Nature Methods 2022 | CellRank:用于定向单细胞命运映射的方法
今天介绍的CellRank发表于《Nature Methods》,是一项旨在解决单细胞命运推断中“方向未知”难题的重要方法。传统的轨迹分析往往依赖预设起点,难以应用于再生、重编程或疾病等具有高度可塑性、方向并不明确的体系。CellRank的核心思想在于将细胞间的表达相似性与RNA velocity提供的方向信息相结合,并在此基础上构建带方向性的马尔可夫链,从而在全局尺度上推断初始、中间与终末状态以及细胞的命运潜能。与仅依赖低维投影或短程velocity的传统方法不同,CellRank通过宏状态分解、命运概率计算与不确定性传播,实现了高维转录组空间中更可靠的命运推断。该方法不仅在胰腺发育中准确恢复分化结构,也在重编程与肺再生中识别出意料之外的细胞路径,为理解复杂动态系统中的细胞状态转变提供了强有力的工具。

获取详情及资源:
- 📄 论文: https://doi.org/10.1038%2Fs41592-021-01346-6
- 💻 代码: https://github.com/theislab/cellrank_reproducibility
- 🌐 网站: https://cellrank.org
0 摘要
计算轨迹推断能够利用单细胞RNA测序实验重建细胞状态动态。然而,这类推断通常要求已知生物过程的方向性,从而在很大程度上将其应用限制在正常发育中具有明确分化方向的体系。CellRank旨在解决这一问题,可用于再生、重编程以及疾病等方向未知的多种情境下的单细胞命运映射。该方法将轨迹推断的稳健性与RNA velocity提供的方向信息结合起来,并同时考虑细胞命运决策的渐进性与随机性以及速度向量中的不确定性。在胰腺发育数据中,CellRank能够自动识别起始、中间及终末细胞群,预测命运潜能,并沿各条谱系可视化连续的基因表达变化。应用于具备谱系追踪的细胞重编程数据时,预测的命运概率能够准确反映最终的重编程结果。此外,在损伤后肺再生研究中,CellRank预测出一条新的去分化轨迹,其中包含此前未知的中间细胞状态,并已通过实验加以验证。
1 引言
细胞在发育、重编程、再生以及癌症等多种生物过程中都会发生状态转换,而且往往呈现高度不同步的特征。单细胞RNA测序能够捕获由这些过程导致的异质性,但由于每个细胞只能被测量一次,因此无法保留其谱系关系。为缓解这一局限,研究者将scRNA-seq与谱系追踪方法结合,这类方法利用可遗传条形码在较长时间尺度上追踪克隆演化;或结合代谢标记方法,通过新生RNA与成熟RNA的比例在短时间窗口内连接可观察的基因表达状态。然而,这两类策略大多局限于体外体系,由此推动了计算方法的发展,即通过重建伪时间轨迹来刻画细胞状态变化,这些方法基于一个关键观察:发育相关的细胞往往具有相似的基因表达模式。伪时间方法已广泛用于将细胞排序到分化轨迹上,并用于研究细胞命运决策。计算轨迹推断通常需要先验生物学知识来确定状态变化的方向性,常见的做法是指定一个初始细胞,这使其应用被限制在正常发育体系中具有明确命运层级的情境。RNA velocity的提出为这一难题提供了新的解决途径,它基于剪接与未剪接mRNA的比例推断轨迹方向。该思想已被推广以适配瞬态细胞群与蛋白动力学,但速度估计往往噪声较大,高维速度向量的解释多依赖于低维投影,而这类投影难以揭示远距离的概率性命运,也难以进行定量解读。
