NCS 2025 | SynGFN:利用生成式基于流的分子发现方法跨化学空间学习

获取详情及资源:
0 摘要
近年来,人工智能显著推动了“设计−合成−测试−分析”循环的发展,深刻改变了分子发现过程。然而,即便取得了诸多进展,计算辅助的分子设计与合成仍然以相互割裂的方式运行,成为进一步优化这一循环的关键瓶颈。基于此背景,提出了SynGFN,将分子设计视为一系列模拟化学反应的级联过程,从可合成的基本结构单元出发逐步构建目标分子。SynGFN包含两个核心要素:一是分层预训练的策略网络,能够在多样化的化学空间中高效学习并适应不同分布的目标分子;二是多保真度采样框架,用以降低奖励评估的成本。通过这些技术创新,SynGFN得以探索比其他具备合成意识的生成模型更大、数量级更高的化学空间(以#Circles衡量),同时识别出更具多样性、可合成性与高性能的分子。在应用示例中,SynGFN用于设计GluN1/GluN3A抑制剂,展示了针对神经精神类疾病靶点的潜在影响。
1 引言
设计−合成−测试−分析(DMTA)循环在近年受益于人工智能的发展,其中生成模型与计算辅助合成规划显著提升了分子设计与合成路径的制定效率。然而,这两者相互独立的流程常造成“可合成性悖论”,使许多潜在优异的分子因难以合成而被排除。尽管逆合成规划与可合成性评分等方法试图缓解这一问题,但仍存在效率不足或严谨性不够的局限。组合化学作为较早的尝试,通过基于反应模板的迭代式组装,在可合成性、多样性与新颖性之间取得一定平衡。近年来,研究者将组合化学思想与深度学习结合用于分子设计;随着组合化学空间不断扩张,更高效、更智能的搜索策略成为必要,深度生成模型在大化学空间中采样具备特定性质的分子方面展现出重要潜力。然而,现有生成模型往往在覆盖度与多样性方面表现不足。
为克服这些限制,生成流网络(GFlowNets)被提出作为潜在解决方案,通过在概率流网络中为各生成轨迹分配奖励,使不同分子的生成概率与其奖励值(目标性质)成正比,从而形成依赖奖励的分布并实现独立同分布采样。这一机制有效缓解了分子多样性受限的问题。在GFlowNets基础上,提出了SynGFN,将合成规划深度整合进分子生成过程中。SynGFN引入分层策略网络以引导基于反应的组装过程,同时借助反应兼容的掩码机制与预训练技术降低计算复杂度并加速收敛。在分子设计阶段直接生成可行的合成路线,使“设计”与“合成”两个环节紧密衔接。基于此前关于超网络GFlowNets的研究,SynGFN进一步作为多保真度贝叶斯优化中的采样器,用以降低评估成本而不损失设计质量。
实验结果显示,SynGFN在探索能力与效率方面均有提升;在真实应用案例中,研究团队在30天内成功合成了10个候选分子,其中6个表现出可测的抑制活性,展示了这一方法的实际潜力。
2 结果与讨论
2.1 预训练的分层策略网络结构
SynGFN将分子生成建模为一个马尔可夫决策过程,在该过程中,反应物经历一系列连续反应,沿着合成树逐步到达目标分子。基于Enamine系列反应物库(S、M、L与XL)以及经过整理的高收率反应集合,SynGFN通过组合式动作完成生成过程,即先选择反应模板,再选择与该模板兼容的反应物,而这一系列决策由分层策略网络进行引导。该网络由两个神经网络组成:其一是反应选择网络,用于输出反应模板的概率分布;其二是反应物选择网络,在给定已选反应的条件下,识别可用的反应物。扩展数据图1a展示了反应选择策略如何生成关于反应模板的概率分布,并结合温度缩放进行随机采样;所选反应随后作为条件输入,引导反应物选择策略确定有效的反应物。
