NCS 2025 | ECloudGen:利用电子云作为潜在变量扩展基于结构的分子设计
ECloudGen发表于 Nature Computational Science,是一项以电子云为核心表征,旨在突破结构基础分子设计数据瓶颈的创新工作。在SBMG中,蛋白−配体复合物数量远不及化学空间规模,长期限制生成模型的有效性。ECloudGen通过将电子云引入为潜在变量,为蛋白−配体数据与仅含配体的大规模数据库之间建立联系,使条件生成从

获取详情及资源:
- 📄 论文: https://doi.org/10.1038/s43588-025-00886-7
- 💻 代码: https://github.com/HaotianZhangAI4Science/ECloudGen
0 摘要
基于结构的分子生成在人工智能驱动的药物设计中具有重要意义,但该方向的发展长期受到蛋白–配体复合物结构数据稀缺的限制。此处提出一种潜在变量方法,用于连接仅含配体的数据与蛋白–配体复合物,从而使具备靶点感知能力的生成模型能够探索更广阔的化学空间,并提升分子生成的整体质量。受量子分子模拟启发,作者设计了ECloudGen这一生成模型,将电子云作为具有实际物理含义的潜在变量引入体系。ECloudGen结合潜在扩散模型、Llama架构以及对比学习任务,将化学空间组织为结构化且高可解释的潜在表示。基准测试显示,ECloudGen在生成更高亲和力、具备更优理化性质并覆盖更宽化学空间的分子方面优于当前主流方法。将电子云纳入潜在变量不仅提升了生成性能,也带来了模型层面的可解释性,这一点在多项案例分析中得到展示。
1 引言
开发新药一直是人类对抗疾病的有效方式,而分子生成作为AI驱动药物设计中的核心环节,旨在提出新颖且高效的药物结构。早期基于分子图的生成方法往往不具备靶点特异性,难以满足真实药物研发的高标准,因此研究重点逐渐转向受约束的分子生成,尤其是结构基础的分子生成。在这一框架中,模型从简单学习
