PNAS 2025 | GeoEvoBuilder: 一种用于高效功能性与热稳定性蛋白设计的深度学习框架
今天介绍的是一项发表于 PNAS 的突破性研究 —— GeoEvoBuilder: 一种用于高效功能性与热稳定性蛋白设计的深度学习框架。传统的蛋白设计往往需要多轮计算与实验迭代才能获得稳定且高活性的变体,而GeoEvoBuilder实现了这一过程的**“零样本学习(zero-shot learning)”革新**。该模型通过将结构驱动的序列设计算法GeoSeqBuilder与蛋白语言模型ESM2相结合,自适应地学习结构–序列–功能之间的复杂关系,从而能够直接生成具备目标活性与稳定性的蛋白序列。研究团队在三种代表性蛋白——绿色荧光蛋白(GFP)、谷胱甘肽过氧化物酶4(GPX4)和二氢叶酸还原酶(DHFR)上进行了实验验证。结果显示,GeoEvoBuilder生成的蛋白不仅能正确折叠,还表现出荧光增强、热稳定性提高及催化效率提升高达20倍等显著优势。晶体结构测定进一步证实了其设计构象的精确性与可行性。GeoEvoBuilder不仅为高通量功能性蛋白设计提供了强大工具,也为理解蛋白序列、结构与功能的进化规律开辟了新的研究方向。

获取详情及资源:
0 摘要
尽管深度学习已显著推动了蛋白质序列与功能设计的发展,但高活性与高稳定性蛋白的工程化改造仍依赖于繁琐的迭代式计算设计与实验验证,这一过程耗时且人力成本高。因此,亟需一种能够直接生成具备目标性质的蛋白序列的新方法。该研究提出的GeoEvoBuilder是一种先进的深度学习框架,能够自适应地融合结构约束与进化信息,实现高效的蛋白序列设计。GeoEvoBuilder能够精确重建功能位点,并生成能够正确折叠、同时具备更高活性与热稳定性的序列。研究者将其应用于绿色荧光蛋白(GFP)、谷胱甘肽过氧化物酶4(GPX4)以及二氢叶酸还原酶(DHFR)的重新设计中,均获得了显著性能提升的变体。其中,最优DHFR变体的催化效率提高约20倍,热稳定性提升10°C。晶体结构测定结果进一步证实,这些设计蛋白能够正确折叠并维持原有构象。此外,对GPX4变体残基动态相关性的分析揭示了远端位点如何调控酶活性的机制。与传统依赖单点突变与多轮实验筛选的设计方式不同,GeoEvoBuilder能够在单次运行中探索广阔的序列空间,并成功生成超过30%残基变化的功能性蛋白。总体而言,GeoEvoBuilder不仅是一种突破性的蛋白工程工具,还能为理解蛋白序列、结构、功能与进化之间的复杂关系提供新视角。
1 引言
蛋白设计的终极目标是创造能够执行特定功能的全新蛋白序列。近年来,无论是针对已知蛋白结构的de novo序列设计,还是全新结构的设计,都取得了显著进展。例如,ProteinMPNN通过消息传递神经网络(Message Passing Neural Network)从已知蛋白的三维结构与对应序列中学习,能够生成与目标结构兼容的蛋白序列;ABACUS-R与ProDesign-LE利用图Transformer网络迭代生成符合给定主链的序列;研究团队此前开发的GeoSeqBuilder则采用多尺度图网络(multiscale graph network),能够同时生成序列并高精度预测其侧链构象;而RFdiffusion与Chroma等扩散模型则可生成高置信度的全新蛋白骨架结构。
尽管这些方法在蛋白结合体设计和de novo酶设计中取得了突破,但设计高活性酶仍极具挑战,实际中仅约1%的突变是有益的,这在庞大的序列空间中比例极小。近期,Sumida等人尝试使用ProteinMPNN设计TEV蛋白酶以提升其活性,即使固定活性位点并允许其他位置突变,生成的序列仍全部失活,只有在额外固定部分保守残基后才恢复活性。该研究表明,在基于结构的深度学习序列生成模型中,进化信息对于改造天然酶至关重要。
