APSB 2025 | PhenoModel: 一种基于多模态表征的表型药物设计基础模型
该研究提出了一个基于双空间对比学习的多模态表型药物发现基础模型PhenoModel,将分子结构空间与细胞表型空间紧密联结:一方面通过子图编码器刻画分子构象与骨架特征,另一方面借助QFormer+ViT从Cell Painting等细胞图像中提取药理相关表型信号,并通过“分子–分子”和“分子–图像”两级对比学习实现统一表征。实验结果显示,在TDC的ADMET性质预测任务上,PhenoModel性能可与大规模预训练的分子模型相媲美,而在表型驱动的虚拟筛选任务、NCI多癌种细胞系活性筛选以及DUD-E和LIT-PCBA等经典基准上,PhenoModel整体优于基线方法,尤其在早期富集和活性分子区分方面表现突出。基于此表征,研究团队进一步构建了表型驱动筛选流程PhenoScreen,在大规模商用化合物库中成功发现了多个对骨肉瘤、横纹肌肉瘤具有显著抑制活性的先导分子,证明其在实际药物发现中的可用性与推广价值。尽管当前版本仍受限于分子和细胞系多样性不足以及表型数据噪声等因素,该工作表明:将分子结构与细胞表型在统一对比学习框架下进行多模态融合,是推动表型药物发现与AI辅助药物设计的重要发展方向。

获取详情及资源:
- 📄 论文: https://doi.org/10.1016/j.apsb.2025.09.036
- 💻 代码: https://github.com/Shihang-Wang-58/PhenoScreen
0 摘要
表型药物发现(phenotypic drug discovery, PDD) 侧重于考察细胞或机体在药物处理后的可观察性状或表型,而非主要依赖预设的分子靶点。通过这种路径发现的药物通常具有更高的治疗相关性,因为其筛选与验证过程往往更接近真实的人类疾病状态。该研究提出了 PhenoModel,一种基于多模态信息的分子基础模型,构建于独特的双空间对比学习框架之上,用于有效联结分子结构与表型信息。PhenoModel 适用于多类下游药物发现任务,包括分子性质预测,以及基于靶点、表型和配体信息的活性分子筛选。结果表明,PhenoModel 在上述任务中整体优于多种基线方法。在此模型基础上,研究团队进一步构建了 PhenoScreen,成功识别出多种对骨肉瘤和横纹肌肉瘤细胞系具有表型活性的化合物。相关发现表明,PhenoModel 具有良好的通用性与应用潜力,有望通过挖掘新的治疗通路、扩展有效候选药物的结构多样性,加速药物发现进程。
1 引言
表型药物发现(phenotypic drug discovery, PDD)是一种经典且强有力的药物研发策略。传统的药物发现主要依赖靶点导向药物发现(target-based drug discovery, TDD),即重点寻找能够与特定生物靶点相互作用的化合物。与此不同,基于表型的策略并不要求事先明确作用靶点,而是通过观察药物处理后生物系统的表型变化(如细胞形态改变、疾病状态逆转或特定信号通路的调控)来筛选候选化合物。由此可以发现作用于新靶点或多靶点的潜在治疗化合物,使PDD在分子机制未知或可用治疗方案有限的疾病中尤为重要。既往回顾性分析也表明,多数“first-in-class”药物源自PDD而非TDD,进一步强调了PDD在复杂疾病创新疗法发现中的关键作用。
