Adv. Sci. 2025 | PROTAC-STAN: 可解释的基于结构信息的深度三元注意力框架用于PROTAC降解预测
今天介绍的是发表在《Advanced Science》上的一项前沿研究——PROTAC-STAN:可解释的基于结构信息的深度三元注意力框架用于PROTAC降解预测。这项工作针对当前PROTAC设计中数据稀缺、结构复杂与模型可解释性不足等关键难题,提出了一种创新性的深度学习框架。PROTAC-STAN通过整合分层分子表示与蛋白结构嵌入,并引入三元注意力机制,在分子亚结构层面显式建模POI、E3连接酶与PROTAC三者间的相互作用,实现了从机制建模到降解预测的端到端可解释学习。研究表明,该模型在多项指标上显著超越现有方法,准确率提升超过10%,并能在原子与残基层面提供直观可视化解释。更重要的是,PROTAC-STAN在不同数据集与真实案例中展现出优异的鲁棒性与泛化能力,为智能化靶向降解药物设计提供了高效、可解释且结构驱动的新思路。

获取详情及资源:
- 📄 论文: https://doi.org/10.1002/advs.202508138
- 📊 数据: http://cadd.zju.edu.cn/protacdb
- 💻 代码: https://github.com/PROTACs/PROTACSTAN
0 摘要
蛋白水解靶向嵌合体(Proteolysis Targeting Chimeras,简称PROTACs)是一类双功能分子配体,能够桥接目标蛋白(Proteins-Of-Interest,POIs)与E3泛素连接酶,从而触发泛素-蛋白酶体途径的降解过程,展现出靶向“不可成药”蛋白的巨大潜力。尽管PROTAC研究在生物医学领域具有突破性意义,但目前仍主要依赖昂贵且耗时的湿实验。近年来,深度学习的引入为加速PROTAC设计与优化、降低研究成本提供了新契机。
然而,现有用于PROTAC降解预测的深度学习方法往往忽视了分子表示的层次性以及蛋白质结构信息的重要性,从而限制了数据建模的精确性。此外,由于多数模型呈现**“黑箱”特征**,难以解释其内部决策过程,研究者无法直观理解PROTAC体系中分子亚结构之间的相互作用机制。
该研究提出了一种可解释的、基于结构信息的深度三元注意力网络框架——PROTAC-STAN(Structure-informed deep Ternary Attention Network),用于精确且可解释的PROTAC降解预测。该模型在原子、分子与性质三个层次上构建PROTAC分子的分层表示,并通过蛋白质语言模型引入POIs与E3连接酶的结构信息。同时,PROTAC-STAN设计了新颖的三元注意力机制,能够在亚结构层面上模拟POI、E3及PROTAC三者间的复杂交互关系,从而为理解PROTAC的降解机制提供前所未有的可视化洞察。
在多项性能指标上,PROTAC-STAN相较于现有最佳基线模型实现了超过10%的性能提升,并能通过原子与氨基酸残基层面的可视化提供显著的模型可解释性。进一步的探索性实验与案例研究表明,该模型在实际应用中展现出强大的可迁移性与实用性。
总体而言,PROTAC-STAN的卓越性能与解释能力有望成为未来PROTAC研究的重要基础工具,为靶向降解药物的智能设计开辟新的方向。
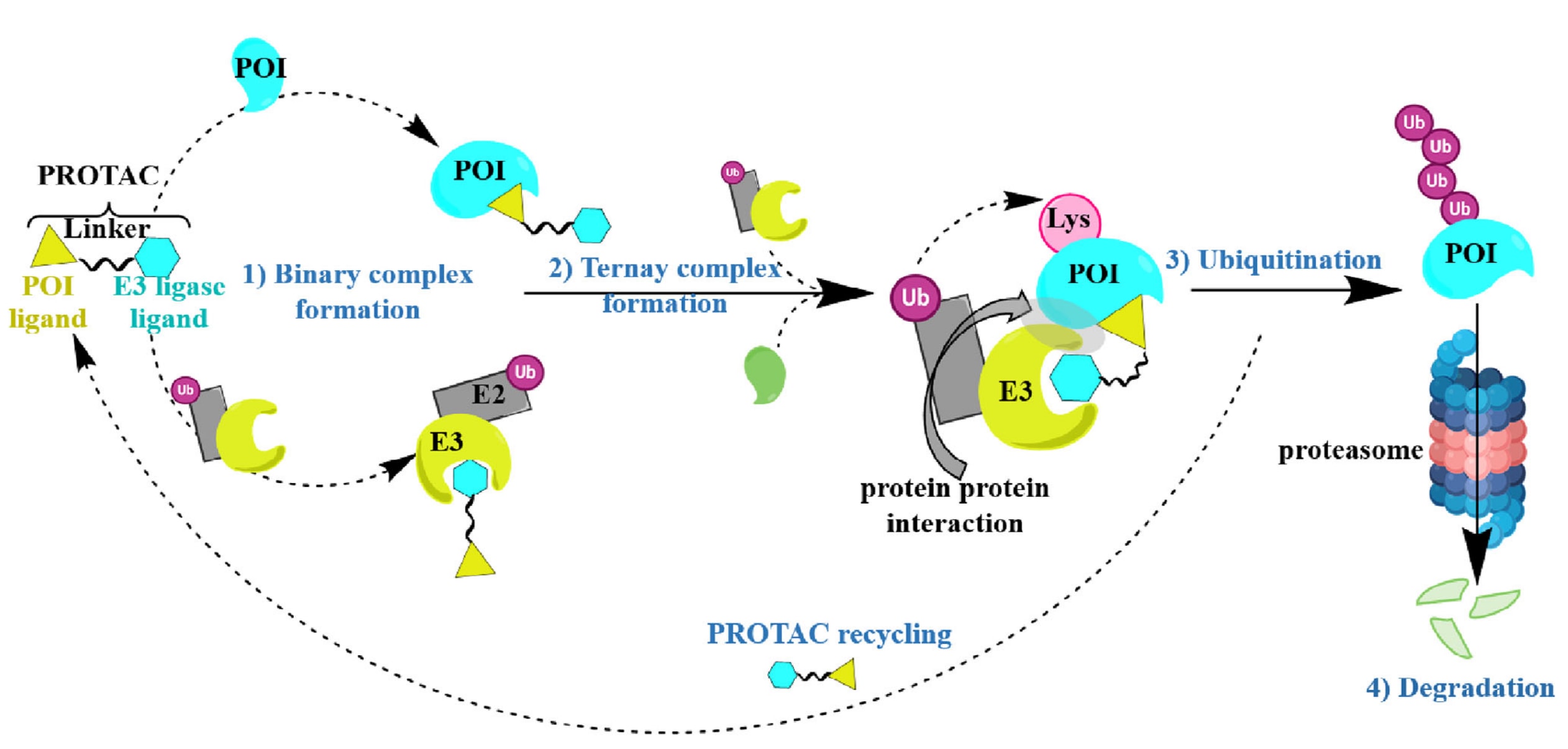
图1 | PROTAC介导的蛋白降解机制 PROTAC是一类双功能小分子,其设计目的是诱导特定靶蛋白的降解。图中展示了PROTAC的作用原理:分子的一端与目标蛋白结合,另一端则招募E3泛素连接酶。在这一过程中,E3连接酶促进目标蛋白的泛素化修饰,从而将其标记为蛋白酶体降解的底物。最终,目标蛋白被高效且选择性地降解,充分体现了PROTAC在靶向治疗中的巨大潜力与应用价值。
引言
近年来,靶向蛋白降解(Targeted Protein Degradation, TPD)已成为现代药物研发中极具前景的策略。与传统药物设计主要通过抑制或激活蛋白功能来实现治疗效果不同,TPD通过将目标蛋白标记为细胞降解系统的底物,从而诱导其被选择性降解,实现治疗目的。TPD能够有效解决传统方法难以作用的“不可成药”蛋白问题,并在一定程度上缓解由靶点口袋突变引起的耐药性。此外,该策略还能降低药物剂量与给药频率,减少不良反应。
