PNAS 2025 | PLACER: 建模蛋白–小分子构象集合
捕捉蛋白–小分子相互作用的构象多样性对于理解天然体系与设计体系都至关重要。研究者开发了图神经网络PLACER(protein-ligand atomistic conformational ensemble resolver),利用全原子级表征来生成蛋白–小分子体系的构象集合。PLACER能够快速描绘对接过程中的蛋白–小分子构象景观,并用于评估设计活性位点的准确性与预组织程度,从而显著提升酶设计的成功率。

获取详情及资源:
0 摘要
建模蛋白–小分子相互作用中的构象异质性对于理解天然体系与评估设计体系都十分关键,但这一问题长期未能得到有效解决。研究者提出,尽管基于残基层面的分子描述在从头结构预测中具有高效性,但在研究折叠态下蛋白与小分子之间的构象多样性时,采用全原子级描述在速度与通用性方面或许更具优势。基于这一思路,研究者开发了名为PLACER的图神经网络(protein-ligand atomistic conformational ensemble resolver),通过对来自CSD与PDB的部分扰动结构进行训练,使模型能够从受损输入中重建正确的原子排布,图中的节点即体系的每一个原子。
PLACER能够在已知原子组成与成键关系的前提下,准确生成多样有机小分子的结构;在输入更大蛋白环境的描述时,还能同时构建小分子与蛋白侧链的三维结构,从而实现蛋白–小分子对接。由于PLACER具备快速与随机采样的特点,模型可以轻松生成构象集合,用以描绘体系的异质性。
在研究者及其他团队的酶设计工作中,利用PLACER评估活性位点的准确性与预组织程度显著提升了设计成功率与酶活。研究中获得了一种预组织的逆醛缩酶,其
1 引言
蛋白与核酸、小分子有机与无机化合物以及金属之间的相互作用对生命功能至关重要,但要在全原子尺度上准确建模这些相互作用及其构象异质性仍然十分困难。基于深度学习的小分子对接方法如DiffDock相较Glide与GNINA/SMINA有所提升,但在高精度任务上差异并不显著,并且在遇到未见过的受体时性能明显下降。同时,也有研究利用化学结构生成小分子的三维构象;在以半经验量子化学方法计算的GEOM-DRUGS训练集上,扩散生成模型展现出领先性能。然而,此类方法通常仅适用于特定类型的相互作用伙伴,输入特征也因分子类型不同而变化,限制了模型抽取通用物理化学规律的能力。
