JMC 2022 | RTMScore: 基于残基–原子距离似然势能与图 Transformer 的蛋白质–配体结合姿势预测与虚拟筛选的增强方法
今天介绍的是2022年发表于JMC的一项工作,提出了面向蛋白质–配体结合姿势预测与虚拟筛选的RTMScore方法。该研究旨在突破传统打分函数在泛化性与稳健性方面的局限,通过引入残基级图表示与图Transformer结构,更有效地捕捉蛋白质口袋与配体之间的空间互作特征。在模型架构中,RTMScore以残基–原子距离似然势能为核心,将蛋白质与配体的节点表征经混合密度网络转换为统计势能,进而用于对接评分与筛选排序。值得注意的是,无论在CASF-2016基准、cross-docked姿势,还是在DEKOIS2.0与DUD-E等大规模筛选数据集上,该方法均展现出领先的对接成功率与筛选能力,同时保持对蛋白质旋转的不敏感性,并可在原子与残基层面给出解释性贡献。整体而言,RTMScore展示了机器学习打分函数在结构驱动药物设计中的进一步发展方向,为对接重评分与虚拟筛选带来了更具潜力的选择。

获取详情及资源:
0 摘要
过去数年中,机器学习在蛋白质–配体打分函数的开发方面取得了巨大进展。然而,要在基于对接的虚拟筛选中持续提高成功率,打分函数在稳健性与广泛适用性方面仍然面临重大挑战。该研究提出一种名为RTMScore的全新打分函数,通过引入基于残基的图表示策略以及多层图Transformer对蛋白质与配体进行表征学习,随后使用混合密度网络以获得残基–原子距离的似然势能。在CASF-2016基准上的严格验证显示,在对接能力与筛选能力两方面,RTMScore均优于几乎所有现有的先进方法。进一步评估表明,该方法具有良好的稳健性,不仅能够在cross-docked姿势上保持对接性能,还能在大规模虚拟筛选中作为重评分工具获得更佳表现。
1 引言
在基于结构的药物设计中,准确预测蛋白质–配体结合模式始终是一项具有挑战性的任务。X射线衍射、核磁共振晶体学以及冷冻电镜等实验技术能够解析复合物的结构细节,但这些手段成本高昂且难以覆盖所有目标体系。分子对接作为替代性的计算方法,在先导化合物发现与后续优化中发挥了重要作用。典型对接流程通常先通过搜索引擎在结合口袋中采样可能的结合姿势,再使用打分函数评估其结合强度,并将得分最高的姿势视为最合理的结合构象。然而,尽管历经数十年的发展,打分函数的不准确性仍旧是阻碍分子对接在真实应用中稳定可靠的主要瓶颈。