在TPD的基础上,蛋白水解靶向嵌合体(PROTAC)技术作为一种新型治疗模式脱颖而出。PROTAC是一类双功能小分子配体,能桥接目标蛋白(POI)与E3泛素连接酶,形成三元复合物,从而利用泛素-蛋白酶体系统(UPS)实现对致病蛋白的定向降解,如图1所示。这一策略相较于传统的小分子抑制剂或受体拮抗剂更具系统性与彻底性,能够有效消除病理性蛋白功能。
然而,传统的PROTAC研究方法仍主要依赖湿实验,包括分子设计、合成、生物活性测试及临床验证等步骤。这些过程虽能产生可靠结果,但往往耗时长、成本高、劳动强度大。近年来,机器学习(ML)在PROTAC研究中的应用发展迅速。传统机器学习方法通常通过构建特征描述符,结合算法预测或优化PROTAC的降解性能;而深度学习(DL)由于具备更复杂的神经网络结构,能够自动提取PROTAC与蛋白间的潜在特征表示,实现从分子输入到降解结果的端到端预测。常见的网络架构包括循环神经网络(RNN)、图神经网络(GNN)及Transformer模型,用于生成分子、预测降解活性等任务。
尽管已有显著进展,当前的深度学习方法在PROTAC降解预测中仍面临多重挑战。首先是如何有效建模POI、PROTAC分子与E3连接酶三者的数据关系。在PROTAC系统中,这三者的相互作用高度依赖于分子亚结构与蛋白的结合位点结构信息。然而,许多研究仅使用SMILES串或分子指纹等单一表征方式,未能充分利用PROTAC分子的多层次信息。同时,在蛋白部分,部分模型仅以氨基酸序列作为输入,忽视了蛋白三维结构信息的重要性,甚至完全省略蛋白组分,导致模型性能受限。
其次,目前许多方法仅通过独立编码器提取联合特征来学习三者关系,未能显式地捕获亚结构间的交互,从而难以解释其预测机制。这种“黑箱”式方法缺乏可解释性,使研究者难以理解预测结果背后的生物学依据。
为克服这些问题,该研究提出了PROTAC-STAN——一种结构信息驱动的深度三元注意力框架,用于可解释的PROTAC降解预测。在该框架中:
- 针对第一个挑战,PROTAC-STAN利用图卷积网络(GCN)结合分子图、SMILES词频映射与理化性质特征,在原子、分子与性质三个层次上实现分层信息编码,从而保留关键结构特征。
- 对于POI与E3连接酶,模型借鉴蛋白语言模型ESM-S的思想,引入蛋白结构嵌入,无需显式三维结构即可捕获其空间结构信息。
- 针对第二个挑战,模型引入新型三元注意力机制,在亚结构层面显式学习POI、PROTAC分子与E3连接酶之间的交互关系。通过注意力图可直观可视化各亚结构对最终预测结果的贡献,从而揭示其结合机制,显著提升模型的可解释性。
在改进后的PROTAC-DB数据库上进行实验时,PROTAC-STAN在多个性能指标上均超越当前最优基线模型,其中降解预测准确率达到88.41%,AUROC为0.8833,F1值为0.8588,整体提升超过10%。此外,模型在原子与氨基酸残基层面可视化中展现了出色的解释能力。探索性测试与分子动力学(MD)模拟进一步验证了其在真实场景下的可靠性与实用性。
综上,PROTAC-STAN通过整合分层分子表示、结构嵌入与三元注意力机制,在性能与可解释性方面均取得突破,为PROTAC系统的计算建模与药物设计提供了重要工具与理论基础,为未来靶向降解药物的智能研发奠定了新方向。
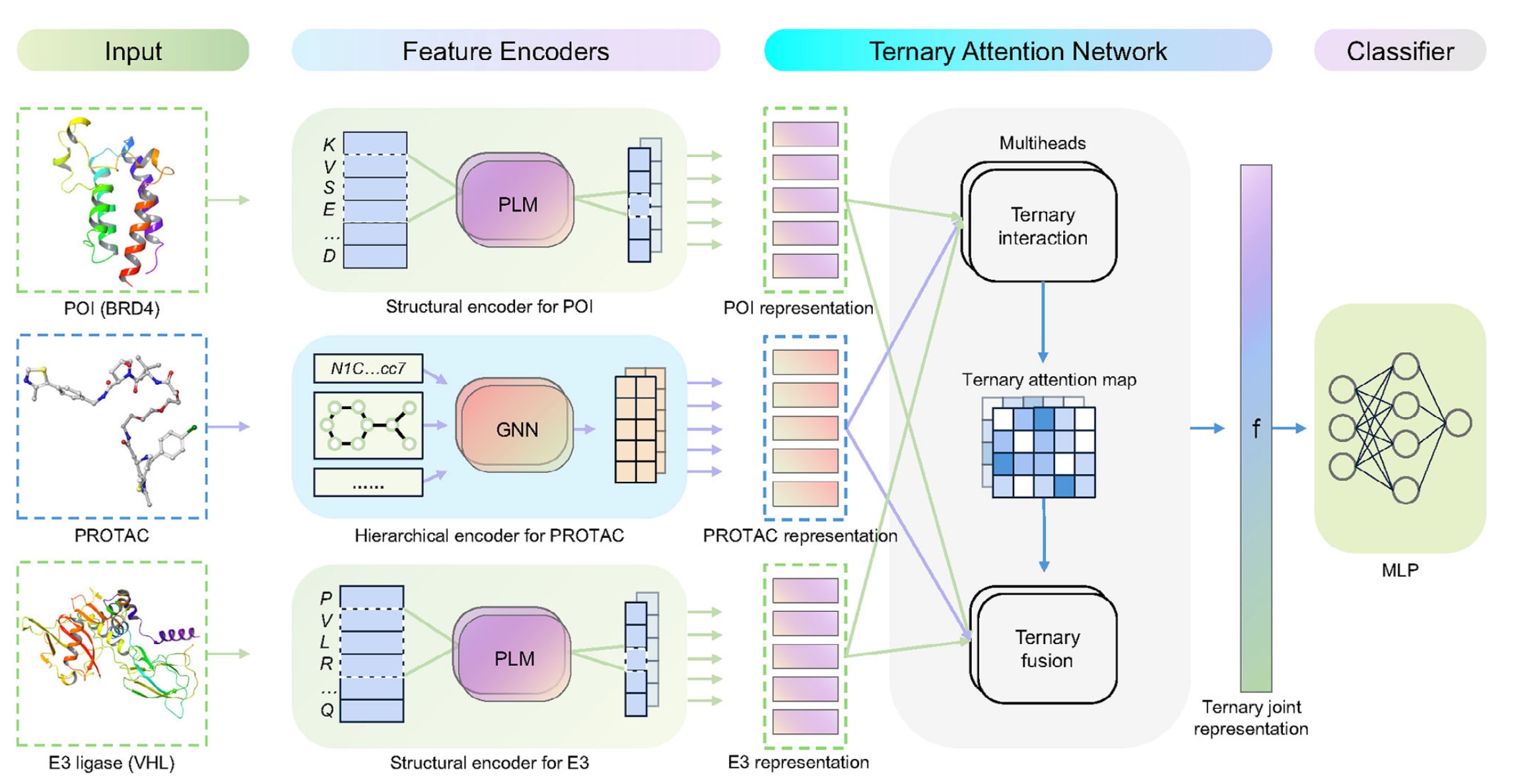
图2 | PROTAC-STAN框架概览 输入的PROTAC分子、目标蛋白(以BRD4为例)与E3连接酶(以VHL为例)首先通过特征编码器分别转化为PROTAC的分层表示与POI/E3的结构表示。其中,PROTAC编码器在原子、分子与理化性质三个层次上提取分层信息;而POI与E3连接酶的结构编码器则将结构信息融入蛋白嵌入表示中,无需显式的蛋白三维结构即可捕获其空间特征。接着,这些编码后的表示被输入到三元注意力网络中,以学习三者之间的亚结构交互关系。在第一次三元交互阶段中,三个实体的亚结构表示进行交互建模,生成反映交互强度的三元注意力图。随后在第二次三元融合阶段,模型在该注意力图的指导下,将三者的特征融合为一个联合表示
2 结果
2.1 PROTAC-STAN框架
如图2所示,PROTAC-STAN框架由三个特征编码器、一个三元注意力网络以及一个MLP分类器组成。给定一个由(POI, PROTAC, E3连接酶)构成的三元组输入,模型首先通过独立的特征编码器进行特征转换:PROTAC部分采用分层编码器,而POI与E3连接酶部分则使用结构编码器。分层编码器(详见第4节)用于捕捉PROTAC分子的层次信息,结构编码器则整合POI与E3连接酶的结构信息(同样详见第4节)。