AlphaFold2与RoseTTAFold依靠多序列信息与残基层面描述实现了蛋白与蛋白复合物的原子级结构预测。其后续扩展如AF3进一步支持蛋白–核酸与更一般的生物体系建模,即通过在残基层面token之外补充体系中非蛋白部分的全原子表征。然而,在接近天然结构的全原子尺度下,复杂度显著提升,多序列信息的重要性也降低。因此,一个用于生成构象集合的方法不必从氨基酸序列入手,而应基于包围结合口袋或催化口袋的蛋白主链坐标,并结合相互作用小分子与氨基酸侧链的成键几何信息。这样的网络并不适用于从序列预测结构,但非常适合在孤立状态或结合位点内建模小分子、限制性肽段及其相互作用侧链的构象。由于蛋白主链结构作为输入,运算成本可显著低于AF2、AF3与RF,从而实现快速的结合位点精修与评估。此外,若网络能够以随机方式生成预测,则可高效地产生构象集合,用于研究具有多状态分布的体系,并评估设计分子或功能位点的预组织程度。
基于上述思路,研究者开发了名为PLACER的随机深度神经网络,用于小分子及小分子–蛋白相互作用的全原子建模。在许多应用中,蛋白结构可通过AF2或RF获得,结合区域在蛋白表面也通常已知,任务便转化为在该区域中对接小分子,并同时调整蛋白侧链与小分子的构象。研究者将学习问题表述为结构去噪任务,在已知体系完整化学信息的前提下,让模型从部分扰动的输入中恢复正确原子坐标。扰动策略根据具体任务而定。在蛋白–小分子对接的场景中,网络输入包括蛋白主链坐标、随机初始化于各自Cα周围的侧链坐标、以及随机置于结合口袋附近的小分子原子坐标。输入体系首先被转化为化学图,其中节点表示重原子,边表示化学键,此表示在不同分子类型间统一。每个节点包含原子类型与被扰动的三维坐标,网络需迭代去噪并预测原子位置的不确定性。
PLACER采用受RoseTTAFold启发的三轨架构。1D与2D特征经初始嵌入后进入迭代模块,不断更新嵌入与三维结构。在迭代过程中,首先构建原子邻域图:对于每个原子,从空间距离与化学图距离两方面各选取相同比例、共32个最近邻。随后,2D特征经前馈适配层投射为边嵌入,并连同1D特征、邻域图与当前三维结构共同输入SE3-Transformer以更新坐标与1D嵌入。手性中心的信息通过一类向量特征传递。2D轨道的特征进一步经结构偏置的pair-to-pair更新。1D与2D轨道在每轮迭代后均分支预测原子与原子对的置信度。最终网络包含八个权重共享的迭代模块。