与此同时,蛋白语言模型(PLMs)的兴起为序列建模带来了新机遇。此类模型在大规模蛋白序列数据上训练,能够捕捉序列语法与进化规律。例如,基于ESM2的ESMFold在蛋白结构预测中表现可媲美AlphaFold2。更重要的是,PLMs不仅能用于结构预测,还可广泛应用于性质预测与功能设计。通过利用PLMs中蕴含的进化知识,研究者能够借助主动学习或少样本学习显著提升蛋白的功能优化效率。
将结构信息与PLM知识相结合,被认为是提升功能蛋白设计成功率的关键。传统结构驱动的设计方法通常能获得高热稳定性蛋白,但容易忽视保守功能信息。近期的COMPSS通过多轮基于多序列比对与结构设计的联合打分提升了酶设计成功率,而InstructPLM则引入自适应注意力机制整合结构与语言模型信息,在两种酶上取得实验验证。此外,新一代模型ESM3通过联合学习序列与结构信息进一步提升性能。然而,这些方法仍需多轮实验与主动学习才能获得高稳定性与高活性蛋白。
为实现零样本学习(zero-shot learning)下直接生成具备高活性与热稳定性的蛋白,研究团队开发了GeoEvoBuilder。该框架整合了结构驱动的序列设计算法GeoSeqBuilder与语言模型ESM2,可自适应学习两者的权重,从而实现高效的功能性蛋白生成。GeoEvoBuilder在大规模测试集中实现了57%的序列恢复率,并能准确回忆功能残基。
实验结果进一步验证了其性能:GeoEvoBuilder在三类蛋白(绿色荧光蛋白、GPX4和DHFR)上的设计成功率均显著优于现有主流方法,所生成序列在酶活性、熔解温度(Tₘ)及荧光强度上均明显提升。多组高分辨率晶体结构解析证实,模型生成的蛋白与设计构象高度一致。值得注意的是,GeoEvoBuilder生成的功能性序列中超过30%的残基被替换,这一特征为理解蛋白序列–结构–功能–进化关系提供了新的研究线索。
综上,GeoEvoBuilder实现了无需温度或活性指导信息的零样本学习,可同时提升蛋白的热稳定性与功能活性,展示了其在高效功能性蛋白设计中的广泛适用性与突破性潜力。
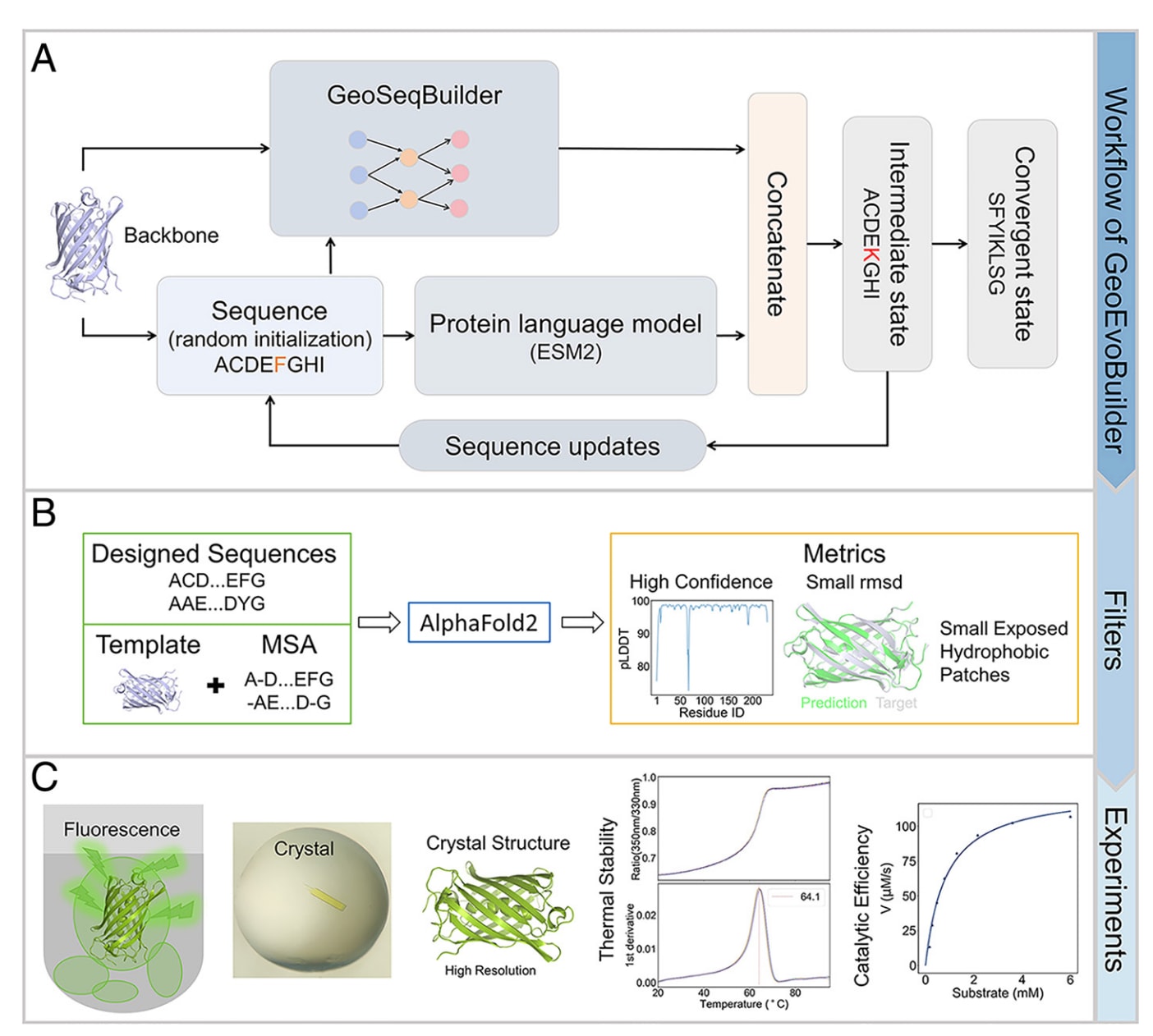
图1|GeoEvoBuilder功能性蛋白序列生成模型概览 (A) GeoEvoBuilder的核心机制:模型通过整合GeoSeqBuilder与ESM2的信息,实现序列的迭代式生成。GeoSeqBuilder用于提取给定蛋白主链的结构特征信息,以增强生成序列的折叠能力;ESM2则提供进化信息,以维持蛋白的功能特性。(B) 结构预测与筛选:利用AlphaFold2 (AF2)对生成序列进行结构预测与质量评估,并据此选择高置信度序列。(C) 功能验证与表征:对筛选得到的设计序列进行多种功能性质实验验证与活性表征,以评估模型生成蛋白的实际性能。
2 结果
2.1 GeoEvoBuilder的工作流程
GeoEvoBuilder由三大模块组成:GeoSeqBuilder、ESM2与自适应拼接模块。其中,GeoSeqBuilder是一个结构编码模块,用于学习蛋白主链(backbone)与序列之间的兼容性;ESM2模块提供目标蛋白的序列进化信息;而自适应拼接模块是一个多层感知机(MLP),用于学习结构信息与进化信息的联合分布。
换言之,MLP层通过梯度下降训练,能够自适应地重新加权不同嵌入特征的权重,以解决结构模块与进化信息之间的潜在冲突,从而在特定输入模式下优先依赖更可靠的模型。这一机制由交叉熵损失函数驱动,通过在结构与进化嵌入的信息流之间实现平衡,近似联合分布,从而形成一种可学习的“共识机制”。