随后,这些编码后的表示被输入到三元注意力网络中,用以学习三者之间的亚结构交互关系。该网络输出一个联合的POI–PROTAC–E3表示,并生成三元注意力图,用于可视化各亚结构对最终预测结果的贡献,从而显著提升模型的可解释性。最后,MLP分类层基于该联合表示预测蛋白降解的结果。
通过这一框架,模型能够更细致地刻画PROTAC介导的蛋白降解相互作用,在保持高预测精度的同时,提供对机制层面的深入理解。
2.2 性能评估
2.2.1 在PROTAC-fine数据集上的表现
该研究在PROTAC-DB 2.0的基础上增强降解信息(见第4节),构建了一个精炼的PROTAC数据集PROTAC-fine,共包含1,503个样本。数据集按随机比例8:2划分为训练集与测试集,同时通过SMILES去重策略避免数据泄漏,即训练集与测试集中不包含相同的PROTAC样本。最终得到1,202个训练样本和207个测试样本。
为了与DeepPROTACs和PROTAC-Degradation-Predictor进行公平比较,将PROTAC-fine与PROTAC-databank[38]求交,得到包含1,213条记录的bank-fine数据集,并在其上开展复现实验。实验采用基于相似度的8:1:1划分策略(train/val/test),利用Tanimoto系数评估PROTAC SMILES相似度,并用Needleman-Wunsch算法计算E3连接酶与POI的序列相似度(阈值设为0.9),以严格防止数据泄漏。模型的训练配置如附录表S3所示。
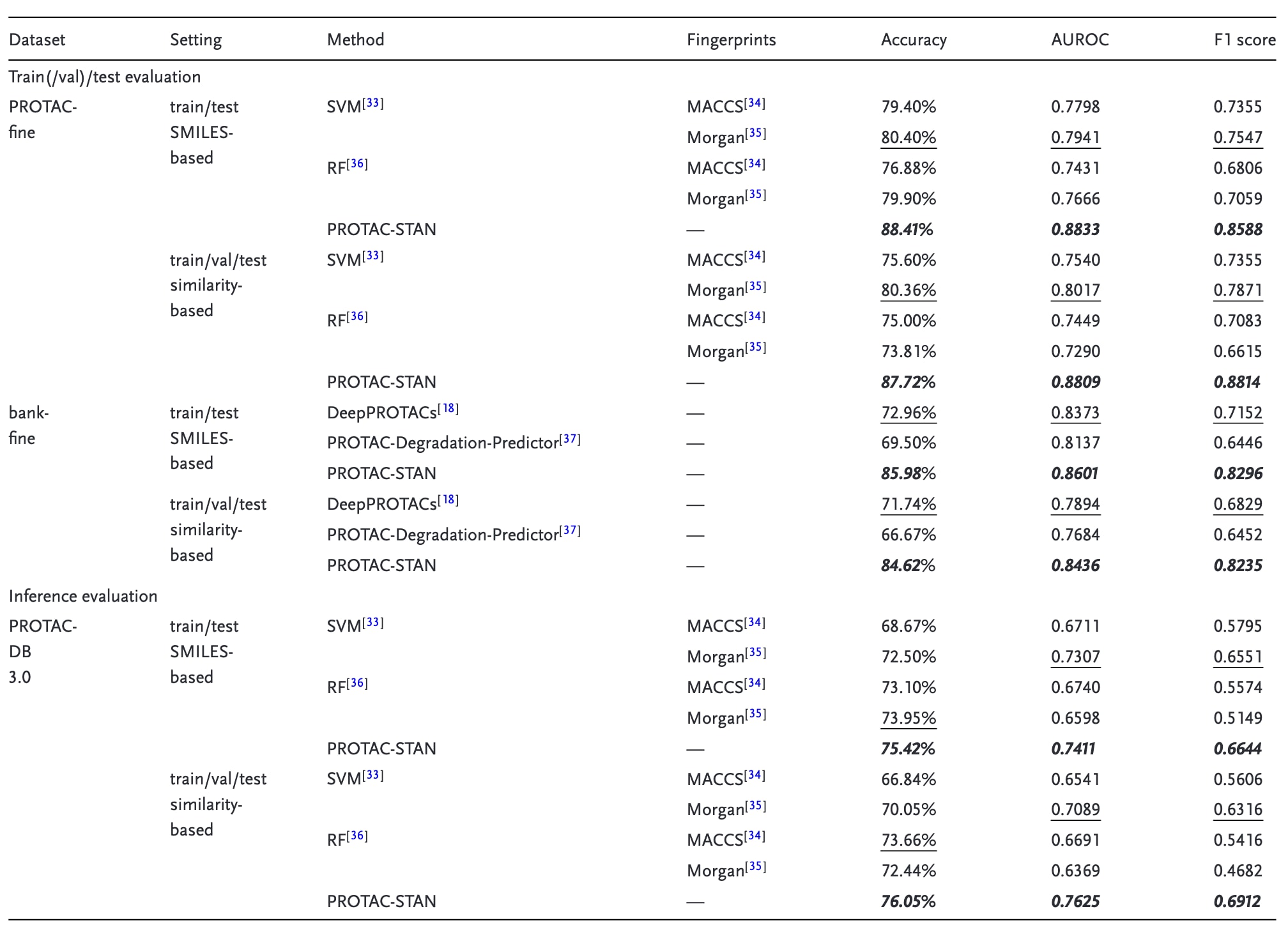
该节在两种实验设置下,将PROTAC-STAN与三种基线模型进行对比:支持向量机(SVM)[33]、随机森林(RF)[36]、DeepPROTACs[18],评估指标包括准确率(Accuracy)、AUROC和F1值。结果如表1所示。
在机器学习基线中,SVM略优于RF,而Morgan指纹特征的表现也略好于MACCS指纹,这与DeepPROTACs的发现一致。总体来看,深度学习方法在AUROC与F1指标上表现更优,证明其在建模复杂分子关系时具有明显优势,且不易受到单一指标偏倚的影响。
在三种深度学习方法中,PROTAC-STAN在所有实验设置中均显著优于DeepPROTACs与PROTAC-Degradation-Predictor,准确率分别提升超过12%与16%,AUROC与F1值亦有显著增长。这表明,数据增强策略与分层结构设计有效提升了模型的表征与拟合能力,而三元注意力机制对亚结构交互的显式建模是性能提升的重要原因。
具体而言,PROTAC-STAN在准确率上达到88.41%,AUROC为0.8833,F1值为0.8588,各项指标均为最高。这一结果凸显了PROTAC-STAN在PROTAC降解预测任务中的显著性能优势与可靠性。
此外,模型的可解释性将在第2.3节中通过三元注意力可视化进一步展示。
表1 | PROTAC-STAN与基线模型在测试集上的评估结果(考虑数据泄漏)
2.2.2 在PROTAC-DB 3.0数据集上的表现
最新发布的PROTAC-DB 3.0[41]相比2.0版本在数据量上有了显著提升,其数据库中PROTAC表的条目总数已达到9,380条。然而,其中同时包含DC₅₀与Dmax显式数值的条目仍相对有限,仅有909条。该研究基于第4节中用于PROTAC-DB 2.0的相同数据处理与增强策略,从PROTAC-DB 3.0中整理得到一个带有降解标签的3,182条有效数据集,并去除与2.0版本重复的样本,最终得到1,653条独立数据用于模型评估。
在PROTAC-DB 3.0上,设计了三种策略来评估PROTAC-STAN的性能:
第一,使用完整数据集进行推理评估(Inference Evaluation),在与第2.2.1节相同的两种设置下利用先前训练好的模型进行测试;
第二,从过滤后的数据集中随机抽取与PROTAC-DB 2.0同等规模的测试集,执行分布外(out-of-distribution, OOD) 测试;
第三,将过滤后的数据集划分为微调集(fine-tuning set) 与测试集,利用在PROTAC-fine上预训练得到的权重进行微调后再测试。按train/test + SMILES划分策略,划分结果为1,322条用于微调、331条用于测试。