训练过程中,模型在每轮迭代后计算结构损失与置信度损失。主结构损失为全原子框架对齐点误差
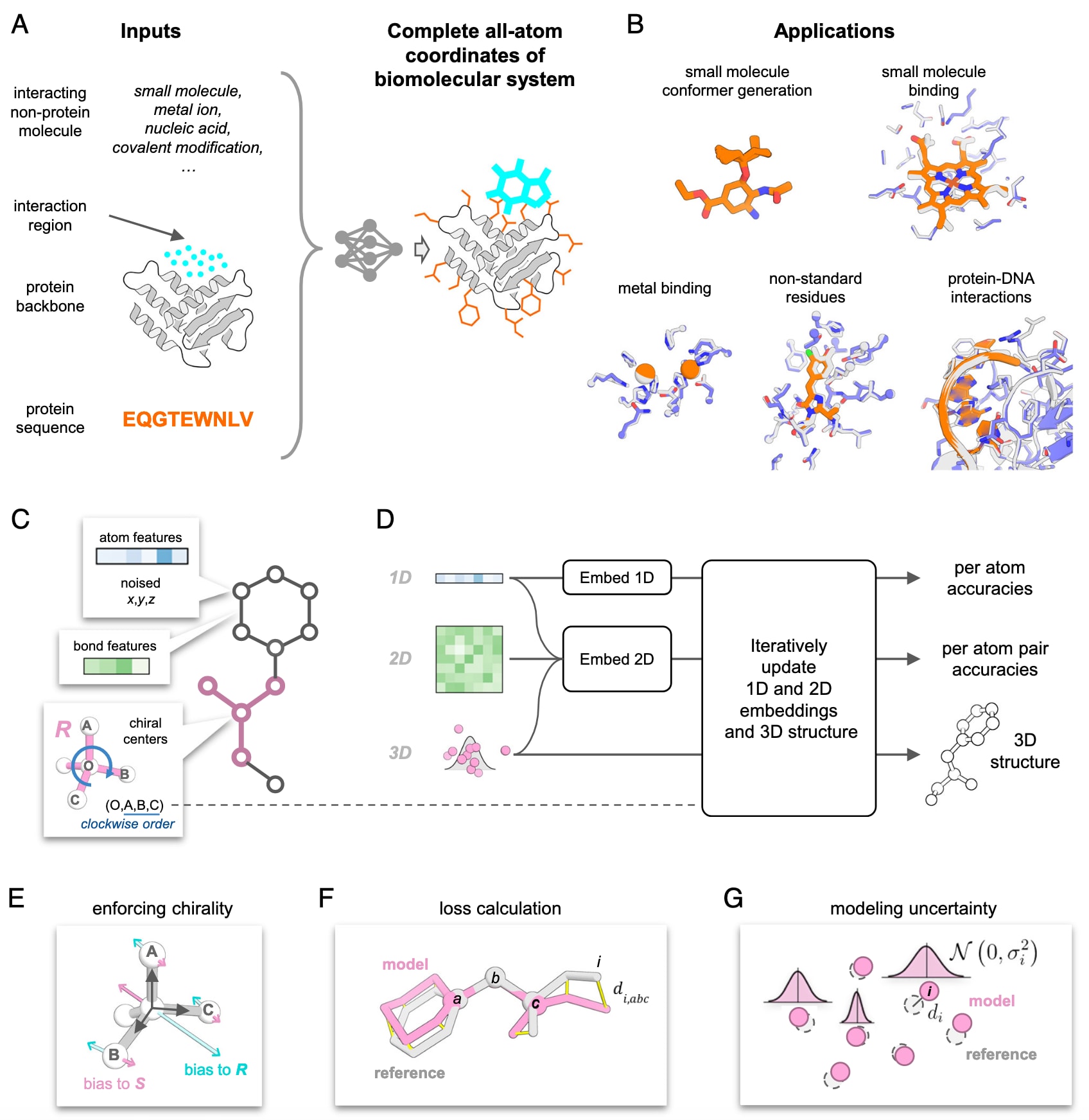
图1|展示了PLACER的整体框架。 (A) PLACER是一个去噪神经网络,输入为部分受扰动的蛋白结构以及相互作用分子的化学结构(但不包含坐标),输出为复合物的全原子结构及其原子位置的不确定性。(B) PLACER可用于多种任务,包括小分子与金属的对接、非标准残基的建模,以及在蛋白–DNA界面预测氨基酸与核苷酸侧链构象。图中灰色为X射线结构,蓝色与橙色为PLACER模型。(C) 输入时,分子体系被表示为标注化学图,节点为单个原子,边为化学键。手性中心的信息以(O, A, B, C)元组形式输入,其中O为手性中心原子,A、B、C为其邻接原子,并按顺时针排序。(D) PLACER为三轨网络,迭代更新1D与2D嵌入以及3D坐标,在每次迭代中生成更精细的原子结构并估计原子位置不确定性。(E) 三个从手性中心指向其邻居的单位向量的三重积
2 在小分子实验结构上微调网络架构
基于实验解析的小分子结构来调试网络架构十分关键。对于小而刚性的分子,其三维结构通常已知,而体积更大的有机分子往往具有独特的基态结构,利用计算方法预测这些结构既耗时又困难,因此如何准确预测一般分子的三维构象仍是一项重要挑战。研究者在剑桥结构数据库的晶体结构上探索了网络架构与训练超参数,这不仅保证了模型能够处理多样化的化学结构,也显著缩短了架构搜索的时间(在PDB上训练至收敛的代价约高一个数量级)。
训练任务是从化学结构与随机初始化的原子坐标恢复出晶体中观察到的小分子构象。训练集与验证集分别包含226,684与7,116个有机非聚合小分子,且训练过程中未使用置信度预测头。由于PLACER是去噪网络,通过多次随机初始化输入坐标并独立运行模型即可生成结构多样的分子构象样本。
在CSD结构上的训练分为两个阶段:第一阶段使用四个迭代模块,并仅采用
完整训练后的PLACER能够以亚埃级精度生成复杂分子的正确三维结构,甚至包括原子数超过50的巨大环结构(图2D),其中也包含肽类大环分子。