与TDD相比,PDD具有多方面优势。首先,PDD能够在更广泛的生物系统层面进行探索,有利于发现具有多靶点作用(多药理学,polypharmacology)的药物,从而可能提升疗效。此外,PDD非常适合用于发现靶点未知或新作用机制相关的“first-in-class”药物,这对于应对复杂或尚未充分理解的疾病尤为关键。已有工作提出了通过汇总外源扰动来开展高通量表型筛选的方法,使得在信息密度极高的读出条件下进行表型筛选成为可能,从而推动了药物发现与基础生物学研究的进展。然而,PDD同样面临诸多挑战,包括靶点解析困难以及大规模筛选成本高昂等问题。高内涵成像(high-content imaging)的发展,例如 Cell Painting 技术,为捕获细胞表型提供了新工具,但现实中的大规模筛选仍然资源消耗巨大,因此亟需高效的计算方法来在大尺度上处理和解析表型数据。
近年来,人工智能(AI),尤其是深度学习,在复杂表型数据分析中发挥了重要作用,覆盖高内涵筛选(HCS)图像、转录组特征以及多组学数据等场景,使得在尚未明确分子靶点的情况下也能挖掘潜在候选药物。引入多样化的计算生物学方法辅助早期药物发现,有望帮助研究者探索传统实验难以覆盖的更广阔化学空间。基于AI的策略通过将表型信息与分子表征相结合,有潜力加速药物发现进程,并更快速、准确地预测化合物疗效。例如,有工作提出基于变分自编码器的表型表示模型,用于刻画细胞环境与化合物效应,并支持基于表型的药物重定位;也有研究构建了基于知识图谱的表型-靶点一体化模型,用于表型和靶点驱动的药物发现流程,并成功获得多种新型 hit 化合物。
已有研究还表明,细胞形态学特征在预测药物疗效方面可以对化合物结构信息形成有效补充。将这些表型数据与机器学习或深度学习方法相结合,已成为药物发现领域的新兴方向。例如,Broad Institute 提出的 Cell Painting 技术通过采集高内涵细胞图像以分析细胞形态,在揭示药物作用机制(mechanism of action, MOA)、预测生物活性以及毒性评估等方面表现出良好效果。后续工作利用高通量显微成像数据结合卷积神经网络预测不同化合物的生物实验结果,或者开发基于深度学习的高通量细胞图像分析方法,用于预测化合物生物活性。最近也有研究将视觉Transformer(如 SwinV2)直接应用于 Cell Painting 图像,从中预测激酶抑制剂的作用机制。
当将整合后的细胞形态学特征与AI模型联合使用时,可以在分子结构信息之外引入细胞表型反应,从而获得更加整体的化合物生物效应视角。近年,Broad Institute 联合多家制药企业与学术机构,发布了多批大规模 Cell Painting 数据集,这些数据集包含了海量细胞显微图像及组学分析结果,覆盖数十万种化合物,以及基因敲除和过表达等扰动条件,为构建强大的深度学习框架、发展基于表型的药物筛选甚至生成式设计方法提供了重要数据基础。
在如此庞大的化学空间下,要全面探索针对特定生物测定(bioassay)的活性分子几乎不可能,这也是当前亟待解决的核心难题之一。已有部分工作开始探索将分子结构与与表型活性相关的特征相结合,以提升虚拟筛选效率。例如,有方法通过对比学习联合建模分子结构与细胞表型信息,在生物活性预测与作用机制判别任务中取得了明显性能提升。总体来看,机器学习和深度学习在形态学分析中的应用,极大丰富了表型药物发现的工具箱,覆盖了小分子 MOA 解析、先导化合物优化以及毒性预测等多个环节。然而,这类方法往往高度依赖高质量的细胞成像数据,而后者在现实场景中相对稀缺;此外,这些模型在跨细胞系或跨实验条件时的泛化能力仍具有不确定性。就当前公开报道情况来看,尚缺乏经实验验证、真正实现“细胞形态信息驱动表型筛选”的AI计算方法。高成本与受限通量仍然使表型筛选成为早期药物发现中的瓶颈环节。