为了使主链中每个氨基酸位点达到最优状态,GeoEvoBuilder采用迭代优化策略,持续更新非最优残基类型,直到所有位点收敛。模型的整体工作流程如图1A所示。
在进入实验验证阶段(图1C)之前,生成的序列会通过AlphaFold2(AF2)进行结构预测与质量评估。评估过程中,AF2同时使用父结构模板和多序列比对(MSA)信息。MSA由HHblits在UniRef30_2023数据库中以父序列为查询序列进行搜索(详见附录)。由于AF2在缺乏MSA输入时无法生成高置信度模型,这些步骤至关重要。
最终,模型基于两个关键指标筛选出高置信候选序列:其一是pLDDT评分,其二是预测结构与模板结构之间的Cα RMSD值。此外,若候选序列在表面存在大面积暴露疏水斑块(定义为≥3个疏水残基在表面聚集),则会被过滤,以降低蛋白聚集风险(图1B)。
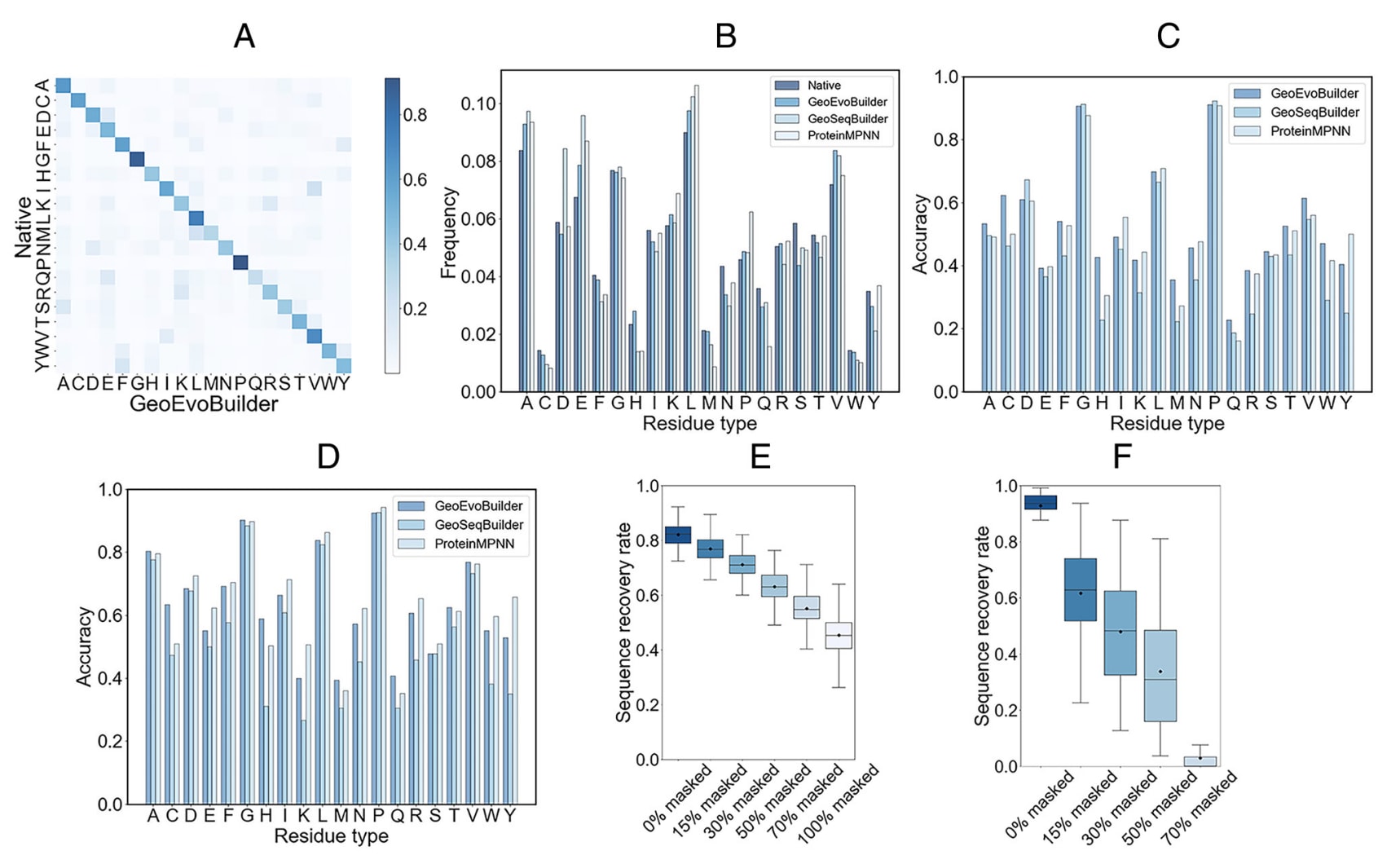
图2|GeoEvoBuilder在TS1000与CAMEO41数据集上的性能表现 (A) 各类型氨基酸残基的整体恢复率概览。(B) 预测残基与天然残基分布的对比分析。(C) loop区域中残基的预测准确率。(D) **埋藏残基(buried residues)**的预测准确率。(E) GeoEvoBuilder在不同初始序列设置下于CAMEO41数据集中的序列恢复率。(F) ESM2在相同条件下的序列恢复率对比。
2.2 GeoEvoBuilder的性能表现
GeoEvoBuilder在与GeoSeqBuilder相同的数据集上进行了训练。具体而言,研究使用CATH4.3数据库中的24,000个单链蛋白对模型进行训练,并采用1,000个蛋白样本(TS1000)进行性能评估。结果显示,GeoEvoBuilder的总体序列恢复率达57.07%,较GeoSeqBuilder提升约5%。混淆矩阵(图2A)显示,大多数残基分布在对角线上,说明模型预测结果质量较高。部分残基被替换为理化性质相似的氨基酸类型,表明模型在保持化学合理性的前提下生成了准确预测。
进一步地,研究分析了模型生成的各类残基分布与天然分布的差异(图2B)。结果发现,GeoEvoBuilder生成分布与天然分布的偏差显著小于GeoSeqBuilder,尤其在Cys、His、Asp与Glu等关键残基上表现尤为明显。已有研究指出,酶的活性位点残基组成通常与整体蛋白的残基分布差异较大。例如,His在酶活性位点中的比例可高达18%,而其在整体序列中的平均比例仅约2.7%。GeoEvoBuilder相比GeoSeqBuilder与ProteinMPNN预测出了更高比例的His残基,说明模型在捕捉功能性位点特征方面表现更优。
由于约50%的活性位点位于loop区域,而在整体蛋白中该比例仅约30%,研究进一步计算了GeoEvoBuilder在loop区域的残基预测准确率(图2C)。结果显示,GeoEvoBuilder在几乎所有残基类型上的准确率均优于GeoSeqBuilder与ProteinMPNN。这可能是因为后两者仅基于结构数据训练,倾向于生成热稳定性高但忽视功能性残基的序列。螺旋与延伸区域的预测准确度见补充图S3。
此外,GeoSeqBuilder倾向于在蛋白核心区域仅生成疏水残基,而天然蛋白的核心区域通常还存在少量极性残基,用于形成稳定的氢键网络。为验证GeoEvoBuilder是否也存在这一偏差,研究计算了其对埋藏残基的预测准确率。结果显示,GeoEvoBuilder在埋藏区域的预测更为精确,尤其在功能性较强的极性残基(Cys、Arg、Trp等)上表现突出(图2D)。除个别残基外(如Cys与His),ProteinMPNN在埋藏区域的预测略优于GeoEvoBuilder。