尽管这些模型在先导化合物设计上取得了可观成果,甚至已有工作获得实验验证,但一个长期存在却常被忽视的问题依然突出:数据稀缺。在一般分子生成任务中,训练数据可覆盖约
鉴于数据质量与规模对AI模型的重要性,突破这一悖论具有极高价值。基于此,提出了ECloudGen,通过融合量子物理思想扩展SBMG可利用的化学空间,从根本上提升生成表现。方法的核心在于引入一个将蛋白-配体数据与仅含配体的数据相连的潜变量,从而将
ECloudGen包含两个主要模块:一个从蛋白口袋生成电子云,对应
实验表明,ECloudGen所覆盖的化学空间明显宽于多种先进基线模型,有效缓解了稀疏化学空间悖论,并能生成结合力更强、性质更优的分子。在实际应用中,电子云作为物理潜变量进一步赋予模型层面的可解释性,并在药物设计中发挥潜在价值。此外,还利用ECloudGen构建了一个与模型无关的分子优化模块,适用于单条件与多条件优化,并在oracle基准与五约束的药物设计任务中得到验证。结合现代AI技术与物理洞见,ECloudGen为分子生成提供了一条独特而强大的新路径。
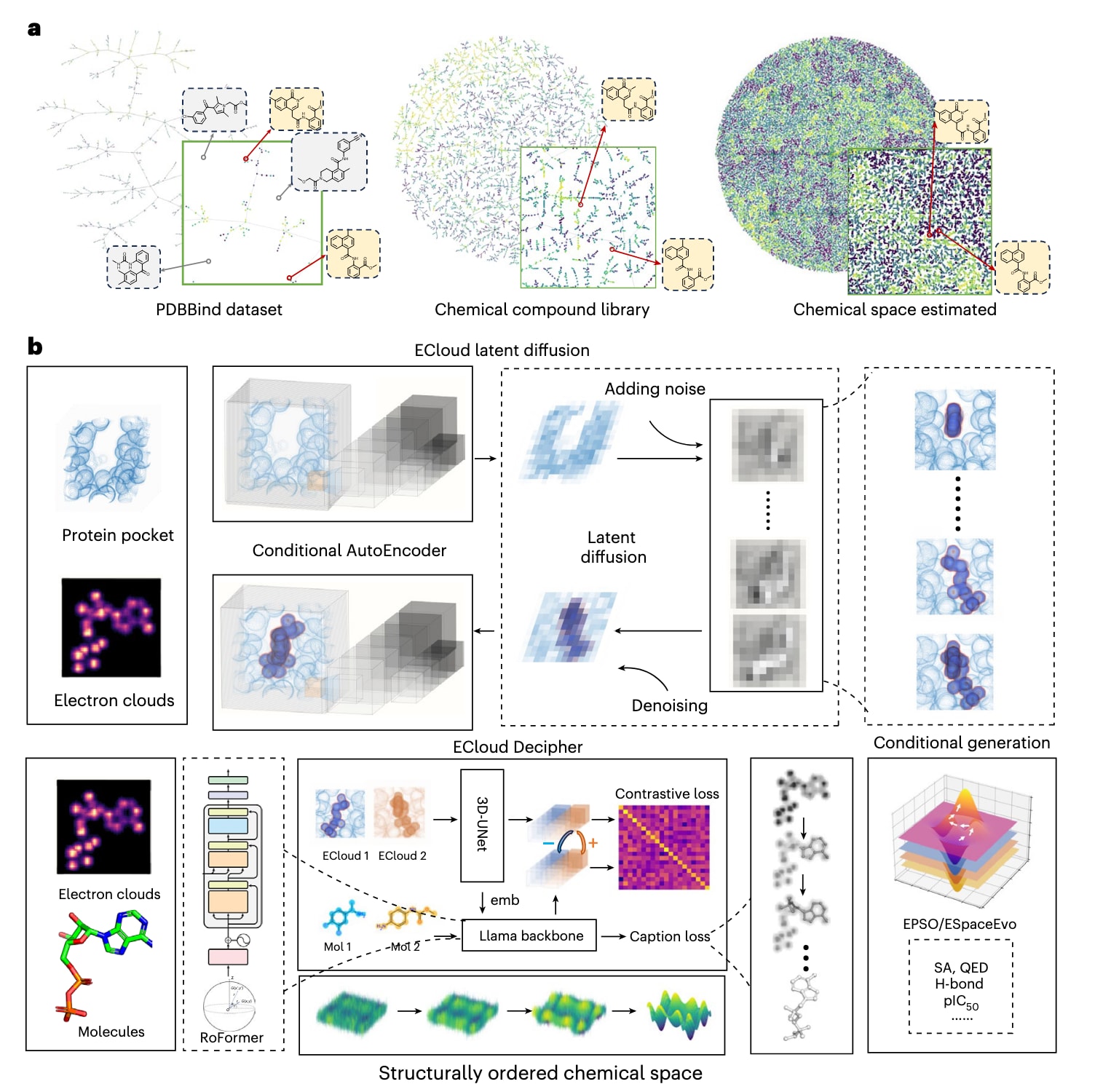
图1|展示了稀疏化学空间生成悖论以及ECloudGen的整体框架。 a部分以三个不同尺度的化学空间为例说明这一悖论:PDBBind数据集仅包含约
2 Results
2.1 结合能力与类药性方面的基准表现
分子能否成为潜在药物取决于其对靶点的结合亲和力以及类药性,因此SBMG模型通常从这两个方面进行评估。早期方法在提升结合能力方面表现突出,但往往在类药性上表现不足。部分基于片段的策略能够改善某些性质,但仍难以解决被称为稀疏化学空间悖论的根本问题。