为应对上述问题,该研究提出了一种多模态分子基础模型 PhenoModel,基于专门设计的双空间对比学习框架,旨在弥合分子结构与表型信息之间的鸿沟。通过联合训练分子图编码器和基于 QFormer 的 ViT 图像编码器,PhenoModel 能够学习同时包含化学结构信息与表型扰动信号的统一化合物表征,从而增强其在多个靶点与疾病模型中的疗效预测能力。
在系统性的测试、验证与应用研究中,PhenoModel 在多靶点、多疾病模型以及多种化学骨架上的表现均体现出良好的稳健性与泛化能力。通过在同一框架中统一分子结构与表型响应,PhenoModel 不仅能够加速 hit 化合物的发现,还为后续扩展(例如整合多组学数据、原代细胞筛选等)提供了通用平台,为构建更加可及、机制驱动且具成本效益的药物设计流程奠定了基础。
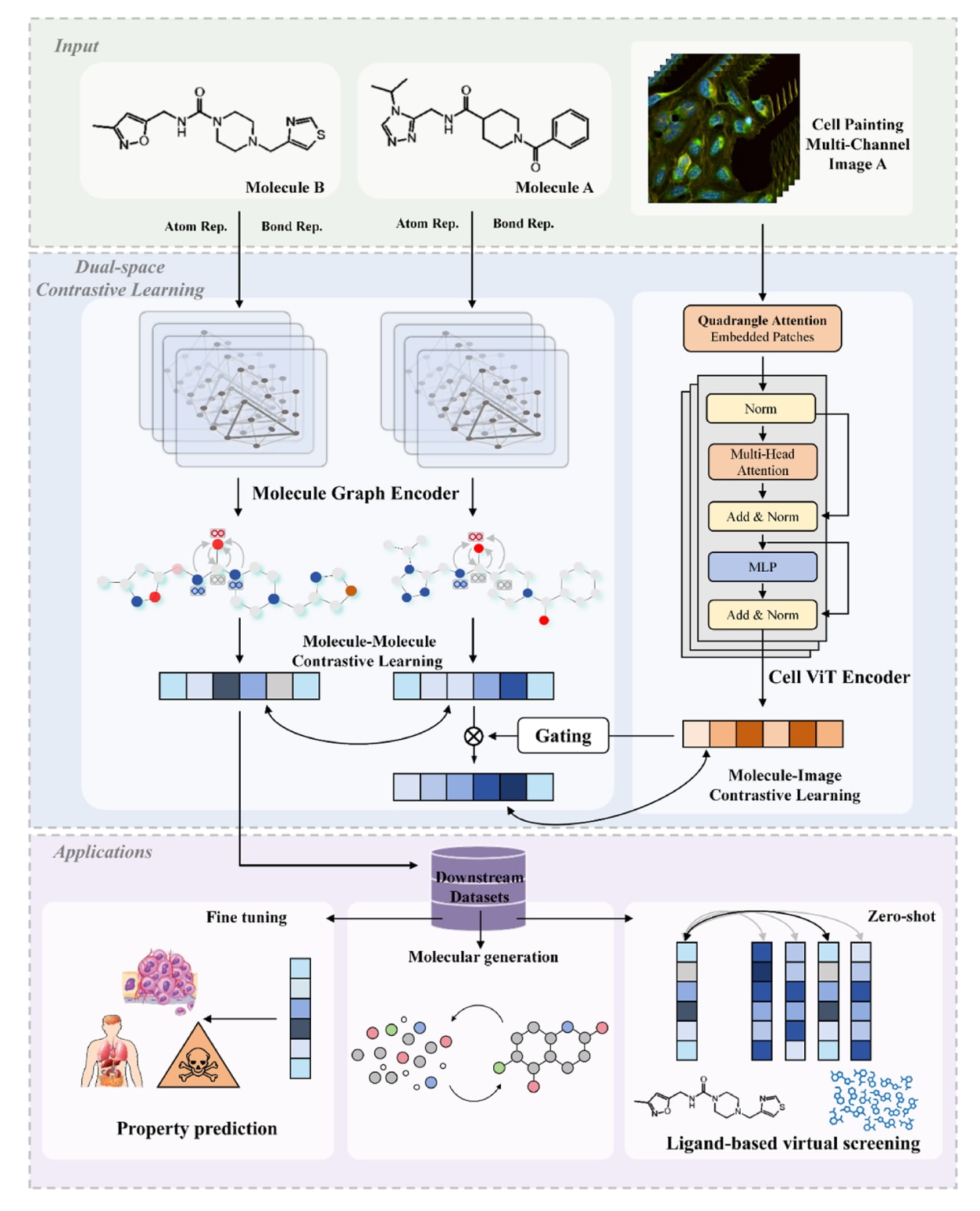
图1 | 展示了PhenoModel架构示意图及其在多种下游任务中的潜在应用。 PhenoModel由分子图编码器、细胞ViT编码器(Cell ViT Encoder)、分子–分子主对比学习模块以及分子–图像逐步对比学习模块组成。基于该表征模型,可以无缝集成多类药物设计任务,包括零样本场景下的活性化合物虚拟筛选、ADMET预测及其他相关应用。
2 结果
2.1 基于双空间对比学习构建多模态分子基础模型
该研究提出了多模态分子基础模型 PhenoModel,其核心是专门设计的双空间对比学习框架,用于同时联结分子的化学结构空间与其诱导的细胞形态表型空间,如图1所示。该基础模型由四个主要模块构成:两个特征提取模块——分子图编码器(Molecule Graph Encoder)和细胞ViT编码器(Cell ViT Encoder);以及两个对比学习模块——分子–分子主对比学习模块和分子–图像逐步对比学习模块。PhenoModel的具体参数设置信息见补充材料表S1。
表1 | 展示了PhenoModel不同变体在DUD-E和LIT-PCBA数据集上的性能表现。

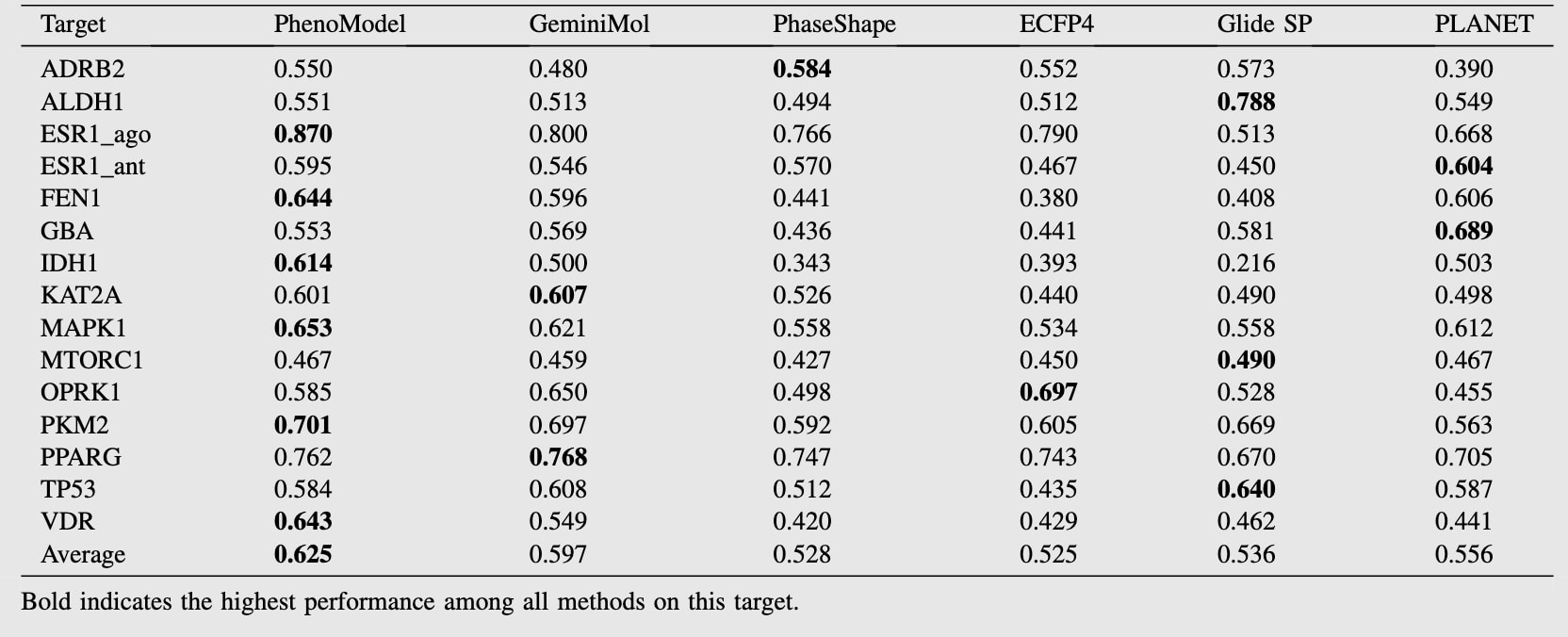
为评估PhenoModel的有效性,研究团队在两个公认的靶点导向虚拟筛选基准数据集 DUD-E 和 LIT-PCBA 上进行了模块消融实验,考察其整体活性分子筛选能力(AUROC)与早期富集能力(EF1%)。在评估过程中,利用分子嵌入来计算参考分子与其他分子之间的相似性,从而识别活性分子,以便解析PhenoModel中各策略的具体贡献。分析重点放在:分子–图像对比学习模块、分子–分子对比学习模块以及**门控机制(gating mechanism)**的作用上。如表1所示,引入细胞图像信息(即加入分子–图像对比学习模块)的PhenoModel,在各项指标上均优于不含该模块的模型,说明细胞图像信息确实能够增强分子表征能力。针对LIT-PCBA中各个靶点的活性分子筛选结果列于表2和表3。
表2 | 展示了PhenoModel不同变体在DUD-E和LIT-PCBA数据集上的性能表现。