CellRank的提出旨在将基于相似性的轨迹推断方法的稳健性与RNA velocity提供的方向信息结合起来,从而在正常或扰动条件下学习带方向性的概率状态转换轨迹。与其他方法不同,CellRank能够在scRNA-seq数据中自动推断初始、中间与终末细胞群,并计算命运概率,这些概率既考虑了细胞命运决策的随机性,也兼顾了velocity估计的不确定性。基于这些命运概率,可以进一步识别潜在的谱系调控因子,并可视化谱系特异性的基因表达趋势。在胰腺内分泌谱系发育中,CellRank不仅能够正确恢复起始与终末状态,还能识别分化偏向以及参与Δ细胞分化的关键驱动基因。将CellRank应用于重编程数据时,其预测的命运偏向能够准确对应于谱系追踪给出的真实结果。进一步应用于肺再生研究,CellRank预测出一条新的去分化轨迹,并实验验证了其中此前未知的中间细胞状态。相比不利用velocity信息的方法,CellRank展现出更优的性能;该方法已作为可扩展、易使用的开源软件发布,并提供文档与教程。
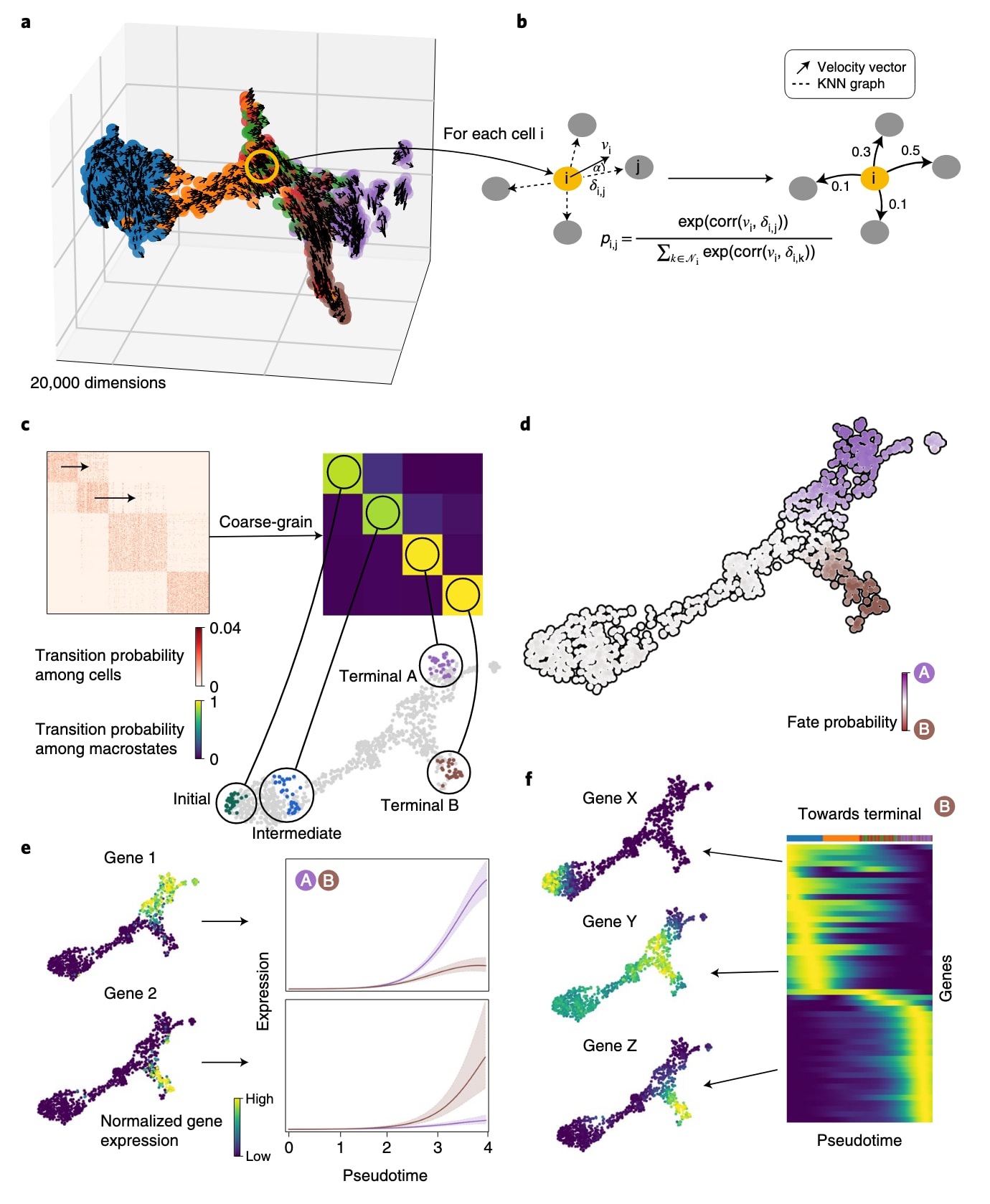
图1 | 展示了如何将RNA velocity与细胞相似性结合,用以确定初始与终末状态,并构建全局性的细胞命运潜能图谱。 a部分显示利用DynGen模拟的1,000个细胞的三维UMAP以及其velocity向量,颜色代表DynGen给出的真实分支归属。CellRank在高维基因表达空间中直接建模细胞状态转换。b部分展示参考细胞i的velocity向量$ v_i
2 结果
2.1 CellRank通过结合细胞相似性与RNA velocity来建模细胞状态转换
CellRank的核心目标在于描绘体系的细胞状态动态,并由此识别初始、终末与中间状态,同时构建一个表征命运潜能的全局图谱,为每个细胞分配到达各个终末状态的概率。基于这些潜能,CellRank进一步刻画不同分化路径中的基因表达变化,并寻找潜在的命运调控因子。算法以scRNA-seq计数矩阵及对应的RNA velocity矩阵为输入。需要指出的是,尽管工作主要使用RNA velocity来近似动态方向,但CellRank能够适配任何提供方向度量的向量场,例如代谢标记或实时测量信息。
所有能够可靠捕获轨迹的伪时间算法均依赖一个关键假设,即细胞状态以小步迁移并伴随大量过渡群体。CellRank也基于同一假设,将状态转换建模为马尔可夫链,其中每个状态对应一个观测到的细胞表达谱,边的权重表示由一个细胞转移到另一细胞的概率。构建链的第一步是计算无向的KNN图,用以表示表型流形上的细胞相似性,其中节点代表细胞,边连接最相似的细胞。不同于传统伪时间算法,CellRank利用RNA velocity为马尔可夫链的边引入方向性。RNA velocity向量基于剪接动态预测基因当前处于上调或下调状态,并指向细胞可能的未来状态。在velocity向量方向上更靠近的邻近细胞将获得更高的转移概率。算法还基于基因表达相似性计算第二套转移概率,并通过加权平均将其与velocity导出的转移概率结合。最终得到的定向转移概率矩阵独立于任何低维嵌入,并同时反映表达相似性与velocity提供的方向信息。
由于转移矩阵可能巨大、噪声较高且难以解释,CellRank通过将细胞表达谱概括为宏状态来缓解这一问题。宏状态是表型流形上细胞不易离开的区域。CellRank将马尔可夫链的动态分解为这些宏状态,并计算其间的粗粒化转移概率。宏状态的数量是可调参数,可通过膝点启发式方法或基于系统的已有知识进行选择。细胞通过软分配方式被划入各宏状态。为了计算宏状态及其粗粒化转移概率,算法将GPCCA方法适配至单细胞背景。粗分辨率下的系统能揭示基于转移概率的不同细胞群体:终末宏状态具有高自转移概率,初始宏状态具有低入射转移概率,其余宏状态为中间状态。终末状态的自动识别依赖稳定性指数,该指数介于0到1之间,反映自转移概率;当SI大于或等于0.96时,该宏状态被视为终末。初始状态通过粗粒化平稳分布确定,该分布反映粗粒化马尔可夫链的长期演化;平稳分布较小的宏状态被标记为初始状态。初始状态的数量默认为1。