由于ESM2在训练中采用随机掩盖15%的残基并进行恢复的方式,因此理论上也可用于迭代式蛋白序列设计。为了探究ESM2在GeoEvoBuilder性能中的贡献,特别是其对功能位点生成的影响,研究在CAMEO41数据集上进行了测试。该数据集包含2022年12月9日至2023年6月3日期间发布的41个蛋白目标。
对于每个蛋白目标,研究分别随机掩盖**100%、70%、50%、30%、15%和0%**的天然序列残基,并在每种条件下生成10条序列。由于ESM2并不知道输入序列是否与天然序列相同(即0%掩盖),因此研究计算了生成序列与天然序列之间的序列一致性。结果符合预期——掩盖比例越高,生成序列与天然序列的一致性越低。
对于GeoEvoBuilder,其序列恢复率从82.11%(0%掩盖)下降至45.39%(100%掩盖)(图2E);而ESM2仅在保留**≥70%的原始残基时才能有效恢复天然序列,且不同目标间的方差更大(图2F)。进一步通过ESMFold**预测这些序列的结构,发现随着掩盖比例增加,ESM2生成的序列逐渐无法折叠成正确的目标结构(补充图S4)。
这些结果表明,结构模块在GeoEvoBuilder中起到关键的引导作用,确保生成的序列与目标结构兼容;而ESM2模块则在中间序列逐渐接近目标时发挥进化优化的功能性作用。
总体而言,GeoEvoBuilder通过结构信息与进化信息的自适应整合,显著提升了序列恢复率、功能位点捕捉能力与理化一致性,为高精度功能性蛋白生成与零样本设计提供了强有力的模型框架。
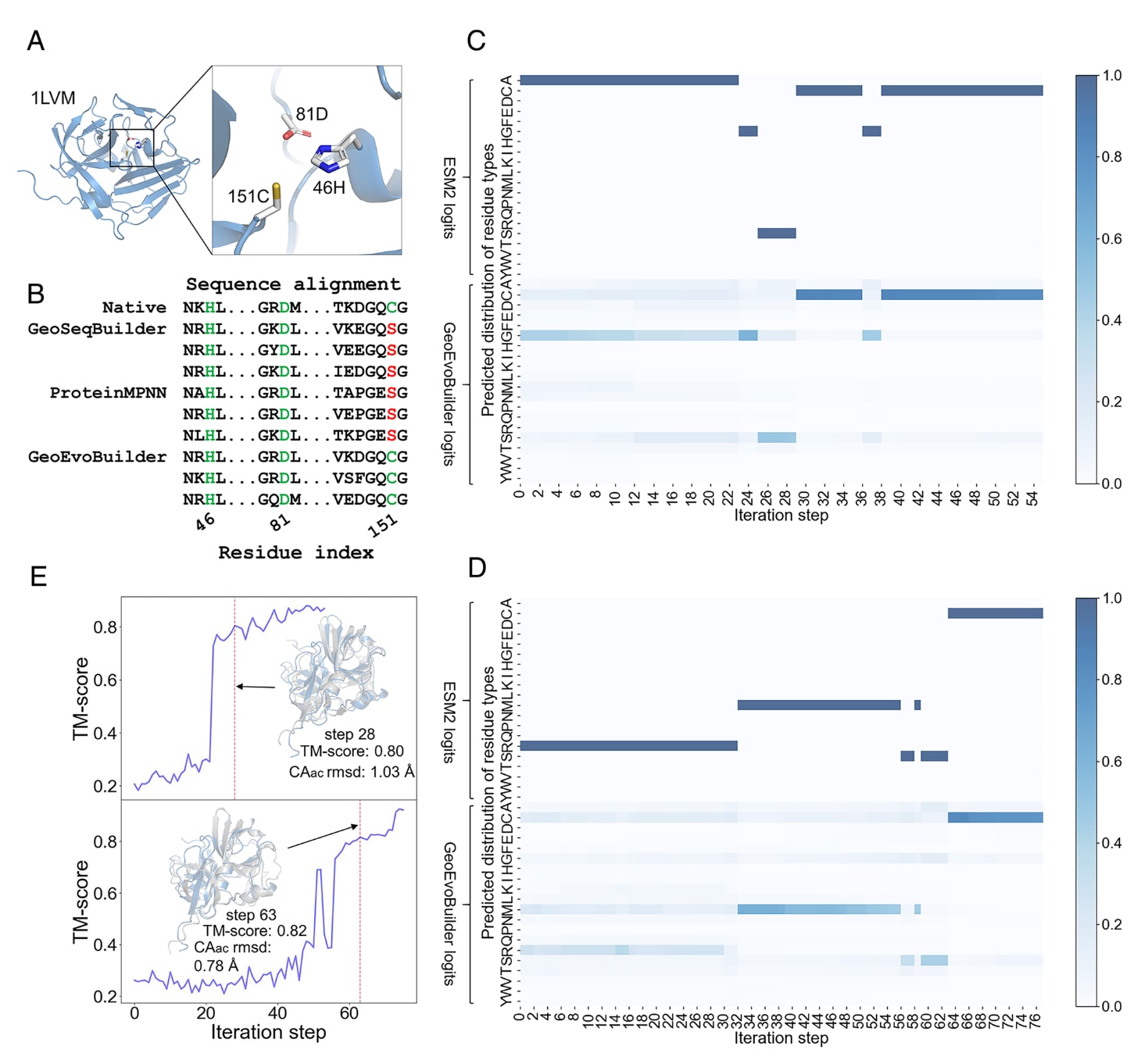
图3|GeoEvoBuilder学习恢复功能位点的过程 (A) TEV蛋白酶的催化活性位点示意图。(B) GeoEvoBuilder在最终设计阶段成功恢复催化残基151C,而基于结构的GeoSeqBuilder与ProteinMPNN均未能回忆该关键位点。(C) 与(D) 展示了GeoEvoBuilder在两种不同初始条件下恢复催化残基151C的动态过程:分别从随机掩盖50%天然序列与完全随机初始化开始。前20行表示来自GeoEvoBuilder中嵌入ESM2的logits残基类型分布,后20行为GeoEvoBuilder模型预测的残基类型分布。(E) 上、下两部分分别对应(C)与(D)中的中间序列,其预测结构的TM-score变化反映了折叠收敛过程。可见,在第28步(上方)与第63步(下方)时,预测结构已与野生型高度相似,尽管此时功能位点151C尚未恢复。这进一步说明,结构模块GeoSeqBuilder在保持蛋白骨架结构中发挥关键作用。其中“Cα rmsd”表示活性位点区域的Cα原子均方根偏差。
2.3 GeoEvoBuilder对酶功能位点的回忆能力
研究表明,GeoEvoBuilder在广泛参与蛋白功能的残基上具有较高的恢复率。接下来,以TEV蛋白酶为例,分析模型中的拼接模块如何自适应地调整权重,实现从“序列–结构一致性”到“序列–结构–功能一致性”的平衡。TEV蛋白酶源自烟草蚀纹病毒,常用于切割多肽识别序列Glu–Xaa–Xaa–Tyr–Xaa–Gln–|–(Ser或Gly),其催化活性位点主要包含三个关键残基:46H、81D与151C(图3A)。