值得注意的是,当未采用双空间对比训练(即去除分子–分子对比学习模块)时,模型性能出现明显下降。这种下降很可能源于:在仅基于图像的对比学习过程中,为了将分子嵌入对齐到图像嵌入空间,分子编码器的参数发生偏移,从而削弱了其原有的结构编码能力。通过联合训练,可以在保留分子编码器对结构信息的固有表征能力的同时,引入来自细胞图像的活性相关信息,从而提升PhenoModel的综合表征性能。此外,在对比训练中移除门控机制同样会在一定程度上导致性能劣化,这进一步表明各模块在PhenoModel中均不可或缺。
研究团队还评估了不同图像编码器对对比学习效果的影响,如补充材料图S1所示。当使用 ResNet18 或 ViT 作为图像编码器时,同一分子对应的多张细胞图像在编码并降维后,并未在特征空间中有效聚集。而在引入 QFormer Attention 后,同一化合物对应的多张细胞图像在特征空间中呈现出显著更紧密的分布。这表明,Cell ViT Encoder 能够使图像编码器更准确地从细胞图像中提取表型特征,从而显著提升整体表征与对比学习效果。
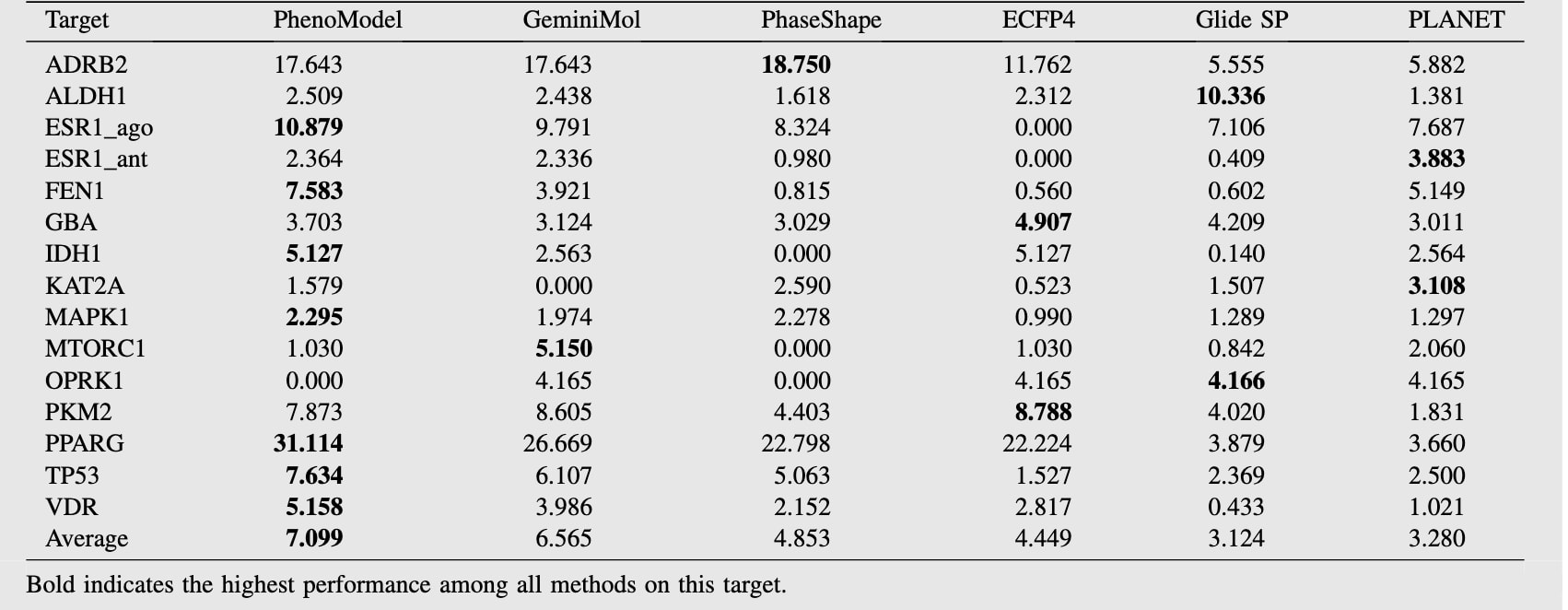
表3 | 展示了不同模型在 LIT-PCBA 数据集上的 EF1% 表现。
2.2 PhenoModel在分子性质预测任务上优于基线方法
分子的动态性质(如跨膜通透性)是影响药物效力和细胞表型的重要因素之一。在新药研发过程中,药物分子在体内的吸收(Absorption)、分布(Distribution)、代谢(Metabolism)、排泄(Excretion)和毒性(Toxicity),即ADMET性质,是衡量候选化合物成药性的重要指标。通过在特定任务上学习不同分子的特征模式,可以构建模型,用于预测分子活性及多种ADMET性质,在药物设计流程中发挥关键作用。该研究将PhenoModel与GeminiMol、Uni-Mol、FPGNN、MIGA、以及多种组合分子指纹(CombineFP,由ECFP4、FCFP6、AtomPairs和Topological torsion组合而成)和各类单一分子指纹进行对比评估,测试了TDC数据集中22个具有公开排行榜的ADMET性质预测任务,其中包括13个分类任务和9个回归任务。结果(见图2A、2B及补充信息表S2和S3)表明:在整体预测性能上,PhenoModel与基于ChEMBL大规模预训练的Uni-Mol相当。
ADMET本质上属于更高层级的“表型”数据,在多数情况下很难与细胞水平的形态学变化直接建立对应关系。因此,在ADMET性质预测方面,PhenoModel相较于经过亿级分子预训练的Uni-Mol并未表现出显著优势,但依然具有较强的竞争力,并在代谢与排泄相关性质的预测上优于多数基线方法。需要强调的是,PhenoModel并未像Uni-Mol那样在数亿规模的分子库上进行预训练。同时,与同样利用细胞图像信息进行预训练的MIGA相比,PhenoModel在所有评估指标上均显著优于MIGA,体现了双空间对比学习策略的优势。总体来看,PhenoModel已经能够较为全面地表征分子结构与表型信息融合特征,并有望在与细胞表型更紧密相关的任务中展现出更明显的性能优势。
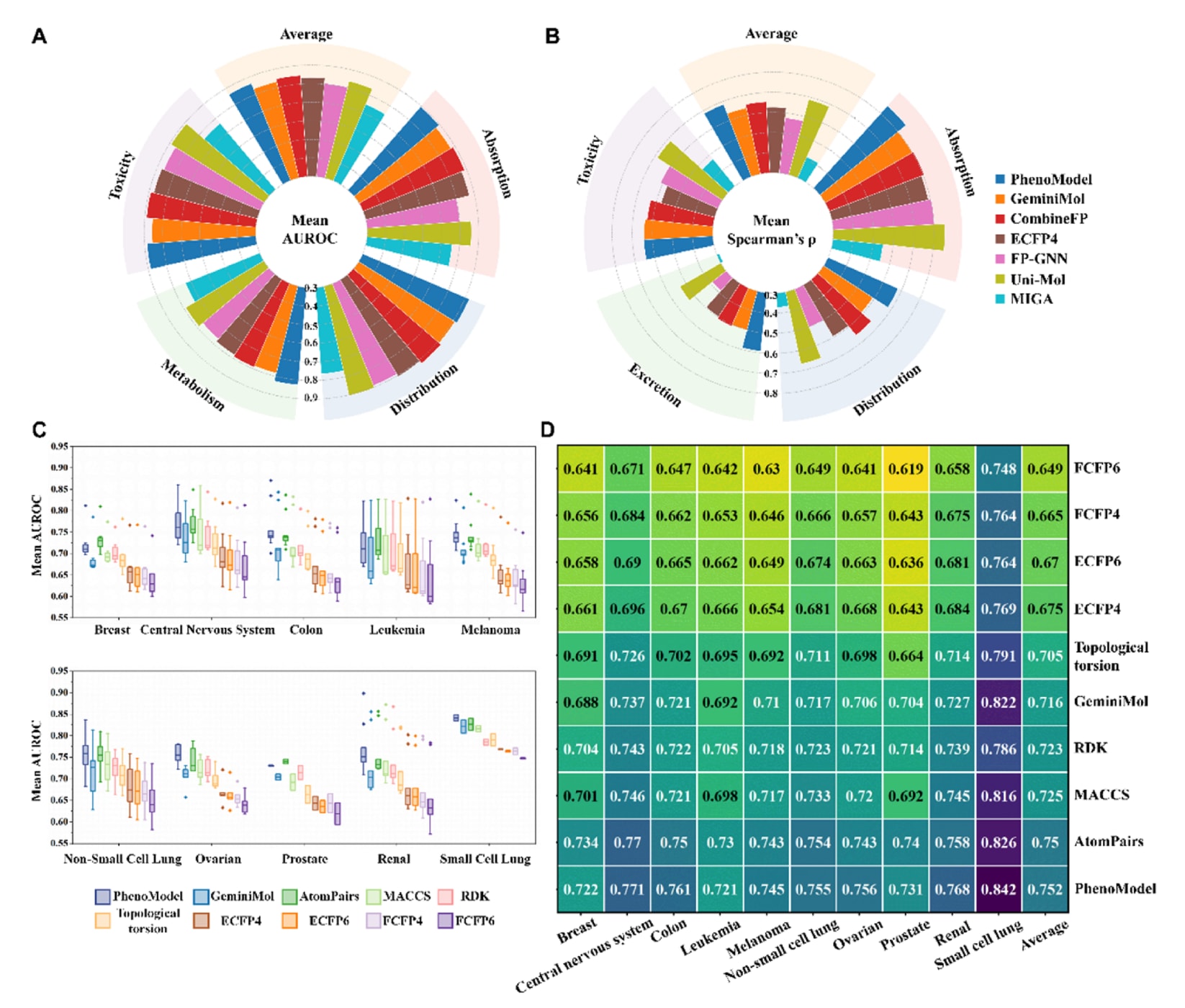
图2 | 展示了PhenoModel与多种基线方法在分子性质预测和虚拟筛选任务中的对比。 (A) 在Therapeutics Data Commons (TDC)数据集中13个ADMET分类任务上的AUROC。(B) 在9个TDC ADMET回归任务上的Spearman相关系数ρ。(C) 各癌症类型中所有细胞系的AUROC箱线图。(D) 横轴表示十种不同癌症类型,纵轴表示不同的分子表征方法。热图中每个方格的数值表示对应方法在该癌症类型所有细胞系上进行活性分子筛选时的平均AUROC。