图2|展示了PLACER在复杂小分子建模中的表现。 (A) PLACER根据小分子的化学结构与随机初始化的原子坐标预测其三维结构。通过多次随机初始化并独立运行模型,可以获得一组结构多样的分子构象。(B) 当移除PLACER中的关键特征时,模型性能明显下降,这里以模型结构与参考X射线结构在最佳比对后的原子坐标RMSD来衡量。(C) 展示了图2B中五个网络生成结构的局部几何质量,包括键长、成键角、平面角与手性角的平均绝对误差。图中使用CSD的7,116个小分子作为验证集,每个示例仅生成一个构象,误差条表示五次独立验证的标准差。(D) 七个大环分子的预测示例,PLACER能够生成准确的大环三维结构。图中蓝色为1,000次生成中RMSD最优的模型,灰色为晶体结构,括号中为CCDC数据库编号。
3 使用PLACER建模蛋白质小分子相互作用
利用PLACER建模蛋白–小分子相互作用需要在PDB结构(包括蛋白与小分子,而非如CSD那样仅含小分子)上对模型进行训练。研究者使用Chemical Component Dictionary将PDB中的各类残基与小分子解析为化学图。尽管PDB中一些分子可能为非生物性化合物(如溶剂),其相互作用也可能并不特异,但这些相互作用同样包含界面物理化学偏好的信息,因此仍然保留用于训练,只有水分子被排除。训练集与验证集分别包含112,828与7,090个分辨率优于2.5 Å的结构。训练时,输入结构被裁剪至最多600个重原子,并围绕随机选定的原子进行居中。裁剪出的各分子片段中,所有非主链原子被收缩至对应的主链原子(若为氨基酸或核酸),或随机选定的原子(若为配体),并加入σ=1.5 Å的高斯噪声。模型任务是从这些扰动起点恢复裁剪区域中全部原子的正确坐标。
在配体对接任务中,通过多次随机初始化坐标并独立运行模型即可生成配体在结合口袋内的构象集合。每次运行时随机选择一个配体原子,对其坐标加入高斯噪声并将其他配体原子全部折叠至该点,再加入独立的高斯噪声,从而完全打乱配体内部结构与初始取向。对生成的构象集合分析表明,PLACER对初始位置不敏感,不同初始点均能产生接近天然的构象,并覆盖输入空间。配体原子预测偏差计算得到的pRMSD能够有效筛选更准确的构象;在血红素与皮质醇上的实验分别达到0.53 Å与0.77 Å的配体RMSD。