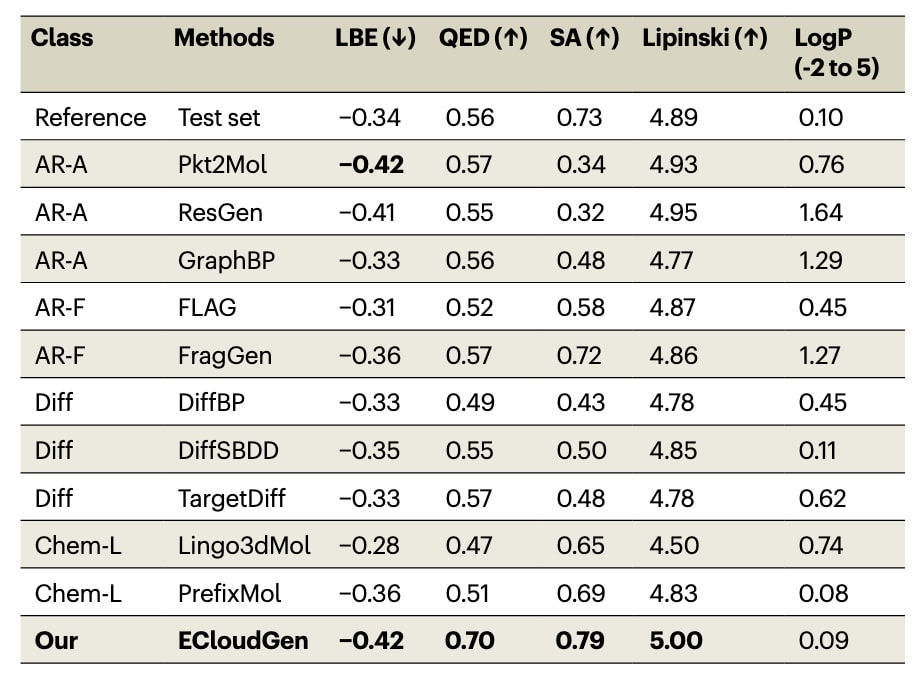
研究中将ECloudGen与十个基线模型进行对比,包括Pocket2Mol、ResGen、GraphBP、FLAG、FragGen、DiffBP、DiffSBDD、TargetDiff、Lingo3dMol与PrefixMol,并在CrossDock数据集上采用蛋白质相似性划分进行训练与测试。结合亲和力采用Vina评分进行估计,评分由原子或片段能量项求和而得,数值越负表明结合越强。然而已有研究指出Vina偏向生成更大的分子,因此这里进一步采用配体结合效率LBE评价分子性质,其定义为
其中Aff为分子结合亲和力,
类药性方面采用QED、SA、Lipinski五规则以及LogP进行评估。药物设计通常关注最具潜力的分子,因此对每个靶点选取测试集中得分最高的前五个分子计算平均表现。
表1的结果显示,ECloudGen在LBE指标上取得最佳表现,说明生成的分子更能有效结合蛋白靶点。DiffBP、DiffSBDD与TargetDiff等扩散模型在QED上较低,这可能源于其难以在单步中准确建模
值得注意的是,某些自回归方法如FragGen在分子性质上表现更佳,例如SA显著提升,但受限于训练片段覆盖范围,难以扩展化学空间。语言模型在SA上具有一定优势,但在LBE方面依然不及ECloudGen。
总体来看,ECloudGen能够生成兼具高结合能力、良好可合成性与类药性平衡的配体,并显著拓展化学空间。
表1|总结了ECloudGen与各基线模型在LBE评价指标及其他分子性质方面的表现。
2.2 化学空间覆盖率和多样性