随后,CellRank利用单细胞定向转移矩阵计算命运概率,即一个细胞最终朝向每个终末状态的可能性。通过求解线性系统,可以高效地为所有细胞获得命运概率。命运概率将RNA velocity提供的短程预测拓展为跨越整个系统、从初始到终末的全局结构。基于马尔可夫链的随机建模允许通过整合大量的局部信息来克服velocity噪声与相似性噪声,并通过限制转移发生在表型流形内部来更真实地捕获状态动态。
velocyto与scVelo模型均基于剪接与未剪接计数比来计算velocity,而这些计数受多种生物与技术噪声影响,包括环境RNA、稀疏性、双细胞、爆发式转录动力学及低捕获效率。尤其是未剪接RNA,本身稀少且检测率低,因此分子计数的不确定性会导致velocity估计的不确定性,可在scVelo中得到估计。CellRank通过传播velocity向量的估计分布来吸收这些不确定性。默认情况下,算法使用一种解析近似方法,在已知velocity向量分布的前提下计算朝向邻近细胞的期望转移概率。此方法高效,适用于大规模数据集。另一选项为MC采样,尽管更慢,但精度更高。
**CellRank将命运概率与伪时间排序结合,用以可视化终末轨迹上细胞执行的基因表达程序。**伪时间对初始状态起始的细胞沿发育进程排序,而命运概率表明细胞对不同轨迹的投入程度。通过利用命运概率对细胞进行软分配,能够捕获谱系承诺逐渐形成的特征,即细胞从未承诺状态逐渐过渡到完全承诺状态。默认伪时间排序由Palantir完成,其以CellRank推断的初始状态为起点,并基于扩散成分空间中的迭代最短路径进行排序。通过计算基因表达与命运概率的相关性,CellRank能更好地识别潜在的轨迹特异性调控因子。将这些调控因子按其在伪时间中的峰值排序,可直观展示其在特定轨迹中的基因表达级联,同时反映命运承诺的连续性。
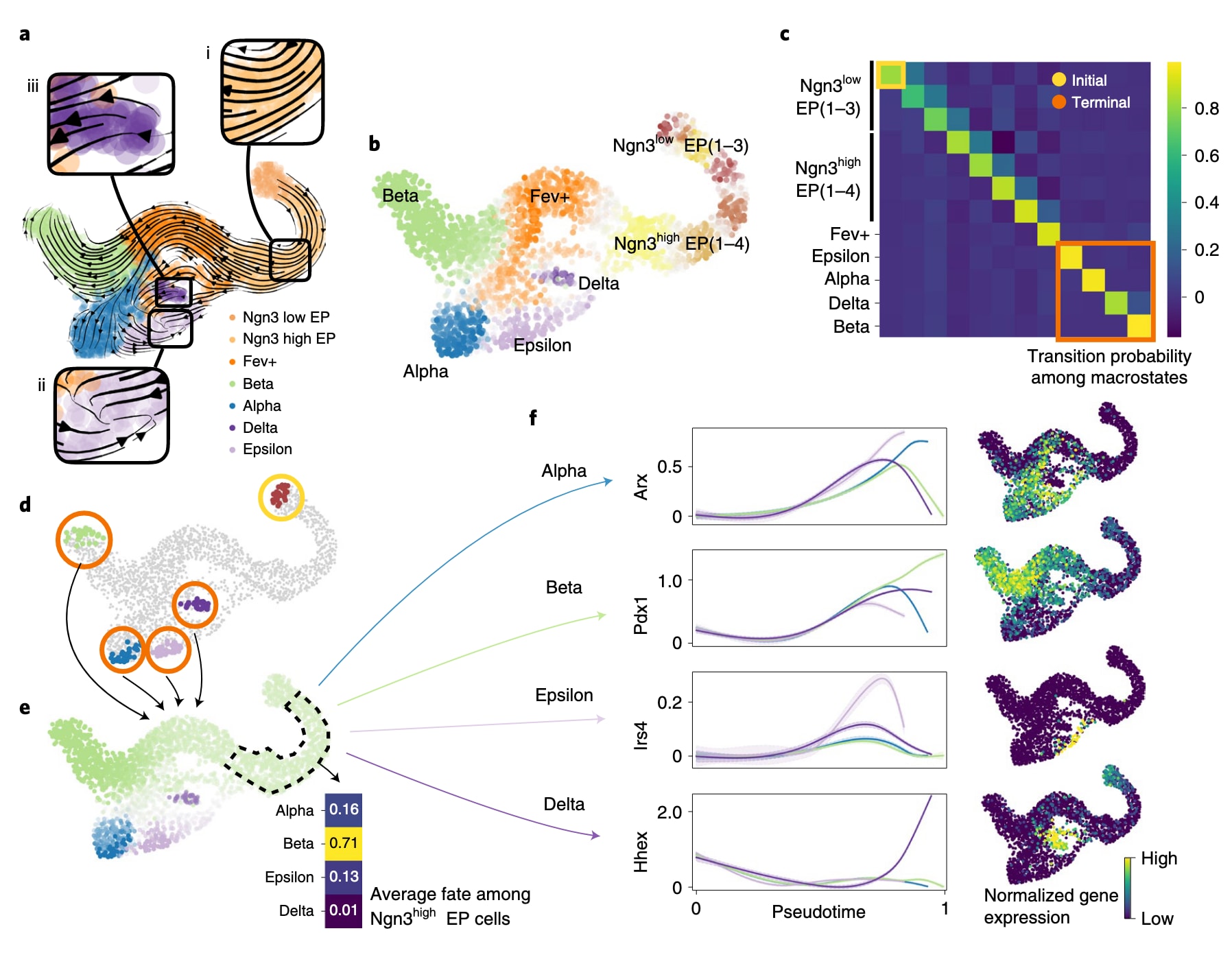
图2 | 展示了胰腺发育过程中的命运选择。 a部分为E15.5小鼠胰腺发育的UMAP,可见scVelo投影的velocity流线,颜色对应既有簇注释。CellRank进一步提供了关于早期细胞命运、终末状态识别以及终末细胞群的潜在祖细胞等关键问题的洞察。b部分为细胞向宏状态的软分配结果,细胞按最可能所属的宏状态着色,颜色深浅反映置信度,灰色表示处于多个宏状态之间的过渡区域。c部分展示宏状态之间的粗粒化转移概率,终末宏状态以红色标框,而初始Ngn3low eP_1宏状态以黄色标框。d部分标示最有信心被归入每个初始与终末宏状态的30个细胞,着色方案与b一致。e部分展示细胞到达α、β、ε与δ终末命运的概率,颜色方案与b相同,且颜色越深表示概率越高。插图显示虚线所示Ngn3high eP簇中细胞的平均命运概率。f部分为沿伪时间平滑后的基因表达趋势,利用CellRank命运概率进行加权,展示α谱系决定因子Arx、β谱系因子Pdx1、δ谱系因子Hhex及ε谱系相关基因Irs4在各自通向相关终末群体的轨迹上的表达变化。右侧列为对应基因在UMAP中的表达分布。
2.2 CellRank能够重现胰腺内分泌谱系形成的粗粒度动态
研究将CellRank应用于E15.5小鼠胰腺发育的scRNA-seq数据。结合原始簇注释与scVelo预测的velocity,UMAP清晰呈现主要发育趋势;细胞由最初表达较低Neurog3的内分泌祖细胞出发,沿着不同轨迹通向α、β、ε与δ细胞命运。针对具体问题,例如谱系偏向的出现时点、初始与终末状态的精确位置以及任一终末状态的潜在祖细胞,仅依赖低维投影中的velocity向量并不可靠。首先,二或三维投影会过度平滑真实velocity,从而产生过于规则的向量场,而高维距离难以在低维中保持,这使基于t-SNE与UMAP的嵌入常常无法保留全局结构。其次,对投影向量的视觉解释忽略了RNA velocity的高度不确定性,会导致对轨迹的过度自信。第三,velocity只能提供局部信息,而CellRank则可聚合这些局部信号,以恢复更长程的全局趋势。因此,二维或三维嵌入中的velocity无法支持对轨迹推断细节的判断,而CellRank能够克服这些限制,并在此数据中展示其对全局轨迹的建模能力。