传统打分函数大致分为物理型、经验型、知识型以及基于机器学习的类别。前两类通常由加权能量项构成;知识型打分函数通过统计分析蛋白质–配体结构中的几何分布,构建配体与蛋白之间的成对统计势能。随着机器学习与人工智能的迅速发展,越来越多的模型尝试直接从数据中学习函数表达,而不依赖预定义的加和式模型。虽然后者在许多研究中表现优于传统方法,但其泛化能力不足的问题引发了广泛担忧。例如,有研究指出,某些基于随机森林与支持向量机的模型虽能重现优异的亲和力预测结果,但在对接能力与虚拟筛选能力上表现糟糕。先前对多种机器学习打分函数的系统评估同样表明,许多主要基于PDBbind复合物训练的模型,在更大规模测试集上的虚拟筛选性能甚至明显低于传统的Glide SP。因此,从机器学习模型的本质来看,大多数现有方法往往只能适用于单一任务,例如亲和力预测、结合姿势预测或虚拟筛选。尤其是面向对接或筛选的模型,通常需要额外引入大量负样本(如脱靶姿势或非活性分子),而经典打分函数仅依赖PDBbind即可用于不同任务。
尽管如此,近年来仍不断涌现旨在提升通用性的机器学习打分函数。例如ΔVinaRF20、ΔVinaXGB与ΔLin_F9XGB等方法,通过对传统AutoDock Vina或其他经验函数进行修正,在CASF基准上实现了优异表现。OnionNet-SFCT则将基于深度学习的姿势预测误差作为校正项,与Vina得分线性组合以增强对接和筛选能力。深度学习的进一步发展也推动了更具泛化性的策略,例如MT-Net的多任务学习框架,或PIGNet基于物理启发的原子层级相互作用建模。然而,这些方法仍需依赖额外的负样本,未能摆脱传统打分函数的定义。
最新的DeepDock方法引入了混合密度网络,学习配体原子与蛋白表面点之间距离的概率密度分布,通过整合所有成对负对数似然形成统计势能,在对接与筛选任务中取得了良好表现。但该方法将蛋白质三角化为表面网格并构建网格图,导致其对蛋白质旋转较为敏感,且在图表示学习的快速发展背景下仍有改进空间。
基于此,RTMScore提出了一种结合残基–原子距离似然势能与图Transformer的全新打分函数。蛋白质被表示为三维残基图,配体作为二维分子图,分别通过独立的图Transformer学习节点表示;随后将所有节点特征两两拼接输入混合密度网络,预测每个残基与每个配体原子之间最小距离的概率分布,再通过汇总所有负对数似然得到统计势能。相较DeepDock,RTMScore的核心创新包括:(1)以残基级别的无向图表示蛋白质;(2)采用图Transformer进行蛋白质与配体的特征抽取。这些设计使其在CASF-2016基准的对接与筛选任务中均达到领先水平。进一步评估证实RTMScore具备出色的泛化能力,并可在原子或残基层面量化贡献,展现良好的可解释性。
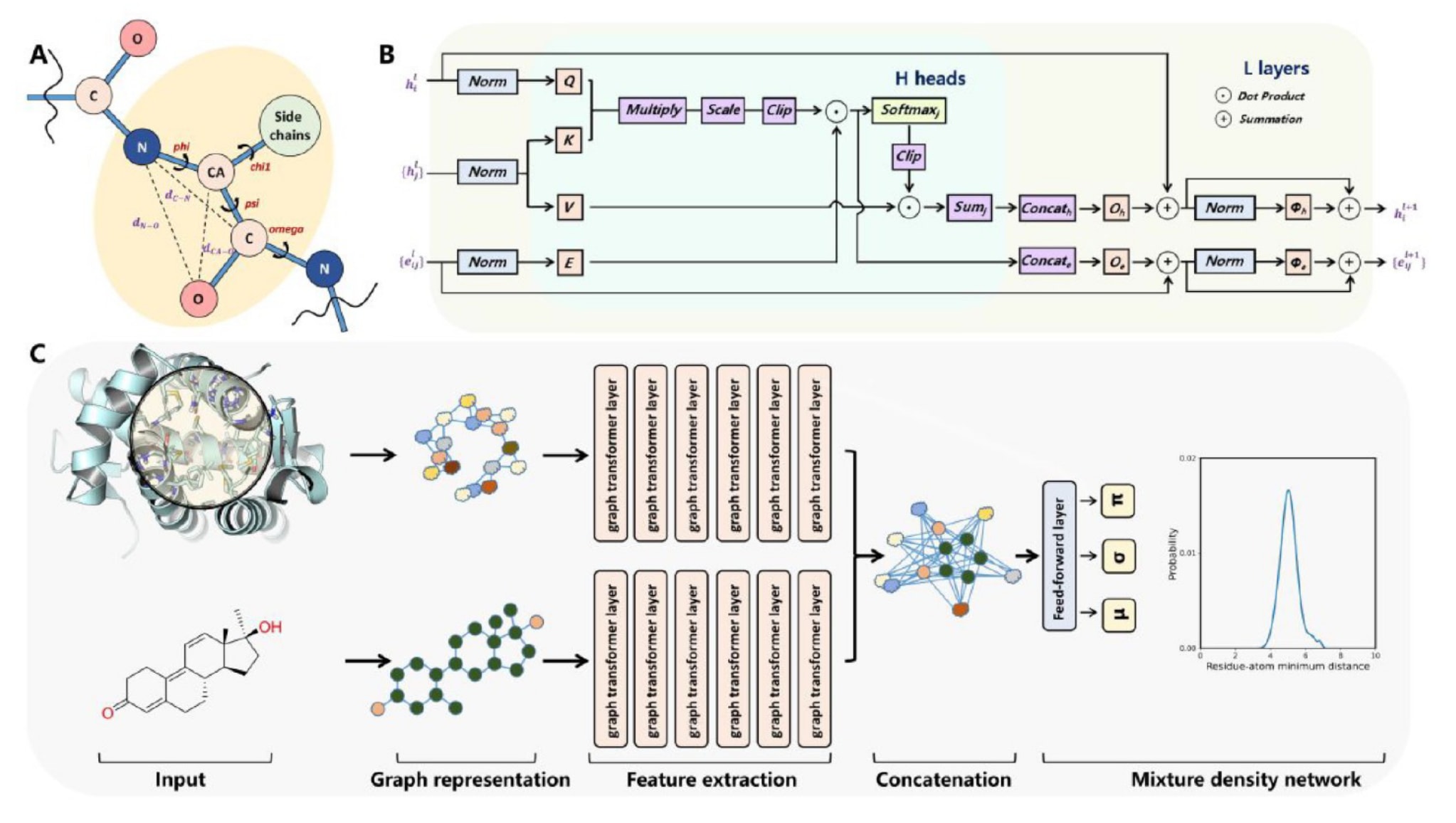