该研究希望对化学空间进行量化评估,以验证ECloudGen在探索大规模化学空间方面的能力。以往研究例如Pkt2Mol多采用内部多样性IntDiv来衡量化学空间,但从点集拓扑的角度来看,稳健的化学空间度量应同时满足次可加性与不相似性偏好两个公理,而IntDiv仅满足后者,因此并非理想选择。为此,这里采用同时满足两项公理的两个指标,即Maximum Exclusion Circle(Circles)与Bottleneck,以更准确地评估化学空间的覆盖度与多样性。
Circles的定义为
Bottleneck的定义为
其中
如图2a,b所示,ECloudGen在Circles指标上达到85,显著高于下一个最佳方法的63;在Bottleneck指标上达到约1200,也高于对照方法的1063。这说明ECloudGen生成的分子覆盖更广阔的化学空间并具有更高多样性。
这种大幅扩展的化学空间归因于其在训练中引入无结构数据的方式。如图2c所示,模型的学习目标从传统的图结构
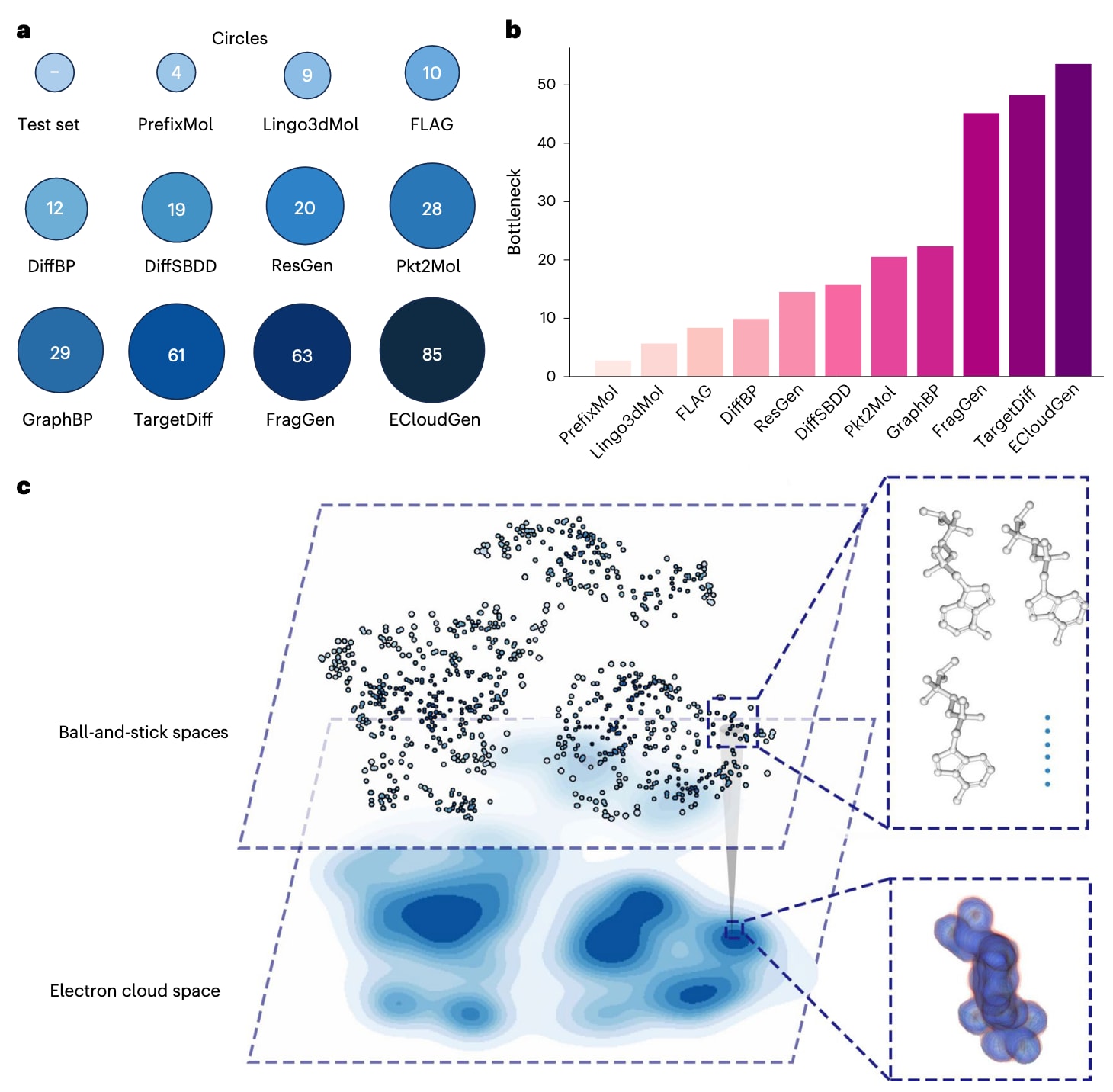
图2|ECloudGen中的定量指标与潜在空间映射 a展示了不同方法在Maximum Exclusion Circle指标上的示意图,圆形越大、颜色越深表示Circles数值越高,具体数值见补充表1。b给出了不同方法的Bottleneck指标得分,柱状越高、颜色越深表示Bottleneck数值越大。c说明在潜变量方法的支持下,ECloudGen能够将一组离散分子映射到潜在空间中的一个紧凑区域,从而在蛋白−配体数据与仅含配体数据之间建立连接。
表2|QED单目标优化结果

2.3 3D蛋白特异性的单目标优化