2.3 PhenoModel在基于表型的虚拟筛选中优于基线模型
细胞图像的表型信息通过分子–图像对比学习模块被注入到PhenoModel中,是该模型的重要组成部分。由于细胞表型通常反映了分子在生物体系中乃至多靶点调控层面的综合效应,该研究团队尝试系统评估这类表型信息如何补充并增强PhenoModel的分子表征能力。为此,研究团队从美国国家癌症研究所药物开发项目(NCI/DTP)中收集了73个细胞表型活性实验数据集,这些数据集分别来自10类肿瘤的73条不同细胞系,包括乳腺癌细胞系、中枢神经系统细胞系、结肠癌细胞系、白血病细胞系、黑色素瘤细胞系、非小细胞肺癌细胞系、卵巢癌细胞系、前列腺癌细胞系、肾癌细胞系以及小细胞肺癌细胞系。每个数据集中测试分子的平均数量约为4.3万,平均活性分子约为2.8千个。由于细胞活性往往不仅受单一靶点影响,还可能来自多靶点协同作用,因此该任务具有更高难度。
在基准测试中,研究团队选取了八种不同的分子指纹方法,以及此前提出的基于构象集合的分子表征方法GeminiMol,并与PhenoModel进行对比。测试过程中,所有分子首先分别用各自的方法独立编码,然后通过计算查询分子与参考分子之间的相似度来区分其在不同细胞系中的活性与否。考虑到细胞表型变化可能由多种作用机制共同驱动,每个生物实验为查询时都会随机选取多个参考分子。最终,计算各方法在每一类癌症下所有细胞系上的平均AUROC。如图2C、2D、支持信息图S2及表S4所示,在十类癌症细胞系中,PhenoModel在活性分子筛选任务上整体表现最为突出,尤其是相较于仅依赖分子结构信息训练的GeminiMol,优势十分明显。这一结果表明,引入细胞表型信息显著增强了分子编码器对与生物活性相关特征的刻画能力。
2.4 PhenoModel在基于靶点的活性化合物筛选中同样表现出色
同时,该研究团队在药物设计中两类重要的虚拟筛选任务上评估了PhenoModel的性能:DUD-E和LIT-PCBA。DUD-E包含102个靶点,LIT-PCBA包含15个靶点,常用于评估虚拟筛选算法的效果。所有分子均由PhenoModel独立编码,然后通过计算查询分子与参考分子之间的相似度来区分其在不同靶点上的活性与否。为保证评估公平性,测试过程中采用了既往研究中常用的策略,即将官方PDB模板中给出的配体作为参考分子。在虚拟筛选能力评估场景中,LIT-PCBA相较于DUD-E更具挑战性。原因在于:在DUD-E中,每个靶点的活性/非活性分子比例相对固定,且结构差异较为充足,任务设置更接近“标准化”的理想情况,而这种数据条件在真实药物发现中其实并不常见。与之相比,LIT-PCBA更贴近实际应用:活性悬崖广泛存在,作用机制复杂,各任务中活性分子比例差异显著,因此难度更高。基于此,LIT-PCBA被视为该研究的主要虚拟筛选基准数据集。
在对比实验中,PhenoModel与多类基线方法进行了系统对比,包括:(I) 基于分子构象集合相似性比较的GeminiMol;基于三维药效团与形状对齐的PhaseShape;以及多种分子指纹方法(包括ECFP4、ECFP6、FCFP4、FCFP6、MACCS、RDK、AtomPairs与Topological Torsion),其中以ECFP4作为代表;(II) 经典分子对接方法Glide SP;(III) 基于药物–靶点亲和力预测的PLANET方法。