在相同超参数条件下,该研究使用PROTAC-STAN、SVM与RF进行实验。由于DeepPROTACs所需的POI与E3连接酶输入数据不可用,因此该模型未纳入本次比较。
完整数据集的推理结果如表1所示。可以看出,PROTAC-STAN在两种实验设置下的准确率均达到约75%,并且AUROC与F1值均为最高,再次验证了模型的鲁棒性与稳定性。这一结果表明,当面对全新数据时,模型依然保持良好的预测能力,能准确判定PROTAC的降解活性。
在图3中展示了OOD测试与微调测试的结果。可以看到,PROTAC-STAN在两种评估中均表现最佳:
在图3左侧的OOD测试中,PROTAC-STAN是唯一准确率超过70%的模型,且在其他指标上也始终领先。值得注意的是,这些测试数据在训练阶段从未被模型见过,然而模型仍能保持较高性能,充分体现出其对分布外数据的泛化能力与稳健性。
在图3右侧的微调结果中,经过少量新数据的微调后,PROTAC-STAN的准确率显著提升,SVM与RF亦有一定改善,说明更大规模、更多样的PROTAC数据将对未来的预测研究提供重要支持。
值得一提的是,SVM在微调后准确率提升较明显,这可能与其对特定特征的高敏感性有关。然而,与PROTAC-STAN相比,SVM与RF的AUROC与F1值仍显著偏低,表明它们在处理分布外数据时存在局限,而PROTAC-STAN凭借其结构化表示与三元注意力机制,在模型灵活性、稳健性与泛化性方面均表现出明显优势。
三组实验的结果进一步证明了PROTAC-STAN的整体能力。尽管受限于训练数据规模,模型在应用于全新数据集时仍有进一步提升空间,但通过引入分层与结构化编码信息以及三元注意力机制的协同作用,模型已在复杂生物系统的建模中取得令人满意的结果。这一研究方向为未来PROTAC智能设计与降解机制分析提供了具有前景的探索途径。
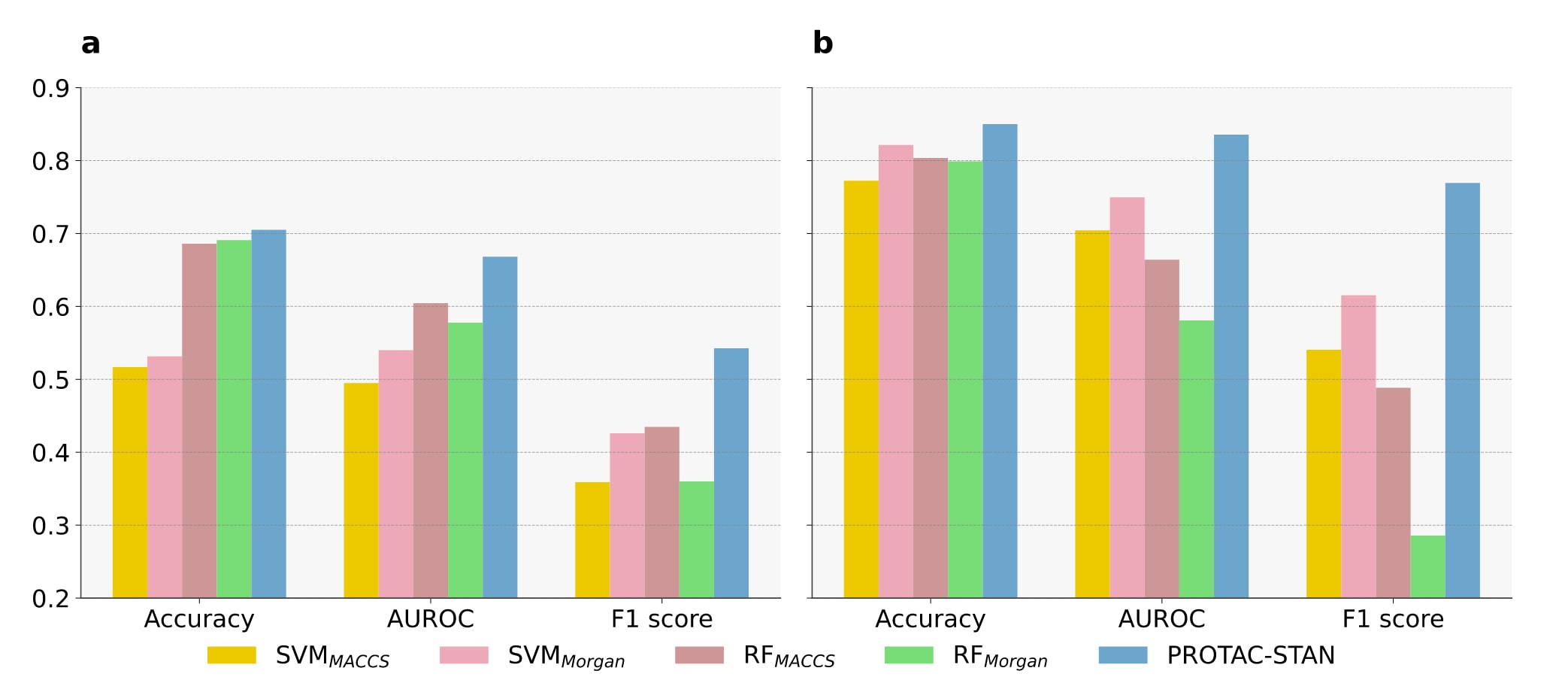
图3 | 基于最新版本 PROTAC-DB 3.0 构建的筛选数据集评估结果。 左图(a)为分布外测试(out-of-distribution test),即直接在采样得到的 PROTAC-DB 3.0 数据集上进行推理评估;右图(b)为微调测试(fine-tune test),其中微调过程包括以 PROTAC-fine 的预训练权重作为初始化,然后在该采样数据集上继续训练并进行评估。
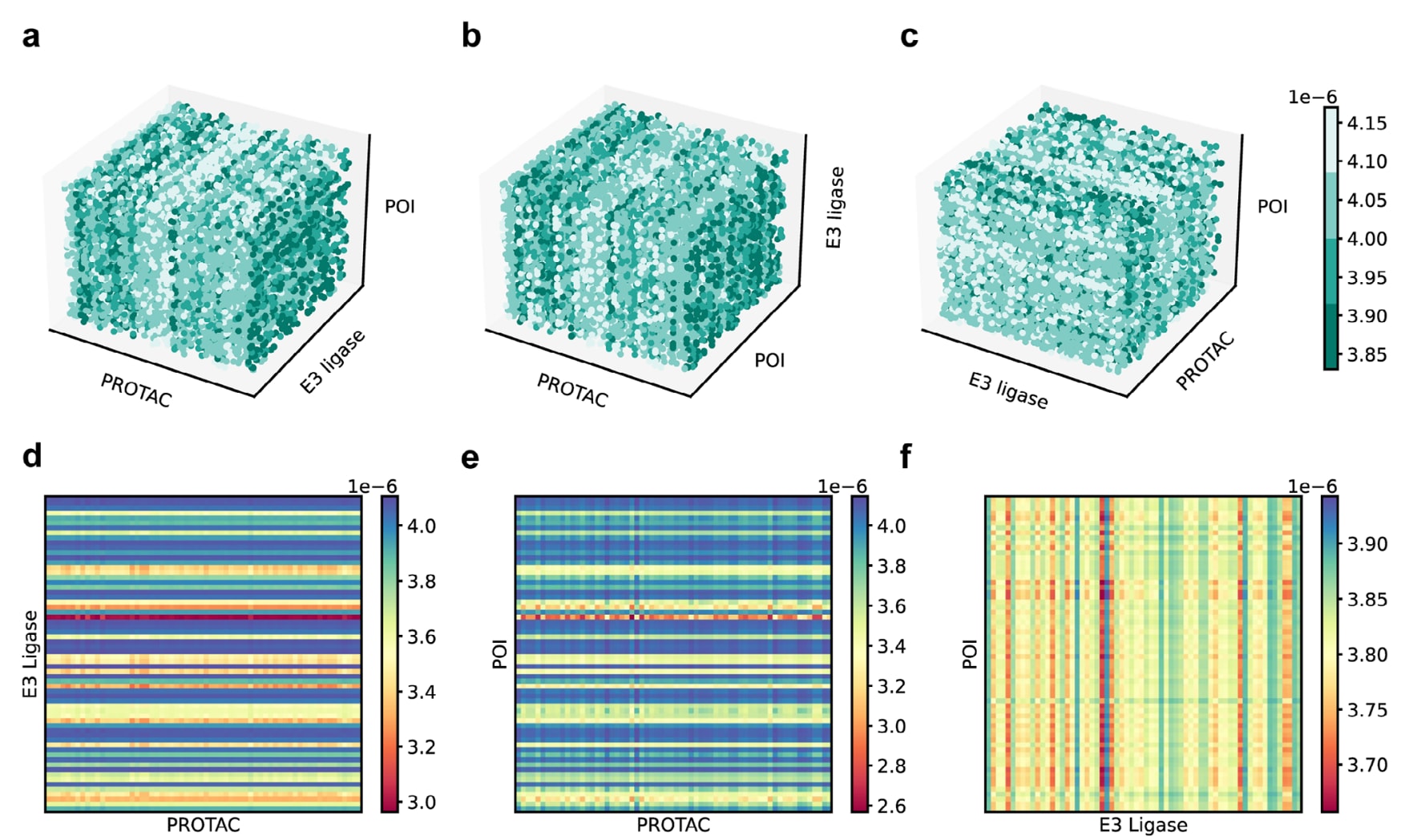
图4. 三维注意力可视化与多视角及成对注意力图可视化。 a) 正视图:从前向后观察注意力图,可见PROTAC与POI之间存在显著的条纹状交互模式。b) 俯视图:从上向下观察注意力图,显示出PROTAC与E3连接酶之间同样存在强烈的条纹状交互特征。c) 侧视图:从左向右观察注意力图,可见POI与E3连接酶之间仅呈现较弱的交互模式。d) PROTAC–E3连接酶成对注意力图。e) PROTAC–POI成对注意力图。f) E3连接酶–POI成对注意力图。
2.3.3 分子与复合物层面的可解释性分析
除了可视化注意力图之外,PROTAC-STAN最关键的能力在于能够将注意力权重映射回PROTAC分子的原子层级,以及E3连接酶与POI的氨基酸残基层级,从而实现对分子及复合物层面的可解释性分析。研究者将三元注意力映射回PROTAC的原子层面与E3连接酶、POI的残基层面,并在PROTAC分子与三维复合物上进行了可视化。其结果展示于图5,同时附有从三维复合物中提取的二维相互作用示意图。
研究以两个实例(PDB ID: 7KHH 与 7JTP)进行说明,这些三维晶体结构来自蛋白质数据库(PDB)。蛋白经由Maestro软件预处理,去除了多余溶剂并补全了缺失环区,获得了优化后的结构。随后从三元注意力图中提取了PROTAC的原子权重,并对其中60%的原子进行了上色(如图5a、d所示),颜色越深表示原子权重越高。基于三维复合物,利用Maestro生成了PROTAC、E3连接酶与POI之间的二维相互作用图,作用距离设定为3.5 Å(如图5b、e所示)。