研究利用GeoEvoBuilder对TEV蛋白酶结构[PDB编号:1LVM]进行随机初始化的序列设计,以测试模型是否能够自动生成正确的功能位点。作为对照,GeoSeqBuilder与ProteinMPNN也被用于同样的设计任务。结果显示,三种模型均能恢复其中两个催化残基(46H与81D),但仅有GeoEvoBuilder成功恢复第三个关键残基151C(图3B),这充分证明了其在功能性蛋白设计中的独特优势。
进一步地,研究跟踪了GeoEvoBuilder在序列生成迭代过程中对151C残基的恢复过程。结果显示,当从随机掩盖50%的天然序列及完全随机初始化两种条件出发时,GeoEvoBuilder分别在第29步与第64步成功恢复出151C残基(图3C、D)。
随后,对每一迭代步骤生成的序列进行了结构预测(图3E)。结果表明,在151位残基类型正确出现之前,模型已先生成与目标结构高度相似的折叠模型(TM-score约为0.8)。在经过数十轮迭代后,模型逐步生成与目标蛋白结构相似的序列,并在此基础上进一步形成正确的催化残基。
这一结果揭示,GeoEvoBuilder能够通过结构驱动与进化约束的协同作用,先捕捉正确的折叠模式,再逐步优化至具有催化功能的活性位点,展现出其在功能性酶设计中的智能演化能力与化学合理性。
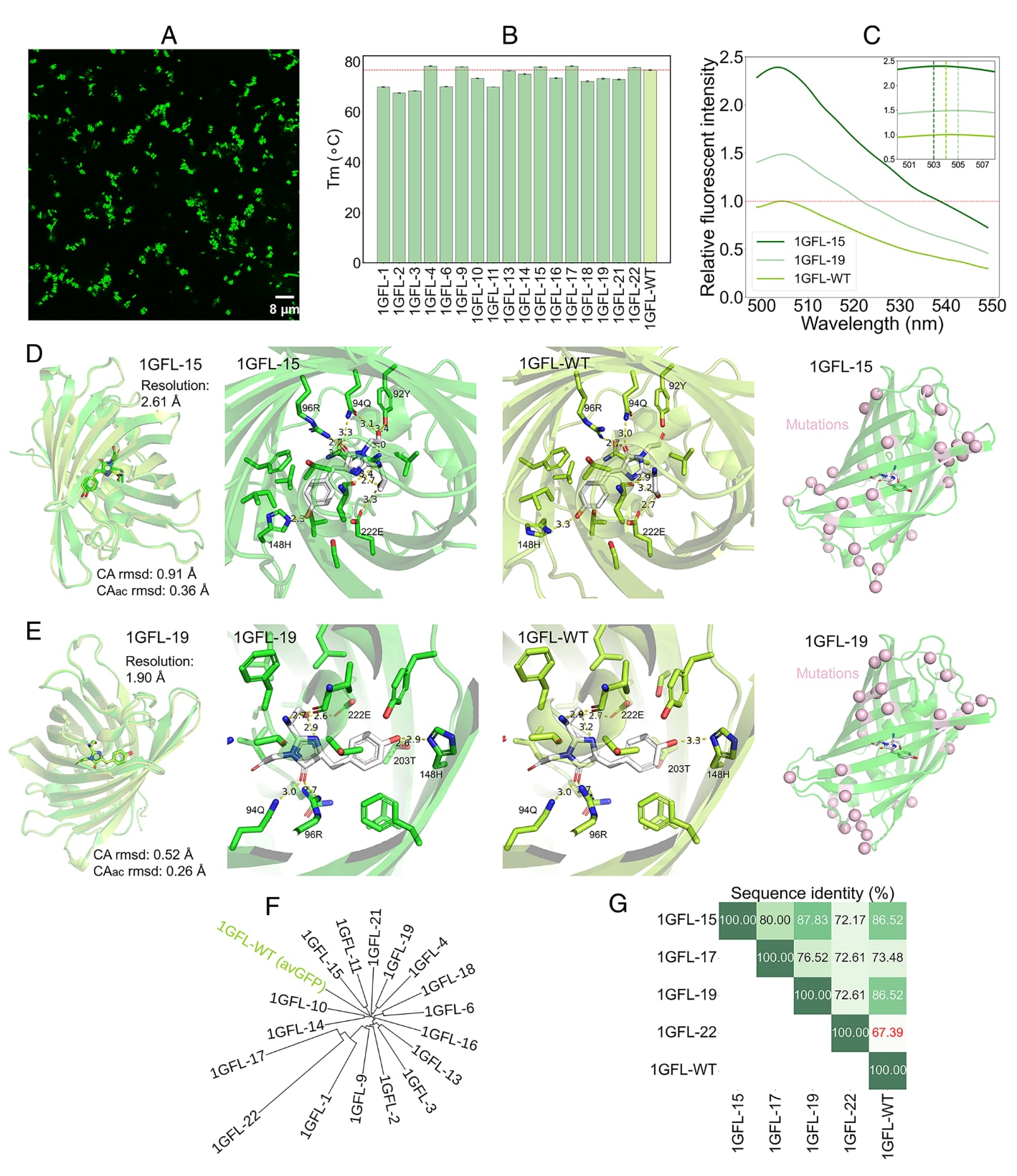
图4|GeoEvoBuilder成功设计出具有荧光活性的GFP目标蛋白序列 (A) 共聚焦显微镜下活体大肠杆菌中表达的设计蛋白1GFL-15的荧光成像图像,显示其强烈的绿色荧光信号。(B) 热稳定性测定结果:通过监测荧光变化评估设计蛋白与野生型GFP的熔解温度(Tm)。(C) 荧光强度对比图:在470 nm激发条件下,比较设计蛋白与野生型GFP在发射峰(emission maxima)处的荧光强度。(D) 与 (E):从左至右依次展示——① 解析晶体结构与野生型GFP的叠合图;② 设计蛋白与野生型的发色团(Chromophore)微环境细节对比;③ 突变位点在三维结构中的分布情况。(F) 系统发育树(phylogenetic tree)分析:展示设计序列间的进化关系及其与野生型的差异。(G) 序列多样性矩阵(sequence diversity matrix):展示多条与野生型显著不同的设计序列间的相似性关系。
2.4 三种蛋白靶点的实验验证
为进一步验证GeoEvoBuilder的性能,研究团队选择了三种具有代表性的蛋白进行序列再设计与实验验证,包括绿色荧光蛋白(GFP)、谷胱甘肽过氧化物酶4(GPX4)与二氢叶酸还原酶(DHFR)。
GFP是一种可自催化形成荧光发色团的蛋白(56),通过重新设计其序列有望改善荧光性质。GPX4是一种在抗氧化应激防护中起关键作用的酶(57),同时也参与细胞凋亡、铁死亡与脂质代谢等生命过程(58)。提升GPX4的催化活性具有潜在的医学应用,可用于清除过量过氧化物。DHFR可利用NADPH将二氢叶酸还原为四氢叶酸,其**蛋白片段互补实验(PCA)**被广泛用于研究蛋白–蛋白相互作用及高通量筛选(59)。
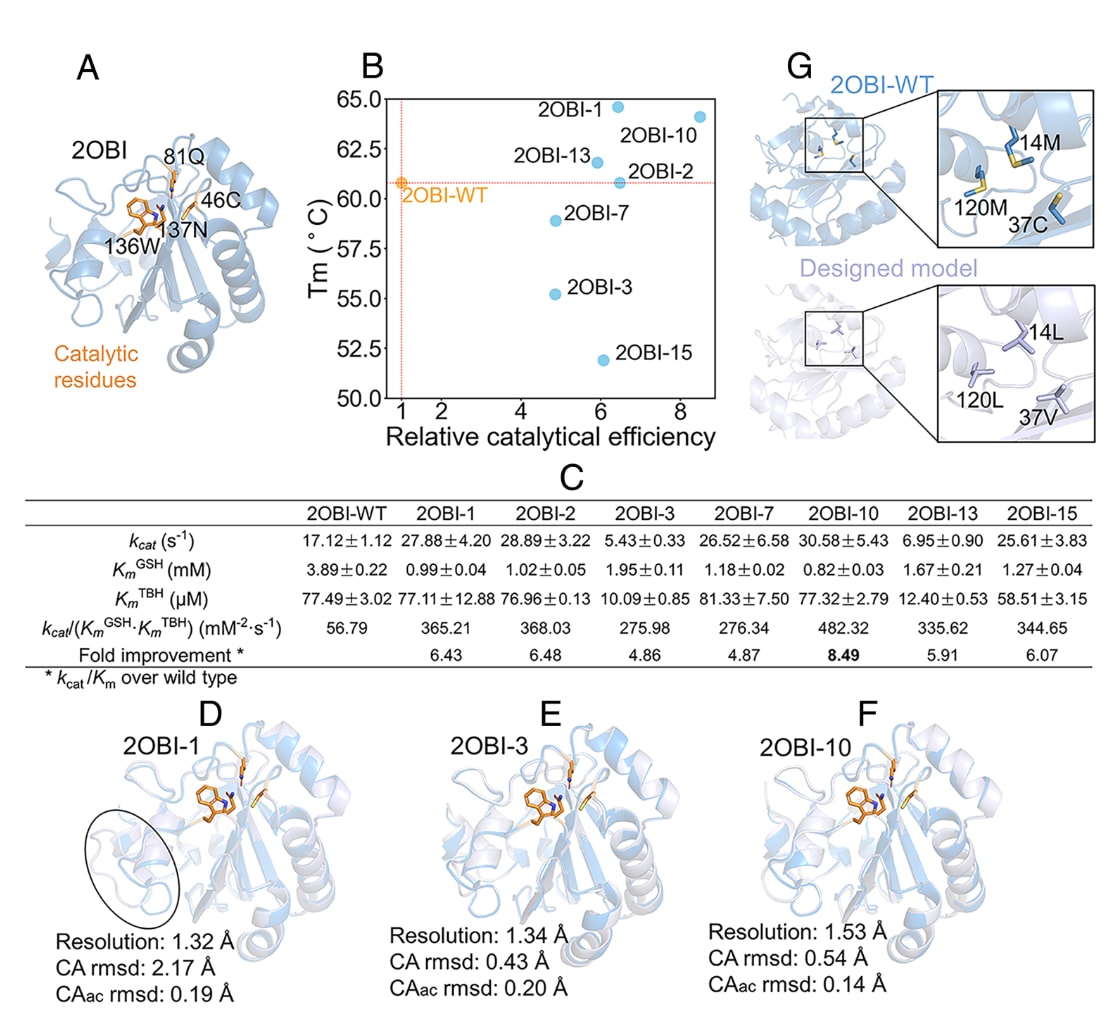
图5|GeoEvoBuilder成功设计出具有功能活性的GPX4序列 (A) 用于序列设计的GPX4结构模板。(B) 催化活性与热稳定性(Tm)之间的关系图,展示不同设计蛋白的性能分布。(C) 设计蛋白与野生型GPX4的动力学参数比较,包括催化常数(kcat)、米氏常数(Km)及催化效率(kcat/Km)等。(D–F) 三种设计蛋白解析晶体结构与野生型结构的叠合结果。黑色圆圈标示出loop区域中结构波动较大的区域。(G) 野生型与三种设计蛋白核心区域的比较(右侧为放大图),展示关键残基替换及其对核心构象的影响。