现有SBMG研究往往忽视分子优化的重要性,常采用事后筛选的方式,即先生成大量分子,再依据性质进行过滤。然而这种方式要求模型既具备生成多样分子的能力,又需确保其具备可药性,对现有方法而言难度极高。为解决这一问题,ECloudGen中设计了两种分子优化策略:ESpaceEvo与EPSO。ESpaceEvo受元动力学思想启发,需要目标函数的梯度信息,并能提供完整的优化轨迹;EPSO则是模型无关的粒子群优化器,仅依赖目标函数数值,无需在ECloudGen空间上额外训练代理模型。由于EPSO使用便捷,因此作为默认优化器。关于ESpaceEvo的更多细节可见补充材料第3节。
由于缺乏基于结构的分子优化基线,这里选取不含蛋白口袋约束的模型进行比较。在此设置中,ECloud Decipher的蛋白条件输入被设为零填充。参考Modof方法,将QED作为测试目标函数,并选取QED在[0.7,0.8]范围内的800个测试分子作为起点。四个基线模型包括JTNN、HierG2G、Modof-pipe与Modof-pipe(m)。JTNN与HierG2G分别基于树结构与片段图结构,通过变分推断对输入分子图进行优化;Modof-pipe逐步修改单个片段,而Modof-pipe(m)在每次迭代中利用束搜索选择前5个候选。
表2的结果表明,ECloudGen在两种成功定义下均超过所有基线。例如在QED>0.9的成功率上达到79.20%,较排名第二的HierG2G提升5%;在QED提升>0.1的标准下达到89.20%,较Modof-pipe(m)提升约2%。需要注意的是,JTNN与HierG2G均为模型特定方法,需要在潜在空间中额外训练代理函数,不可避免带来额外误差;两种Modof变体则需从低QED到高QED构建单片段修改的训练对,难以推广到新的性质。面对更复杂的真实目标函数时,这些方法均难以有效扩展。
相比之下,ECloudGen依托EPSO模块实现即插即用,无需额外模型或数据准备。其通用性将在后文的“ECloudGen在V2R内源性配体再设计中的应用案例”中进一步展示。