研究首先计算CellRank的定向转移矩阵,并基于特征值间隙将其粗粒化为12个宏状态,从而揭示转移矩阵的块状结构。根据宏状态与基因表达簇的重叠关系,这些宏状态覆盖了从初始Ngn3low EP状态、中间的Ngn3high EP与Fev+状态到终末的α、β、ε、δ分泌细胞的完整发育阶段。其中,α(SI 0.97)、β(SI 1.00)与ε(SI 0.98)宏状态最为稳定,被识别为终末状态;一个稳定性为0.84的宏状态与δ细胞对应。初始状态被识别为Ngn3low EP_1,因为其CGSD值最小。初始与终末状态均与相关标志基因的表达一致,例如β细胞的Ins1与Ins2、α细胞的Gcg、ε细胞的Ghrl、δ细胞的Sst,以及初始状态中的Sox9、Anxa2与Bicc1。
在此基础上计算命运概率并绘制命运图谱,结果显示在E15.5阶段的Ngn3high EP簇中,β命运占主导,这与既有生物学认识一致。以Ngn3low EP_1宏状态中的细胞为伪时间起点,通过Palantir进行排序,并叠加调控因子Arx(α)、Pdx1(β)、Hhex(δ)与谱系相关基因Irs4(ε)的表达,能够基于CellRank的命运概率清晰呈现其表达趋势,且均在接近相应终末状态时上调。
CellRank在多种参数变化下均表现出极高稳健性,包括宏状态数量、表达相似性权重、KNN邻居数、scVelo基因最小计数、可变基因数量及主成分数量,在随机下采样细胞时同样稳定。进一步利用该数据集检验不确定性传播的作用,发现在velocity噪声较高的区域,考虑不确定性会显著调整转移概率,自动降低不可信velocity向量的影响。解析近似方法与MC采样结果一致,而不确定性传播总体提升了命运概率的稳健性。
为检验CellRank是否能处理分化与增殖信号混杂的情形,研究加入了一群循环状态的导管细胞。粗粒化转移概率能够自动识别导管与内分泌的终末状态,且对应的命运概率与相关谱系标志基因呈良好相关。这些结果表明CellRank能够在复杂动态系统中稳健恢复细胞命运结构。
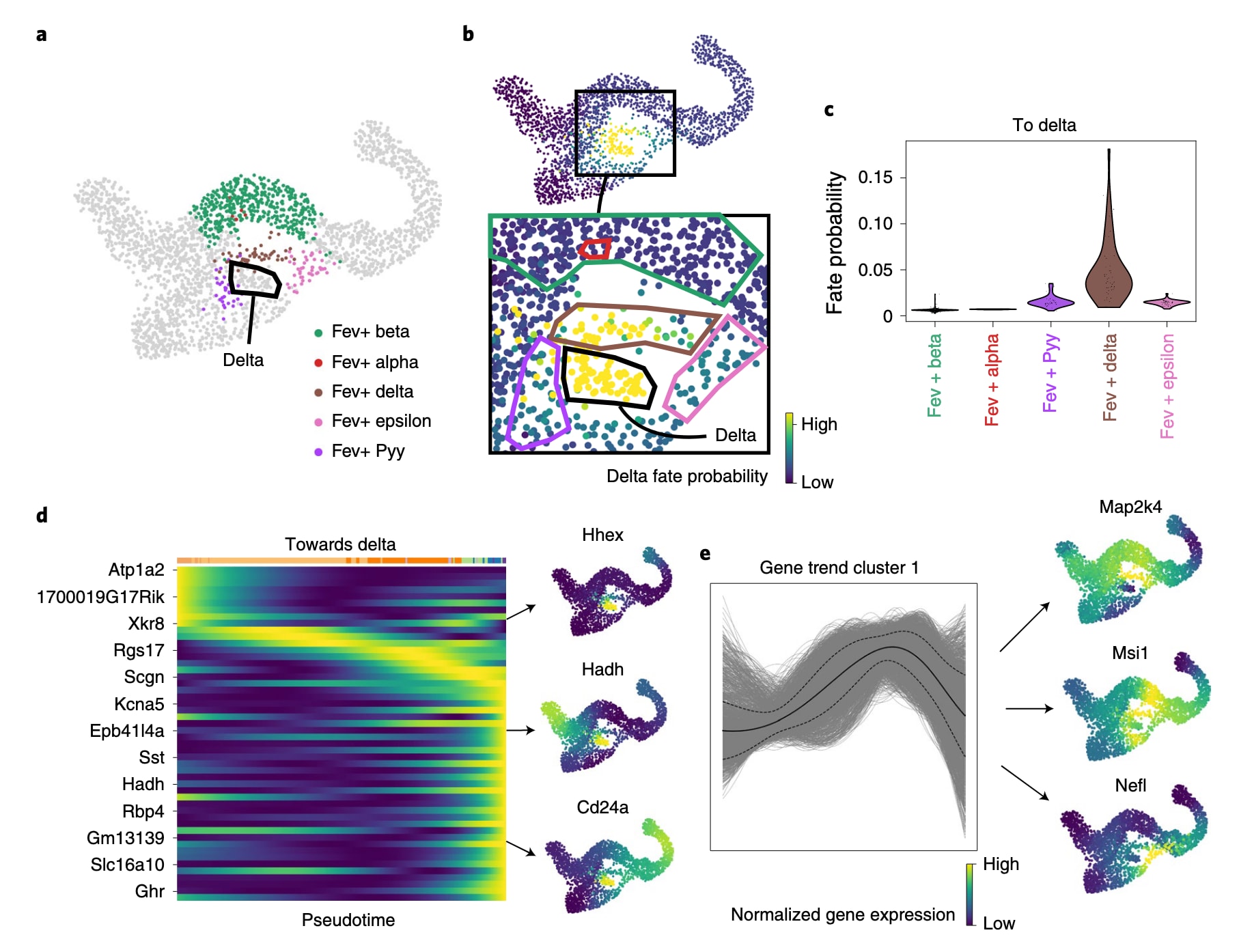
图3 | 聚焦于δ细胞状态,以解析其分化路径。 a部分为对Fev+且不表达激素的内分泌细胞进行正交子聚类的结果,δ细胞以黑色边框标示。b部分展示CellRank预测的获得终末δ命运的概率,细胞依照到达δ状态的概率着色。插图显示最可能分化为δ细胞的一组细胞,并给出CellRank预测的分化路径。Fev+子簇以与a部分一致的颜色标框表示,δ细胞同样以黑色边框标示。c部分呈现各Fev+子簇中的CellRank命运概率(不包含δ簇本身)。Fev+ δ子簇中的细胞被赋予显著更高的概率(双侧Welch t检验,51个Fev+ δ细胞对比536个其他Fev+细胞,
2.3 CellRank能够识别可能驱动δ细胞分化的基因程序。
δ细胞的案例清楚展示了CellRank的全局建模如何克服RNA velocity的局限。在此数据集中,δ细胞极为稀少(70个细胞,占总数的3%),更重要的是,在scVelo给出的30个最高置信度基因中,没有任何已知参与δ细胞发育的基因。此外,与δ细胞发育相关的基因也未能被scVelo的剪接动力学模型良好捕获。推测其原因在于δ细胞出现在胰腺发育的较晚阶段,在此数据中极为稀有,使剪接信号不足以描述其分化动态。δ细胞的发育过程本身也不清晰。成熟δ细胞可通过Sst表达识别,但未成熟δ细胞非常难以鉴定。Hhex是唯一被广泛认可、用于维持δ细胞分化的转录因子,且特异性标记成人朗格汉斯岛的δ细胞;Cd24a也被认为与人类δ细胞发育有关。