为评估PLACER在更现实情境(即对非天然构象进行对接)中的表现,研究者使用Astex非天然测试集,包括65个药物靶点与1,112个非天然结构。结果显示采样与评分均很重要:生成更多模型可提高近天然构象的选取成功率。在三种置信度指标中,pRMSD具有最佳选择能力,优于Vina、GOLD与GalaxyDock。相较表现最佳的Rosetta GALigandDock,PLACER在低精度阈值(RMSD<2 Å)上更强(82.4% vs. 73.6%),但在高精度阈值(RMSD<1 Å)上略逊(41.8% vs. 51.6%)。值得注意的是,PLACER并未针对非天然蛋白–小分子对接进行特定训练,而且必须从零开始恢复小分子与侧链构象,而传统方法多依赖输入蛋白结构,因此其表现仍具竞争力。进一步结合基于物理的Rosetta力场,可在<1 Å阈值上额外提升7.3%的成功率。
在PoseBusters基准上的比较显示,在118个不包含于训练与验证集的复合物上,PLACER在<2 Å阈值下获得84%成功率,高于AlphaFold3(77%)与RF All-Atom(38%)。在更严格的<1 Å阈值下,AlphaFold3稍优(58% vs. 51%)。
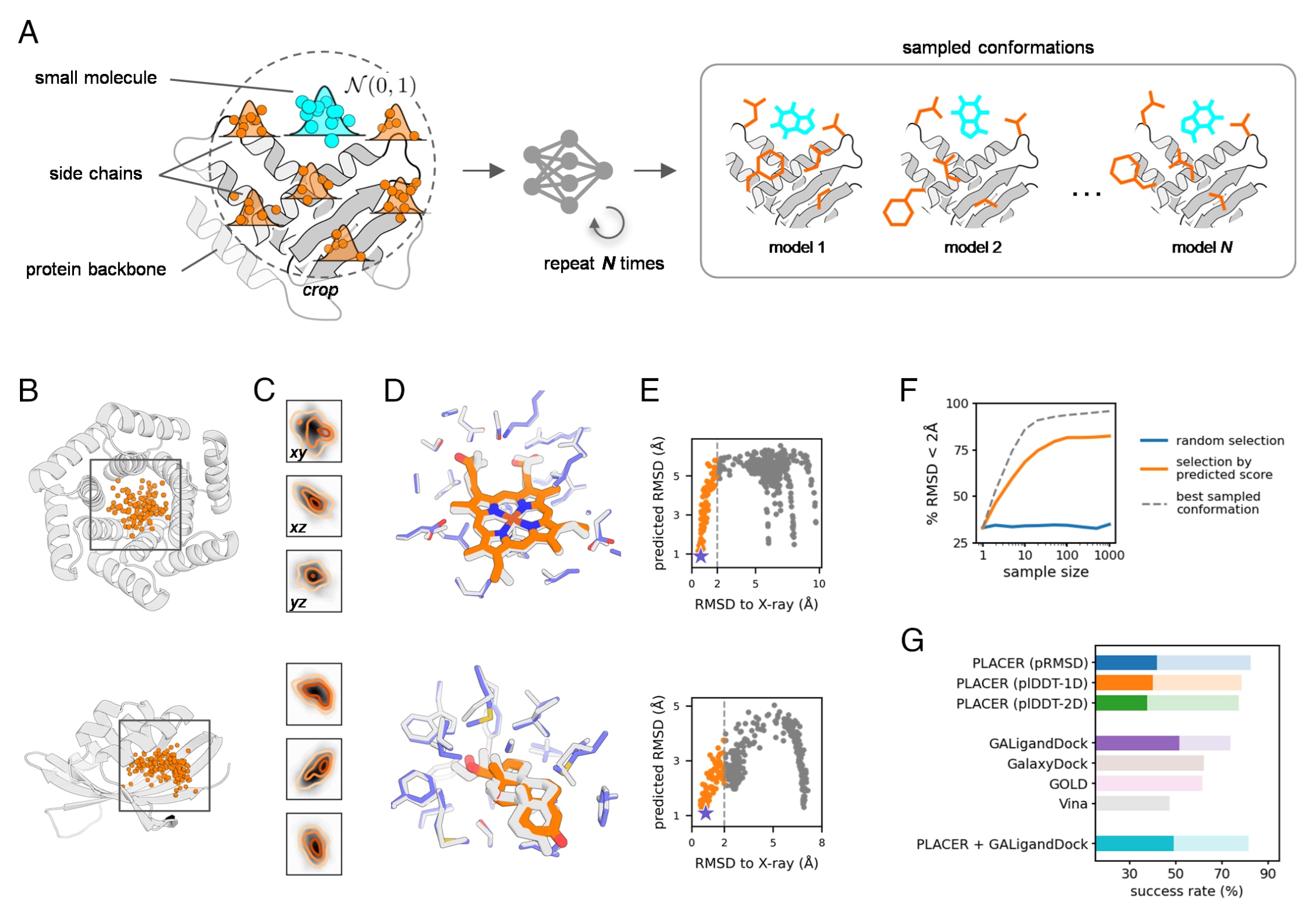
图3|展示了PLACER在蛋白–小分子相互作用建模中的应用。(A) 以蛋白主链结构为起点,并将小分子的坐标随机初始化在结合位点附近(青色点),PLACER能够预测蛋白侧链构象(初始随机化于各自Cα周围,橙色点)、以及小分子相对于蛋白的最终结构与位置。通过多次重复这一过程,PLACER可生成结构多样的对接构象集合。(B、C) 两个从头设计的小分子结合蛋白的示例,展示小分子的采样起始位置。C中为这些起始点在三个坐标平面上的投影,灰度代表起始点密度,橙色轮廓表示最终对接结果中配体RMSD < 2 Å的起始点密度。两者高度重叠,说明PLACER对配体在口袋中的初始放置并不敏感。(D) 具有最低pRMSD得分的构象(蓝/橙)与实验结构(灰)高度一致。(E) pRMSD得分更低的模型更接近天然构象,体现了该评分的判别力。(F) 增大采样规模并使用pRMSD重评分(橙色曲线)可显著提高选到优质模型的概率,优于随机选择(蓝色曲线),但仍未达到最优(灰色虚线)。(G) 在PLACER预测的三种精度指标中,pRMSD表现最佳(图顶部三条)。鲜色与浅色分别表示Astex非天然集合中配体RMSD < 1 Å与 < 2 Å的对接成功率。中间四条为常用对接工具Vina、GOLD、GalaxyDock与Rosetta GALigandDock的表现。使用PLACER采样并通过GALigandDock最小化与重评分,可在<1 Å阈值上比单独使用PLACER提升7.3%的成功率。