为进一步简化学习过程,设计了一个预训练的多标签分类任务,使反应物选择策略能够提前识别与模板兼容的反应物。扩展数据图1b给出了这一预训练的设置,有助于模型学习更高效的反应物分布。研究者以可溶性环氧化物水解酶(sEH)抑制剂的设计任务为例,对SynGFN在不同规模反应物库下的表现进行了分析。补充图3显示,预训练显著提升了探索效率,尤其在规模较大的反应物库(约10万分子)中,使SynGFN得以覆盖更广的化学空间,并生成结构更加多样的候选分子。
2.2 SynGFN的训练过程是一种高效的虚拟筛选
随着虚拟化学空间呈爆炸式增长,传统筛选方法的效率愈发难以维持。SynGFN的训练过程可视为在超大规模组合化学空间中的虚拟筛选。为展示这一点,研究者以S级反应物库与反应模板组合生成的虚拟化学空间(约3亿个化合物)为例,采用对sEH靶点迭代打分的方式训练SynGFN:每轮评估100,000个分子并保留得分最高的10,000个(扩展数据图2a)。作为对照,研究者从完整化学空间中随机采样100万个分子,对其进行穷尽式评分,并保留得分排名前1%的10,000个分子。
研究者使用#Circles这一基于拓扑思想的指标来衡量化学空间覆盖度(方法部分提供更多细节)。扩展数据图2b显示,即便SynGFN评估的分子数量仅为随机筛选的十分之一,其覆盖范围仍然更广。t-SNE投影结果(扩展数据图2c)与得分分布(扩展数据图2d)进一步支持这一点:与暴力式筛选相比,SynGFN识别出更高比例的高分子得分化合物。补充图4a显示,当评估量达到约100,000个分子时,平均奖励值(对应于针对sEH靶点的活性得分)趋于稳定,表明SynGFN已接近收敛,可直接用于采样。
最后,扩展数据图2e比较了在不同QSAR活性评分阈值下,SynGFN与传统虚拟筛选的表现。以富集因子为指标,SynGFN在所有阈值上均优于随机筛选,并在更高的阈值下呈现更强的富集效果(补充图4b)。总的来看,这些结果表明,与传统虚拟筛选相比,SynGFN能够更高效地发现得分更高且结构更具多样性的候选化合物。
2.3 SynGFN的化学空间覆盖能力
补充表1显示,各模型在有效性、新颖性与内部多样性方面均表现良好,但这些指标并不能真实反映化学空间的覆盖程度。为此,研究者采用#Circles进行评估。#Circles基于每个模型生成的10,000个分子及其中得分排名前1,000个分子的结果,并以距离阈值
在
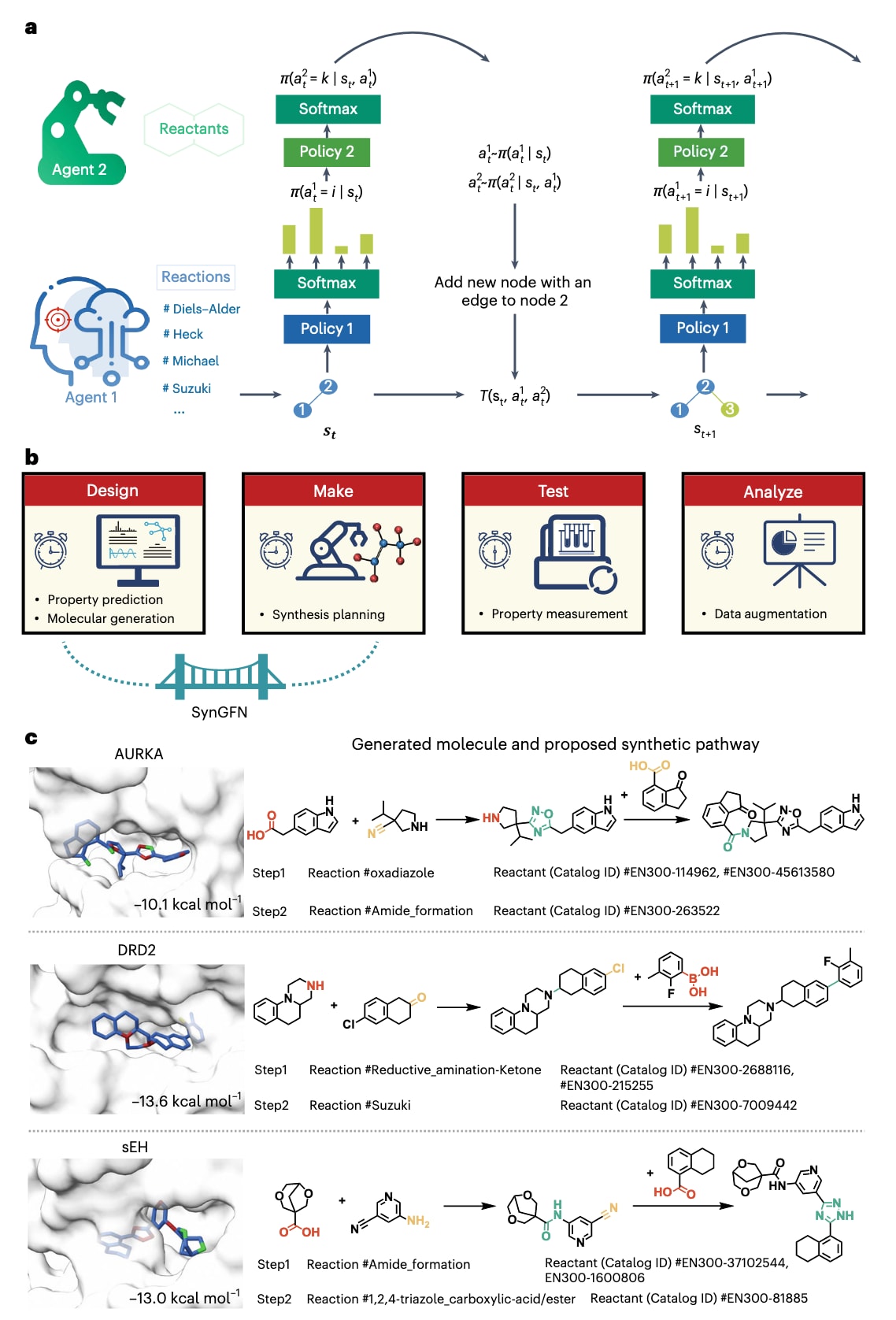
图1|SynGFN算法概览 a,分子生成过程被定义为一个马尔可夫决策过程(MDP),其中反应物依据反应规则经历一系列反应,最终形成产物分子。SynGFN通过离散动作对部分构建的中间结构进行逐步修改,以模拟这一生成过程。在给定前一状态
2.4 对SynGFN生成分子的验证
为进一步评估SynGFN生成分子的潜在生物活性,研究者采用AutoDock Vina对四种SynGFN规模及各基线模型生成的前1,000个分子(从10,000个样本中选取)进行对接评分评估。相比QSAR得分,对接评分基于配体–受体相互作用模式,被视为更具可靠性。研究者首先比较了得分分布,并结合#Circles聚类分析多样性调整后的得分以及高分子数量。补充图6显示,SynGFN在对接评分分布上表现具有竞争力;在DRD2与sEH两个靶点上,SynGFN-XL生成的高得分且多样化的分子数量比基线模型高出3至70倍。