GFP的重新设计与实验验证
研究使用GeoEvoBuilder基于水母来源的原始GFP结构模板(PDB: 1GFL)进行两种设计方案:
(1) 固定发色团8 Å范围内的77个残基,其余位点随机初始化;
(2) 同样固定8 Å范围内的残基,但对初始天然序列随机掩盖50%。
在模型构建时,研究将半径参数由文献中的7 Å扩展至8 Å,以纳入关键的保护性氢键残基(168H、147S、146N),这些残基可能在结构中形成屏障,防止发色团暴露于溶剂。每种策略生成200条序列,并利用AlphaFold2 (AF2)进行结构预测。AF2仅在输入结构模板与多序列比对(MSA)信息时能生成高置信模型,因此研究基于pLDDT ≥ 95和Cα RMSD ≤ 0.6 Å筛选出13与19个候选序列。随后,剔除表面存在≥3个疏水残基聚集的序列,最终从两种策略中分别选取5与17个序列进行基因合成并在大肠杆菌中表达。
荧光显微镜下,大多数菌株呈现绿色荧光(图4A)。SDS-PAGE分析显示,22个过表达蛋白中有20个可溶,仅有1GFL-8形成包涵体,1GFL-7未检测到表达信号。17个设计蛋白的上清液均显示出显著荧光信号。通过监测荧光强度随温度变化测得熔解温度(Tₘ),结果显示野生型GFP的Tₘ为76.6 °C(与文献值76 °C一致),而设计蛋白的Tₘ分布于67.5–78.3 °C之间(图4B)。
进一步纯化表达量较高的1GFL-15与1GFL-19进行结构与光谱分析。两者在凝胶过滤柱上的洗脱峰与野生型相近,表明为单一均一状态。光谱测试结果显示,1GFL-15的激发波长红移至470 nm(野生型为395 nm),其荧光强度与野生型相当(分别为0.94与0.80倍)。红移的激发峰有利于活细胞成像,可减少背景干扰与紫外光对细胞的损伤。在470 nm激发下,1GFL-15与1GFL-19的荧光强度为野生型的1.5–2.5倍(图4C),展示了出色的成像优势。
绝对量子产率测定表明,1GFL-15与野生型相当,而1GFL-19约为其1/3。两者与野生型序列同一性分别为86.52%与87.83%。晶体结构解析显示,1GFL-15分辨率为2.61 Å,1GFL-19为1.90 Å(图4D、E),其总体结构与野生型高度一致,Cα RMSD分别为0.91 Å与0.52 Å。
局部结构分析发现,1GFL-15中66Y与148H间的氢键距离更短,1GFL-19中203T与66Y之间形成新的氢键,此外67G的羰基氧与92Y的羟基形成新的氢键。这些微小结构差异可能解释荧光强度变化。核心区域中,169H与177Q被替换为疏水残基169L与177L,有助于减少埋藏不理想氢键,提升稳定性。系统发育树分析(图4F)显示,大多数设计序列与野生型差异显著,例如GFP-22与野生型序列同一性仅67.39%(突变达75个残基),仍保留荧光功能。数据库比对结果表明,这些序列为全新设计结构,未在天然荧光蛋白中出现。
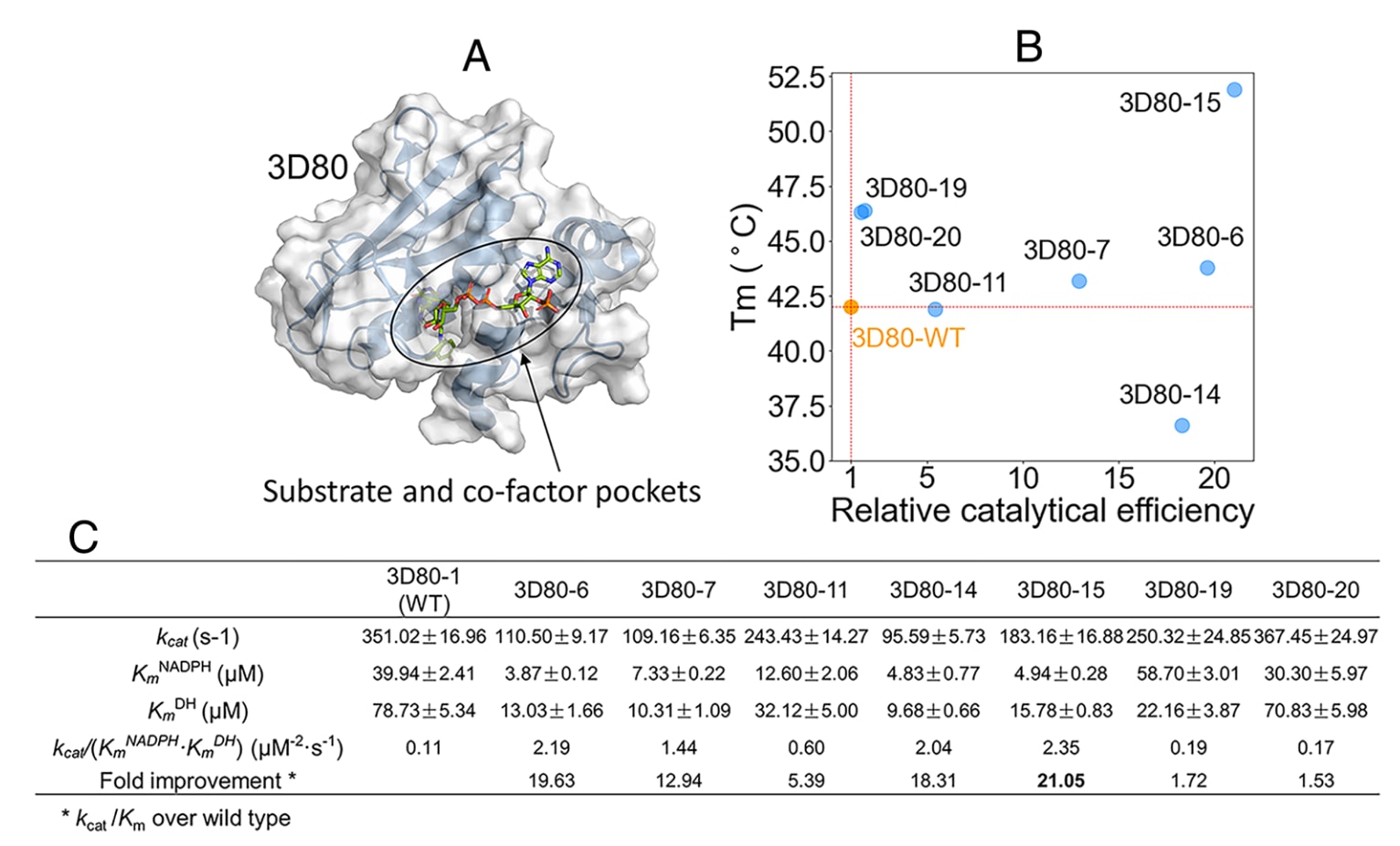
图6|GeoEvoBuilder成功设计出具有功能活性的DHFR序列 (A) 用于DHFR设计的结构模板,展示底物与辅因子结合口袋的位置与构型。(B) 七种纯化DHFR设计蛋白的热稳定性(Tm)与催化活性关系图,显示不同设计蛋白在热稳定性与酶活性之间的协同变化趋势。(C) 所选设计蛋白与野生型DHFR的动力学参数比较,包括催化常数(kcat)、米氏常数(Km)及整体催化效率(kcat/Km),揭示GeoEvoBuilder生成的DHFR变体在酶学性能上的显著提升。
GPX4的重新设计与验证