**图1|展示了(A)每个残基的表示方式、(B)图Transformer层结构以及(C)RTMScore整体模型架构。**蛋白质与配体的图表示首先分别经过两组独立的图Transformer层进行特征提取,随后将提取到的特征以成对方式进行拼接并送入混合密度网络。通过对所有节点成对距离的概率分布进行求和,即可得到最终的统计势能。
2 结果与讨论
2.1 RTMScore在CASF-2016基准上实现了同类方法中的领先对接与筛选性能。
首先基于CASF-2016标准基准对RTMScore(图1与表1、表2)进行性能评估,并与多种常用传统打分函数进行比较。亲和力预测(以Pearson相关系数
如预期,由于缺乏结合亲和力信息的充分利用,RTMScore在打分能力(
在结合漏斗分析(图S2)中,基于距离似然势能的方法(RTMScore、RTMScoreM、DeepDockM、DeepDock)之间差异不大,但均显著高于其他方法的
在筛选方面,RTMScore仍保持显著优势。在正向筛选测试中(图2C、2D、表3),于57个靶点中,RTMScore在1%、5%与10%排名区间内平均可识别出38个(66.7%)、47.7个(83.6%)与51.3个(90.1%)靶点的最高亲和力配体,其SR1%甚至超越具物理先验的深度学习模型PIGNet(SR1%=55.4%)。其平均EF1%、EF5%与EF10%分别为28.00、10.02与5.90,与知识型打分函数KORP-PL的表现相当,但仍显著优于其他方法。
在反向筛选(图2E)中,285个配体中,RTMScore在1%、5%与10%排名区间内可分别为平均107.3个(37.6%)、149.3个(52.4%)与177个(62.1%)配体找出真实靶点,而排名第二的DeepDock仅能达到23.9%、39.3%与50.9%。综合筛选的三类指标,RTMScoreM虽未必优于DeepDockM,但RTMScore的突出表现仍充分验证了该策略在筛选任务中的有效性。
表1 | 配体图构建所使用的节点与边特征

表2 | 蛋白质图构建所使用的节点与边特征

2.2 RTMScore在cross-docked姿势上依然保持其出色的对接性能。
由于CASF基准对对接能力的评估仅基于redocked姿势,而此类情形在实际应用中并不常见,因此进一步在此前研究中构建的cross-docking数据集(PDBbind-CrossDockedCore)上测试已训练模型,以检验其在cross-docked姿势上的泛化能力。该数据集基于PDBbind-v2016核心集构建,利用Surflex-Dock、Glide SP与AutoDock Vina三种对接程序,将同一簇中的配体对接至对应蛋白的口袋(生成redocked姿势)或簇中其他蛋白的口袋(生成cross-docked姿势),共形成6个子集。
