在后续阶段逐渐改善,并在约200步时达到峰值。最终,模型提出了一系列兼具高溶解性与高通透性的宏环肽,其中包括异环骨架引入等常见的渗透性增强策略,且始终保持高生成有效性。
综上,PepINVENT不仅能够通过RL灵活调控肽的拓扑结构,还可在MPO场景下实现药物相关性质的协同优化,展现了在肽类药物设计中的实际应用潜力。
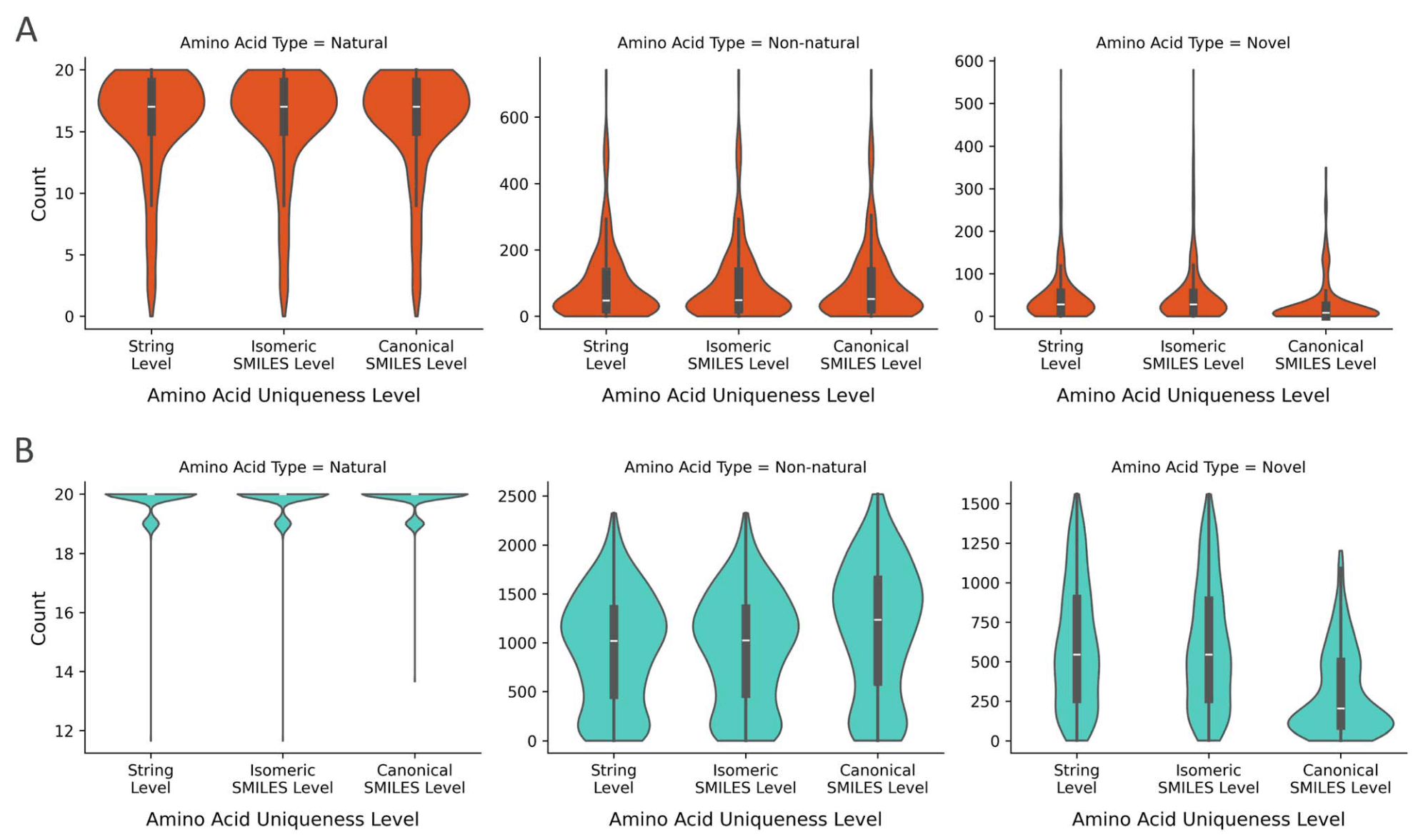
图6|氨基酸唯一性的分布。 展示了三种层次的唯一性在不同类别氨基酸中的分布,包括天然氨基酸、训练集中的非天然氨基酸以及新颖氨基酸。结果分别展示了(A) 束搜索输出与(B) 多项式采样输出的分布情况。