分析发现,PROTAC与蛋白之间的主要作用为氢键作用与π–π堆积作用,且相互作用的原子主要分布在PROTAC两端,这与其实际结合模式一致——即PROTAC的“战斗头”(warhead)结合于POI,而E3配体(ligand)结合于E3连接酶。以图5a为例,二维分子可视化准确识别了多个关键作用区域及相应原子/基团。具体而言,在图5b分子左侧,来自2-吡啶酮环的氧原子(C=O)与残基ASN D:140作用,相邻吡咯环上的NH基团也与ASN D:140形成稳定氢键;甲磺酰基中的氧原子(S=O)与ASP D:88形成氢键。在分子右侧,来自3-羟基吡咯环的羟基(OH)与SER C:111及HIE C:115相互作用,形成氢键;同时,酰胺基的羰基氧(C=O)与TYR C:98作用,而胺基中的氮原子(NH)与HIE C:110形成氢键。这些可视化结果明确展示了PROTAC与E3连接酶及POI之间的关键作用区域,提示这些部位在三元复合物的形成与稳定中起着至关重要的作用。
图5c与5f展示了PROTAC在三维结合口袋中的结合情况。该部分通过PyMOL实现。研究从三元注意力图中提取了E3连接酶与POI的前五个高权重残基,并将权重最高者标记为灰色,实际相互作用残基标记为绿色,重叠残基标为品红色,氢键以黄色显示,π–π堆积作用以绿色显示。背景中,蓝紫色部分表示E3连接酶,橙色部分表示POI。
研究进一步计算了这些残基到PROTAC分子质心的距离,以评估其空间分布并近似分析作用界面(数据见附表S4)。结果表明,大多数高权重残基位于相互作用残基附近,只有少数超出该区域。在标记残基中,7KHH中高权重残基的比例超过一半,且在7JTP中也能观察到正确的趋势感知。在图5c中,ASN-140与ASP-88被准确标记为高权重残基,并与PROTAC形成氢键作用;其他未直接形成作用的高权重残基,如CYS-136与PHE-76,也位于相互作用残基附近,这一结果令人印象深刻,显示该方法能在三维复合物层面提供较强的可解释性。在图5f中,尽管相互作用残基较为集中且无重叠,但高权重残基如PHE-76、LEU-88、ASN-130、GLY-147与ALA-105均与相互作用残基相邻,说明三元注意力学习能够捕捉关键残基的趋势特征,并具有潜力用于理解PROTAC三元复合物的形成机制。
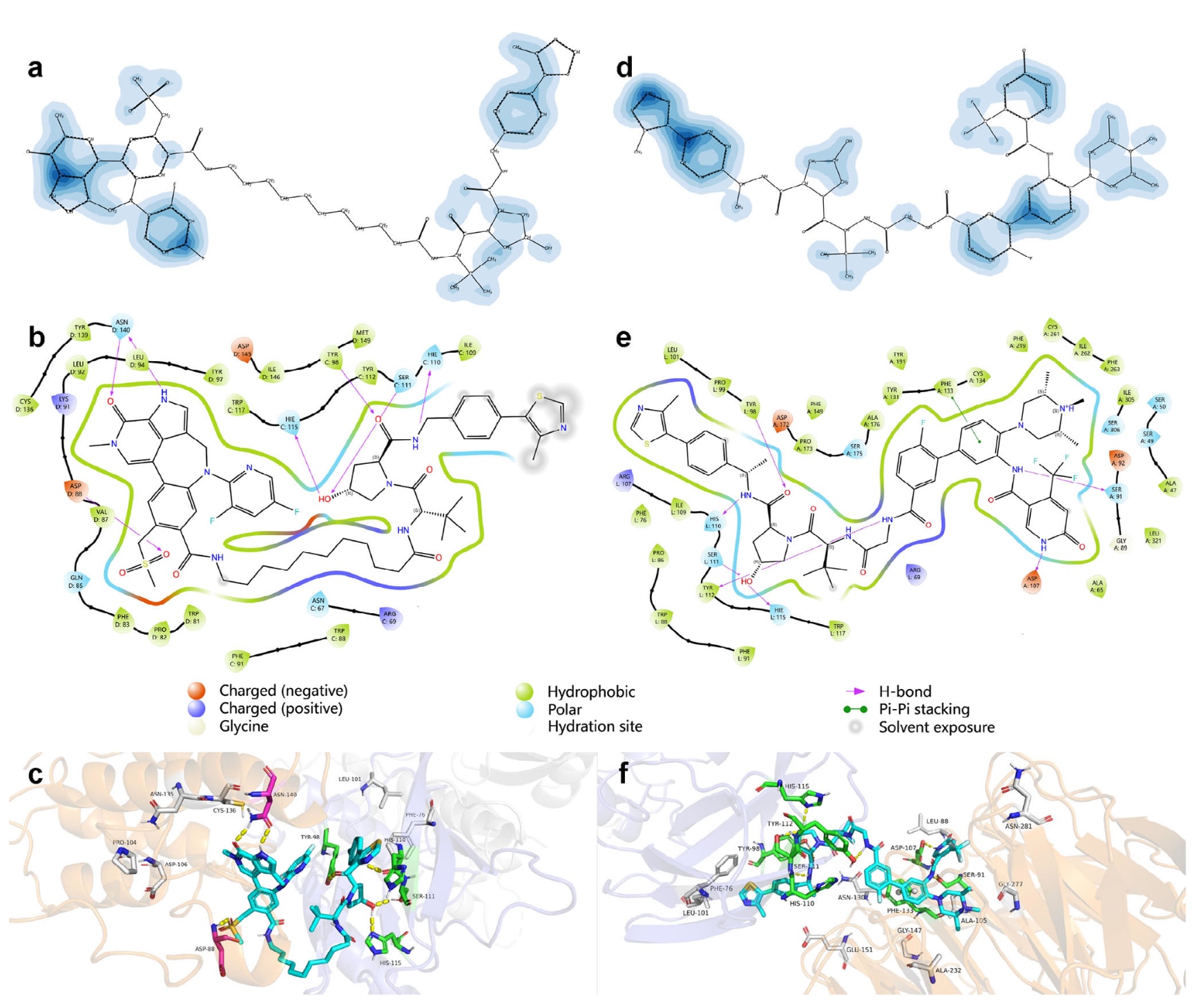
图5 | PROTAC分子与三维复合物的三元注意力可视化。左侧(a–c)来自PDB 7KHH,右侧(d–f)来自PDB 7JTP。a、d) 为带有权重标记原子的二维PROTAC分子可视化图,颜色越深表示该原子的权重越高。b、e) 为从复合物中提取的二维相互作用可视化图,下方附有图例说明。c、f) 为三维口袋结构可视化图,展示关键残基分布:其中高权重残基标记为灰色,实际相互作用残基标记为绿色,重叠残基标记为品红色。
2.4 探索性测试
2.4.1 连接臂敏感性
在PROTAC分子中,连接臂(linker)对其降解效率具有决定性作用,是影响PROTAC设计与功能多个方面的关键组成部分。研究者评估了该方法对连接臂变化的敏感性。首先,将精炼后的PROTAC数据集与包含战斗头(warhead)、连接臂(linker)及E3配体(ligand)的附加数据表进行比对,获得共1,323条数据记录,即(PROTAC, warhead, linker, E3 ligand)的匹配组合。随后以(warhead, E3 ligand)为组合进行分组,并剔除仅含单一正样本或负样本的组,最终得到37个分组,共251条数据。
利用PROTAC-STAN模型对所有样本进行评估,整体降解预测准确率达到88.45%,显示出优异的预测性能。针对每个分组的实验结果如图6a所示,在37个分组中,有20个分组的正负样本均得到了准确预测,整体准确率在正、负样本间保持平衡。值得注意的是,部分预测准确率为0%的分组主要由单一样本构成,凸显了进一步扩充PROTAC数据的重要性。在这些分组中,E3连接酶–E3配体与POI–warhead保持不变,仅连接臂不同。实验结果表明,该模型能够有效预测不同连接臂下的降解结果,说明PROTAC-STAN对连接臂变化具有显著敏感性。这一发现表明该模型具备与连接臂设计策略结合的潜力,为未来新型PROTAC分子的发现提供重要支持。
2.4.2 连接臂柔性
连接臂的柔性(flexibility)是PROTAC设计中的关键因素,对模型在真实应用中的表现有显著影响。目前大多数模型主要聚焦于传统柔性连接臂,如PEG或烷烃链,而对于临床相关的刚性连接臂的研究仍相对有限。为评估模型在不同柔性水平下的表现,研究依据文献[46]的方法计算了连接臂柔性得分。该得分定义为可旋转键数与总键数之比,数值越高表示柔性越强,数值越低则表示结构越刚性。