结果表明,在DUD-E和LIT-PCBA两类任务上,PhenoModel均表现优异(见表2、表3及支持信息表S5和S6)。在DUD-E的102个靶点中,PhenoModel在32个靶点上的AUROC超过0.9,在57个靶点上的AUROC超过0.8,整体平均AUROC达到0.803,显著优于其他基线方法(见表S4)。图3展示了PhenoModel与ECFP4在多个靶点上的分子编码可视化结果:PhenoModel在特征空间中对活性分子和非活性分子的区分更加明显,大部分活性分子在分布上紧邻参考分子,而ECFP4编码下部分活性分子则分布较为离散。这说明PhenoModel能够更有效地捕捉活性与非活性分子之间的表征差异。
在更具挑战性的LIT-PCBA任务中(见表2、表3与表S6),PhenoModel在15个靶点中的8个靶点上,其整体筛选性能和早期富集指标均超过各类对比基线方法。与Glide SP和PLANET不同的是,PhenoModel在虚拟筛选过程中并未利用任何靶蛋白结构信息,这从侧面进一步凸显了其在分子表征方面的优越性。此外,相较于仅基于分子结构信息训练的GeminiMol,PhenoModel在大多数靶点上的活性分子虚拟筛选任务中表现更佳,表明细胞表型中携带的活性信息的确提升了分子表征能力及活性分子筛选能力。
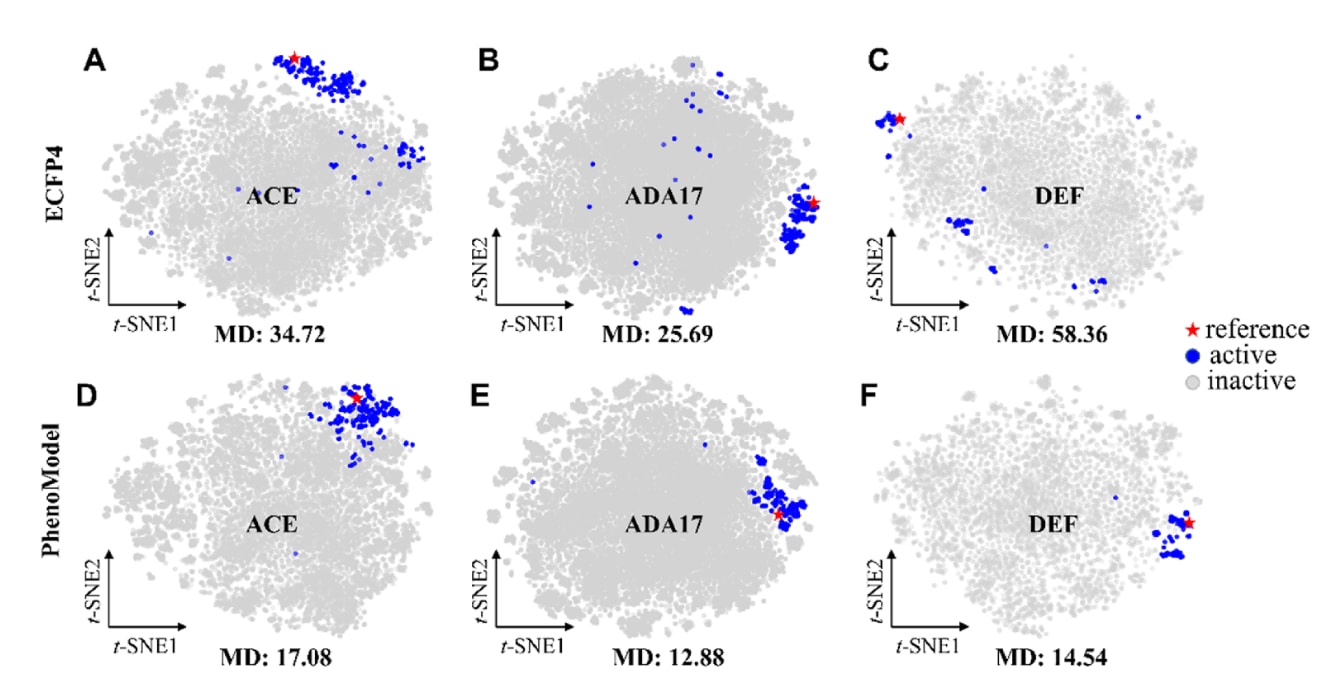
图3 | 展示了t-SNE可视化ACE、ADA17和DEF三个靶点的分子表征。 MD表示特征降维后所有活性分子与参考分子之间的平均距离。(A–C) 为ECFP4编码的分子;(D–F) 为PhenoModel编码的分子。与PhenoModel相比,ECFP4编码下的活性分子在特征空间中距离参考分子更远,这表明PhenoModel在分子表征方面可能更加有效。
2.5 PhenoModel的PDD筛选流程
为评估PhenoModel在真实药物设计场景中的应用潜力,该研究构建了一个基于PhenoModel的活性化合物筛选流程,命名为PhenoScreen,用于在已知活性化合物的基础上,进一步筛选具有相似活性但骨架新颖的分子。研究团队首先从Ardigen的PhenAID数据库中收集了7个可影响U2OS细胞系表型的化合物,并从文献中筛选出4个对骨肉瘤具有抑制作用的分子(参考活性化合物的详细信息见补充信息表S7)。在已知表型及文献报道活性信息的前提下,该研究期望通过PhenoScreen筛选出更多具有相似或更优表型的新分子。
随后,研究团队使用这些活性参考分子作为“起始模板”,在Specs化合物库(共包含约335,000个分子)中利用PhenoScreen进行相似性筛选,具体流程如图4A所示,最终获得候选分子A1–A15。通过CCK-8实验对这些候选分子的细胞活性进行评估(图4B和4C),结果显示大多数筛选得到的分子在细胞水平具有明显的抑制活性。进一步采用Cell Painting实验观察这些化合物对细胞表型的影响,结果令人瞩目:A3、A5和A9的诱导表型与参考分子高度相似,而A11和A15在细胞水平表现出比参考分子更强的抑制活性(图4D)。这些分子有望作为骨肉瘤治疗候选药物进一步深入研究。