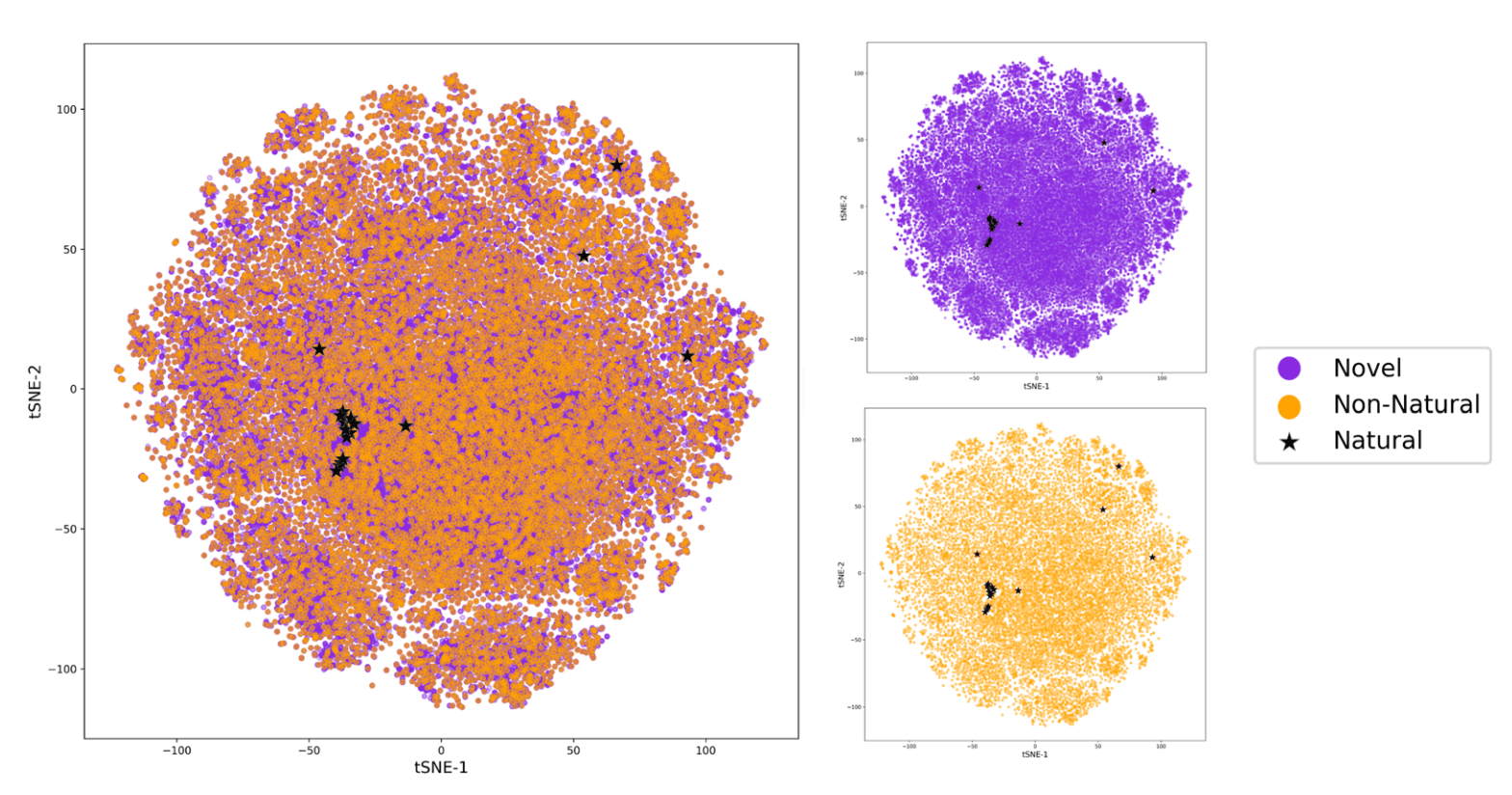
图7|氨基酸化学空间的可视化。 采用t-SNE降维方法绘制,不同类别的氨基酸以颜色区分,包括天然氨基酸、训练集中的非天然氨基酸以及新颖氨基酸。图中还分别展示了约9.2万种新颖NNAAs与训练集中的1万种NNAAs的化学空间分布,均在采样中被恢复,以突出不同类别氨基酸之间的重叠趋势。
表2|生成肽的有效性百分比。 针对不同拓扑类型及整体测试集,报告了三次独立运行中的平均值与标准差。

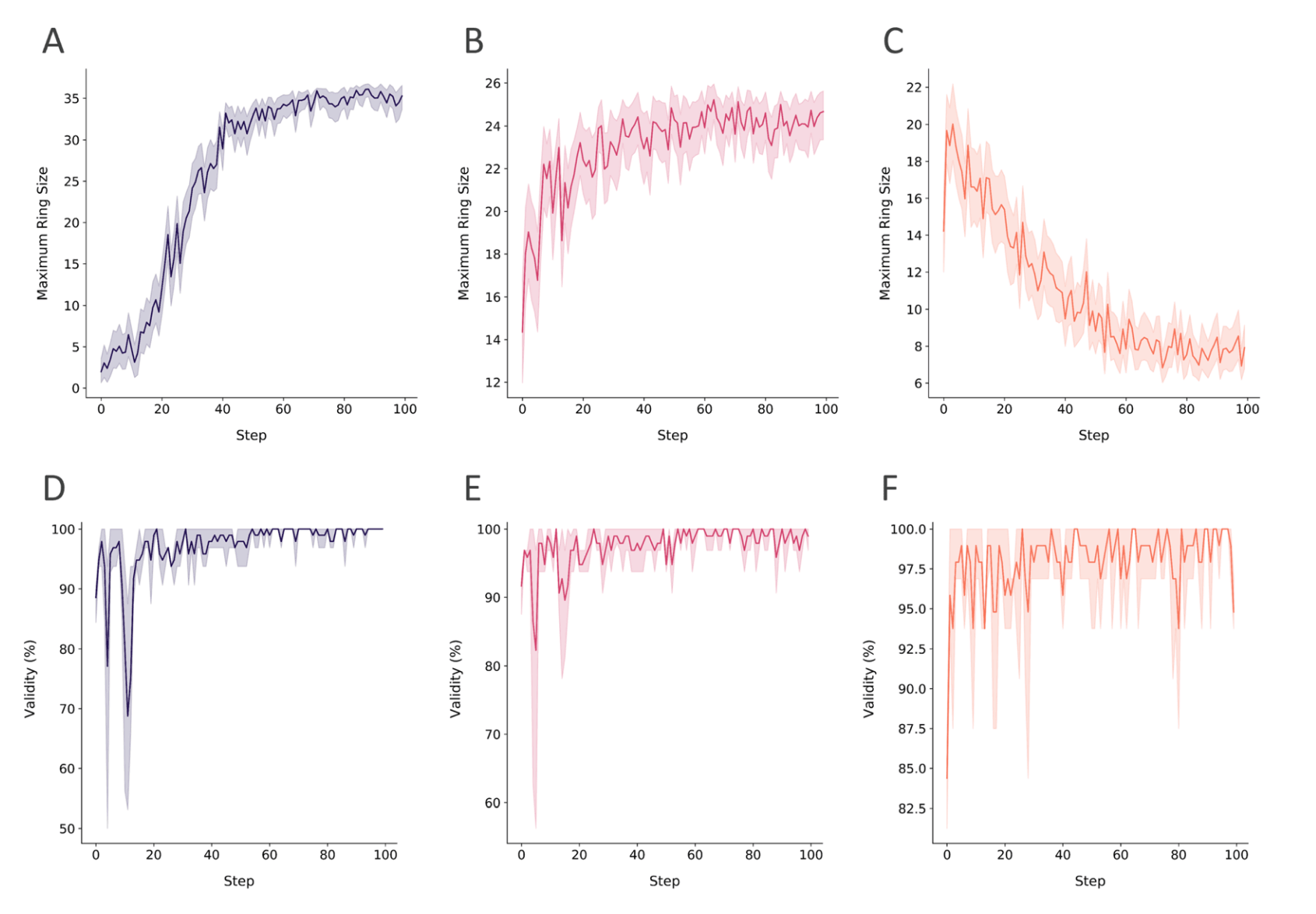