4 评估酶活性位点设计的准确性与预组织程度
评估酶活性位点设计的准确性与预组织程度是从头酶设计中的核心难题。设计任务不仅需要获得能够折叠成目标主链构型的氨基酸序列,还必须确保催化侧链与底物被精准定位,使关键官能团能够与过渡态及彼此之间形成正确的氢键与静电作用。由于距离偏差0.5 Å或角度偏差30°即可显著影响氢键能量,所需构型精度极高。此外,优秀的活性位点应在未结合底物时就保持预组织状态,即催化残基主要通过蛋白内部相互作用被固定,以减少底物结合时的熵代价,同时确保所有催化基团排列恰当。这种预组织特征在天然酶中十分常见。
评估预组织最通用的方法是分子动力学模拟,但由于侧链重排可能发生在微秒尺度,此类模拟计算代价极高,难以应用于大规模设计筛选。离散近似方法如Rosetta Rotamer Boltzmann可在单侧链层面估计预组织,但受制于构象限制,无法描述侧链与小分子的协同运动。研究者认为,PLACER能够通过快速生成小分子与相互作用侧链的构象集合来评估活性位点的准确性与预组织程度,速度远快于分子动力学,也不受构象库方法的局限。
研究者将PLACER应用于此前设计的RA95系列逆醛缩酶,并比较其经定向进化改造的高活性版本,这些酶均已有高分辨率晶体结构。在每个反应中间体上运行50次PLACER,并通过侧链原子(不含主链N、Cα、C、O)的平均预测RMSD评估催化赖氨酸及其加成物的构象多样性。结果显示,早期低活性设计的构象集合高度分散,体现出严重缺乏预组织,而进化后的高活性版本则构象趋于集中,体现出更高的预组织程度。这说明预组织不足是早期酶设计的重要短板,而PLACER为其提供了快速、可靠的评估手段。
随后,研究者进一步将PLACER用于前瞻性设计。基于此前能产生高活性de novo荧光素酶的DL生成NTF2样折叠,构建了新一轮逆醛缩酶设计。活性位点来源于演化版本中最活跃的赖氨酸四元催化组,其内部由复杂的氢键网络支撑,因此难以设计。研究者希望利用PLACER筛选、识别更具预组织特征的活性位点。通过RosettaMatch与LigandMPNN生成320个设计,并首先在体外转录翻译系统(IVTT)中筛选活性,再对活性最高的变体进行表达与纯化,测定其