为了更深入理解δ细胞的发育,研究聚焦于CellRank指向相对稳定δ宏状态(SI 0.84)的命运概率,该状态并未被自动归类为终末状态。将velocity投影到UMAP后无法揭示可能的δ细胞前体,但CellRank命运概率指向了一条可能性最高的路径,该路径经过此前研究中在Fev+亚群中被注释为δ前体的细胞。因此,尽管RNA velocity未能捕获δ细胞发育动态,CellRank仍能成功恢复这一过程,因为其通过KNN图将velocity限制在表型流形上,结合细胞相似性并建模长程趋势。
为发现更多与δ分化相关的基因,研究在Fev+细胞群中计算基因表达与CellRank δ命运概率的相关性。相关性最高的前50个基因的平滑表达趋势呈现一系列逐级激活的基因事件,其中包括Hhex与Cd24,以及由成熟δ细胞分泌的激素基因Sst。若干此前未被描述为参与δ分化的基因也被识别,例如Hadh(Foxa2的靶基因,参与胰腺分化)、Isl1(参与胰腺分化的转录因子)与Pkhd1(Hnf1a/b的靶基因,而Hnf1a/b同样参与胰腺分化)。
进一步聚焦于瞬时上调基因簇后发现,当按与δ命运的相关性排序时,Map2k4、Msi1与Nefl可作为新的候选调控因子。其中,Msi1受Rfx4调控,而Rfx4是Rfx6的旁系同源基因,并与Rfx3结构相近,二者均参与内分泌分化过程。
2.4 谱系追踪验证了重编程中的命运概率
胰腺的示例展示了CellRank如何用于研究正常发育中的分化轨迹。在扰动情境下,研究将CellRank应用于包含48,515个小鼠胚胎成纤维细胞在六个时间点重编程为诱导性内胚层祖细胞的数据集。只有约1%的细胞能够成功重编程(以Apoa1标记),其余细胞会进入“死胡同”状态(以Col1a2标记)。该数据集同时包含CellTagging谱系追踪信息,可用于重建细胞间的克隆关系,从而为早期细胞的最终命运(成功或死胡同)提供真实标签。研究关注CellRank的命运概率在这一具有挑战性的体系中能否恢复真实结果。
使用scVelo计算velocity并投影到原始t-SNE嵌入后,结果未能展示通向成功状态的路径,可能因为重编程信号过弱,无法在低维空间中表现出来。相比之下,CellRank识别出的宏状态同时包含死胡同状态与罕见的成功状态。计算指向这些状态的命运概率后,将其与谱系追踪得到的真实标签进行比较,结果显示命运概率能够高度预测重编程结局,且预测准确性在更早的时间点上随着信息减少而下降,这是合乎预期的。

图4 | 展示了CellRank对重编程结局的预测。 a部分为48,515个MEF向iEP重编程过程的t-SNE嵌入,每个点代表一个细胞,颜色分别表示重编程诱导后的时间、iEP标志基因Apoa1(成功重编程的指标)、MEF标志基因Col1a2(重编程失败的指标)或原始簇注释。虚线标示的簇1与簇3分别代表成功状态与死胡同状态。b部分呈现scVelo计算的velocity并投影到a中的t-SNE上,可见velocity既未显示通向成功状态的路径,反而错误地显示从成功状态指向死胡同状态的转移。c部分展示CellRank计算的宏状态,并根据其与a中簇的重叠情况着色。d部分显示各宏状态中细胞在重编程时间(左)及簇(右)上的分布,可见宏状态1与3仅包含来自第21与28天的细胞,分别对应成功与死胡同状态。e部分展示CellRank预测到达成功宏状态1的命运概率(上)以及CellTag谱系追踪提供的真实重编程结局标签(下)。这些标签指示了3,049个跨时间点细胞的可能重编程结果。f部分为在第12、15与21天,基于CellRank命运概率训练的分类模型的AUC表现,其真实标签来源于CellTag数据,用于评估命运概率对重编程结局的预测能力。
2.5 CellRank优于其他竞争方法