使用GPX4的晶体结构模板(PDB: 2OBI),研究采用与GFP类似的两种方案:
(1) 固定距催化位点7 Å内的47个残基并随机初始化;
(2) 同样固定催化位点邻域,但对天然序列随机掩盖50%。
每种方案生成200条序列,基于pLDDT ≥ 92、Cα RMSD ≤ 1.5 Å筛选高置信序列并去除疏水暴露候选。最终获得19条高质量设计序列,其中16个成功表达且可溶。粗略酶活性测定显示7个蛋白具明显活性。进一步纯化与热稳定性分析表明,这些设计蛋白的Tₘ分布在53–65 °C之间,其中3个较野生型更稳定(图5B)。
动力学分析显示,最活跃的2OBI-10具有4.74倍更低的GSH结合Km值,其催化效率(kcat/(Km_GSH·Km_TBH))提高8.49倍,同时Tₘ提高3 °C(图5C)。2OBI-10的kcat约为野生型的1.79倍,表明其在低GSH浓度下仍能高效催化。
高分辨率晶体结构显示,2OBI-3与2OBI-10相对野生型的Cα RMSD分别仅为0.43 Å与0.54 Å,而2OBI-1在排除柔性loop区后RMSD仅0.70 Å(图5D–F)。核心残基中,野生型14M、37C、120M被替换为14L、37V与120L(图5G),可能增强稳定性。
分子动力学模拟(200 ns)揭示2OBI-10的残基运动相关性与模块化结构显著不同于野生型与失活变体(2OBI-9)。蛋白网络分析发现,其催化残基所在社群的连接更紧密,且与远端变构位点存在强耦合关系(补充图S17–S18),说明活性提升可能源于变构调控增强。
DHFR的重新设计与验证
鉴于前两项实验中,固定活性口袋并掩盖50%天然序列的方案成功率最高(GFP为15/17,GPX4为6/9),研究采用相同策略对**DHFR(PDB: 3D80)**进行设计。由于其底物与辅因子结合口袋呈长槽形,若设定7 Å半径将导致固定残基过多,因此调整为6 Å半径(可变残基66/186)。
模型生成200条序列,经AF2预测后筛选出26条(pLDDT ≥ 94, RMSD ≤ 1.3 Å),其中23条进入实验验证。PCA初筛显示所有设计蛋白均具活性,其中7个表现高活性并被进一步纯化。所有蛋白在凝胶排阻实验中为单体且均一,其中5个的Tₘ高于野生型(图6B),其中3D80-15的Tₘ提升10 °C。
动力学结果显示,设计蛋白的催化效率提升1.53–21.05倍,其中3D80-15的催化效率提升超过20倍,同时热稳定性提高10 °C(图6C)。
综合三种靶标的实验结果,GeoEvoBuilder生成的蛋白均在活性与稳定性方面显著优于野生型,其设计的结构经晶体学验证与预测模型高度一致。这些结果充分证明,GeoEvoBuilder具备在功能性蛋白设计中直接生成高活性、高稳定性序列的能力,展现出其在深度学习驱动蛋白工程领域的强大潜力与通用性。
3 讨论
深度学习算法为高效学习蛋白序列、结构与功能之间的关系提供了强有力的工具。该研究提出的GeoEvoBuilder算法,通过结合结构编码与蛋白语言模型(PLM)中的序列进化信息,实现了功能性蛋白设计。GeoEvoBuilder在基准数据集上展现出较高的序列恢复率,并在多个实例中成功回忆关键功能位点。实验验证进一步证明,该模型能够在无需微调或多轮迭代优化的情况下,生成多样化的蛋白序列,其表现出更高的热稳定性、更强的GFP荧光强度,以及显著提升的GPX4与DHFR酶活性。这一成果显示,GeoEvoBuilder是一种高效、易用的功能蛋白设计工具。