在此基础上,该研究还考察了PhenoScreen在其他疾病场景中的可迁移性。结合前期研究结果,从文献中选取QC6352和ML324作为横纹肌肉瘤的潜在治疗药物,同时选取indisulam作为白血病的参考化合物。基于PhenoModel,在商业化合物库中进行相似性筛选,获得候选分子A16–A22。Cell Painting与CCK-8实验结果表明,这些候选分子相较于参考化合物具有更强的细胞抑制能力(图4E及补充图S3)。其中,A16、A18、A21和A22在横纹肌肉瘤及白血病相关细胞系中展现出较好的活性潜力,表明PhenoScreen在多疾病场景下均具备良好的活性分子筛选泛化能力。
综上,PhenoScreen通过捕捉分子诱导的细胞表型信息,能够筛选出表型相似、甚至抑制活性更强的候选分子,是一种适用于多种疾病场景的优良初始命中(hit)发现策略。在实际应用中,参考分子常常需要通过结构修饰进一步提升活性或改善药代性质,而PhenoScreen在筛选过程中同时利用结构信息与表型信息,有望为后续的活性优化与ADMET性质改善提供更具指导性的候选分子。此外,PhenoScreen也可用于活性分子的骨架跃迁(scaffold hopping),帮助探索具有新化学骨架的新型活性分子。
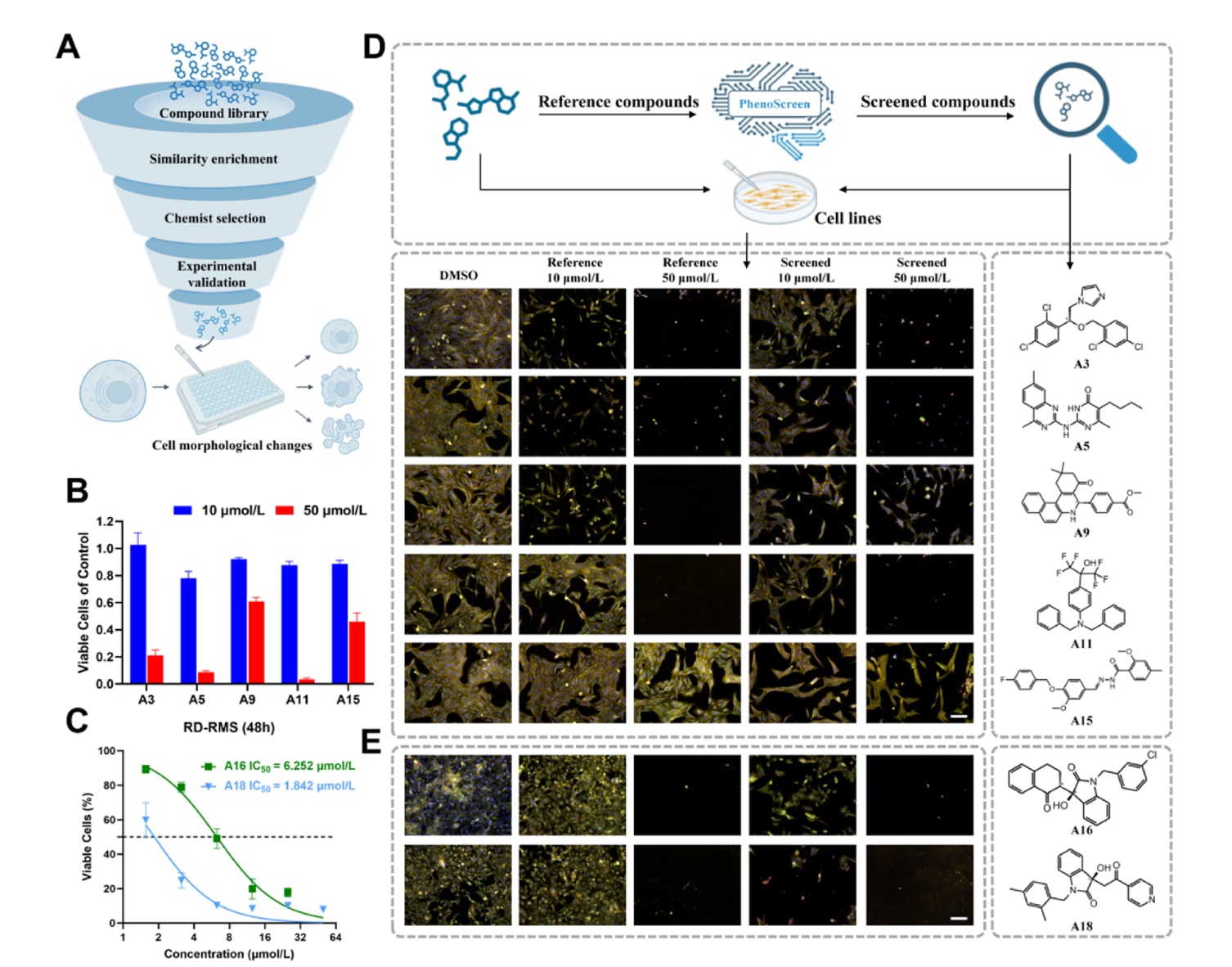
图4 | 展示了PhenoModel的表型药物筛选流程及其实验结果。 (A) 在化合物库与预先定义的参考分子之间进行相似性计算,用于富集高相似度分子。随后,由化学家从这些高相似度分子中进行筛选,并通过实验验证其在细胞水平上的抑制能力及形态学变化。(B) 针对U2OS细胞筛选所得分子的细胞活性检测结果。(C) 所鉴定的表型活性化合物A16(6.252 μmol/L,置信区间:5.590–6.994 μmol/L)和A18(1.842 μmol/L,置信区间:1.470–2.148 μmol/L)对横纹肌肉瘤的半数抑制浓度(IC₅₀)。(D) 在U2OS细胞系中,对筛选分子进行Cell Painting实验得到的细胞表型结果表明,A3、A5和A9诱导的表型变化与参考分子相似;相比之下,A11和A15诱导的细胞表型变化更为显著,提示其具有更高的潜在抑制活性。比例尺 = 100 μm。(E) 针对横纹肌肉瘤筛选所得活性分子的Cell Painting细胞表型结果。A16和A18相较于参考分子诱导出更强烈的细胞表型变化,提示其具有更高的潜在抑制活性。比例尺 = 100 μm。
2.6 面向高效虚拟筛选与靶点识别的在线公开Web服务器
为了便于研究人员使用PhenoModel,该研究团队在 https://bailab.siais.shanghaitech.edu.cn/services/PhenoModel/ 搭建了一个易于使用的在线Web服务器。该服务器支持基于化合物相似性的虚拟筛选功能。用户只需上传一个感兴趣的活性化合物的SMILES串,并从支持的分子库中进行选择,网站即可返回按相似度排序的前3000个候选分子及其相似度得分。考虑到分子库中结构多样性及实际合成难度,该平台提供了多个分子库选项,例如Specs(超过33.5万条分子)、LifeChemicals(超过61.6万条分子)以及Chemdiv(超过170万条分子)。在任意一个分子库中,以单个参考分子为基础进行一次筛选的时间约为1分钟。
此外,通过表型筛选获得的小分子,其作用靶点机制的解析有助于拓展新靶点发掘策略。因此,该研究还在对BindingDB数据库进行预处理的基础上构建了一个名为DTIDB的基准数据集。该数据集可以通过检索与查询分子结构相似的已知活性化合物及其对应靶点,帮助研究者推测和识别候选分子的潜在作用靶点。总体而言,这两类基于PhenoModel的应用——相似性虚拟筛选与靶点识别——有望为更多后续的药物发现研究提供便捷而高效的计算支持。