图8|强化学习(RL)运行过程中最大环大小的评分组件与有效性表现。(A–C) 展示了在不同RL目标下(最大化环大小——紫色;限制环大小的宏环——红色;最小化环大小生成线性肽——橙色)随学习步数变化的平均环大小,误差区间为95%置信区间。(D–F) 展示了相应条件下生成肽的有效性百分比随学习步数的变化。
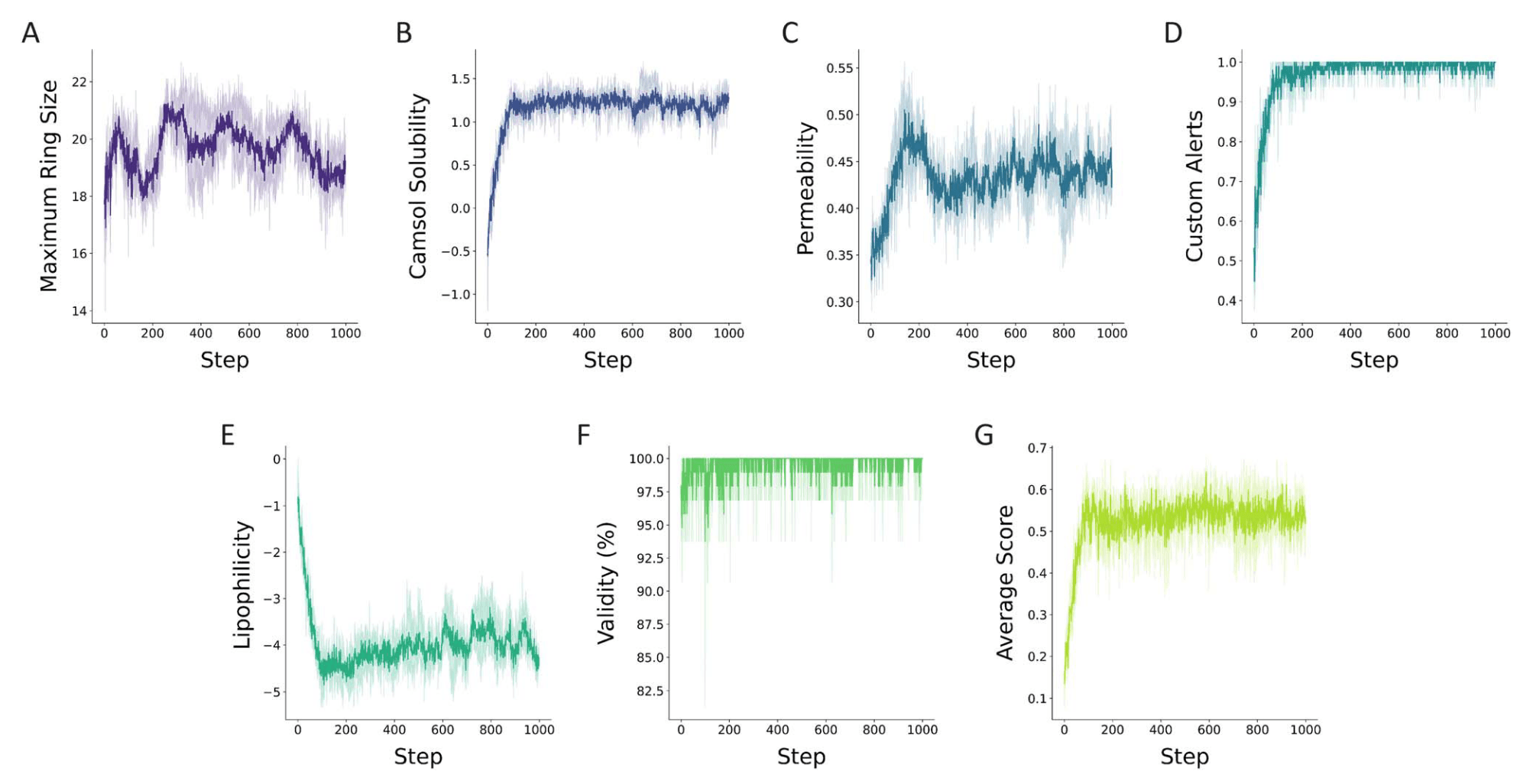
图9|在RL运行中设计可溶且可透的环状Rev结合肽时,多参数优化(MPO)任务的打分组件变化。(A) 拓扑约束(生成宏环肽),(B) 通过CAMSOL-PTM预测的内在溶解性,(C) 通过分类器评估的肽被动通透性,(D) 对潜在毒性相关不良子结构的惩罚。