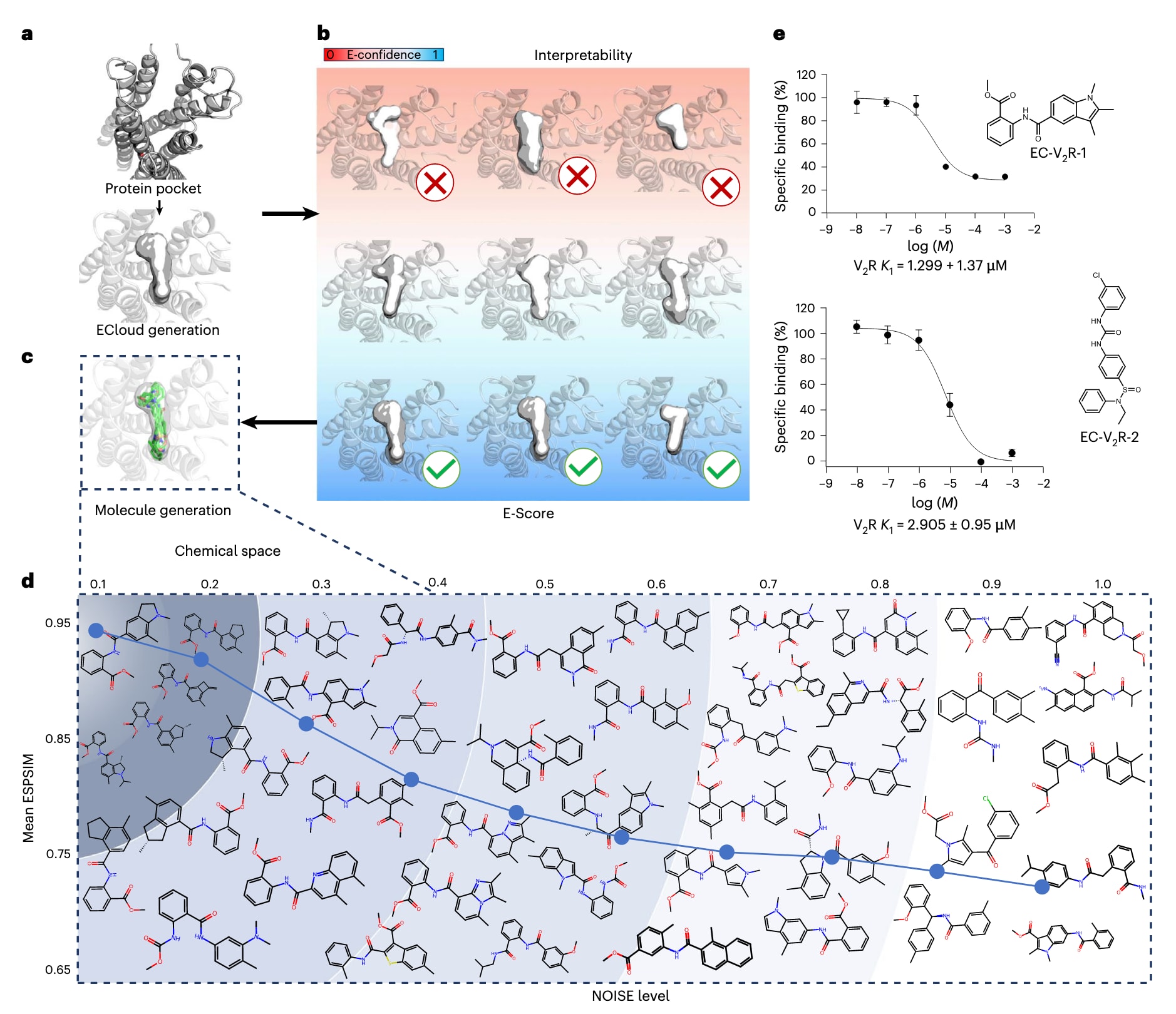
图3|ECloud在V2R设计案例中的工作流程 图3a展示了ECloud Latent Diff模块在V2R受体内生成电子云的过程。图3b中,化学研究者在E-Score排序的辅助下,从中选择合适的电子云作为潜在变量C。图3c,d显示,从选定的C出发,ECloud Decipher将其映射到连续化学空间中。在该空间内,距中心越远,分子结构的变化越大,蓝色曲线展示了化学空间中噪声水平逐渐增加的趋势。图3e展示了最终选定的两种分子并进行了合成与生物测定,其活性均达到微摩尔水平。IC50为半数抑制浓度,结果以平均值±s.e.m.表示(n=3个生物重复)。ESPSIM表示静电势相似性。
2.4 ECloudGen在V2R内源性配体再设计中的应用案例
加压素2型受体V2R是一类与肾功能障碍相关的重要G蛋白偶联受体靶点。为了展示ECloudGen作为实际分子设计流程的可行性,这里将其应用于V2R内源性配体的结构再设计,生成全新的候选分子。
从V2R的结合口袋出发(图3a),ECloud潜在扩散模块首先生成多个电子云代理,每个电子云都被赋予E-Confidence评分,用以表示模型对该潜在结构作为有效起点的信心。选择E-Confidence大于0.8的三个电子云进入后续设计步骤(图3b)。这些电子云被输入ECloud Decipher模块以生成离散的分子结构(图3c),最终得到的候选分子在电子分布上与对应的潜在电子云保持较高相似性(图3d)。
随后针对两个来自不同规模电子云的候选化合物进行了快速验证,测定结果均呈现微摩尔水平的活性(图3e)。这一案例展示了ECloudGen如何应用于临床相关的G蛋白偶联受体的内源性配体再设计,通过自动化生成与E-Confidence的简易筛选相结合,能够有效锁定具有合成与活性潜力的候选分子。