3 总结
该研究提出了一种基于双空间的表型药物发现基础模型PhenoModel,将分子结构空间信息与生物活性表型空间信息进行有机融合。PhenoModel不仅充分表征了分子的构象信息,还引入了细胞表型中所蕴含的活性信号。基准实验结果表明,PhenoModel所学习到的分子表征在虚拟筛选任务中发挥了重要作用,并且在分子性质预测任务上表现出与多种专用模型相当的性能。此外,PhenoModel在活性分子识别方面同样表现优异,无论是在DUD-E和LIT-PCBA等经典单靶点虚拟筛选任务中,还是在NCI多种癌细胞系的多靶点活性测定任务中,均展现出强大的筛选能力。
在此基础上,研究团队构建了一个基于PhenoModel的表型驱动活性分子筛选流程PhenoScreen,用于发掘对多种癌细胞系具有表型活性的候选化合物,并成功发现了多种高活性先导分子,展示了该方法在实际药物发现中的广泛应用潜力。
当然,PhenoModel目前仍存在一定局限性。其一,相较于庞大的化学空间,当前用于训练的分子结构数据规模仍然有限,仅包含约3万条单体化合物结构,这对于需要全面覆盖多样分子结构的任务(如特定分子性质预测)而言仍显不足。因此,在相关基准测试中,PhenoModel在某些场景下尚难超越如Uni-Mol等在数以亿计分子上预训练的大规模表征模型。尽管PhenoModel在小分子相关任务上表现出较好的泛化能力,其预训练数据中宏环、环肽以及其他低频骨架的样本仍然相对缺乏。未来工作的一个关键方向,是通过引入骨架多样性更高的数据集来扩展PhenoModel在更广泛化学空间中的适用性,例如纳入cpg0016数据集、Tahoe-100M数据集以及具有更多独特结构特征的宏环化合物,从而进一步提升化学空间覆盖度。
其二,细胞表型数据本身所承载的信息,可能不足以完全支撑某些对高维分子信息表征要求更高的任务。目前版本的PhenoModel仅基于U2OS细胞系的细胞图像进行训练。虽然已经在其他癌细胞系上进行了性能测试,但尚难保证在所有细胞类型或更广泛的细胞系范围内保持稳定表现。这一现象与不同细胞类型(特别是原代细胞或不同组织来源细胞)之间表型特征存在明显差异密切相关,可能对模型的泛化性构成限制。为缓解这一问题,后续工作将引入更丰富的细胞背景信息,包括原代细胞数据等,以增强模型的鲁棒性与适用范围。同时,引入类类器官(organoid)系统中分子作用过程的动态信息,也可能进一步提升PhenoModel在分子表征层面的表现力。
此外,细胞图像数据不可避免地受到实验噪声的影响,如何获取更干净、更高信息量的表型数据,是当前相关研究领域亟待解决的共性问题之一。值得注意的是,转录组层面的变化在表型驱动药物设计中同样至关重要。未来,若能在统一框架下联合利用分子结构、细胞图像与转录组等多模态信息,有望进一步提升模型的分子表征能力与机制解析能力。与此同时,在将表型信息融入分子表征模型的过程中,需要避免破坏原有分子编码器对结构信息的刻画能力,因此有必要设计如联合训练等策略,以减轻多模态融合带来的潜在风险,尤其是在此类复杂多模态模型中。
研究团队计划在后续工作中持续强化PhenoModel的表征能力。随着更多任务相关训练数据的不断补充,PhenoModel有望在虚拟筛选与分子性质预测等常见药物设计任务中展现出更优性能,并在基因–化学扰动关联建模、基于表型的分子生成等方向发挥重要作用,从而为加速药物发现过程提供更加有力的计算工具支撑。