研究按柔性程度对连接臂进行分组,并评估了模型在各组内的表现(见图6b)。结果显示,PROTAC-STAN在处理刚性连接臂时的稳定性略有下降,但仍保持了具有竞争力的预测性能。这一性能波动与训练集中各类别连接臂样本数量的不均衡高度相关,说明数据分布不平衡可能是导致模型性能差异的主要原因。
此外,研究进行了前瞻性验证(见附录S2.5与S1.1.3),使用包含非典型连接臂的PROTAC进行测试,结果显示模型在中等柔性连接臂(PROTAC 1、4、12、13)上保持高准确率,而在高刚性连接臂(PROTAC 10、11)上准确率略有下降,但仍处于可接受的竞争水平。
这些结果表明,扩大数据集以涵盖更多样化的连接臂化学类型对于进一步提升模型的泛化能力与稳健性至关重要。
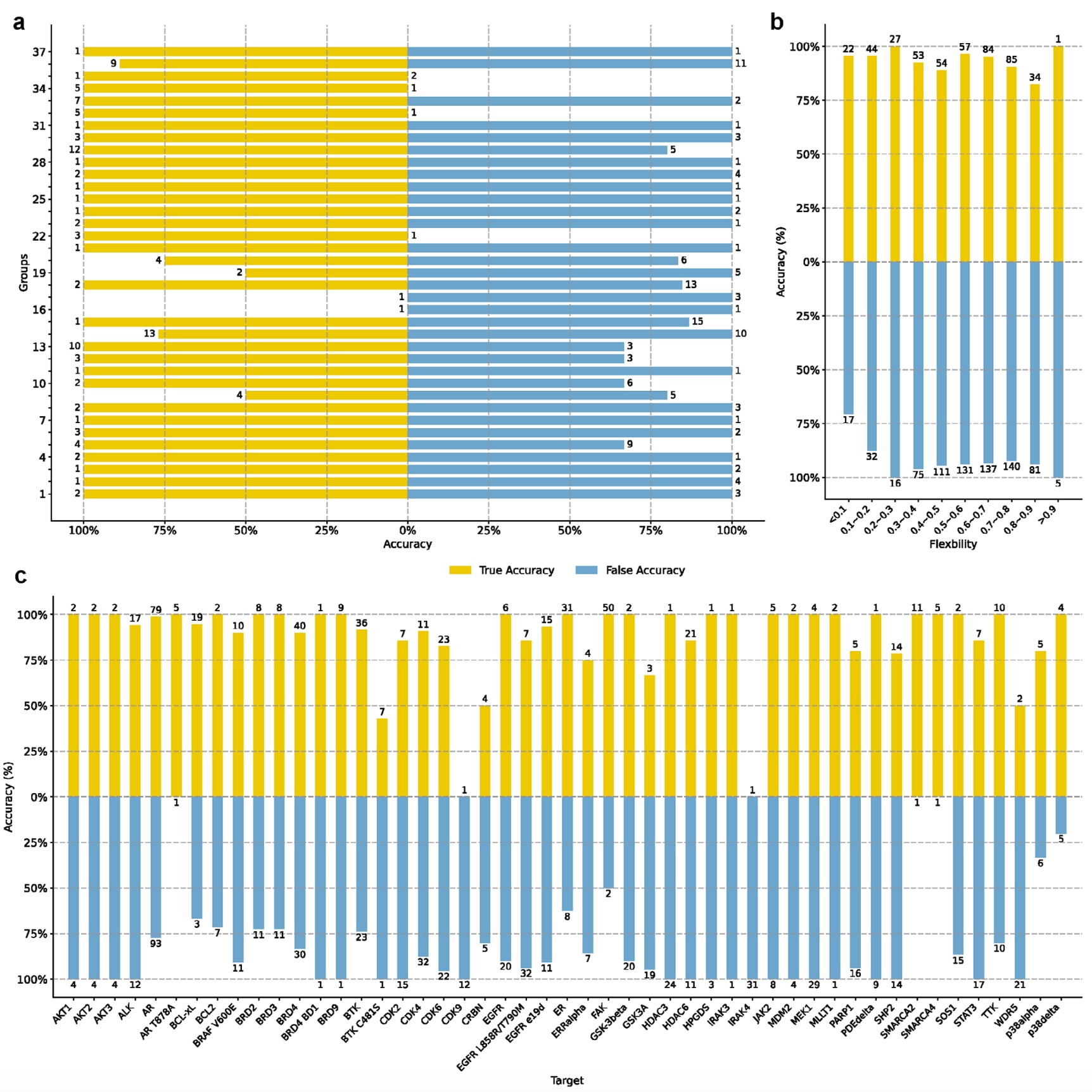
图6 | 探索性评估结果。 a) 连接臂敏感性评估:通过分组降解预测进行分析。每个分组中的样本均保持E3连接酶–E3配体及POI–warhead固定,仅连接臂不同。b) 不同连接臂柔性组的评估结果:柔性值越高表示连接臂越灵活,值越低则表示结构越刚性。c) 按靶点进行的评估结果:两端的数字分别表示各组中的样本数量。
2.4.3 靶点适应性
为进一步评估模型的鲁棒性与泛化能力,研究进行了基于靶点的分组分析(见图6c)。研究者根据各PROTAC的靶点类型对数据进行分组,并在靶点层面上评估模型的预测性能。结果表明,PROTAC-STAN在主要靶点上均表现出稳定且一致的预测能力,预测结果与综合评价指标高度一致。尽管在训练数据有限的靶点上存在轻微性能下降——这是数据稀缺情况下的可预期现象——但模型整体仍保持竞争性水平的性能表现。这些结果强调了扩大数据集对于进一步提升模型鲁棒性与泛化性的必要性。
此外,在图3的微调实验中使用新数据后,模型的预测性能出现显著提升,表明其能够通过少量新增数据快速适应新靶点,具备在现实应用中对未知靶点进行有效泛化的潜力。
2.5 案例研究
为验证PROTAC-STAN对新型PROTAC分子的预测能力,研究选取了细胞周期依赖性激酶4(CDK4)作为案例。CDK4(UniProt ID: P11802)是一种丝氨酸/苏氨酸激酶(Ser/Thr kinase),在细胞周期调控中发挥关键作用,是包括乳腺癌、恶性黑色素瘤及非小细胞肺癌在内多种肿瘤的重要治疗靶点。基于PROTAC的CDK4降解剂为抗癌治疗提供了新的思路,有望克服传统CDK4/6抑制剂(如palbociclib)的耐药问题。
研究以palbociclib作为CDK4的配体,并选用已知的VHL结合配体(PubChem CID: 129900323)作为E3连接酶配体,设计了13种不同长度与化学结构的连接臂(见附表S2)。构建了13个三元复合物(CDK4–PROTAC–VHL)(数据见附录S1),并进行了500 ns分子动力学(MD)模拟以评估结构稳定性。
2.5.1 结合自由能分析
利用MM-GBSA方法计算的结合自由能结果显示,PROTAC 1–5的蛋白–蛋白相互作用能量较强(范围为−39.25至−20 kcal·mol⁻¹),与PROTAC-STAN预测的高降解活性一致(见图7a)。PROTAC 6与7表现出中等亲和力(−15至−20 kcal·mol⁻¹),预测结果同样吻合。而PROTAC 8–13的蛋白–蛋白相互作用较弱(>−15 kcal·mol⁻¹),其中PROTAC 12与13在模拟初期发生体系坍塌,推测因三元复合物不稳定所致。在这些低稳定性样本中,有四个(PROTAC 8、11、12、13)被模型正确预测为低活性降解剂(见附表S2)。
该结果表明,PROTAC-STAN能够有效识别并优先筛选具有高复合物稳定性的候选分子,同时排除潜在低活性降解剂。
唯一的假阳性样本是PROTAC 9,被错误预测为高活性,但其结构与PROTAC 1几乎一致,仅在连接臂中多出一个PEG单元。其高度结构相似性导致预测分数接近,这说明误判主要源自结构相似性而非模型缺陷,进一步证明了模型的稳健性。此外,PROTAC-STAN预测得分与MM-GBSA能量之间的相关性分析(见附录S1.1.4)进一步验证了模型的实际可靠性。
2.5.2 蛋白–蛋白距离分析
研究通过测量CDK4残基Arg101与VHL残基Tyr98之间的空间距离变化,评估两者在模拟过程中的分离程度,结果如图7b所示。总体来看,五个样本中CDK4与VHL之间的距离均保持稳定,表明三元复合物在分子动力学模拟中结构完整性良好,未发生显著构象变化。这说明PROTAC分子成功诱导了CDK4与VHL形成稳定的三元复合物,进一步支持了PROTAC 1–5具备高降解活性的结论,并验证了深度学习模型预测结果的准确性与可靠性。