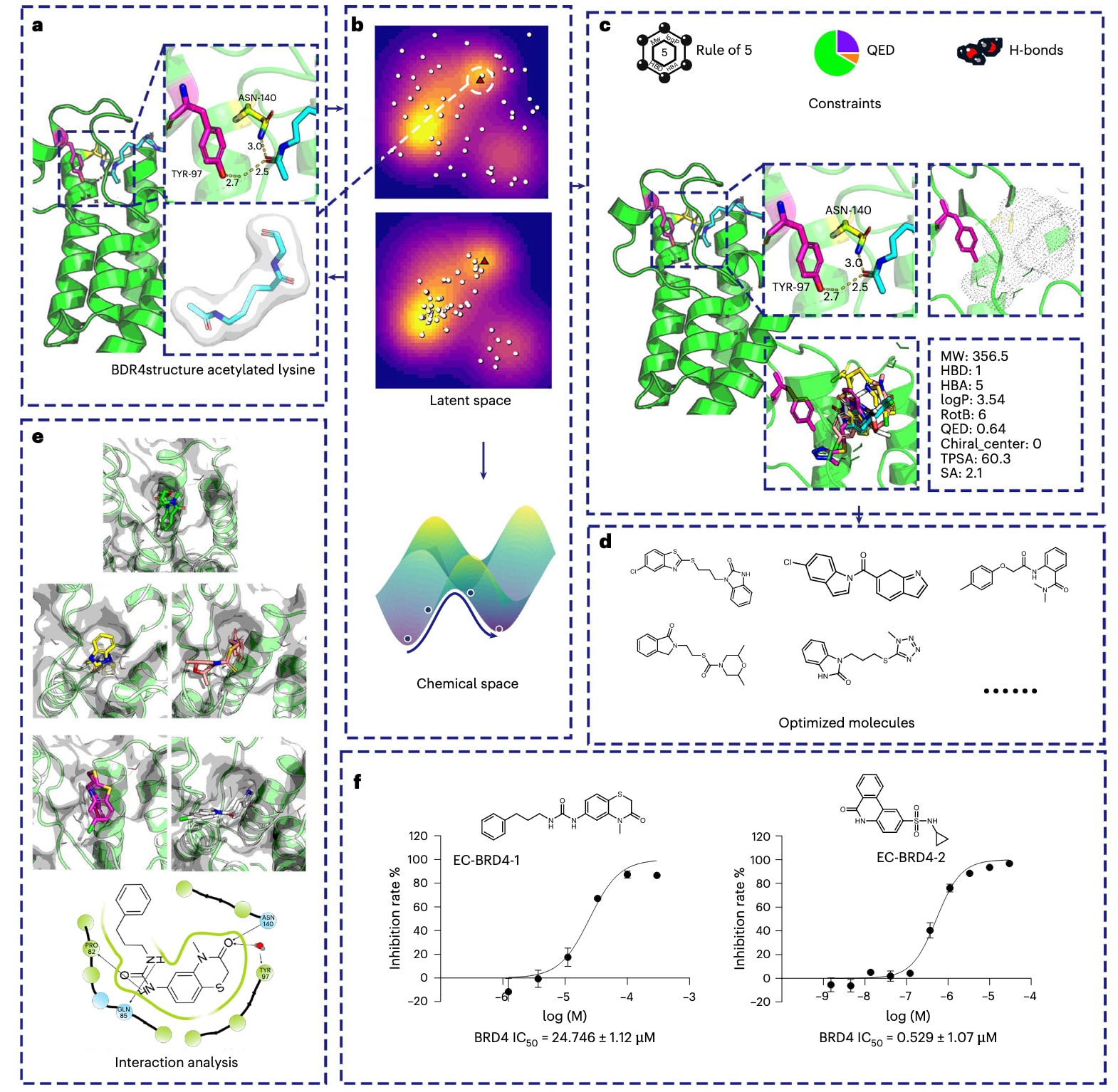
图4|ECloudGen在BRD4设计案例中的工作流程 图4a展示了BRD4的作用方式,其通过与组蛋白H3与H4中的内源性配体——乙酰化赖氨酸结合而发挥功能。图4b说明了EPSO模块在潜在空间中进行分子优化的过程。图4c给出了BRD4内源性配体再设计所需的五个优化目标,其中三个为分子性质指标,两个为BRD4案例中的特定考量。MW为分子量,HBD为氢键供体数量,HBA为氢键受体数量,LogP为分配系数,RotB为可旋转键数量,TPSA为拓扑极性表面积。图4d展示了ECloudGen优化得到的分子结构。图4e显示了部分优化分子与BRD4靶点的对接构象。图4f中,两个候选分子被选中进行合成与生物活性测定,其活性均落在微摩尔水平。IC50表示半数抑制浓度,结果以平均值±s.e.m.表示(n=3个生物重复)。
2.5 ECloudGen在BRD4多目标优化中的应用案例
含溴结构域蛋白4(BRD4)属于BET蛋白家族,其过度表达与多种癌症的发生密切相关。BRD4通过识别组蛋白H3与H4上的乙酰化赖氨酸残基发挥功能,因此针对BRD4的药物设计自然思路是构建能够与乙酰化赖氨酸竞争的外源性抑制剂,以干预BRD4在转录调控中的作用并实现治疗效果。在这一任务中,目标是设计能够保持内源性配体与BRD4蛋白结合模式的外源性配体。
基于此,首先从“内源性配体”乙酰化赖氨酸的电子云出发构建了ECloudGen的设计流程(图4a)。在选择优化目标时,MolSearch指出对QED与SA等性质过度优化会导致分子尺寸过小,因此这里将性质优化转化为约束问题。