此外,还跟踪了(E) 脂溶性(log P),(F) 有效性,以及(G) 各批次的聚合得分平均值。图中展示了三次独立运行的平均结果,单次运行详见ESI图7。
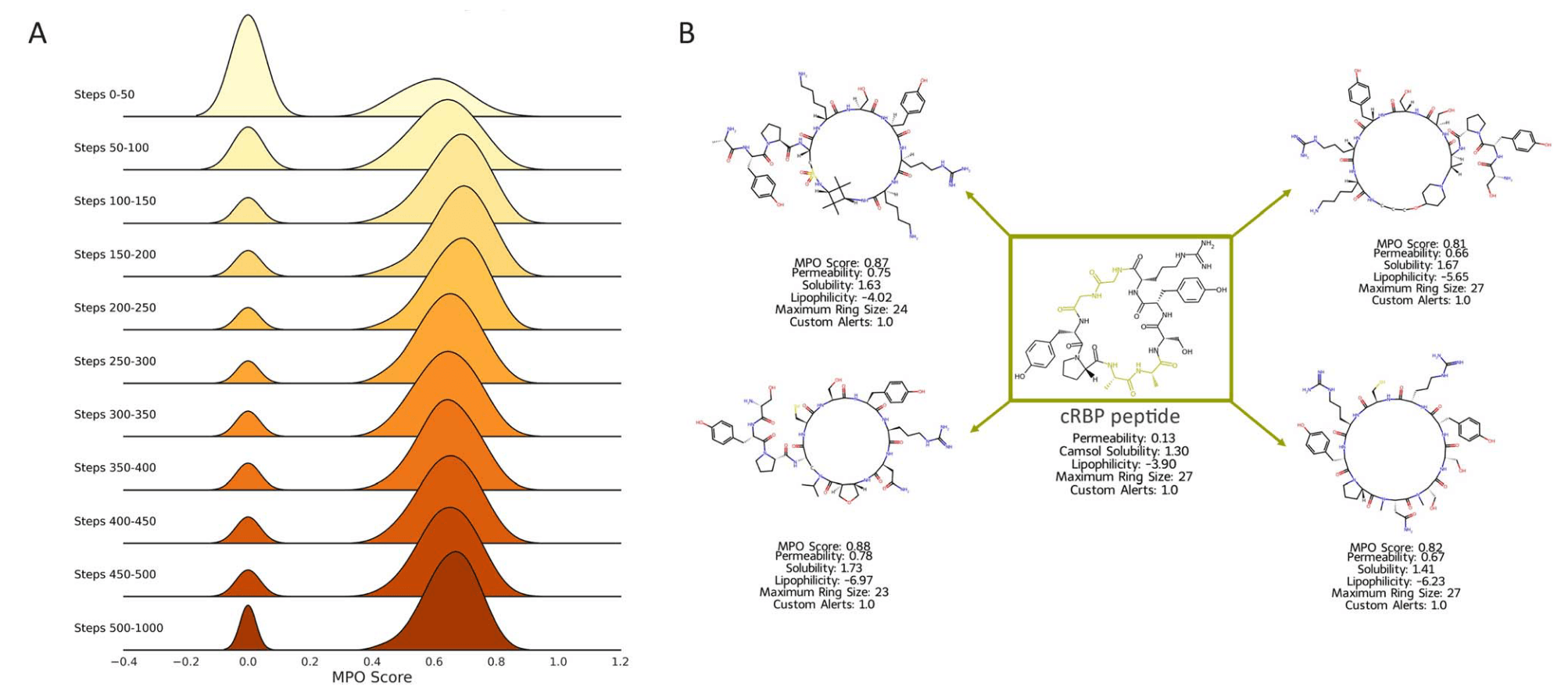
图10|MPO结果可视化。(A) 山脊图显示了前500步中以50步为区间的MPO得分分布及后续学习过程,表明在前200步模型聚焦于具备目标性质的肽,随后扩展探索化学空间。共生成5146、534和1条宏环肽,分别对应通透性得分高于0.6、0.7和0.8,且无不良子结构。(B) 展示了部分生成肽及其MPO打分结果。绿色框内为输入肽cRBP,绿色标注的氨基酸为被掩码的位置。
4 讨论