2.5.3 均方根偏差(RMSD)分析
为了评估三元复合物在分子动力学模拟中的构象稳定性,研究对基于PROTAC分子的复合物进行了RMSD分析,结果如图7c所示。RMSD趋势显示,PROTAC 1及PROTAC 3–5在整个模拟过程中保持高稳定性,而PROTAC 2在部分时间点出现轻微波动,但整体RMSD变化较小,表明复合物结构仍较为稳定。
其中波动最大的PROTAC 2的最大RMSD约为8 Å,而其余PROTAC的最大RMSD约为5 Å,说明这些PROTAC在靶蛋白结合口袋中的结合稳定性良好。这些结果进一步证实,PROTAC 1–5所诱导的三元复合物具有高度结构稳定性,与模型预测结果高度一致,从而体现出PROTAC-STAN在分子层面预测降解活性上的有效性。

图7 | 分子动力学(MD)模拟结果。a) 前五个PROTAC的MM-GBSA结果:由PROTAC-STAN模型预测为具有降解活性的前五个PROTAC在MD模拟中表现出CDK4蛋白与VHL蛋白之间更强的结合亲和力,该结果通过MM-GBSA能量计算得到。b) CDK4与VHL随时间的距离变化:距离变化越小,表示复合物结构越稳定。c) PROTAC的RMSD随时间变化:RMSD值越小,说明PROTAC在蛋白结合口袋中的结合构象越稳定。
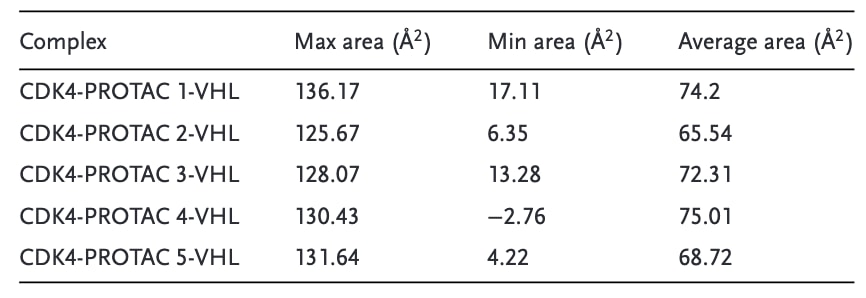
表2 | 模拟过程中赖氨酸残基的溶剂可及表面积(SASA)统计结果。
2.5.4 溶剂可及表面积(SASA)分析
研究通过分析赖氨酸残基的溶剂可及表面积(SASA)来评估PROTAC诱导的三元复合物的降解潜能。前五个结果列于表2。分析显示,由PROTAC 1–5诱导形成的三元复合物具有较大的SASA值,平均约为70 Ų,最大可达136 Ų,表明在模拟过程中这些残基具有较高的溶剂暴露度。较高的SASA值通常意味着更容易被E3连接酶识别并发生泛素化,从而提升降解效率,这提示PROTAC 1–5可能具有更高的降解活性。这一结论与深度学习模型的预测结果高度一致,进一步验证了模型在预测PROTAC降解活性方面的可靠性与有效性。
2.6 消融研究(Ablation Study)
2.6.1 PROTAC-STAN关键组件的消融分析
为了评估PROTAC-STAN框架中各关键模块的重要性(详见第2.1节),研究设计了一系列消融实验。基准模型(Raw)使用了PROTAC SMILESNet编码器、POI/E3连接酶的Ngrams编码器以及简单拼接融合方式,用于与PROTAC-STAN对照。随后分别分析各模块的影响:
- −S1方案用于评估PROTAC层级编码器的作用;
- −S2方案用于评估POI/E3连接酶结构编码器的作用;
- −S方案同时去除S1与S2模块,用于整体特征编码效果分析;
- −T方案用于考察三元注意力网络(TAN)的作用。
根据表3结果,基于基线构建的Raw模型在降解预测上表现尚可,验证了已有方法的合理性。而−S模型将F1得分从0.7738提高至0.8333,表明结构信息驱动的特征编码器显著提升了模型性能,其中−S1的贡献更为突出。−T模型的表现接近Raw,但由于其引入了三元注意力网络以联合建模POI、PROTAC与E3连接酶间的相互作用,在可解释性与特征融合方面表现更优。
当同时引入−S与−T模块,即形成完整的PROTAC-STAN架构时,模型的整体性能显著提升——准确率提高6.77%,AUROC达到0.8833,F1得分达到0.8588,充分证明了该方法的综合优势。
在进一步分析中,研究还针对SMILES最大长度(128/256)与结构编码器(ESM-S与ESM-2)进行了额外的消融测试(见附录S1.3.2)。结果表明,256长度或使用ESM-2时模型性能下降,说明128长度更适合当前任务,而ESM-S因具备显式结构监督信号,在本任务中表现更优。
2.6.2 三元注意力网络(TAN)的消融分析
为深入研究TAN模块的作用,研究比较了不同的特征融合方式、注意力头数量及输入顺序的影响。具体而言,比较对象包括:
- Concatenation拼接融合法;
- 低秩多模态融合(LMF);
- TAN多头注意力融合法。