参考PocketFlow的策略,定义的性质约束包括:(1) QED>0.6,(2) SA>0.6,(3) 分子量>250,(4) Lipinski=5。同时,BRD4的共晶结构显示乙酰化赖氨酸可与Asn140与Tyr97形成关键氢键,因此加入额外约束:(5) 分子需具备至少一个氢键受体(H_acceptor≥1)。
如图4c所示,明确优化目标后,利用ECloudGen从内源性配体乙酰化赖氨酸出发进行多目标分子优化(图4b)。优化后分子的统计表现见补充表2。经过50轮PSO迭代,几乎所有分子均满足五项优化约束(图4d)。为进一步缩小筛选范围,将分子对接至BRD4并依据对接得分排序。图4e中可见优化分子仍然保留BRD4关键结合相互作用,验证了所设优化目标的合理性。
最终,药物化学家选择其中两种候选进行合成与活性测定,活性分别达到25 μM与0.5 μM(图4f)。该内源性配体再设计案例展示了ECloudGen如何模拟药物化学家的思考方式,并为其在多目标分子优化中的应用提供了明确参考。
3 讨论
该研究针对SBMG领域中的关键难题之一,即稀疏化学空间生成悖论进行探讨。通过在模型中引入潜在变量C并将
当前的限制在于,尽管整体流程显著提升了化学空间的探索能力,但最关键的瓶颈仍在第一阶段,即根据蛋白−配体复合物生成电子云的步骤。该阶段的准确性受限于蛋白−配体数据的数量与质量,因此成为预测性能的主要制约因素。此外,输入结构中的口袋模糊性可能导致电子云提议质量不佳。尽管后续的Decipher阶段能够利用蛋白口袋特征对这些缺陷进行一定程度的补偿,但整体性能仍受到初始电子云质量的上限所限制。
未来工作可探索更强的三维生成模型以提升电子云提议的质量,例如用基于表面的生成方法替代当前的稀疏网格表示,以更准确捕捉蛋白口袋的精细结构。此外,ECloudGen方法也具有扩展潜力,可应用于诸如蛋白设计等其他分子设计任务。