为了评估velocity信息的作用,研究在胰腺数据上将CellRank与多种基于相似性的命运概率方法(Palantir、STEMNET与FateID)以及一个基于velocity的初始/终末状态识别方法(velocyto)进行了系统对比。结果显示,只有CellRank能够同时正确识别初始状态与终末状态。Palantir需要用户指定初始状态,并且仅能识别四个终末状态中的两个;STEMNET与FateID均无法确定初始或终末状态。velocyto无法识别单个初始或终末状态,只能输出其分布,而这些分布仅分别与β细胞和Ngn3low EP细胞重叠。
接着,为所有方法统一提供CellRank识别出的终末状态,并测试其细胞命运概率。结果显示,仅有CellRank与Palantir能够正确识别β命运在Ngn3high EP细胞中占主导。velocyto不提供命运概率。对于谱系特异性的基因表达趋势,CellRank和Palantir均正确预测关键驱动因子的表达模式,而FateID未能预测β谱系中Pdx1与Pax4的(瞬时)上调,也未能捕获α谱系中Arx的上调。STEMNET与velocyto不提供表达趋势。
研究还在包含10万个细胞(MEFs到iEPs重编程)的数据集上比较了运行时间和内存占用。CellRank仅用约33秒便完成宏状态计算。对于命运概率,STEMNET(广义线性模型)最快,仅需1分钟;CellRank约2分钟;Palantir需1小时12分钟。FateID在9万个细胞时用时更长,在10万个细胞时因内存限制而失败;velocyto最慢,在超过4万个细胞时即超出1万秒的时间预算。
内存占用趋势与运行时间一致:在计算10万个细胞的命运概率时,CellRank的峰值内存分别仅为Palantir与FateID的三分之一与五分之一,只有STEMNET占用更少内存。velocyto的内存需求最高,在4万个细胞上就超过其他所有方法在10万个细胞上的用量。在10万个细胞且无并行加速的条件下,CellRank的峰值内存低于15 GiB,使其可在笔记本电脑上运行如此规模的数据集。
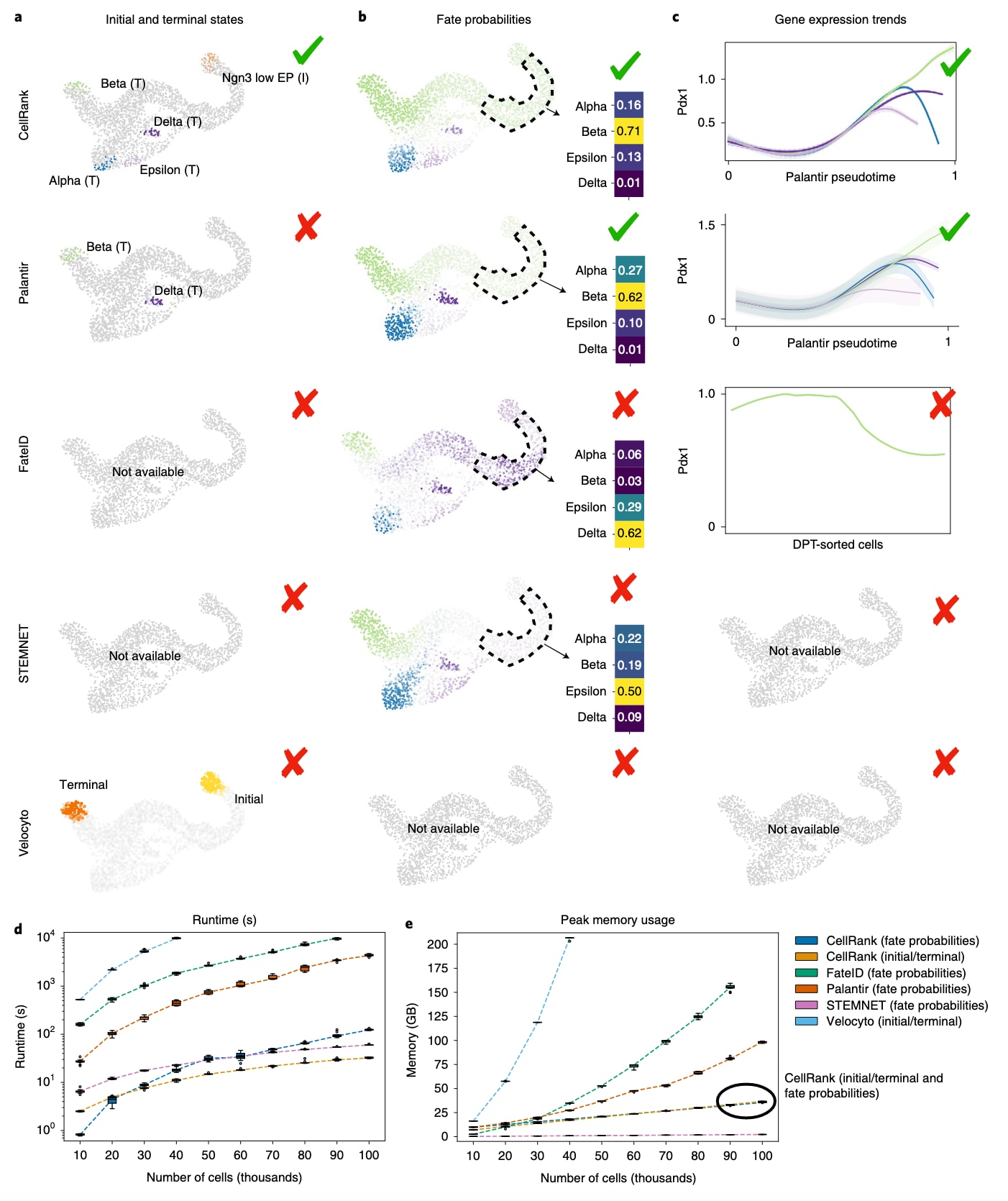
图5 | 展示了CellRank在细胞命运推断方面优于其他方法的结果。 a–c部分基于胰腺数据进行方法比较。CellRank能够自动识别终末的α、β与ε状态,以及初始的Ngn3low eP状态;δ细胞被识别为一个宏状态,并在图中手动标记为终末状态。Palantir识别出了β与δ的终末状态。velocyto的状态分布与β细胞(终末,橙色)及Ngn3low eP细胞(初始,黄色)分别重叠。只有CellRank与Palantir能够正确预测β命运在Ngn3high eP细胞中占主导(b)。velocyto不计算命运概率。c部分展示β谱系调控因子Pdx1的基因表达趋势。横轴为对应方法使用的伪时间,纵轴为基因表达量。对于FateID,横轴为被分配到β谱系的细胞索引,并按DPT排序。CellRank与Palantir沿各自的谱系提供一条平滑趋势;FateID仅能显示β谱系上的一条趋势,因为其无法同时显示一个基因在多个谱系上的变化。CellRank与Palantir均正确识别到沿β谱系的Pdx1上调,而FateID未能捕获这一趋势,STEMNET与velocyto则无法提供谱系特异的表达趋势可视化。d与e部分分别为不同方法在包含10万个细胞的重编程数据集上的运行时间与峰值内存使用量比较。研究将数据集划分为十个不同规模的子集,并在每个子集上重复运行各方法十次。箱线图展示25%到75%分位,线表示中位数,须状线延伸至1.5倍四分位距,点为离群值;虚线连接中位数。CellRank在初始/终末状态及命运概率计算中的峰值内存基本一致,因此对应曲线重叠。
2.6 命运概率预测了肺再生中的一条新的去分化轨迹