该研究提出的PepINVENT是REINVENT平台的扩展版本,基于transformer架构的生成模型,能够通过文本填充方式在肽序列中生成天然或非天然氨基酸,从而实现化学感知的设计。不同于以往仅依赖有限氨基酸集合的生成方法,PepINVENT在原子层级上实现了新侧链设计、主链修饰及立体化学突变的可能性,显著拓展了肽类药物的潜在空间。
为解决公开数据稀缺的问题,模型训练基于半合成肽数据,涵盖天然氨基酸与虚拟库中可合成的NNAAs,并通过CHUCKLES表示法确保化学上下文与序列方向性。结果显示,PepINVENT能够生成有效、独特且多样的肽,并提出超越训练集的全新NNAAs。
通过实验验证,PepINVENT在拓扑约束优化与多参数优化(MPO)场景中均展现出高度灵活性。其一,借助环大小这一简单的物化指标,模型能在不到50步的强化学习中收敛到目标拓扑,并生成包括双环肽在内的全新结构。其二,在HIV相关Rev结合肽(RBP)的案例中,模型在保持药效基团不变的前提下,提出了兼具溶解性与通透性的新型环肽设计,成功平衡了多个性质间的权衡。
PepINVENT在实验中始终维持超过90%的有效性,避免生成不合理模式,表明其在探索化学空间时兼具可靠性与创造性。该工具不仅可用于肽性质提升、拟肽设计和先导优化,还能作为开放源代码平台支持多样化的药物研发任务。未来的研究将进一步验证其在真实药物优化场景中的应用潜力,并扩展打分组件,特别是关于合成可行性的考量。