由于Vina评分偏向体积较大的分子,研究者额外采用配体结合效率(LBE)作为评价指标,并对各模型前10与前100名分子的平均Vina与LBE得分进行比较。补充表2结果表明,SynGFN在所有靶点上均能识别出活性相当甚至更高的分子,从而在提升化学空间探索能力的同时不损害得分竞争力。
研究者进一步将SynGFN-XL的生成分子与已有活性化合物进行比较。扩展数据图4a显示,在三个靶点上,LBE分布具有显著重叠,表明SynGFN能够发现具有蛋白结合潜力的分子。研究者还检查了结合构象:扩展数据图4b中,均方根偏差集中在1.0 Å至2.0 Å之间,反映生成分子在结构上与已知活性分子具有一定相似性。最后,对SynGFN-XL得分最高的前5个分子的案例研究(扩展数据图4c与补充图7–9)显示,这些分子能够良好嵌入蛋白结合口袋,形成有利相互作用,并展现出强烈的类药潜力。
2.5 针对GluN1/GluN3A靶点的SynGFN案例研究
基于此前任务中的表现,研究者将SynGFN应用于N-甲基-D-天冬氨酸受体(NMDAR)的抑制剂设计。传统NMDAR因在神经元发育与突触可塑性中发挥重要作用,长期以来一直是神经疾病药物开发的重要靶点。经典NMDAR为由两个GluN1与两个GluN2组成的异源四聚体,而GluN1/GluN3A则作为一种兴奋性甘氨酸受体(eGlyR)发挥作用,与传统NMDAR有所不同。近期研究确认eGlyR是真实存在且在多个脑区表达的受体,具有重要的治疗潜力。然而,目前针对其的药物开发仍十分有限。由于缺乏GluN1/GluN3A的晶体结构,且多亚基构象预测存在不确定性,使得基于结构的设计难以开展。此外,靶向正构位点的化合物难以开发,因为GluN1与GluN3A的配体结合口袋高度相似。因此,近年来更可行的策略是开发负别构调节剂,如EU1180-438与WZB117,它们在靠近GluN3A pre-M1区域的跨膜结构域位点发挥作用。
在此背景下,研究者采用基于配体的方法,借助SynGFN的化学空间探索能力。以EU1180-438与WZB117为形状模板,通过OMEGA生成分子构象并以ROCS进行对齐,利用相似性评分引导SynGFN的生成过程,最终获得10个候选分子(D1–D10)用于合成与生物测试(扩展数据图5a)。在30天内,这10个分子全部被成功合成,其中6个表现出对GluN1/GluN3A的抑制活性。表现最佳的D1具有
3 讨论
尽管近年来提出了许多分子生成模型,但少有方法能够同时解决可合成性、庞大化学空间覆盖不足以及反馈成本过高等问题,而这些正是AI主导的de novo设计走向实际应用的主要障碍。SynGFN在这一方向提供了有前景的框架。通过在化学空间构建中纳入合成约束,并采用基于反应的分子组装方式,SynGFN能够在实时生成分子的同时给出可行的合成路径。依托GFlowNet所保证的多样性生成能力,SynGFN在探索能力上获得增强,并结合具备合成意识的化学空间,在所有测试模型中实现最广的覆盖。此外,SynGFN作为虚拟筛选工具显示出卓越效率,仅需传统枚举方法约十分之一的搜索量即可获得相当甚至更高的活性化学空间覆盖。提出的多保真度采样策略进一步降低对昂贵打分方法的依赖,在探索、利用与计算成本之间实现平衡。
尽管如此,SynGFN仍存在局限。目前的验证仅集中在针对单一受体亚型GluN1/GluN3A的体外抑制剂设计。在全细胞背景下同时实现靶点特异性与活性仍是巨大的挑战。即便如此,SynGFN在药物分子设计中的潜在价值已经显现,有望作为加速DMTA循环并推动分子设计研究的重要方法。