为了展示CellRank在再生情境中的能力——在该情境中,细胞状态并不一定遵循朝向更加分化细胞的单向路径——研究将其应用于小鼠急性损伤后的肺再生过程。该scRNA-seq数据集包含24,882个气道与肺泡上皮细胞,于损伤后第2至第15天的13个时间点采集,使用分辨率较低的Drop-seq平台获得。在组织稳态被扰动时,上皮细胞类型之间的高度可塑性已被观察到,包括损伤诱导的分化细胞重编程为真正的长寿命干细胞,无论在肺还是其他器官中均有报道。在当前的气道谱系模型中,多能性的基底细胞产生Club细胞,后者可进一步产生杯状细胞与纤毛细胞。已有研究表明,在基底干细胞被清除后,腔面分泌细胞能够去分化成为完全功能性的基底干细胞。在此背景下,研究利用CellRank在气道细胞中无偏探索潜在的意外再生轨迹。
研究首先计算scVelo的velocity,随后应用CellRank并识别出九个宏状态,用以进一步计算命运概率。结果显示,MHC-II+ club细胞具有较高的多谱系潜能,这与先前研究一致。聚焦于气道相关细胞,可见纤毛细胞包含三个宏状态,基底细胞与杯状细胞各包含一个宏状态。与谱系追踪实验一致,club细胞显示出较高概率分化为纤毛细胞。杯状细胞宏状态与club细胞的区别在于其表达特异性黏蛋白基因(如Muc5b与Muc5ac)以及参与固有免疫的分泌蛋白(如Bpifb1)。基于指向基底与杯状状态的命运概率,研究发现杯状细胞很可能向Krt5+/Trp63+基底细胞发生去分化。进一步针对基底与杯状细胞计算扩散映射以提高解析度,并确认基底细胞比例随时间增加,同时velocity在基因层面上支持去分化假设。使用CellRank与CGSD识别出转变过程中的早期细胞,并以此利用Palantir构建伪时间排序。随后将伪时间与向基底命运转移的概率结合,定义数据子集中的去分化轨迹阶段:将至少有66%概率到达基底状态的细胞分为三个等量伪时间区间。
阶段1为杯状细胞,具有Bpifb1的高表达。阶段2为中间细胞群体,Bpifb1与基底标志Krt5共表达。阶段3为终末基底细胞,高表达Krt5与Trp63且不再表达Bpifb1。该新提出的杯状细胞去分化模型预测:损伤后,中间阶段的细胞比例应增加,因为它们代表通向基底细胞去分化桥梁上的过渡状态。为验证这一预测,研究在未处理与损伤后第10与21天的小鼠气道上皮细胞中,通过免疫荧光检测Bpifb1、Krt5与Trp63的表达。结果表明,阶段1(杯状)与阶段3(基底)细胞在对照与处理组均存在,而中间的阶段2细胞仅在损伤后第10天出现。此外,还检测到三阳性细胞,但仅在损伤后出现。杯状细胞增生是多种慢性炎症疾病的重要特征。CellRank预测的新去分化轨迹指向基底干细胞,这一意外发现提示在再生反应的恢复阶段存在形成多能干细胞的潜在路径。
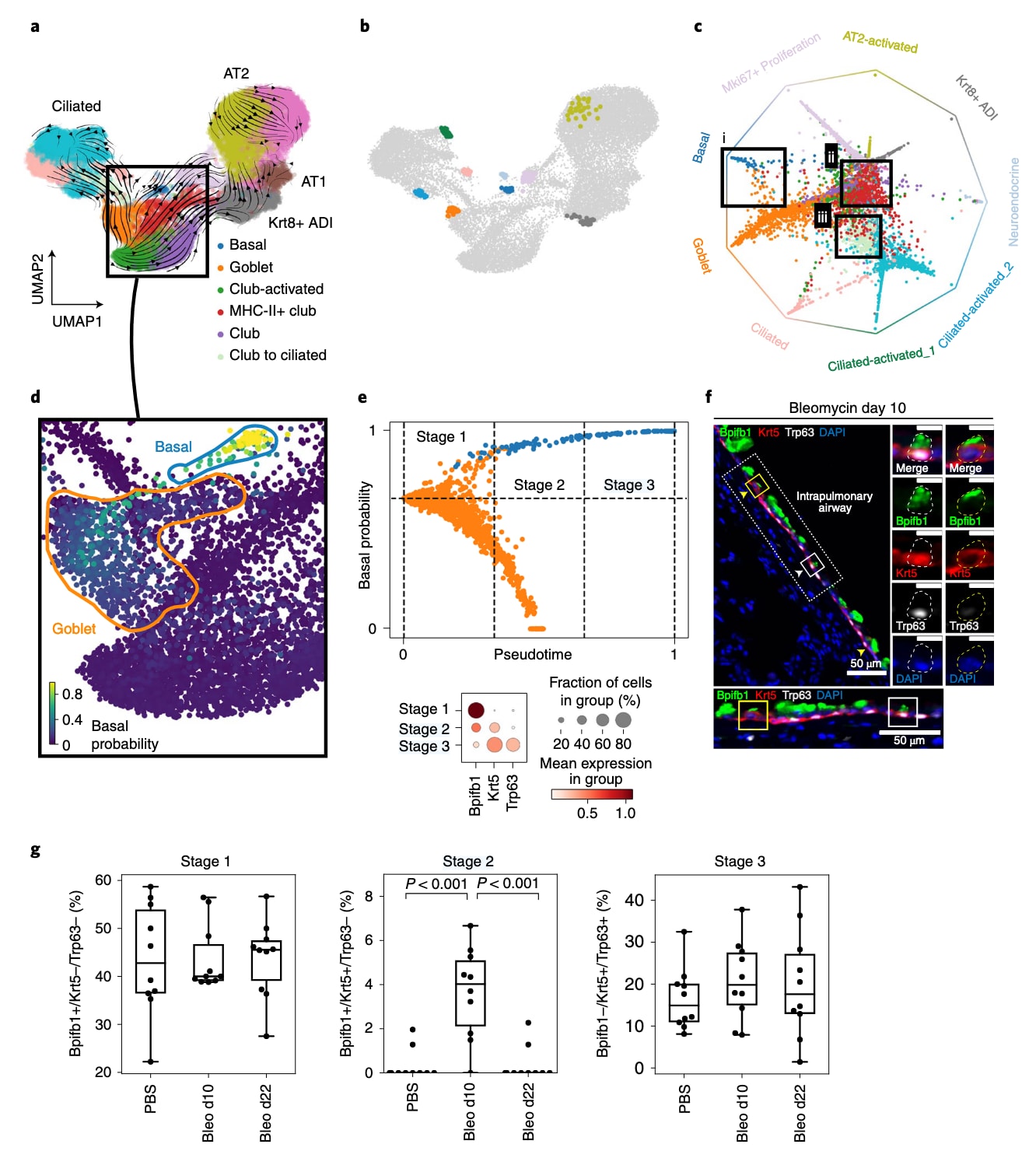
图6 | 展示了CellRank在小鼠肺再生中预测出一条新的去分化轨迹。 a部分为24,882个在损伤后第2至第15天的13个时间点采集的上皮细胞UMAP,颜色依据原始簇注释。流线表示平均并投影后的scVelo velocity,方框标出气道细胞子集。b部分显示CellRank计算的宏状态,每个宏状态展示最有信心归属于该状态的30个细胞。宏状态的名称与颜色依据其与a中簇的最大重叠进行指定。c部分为基于命运概率的环形投影,将细胞按其到达宏状态的概率映射到圆内部。宏状态位于圆周,细胞越靠近中心表示多谱系潜能越高,越接近某一角落表示越趋向单一命运。方框突出三类细胞:可能到达基底终末状态的杯状细胞(i),具有高多谱系潜能的MHC-II+ club细胞(ii),以及可能转变为纤毛细胞的club细胞(iii)。d部分为UMAP着色图,按向基底宏状态的命运概率标色,显示从杯状细胞至基底细胞的路径。e部分将CellRank的命运概率与Palantir伪时间结合,用以定义去分化轨迹的三阶段。顶部示意基于方法定义阶段。每个阶段由特定基因表达特征界定:Bpifb1(杯状),Krt5(早期基底),Trp63(晚期基底);阶段1对应杯状细胞,阶段2为中间状态,阶段3为基底细胞。