分析PLACER的预组织指标与实验活性之间的关系时,研究者聚焦于反应路径中各步骤中与中间体相连的催化赖氨酸的构象灵活性。结果表明,
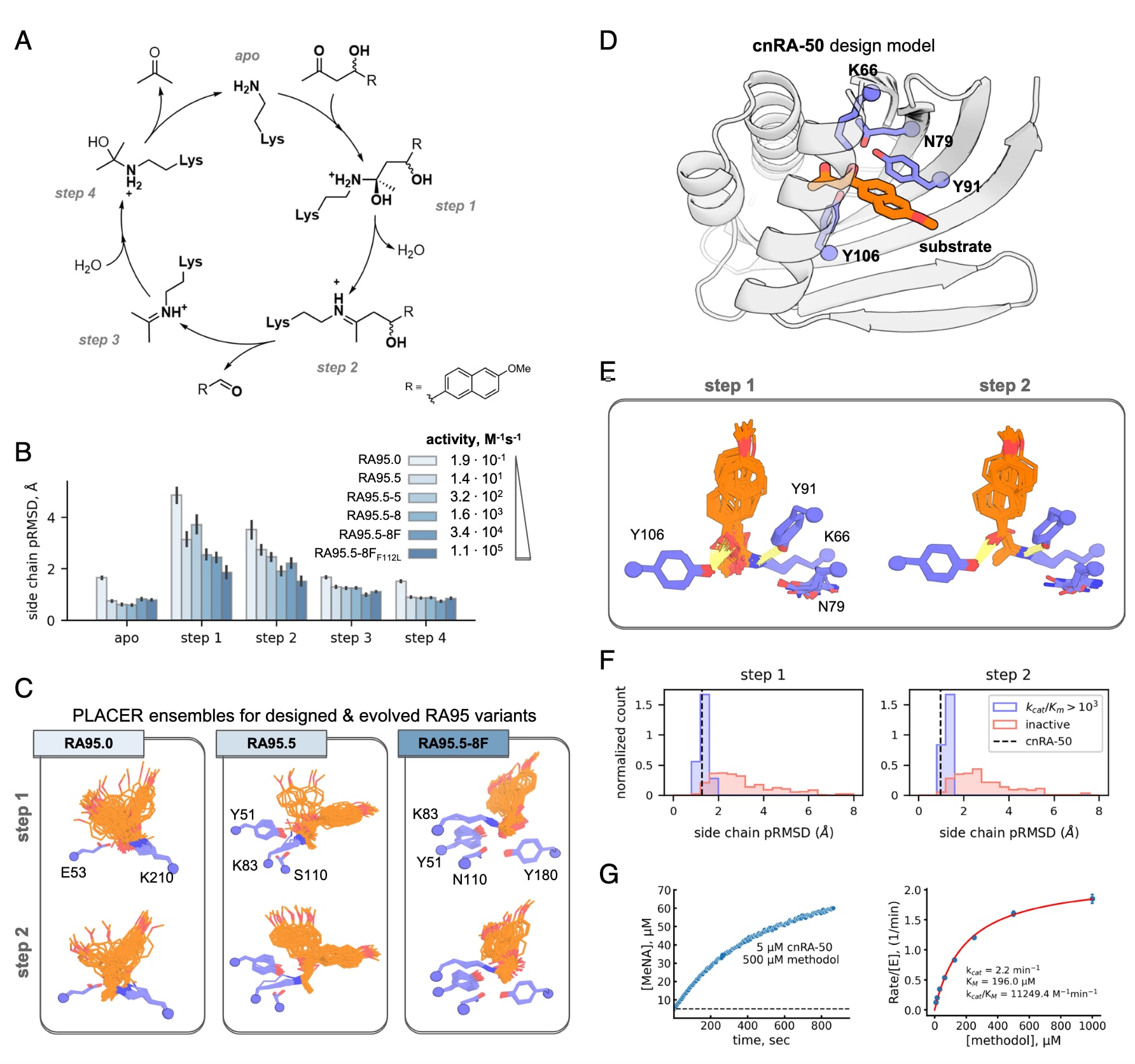
图4|展示了利用预组织催化残基筛选设计,可提升酶活性的结果。(A) 逆醛缩反应机制及其关键中间体。(B) 使用PLACER对RA95系列设计在与methodol反应时的五个中间态进行建模,用于评估活性位点赖氨酸及其修饰形式的预组织程度。(C) 三个已发表的逆醛缩酶设计的PLACER构象集合示例,随着酶活性提升,其在反应路径步骤1与步骤2中的预组织程度逐渐增强。(D) 最活跃变体cnRA-50的设计模型,其中催化四元体以蓝色标示,底物以橙色标示。(E) PLACER生成的cnRA-50在反应步骤1与步骤2中赖氨酸–methodol加成物的构象集合。(F) 利用PLACER评估活性位点预组织的指标(即不含主链的赖氨酸加成原子pRMSD),能够富集筛选出更高活性的从头设计逆醛缩酶。(G) cnRA-50催化逆醛缩反应的实验数据:左图为生成6-methoxy-2-naphthaldehyde的时间过程,右图为基于初速度获得的米氏曲线。
5 结论
PLACER在已知蛋白序列与主链原子坐标的前提下,能够快速生成小分子在孤立状态或结合位点中的构象集合。与AF3、RF All-Atom等蛋白结构预测方法不同,PLACER并不预测蛋白主链结构,从而大幅提升了计算效率,使其能够以随机方式生成大量构象集合。由于所有相互作用均采用一致的原子级表征,模型可以自然扩展到大环及其他复杂小分子。
这种快速生成蛋白–小分子构象集合的能力对计算酶设计与小分子结合物设计尤为重要:模型能够直接评估目标活性位点的重建精度以及关键催化/相互作用侧链的预组织程度。PLACER对活性位点准确性与预组织的评估显著提高了多步丝氨酸水解酶与Zn依赖金属水解酶的设计成功率。该研究还展示了利用PLACER设计出活性远超深度学习前时代的逆醛缩酶,且无需实验定向改造。
研究者认为,基于PLACER的构象集合生成将广泛适用于建模复杂非蛋白分子在孤立状态及蛋白环境中的结构,并可在更普遍意义上用于评估酶设计与蛋白–小分子结合体的设计质量。