研究结果表明,将结构驱动的序列设计方法与语言模型学习的进化信息相结合,使功能性蛋白设计过程变得更快速、更智能、更普适。虽然已有多种基于深度学习的蛋白设计工具被开发,但目前的**从头设计酶(de novo enzyme design)通常催化效率不及天然酶。如何满足真实蛋白工程的性能需求仍然是一大挑战。近期的一些工作(45, 47, 48, 67)虽取得积极进展,但普遍依赖多轮实验筛选与主动学习(active learning)**以发现有益突变。而该研究表明,GeoEvoBuilder作为一种零样本学习(zero-shot learning)模型,可在单轮实验中显著提升蛋白的活性与稳定性,从而极大地拓展了传统定向进化方法的探索范围。
GeoEvoBuilder生成的新序列可作为进一步进化优化或组合突变设计的起点,为实现高性能蛋白工程奠定基础。在实验部分,为保持催化功能,研究在GFP、GPX4与DHFR的设计中固定了底物口袋中的第一层残基。随后通过完全随机初始化重新设计GPX4,考察模型在无约束条件下恢复这些关键残基的能力。结果显示,GeoEvoBuilder在47个位点中正确恢复了45个(95.7%)残基,而GeoSeqBuilder与ProteinMPNN的恢复率仅为72.3%与78.7%。该趋势在其他两个靶标(GFP与DHFR)中同样存在,说明ESM2提供的进化信息为几何结构设计带来正交补充维度。
然而,若在完全无约束的条件下进行功能性设计,由于酶与底物关系复杂,成功率可能下降。为此,未来可在模型中引入底物、激活中间态及分子编码信息,并基于蛋白复合物数据进行再训练,以更好地模拟酶–底物作用。
此外,对于稀疏蛋白家族,ESM2中进化信息可能被稀释。研究据此开发了GeoEvoBuilder-MSA网络,将GeoSeqBuilder、ESM2与目标特异的MSA信息自适应融合。该模型充分利用自然同源序列信息,有望在不依赖远程位点数据的情况下达到最优状态。应用GeoEvoBuilder-MSA设计GPX4时,随机初始化并固定关键残基后,共筛选出7条可溶性蛋白,其中4条具有明显酶活性,其催化效率提升约5–7倍,但热稳定性略低于GeoEvoBuilder生成的设计。结果表明,目标特异的MSA信息虽能提高成功率,但会限制序列空间探索,从而降低活性提升幅度。
进一步分析显示,GeoEvoBuilder在训练时并未剔除与目标蛋白同源的序列。为验证潜在影响,研究移除了所有序列同一性≥40%的训练样本并重新训练模型,得到GeoEvoBuilder40。该模型仍能在TEV蛋白酶中正确恢复关键催化位点151C,且在GFP、GPX4与DHFR上的恢复率分别为0.46 vs. 0.45、0.59 vs. 0.60、0.60 vs. 0.61,与原模型几乎一致。使用GeoEvoBuilder40重新设计GPX4后,获得的6条新序列全部具有活性,并多数在热稳定性与催化效率上进一步提升。这说明:
PLM(ESM2)提供的进化信息在功能性设计中至关重要,而过多同源或MSA约束反而会抑制模型的创新潜力。
综上,无论是否包含高同源序列,GeoEvoBuilder及其改进版GeoEvoBuilder40均能生成功能显著提升的蛋白变体,展现出广泛适用性与鲁棒性。值得注意的是,即便训练集中存在同源序列,模型也无需针对新目标重新训练,极大简化了用户的实际应用流程。
4 结论
总体而言,统一深度学习模型GeoEvoBuilder在功能性蛋白设计中展现出卓越能力,能够直接生成高活性、高稳定性的序列。作为一种零样本学习模型,它仅需单轮设计与实验验证即可实现性能提升,大幅减少实验工作量并提高研究效率。除直接应用于蛋白工程外,GeoEvoBuilder还可作为研究蛋白序列–结构–功能–进化关系的重要工具,推动人工智能驱动的分子设计进入更高水平的智能化阶段。