f部分为损伤后10天小鼠肺组织切片的免疫荧光染色,Bpifb1(绿)、Krt5(红)、Trp63(白)及DAPI(蓝)。可见处于中间阶段2的细胞(Bpifb1+/Krt5+/Trp63−)仅存在于损伤组织中。比例尺为50 μm;放大图为10 μm。每一面板中虚线框区域在下方放大,实线框中的细胞在右侧显示单独及合并通道图像,图像来自两个独立生物学重复。g部分对不同阶段细胞的丰度进行量化,包括野生型(PBS)、损伤后10天(bleo d10)及损伤后22天(bleo d22)。每组条件在两个独立实验中共分析十个肺气道区域。结果表明,bleo d10中阶段2细胞显著富集(嵌套单因素方差分析与Tukey多重比较检验,P < 10−3)。
3 讨论
该部分总结了CellRank在多种生物体系中的表现。**研究表明,CellRank通过结合基因表达相似性与RNA velocity,能够在不同实验平台(10x与Drop-seq)上稳健推断发育、重编程与再生中的定向细胞轨迹。**应用于胰腺发育时,CellRank在识别初始与终末状态、恢复命运潜能以及重建基因表达趋势方面均优于现有方法,并能在10万个细胞规模下于数秒内计算终末状态、数分钟内得到命运潜能。传统基于相似性的轨迹分析方法通常仅适用于起点和方向明确的过程,而CellRank突破了这一局限,不仅在体外成纤维细胞重编程中成功恢复谱系追踪得到的真实结果,还在肺损伤后预测出从杯状细胞向基底细胞去分化的新轨迹。实验进一步验证了杯状与基底细胞之间存在新的中间状态,但该轨迹方向仍需通过谱系追踪确认。
CellRank包含多项创新,包括不确定性传播与高维向量场分析。此前进行向量场分析的方法要么忽略命运决策的随机性及velocity的不确定性,要么并未聚焦于轨迹重建。velocyto模型曾尝试通过模拟马尔可夫过程前推或后推来寻找初始与终末状态,但依赖于二维t-SNE嵌入,不仅偏离表型流形,也无法区分具体的初始与终末状态。由于RNA velocity向量本身是带噪声的基因调控状态估计,CellRank通过传播其分布、并按局部噪声水平进行调节,从而提升稳健性。**但当前模型仍需在局部邻域计算velocity向量的矩以近似其分布。未来可能发展从原始计数到终末状态与命运概率的端到端不确定性传播框架。**如果velocity存在系统性偏差(如关键驱动基因的未剪接转录本不足以支持动力学估计),即便进行不确定性传播,最终的命运概率也会受到影响。
与以往基于马尔可夫链的方法不同,CellRank使用的是非对称转移矩阵。非对称矩阵的特征向量通常为复数,缺乏物理意义,难以利用特征分解获取整体动力学。**尽管可通过昂贵的模拟解决此问题,CellRank采用了实Schur分解这一更为稳健的方式,使其能够处理不可对角化矩阵。**在胰腺数据中,CellRank自动识别了α、β与ε状态,但δ宏状态因稀有及其调控未能被velocity正确捕获,因此需人工标注为终末状态。为克服剪接数据的局限,可考虑将模型扩展到包括表观遗传信息,例如染色质可及性,并利用表观遗传变化相对转录变化的时间延迟来提供方向信息。此类信息可通过在马尔可夫链中引入有限记忆来整合。
**在δ细胞发育分析中,研究展示了如何通过基因表达与命运概率的相关性识别潜在驱动因子;另一种可能的方法是基于广义加性模型拟合的参数进行统计检验。**其他现有模型也可利用CellRank的命运概率来改进细胞到谱系的分配。对新识别的δ细胞分化标志仍需进一步实验验证。未来的方向包括将该框架应用于循环细胞及癌症体系。CellRank也可结合时间信息(例如肺数据集中的时间点)来正则化模型,只允许与实验时间一致的转移;或结合谱系追踪数据,使模型遵循克隆动力学。**此外,CellRank也可直接用于分析代谢标记数据。**作为一种解释高维向量场的通用框架,CellRank在研究再生、重编程与癌症等方向难以确定的复杂轨迹时具有广泛应用潜力。