如附表S11所示,Concatenation与LMF的性能接近单头TAN(TAN1),但均低于双头TAN(TAN2),表明尽管三者均能完成特征融合,但Concatenation过于简单,而LMF与TAN更为复杂、可训练性更强,因而在相似复杂度下表现更优。此外,TAN通过生成三元注意力图,具备更高的可解释性。
在多头配置中,多头TAN整体优于单头,但参数量随之增加,因此研究未进一步扩大头数,以平衡性能与计算成本。同时,不同输入顺序(如PROTAC–E3–POI与E3–POI–PROTAC)对最终性能影响较小,最优顺序为123与312组合。
值得注意的是,研究还构建了一个仅考虑成对交互的变体模型PROTAC-STANpair(即仅建模PROTAC–POI与PROTAC–E3配对交互,而非三者同时交互),结果显示其性能明显低于完整模型,说明蛋白–蛋白间相互作用在PROTAC介导的降解中起关键作用,这一发现与近期研究结果相吻合并提供支持。
2.7 模型效率
为评估计算效率,研究比较了PROTAC-STAN与DeepPROTACs在推理时间与显存占用方面的差异。所有模型在相同设备上测试,使用bank-fine数据集,批量大小设为4。结果(见表4)显示,PROTAC-STAN的训练速度比DeepPROTACs快约1.5倍,在训练与推理中分别节省13%与12%的显存。这种效率提升得益于TAN网络中的参数共享机制及优化的einsum计算。尽管TAN在GPU显存上有额外开销,但其性能提升与可解释性优势完全值得这一代价。未来工作将探索基于稀疏注意力或模型蒸馏的优化策略,以进一步提高效率并保持预测精度。
表4 | DeepPROTACs与PROTAC-STAN的计算效率比较。

3 讨论
该研究提出了PROTAC-STAN——一种端到端结构信息驱动的深度三元注意力框架,用于可解释的PROTAC降解预测。该方法融合了PROTAC的层级表示、POI与E3连接酶的结构嵌入,以及三元注意力机制以高效建模三者的亚结构相互作用。通过层级与结构双重建模,PROTAC-STAN能够捕捉关键结构特征,并在原子与残基层面上生成可解释的注意力分布图,从而揭示潜在的降解机制。
与当前主流模型相比,PROTAC-STAN在输入表示、交互建模方式与结果可解释性上均具有本质差异。
- DeepPROTACs将PROTAC拆解为warhead、linker与E3-ligand三部分,与POI和E3的结合口袋图结构拼接后再输入分类头,捕捉几何与拓扑特征,但采用**晚期融合(late fusion)**策略,模态间交互有限。
- PROTAC-Degradation-Predictor则使用Morgan指纹结合蛋白预训练嵌入及细胞系文本信息,模态输出经线性加权求和后输入浅层预测头,融合粒度较粗。
相比之下,PROTAC-STAN采用分层多尺度编码器,在原子、片段与分子层面聚合特征,并结合结构感知的蛋白表示,通过三元注意力网络显式建模PROTAC–POI–E3间相互作用,从而生成原子与残基层面的注意力归因及三元注意力图,连接全局交互模式与分子机制假设。在多个数据集上,PROTAC-STAN均显著优于其他深度模型与传统机器学习方法,展现出更强的分布外(OOD)鲁棒性与少样本适应能力。
在实际应用中,PROTAC-Degradation-Predictor更适用于细胞系数据丰富的场景,而PROTAC-STAN更适合结构导向的设计与机理解释,并能跨靶点迁移至早期药物发现阶段。模型的注意力推理结果与分子动力学模拟(MD)分析高度一致,可用于连接臂优化、POI/E3选择与实验假设设计。
此外,研究对E3–POI间相互作用的分析指出,系统协同效应对目标蛋白有效降解至关重要。已有研究表明,这类作用通常较弱,但连接臂长度与柔性对三元复合物形成与稳定性有显著影响。例如,较短的连接臂往往对应更高的降解效率。这表明,通过合理分子设计可增强系统协同性,从而利用弱相互作用实现有效降解。
当然,该研究仍存在一定局限性,如数据集偏差与蛋白结构信息不足。对于前者,尤其是刚性连接臂数据稀缺导致的模型性能偏低,未来将优先补充刚性与大环连接臂数据,以改善数据平衡与模型泛化性。对于结构信息缺乏的问题,该研究使用ESM-S蛋白编码器(结合序列与结构预训练信息)以缓解影响,但在应对翻译后修饰(PTMs)或动态构象变化时仍可能存在偏差。未来将引入AlphaFold3预测结构以进一步提升预测精度与结构可变性建模能力。
总之,PROTAC-STAN已在性能与可解释性上超越同类算法,随着PROTAC数据的持续积累,其鲁棒性与预测能力有望进一步增强,为结构驱动的PROTAC药物设计提供强大支持。