如表4所示,模型整体上优于多种传统方法,包括对应的对接程序、基于NNscore特征的Vina评分、X-Score与Prime-MM/GBSA等。例如,以Surflex-Dock生成的姿势为例,RTMScore能在redocked与cross-docked情形中分别识别81.0%与50.8%的复合物,而表现最好的传统方法仅达到75.4%与43.8%。在此前工作中,尝试基于Surflex-Dock生成的redocked或cross-docked姿势构建机器学习分类器,以区分近天然姿势与错误姿势。结果显示,基于cross-docked姿势训练的模型在cross-docked测试中表现更优,而在redocked测试中则相反。此外,基于某一对接程序生成的训练数据往往只能在相同程序生成的测试姿势上表现良好,对于Glide SP或AutoDock Vina生成的姿势,模型性能有时甚至低于传统打分函数。这表明此类分类器对训练数据的构成高度敏感,无论是对接模式(redocked或cross-docked)还是对接程序本身都会显著影响其表现。
相比之下,此处提出的方法表现更加稳定且具有更强的鲁棒性。即便将RTMScore的平均表现与这些特定任务模型中最优的进行比较,RTMScore仅在Surflex-Dock生成的cross-docked姿势的top1成功率上略逊一筹(51.8%对52.2%),但在其余五种情形中均表现更好(80.4%对80.0%、73.8%对71.6%、48.8%对47.1%、64.9%对61.4%、40.2%对36.1%)。此外,RTMScore相较DeepDockM在cross-docked姿势上的优势更加明显(cross-docked为51.8%对47.7%、48.8%对45.1%、40.2%对36.7%;redocked为80.4%对78.4%、73.8%对72.7%、64.9%对64.1%),进一步说明RTMScore在cross-docked姿势上具有更好的泛化能力。
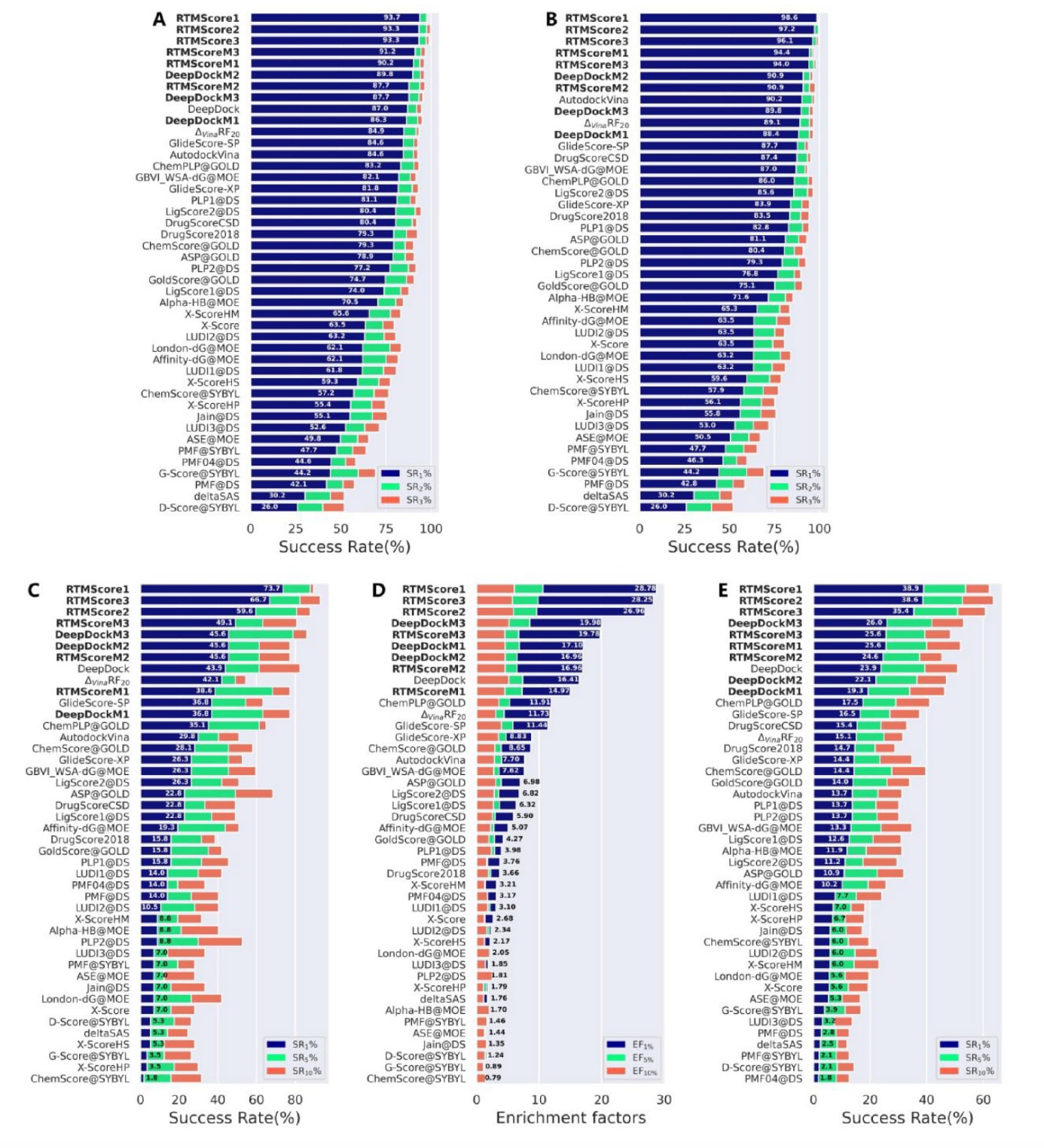
**图2|展示了各类打分函数在CASF-2016基准上的表现,包括(A)不含晶体姿势的对接成功率、(B)包含晶体姿势的对接成功率,以及正向筛选中的(C)成功率与(D)富集因子和反向筛选中的(E)成功率。**该研究重新训练的模型在图中以强调方式标示。所有方法均按照(A、B、C与E)的top1成功率及(D)的EF1%由高到低排序。
表3 | RTMScore与其他先进方法在CASF-2016基准上的对接能力与正向筛选能力的比较
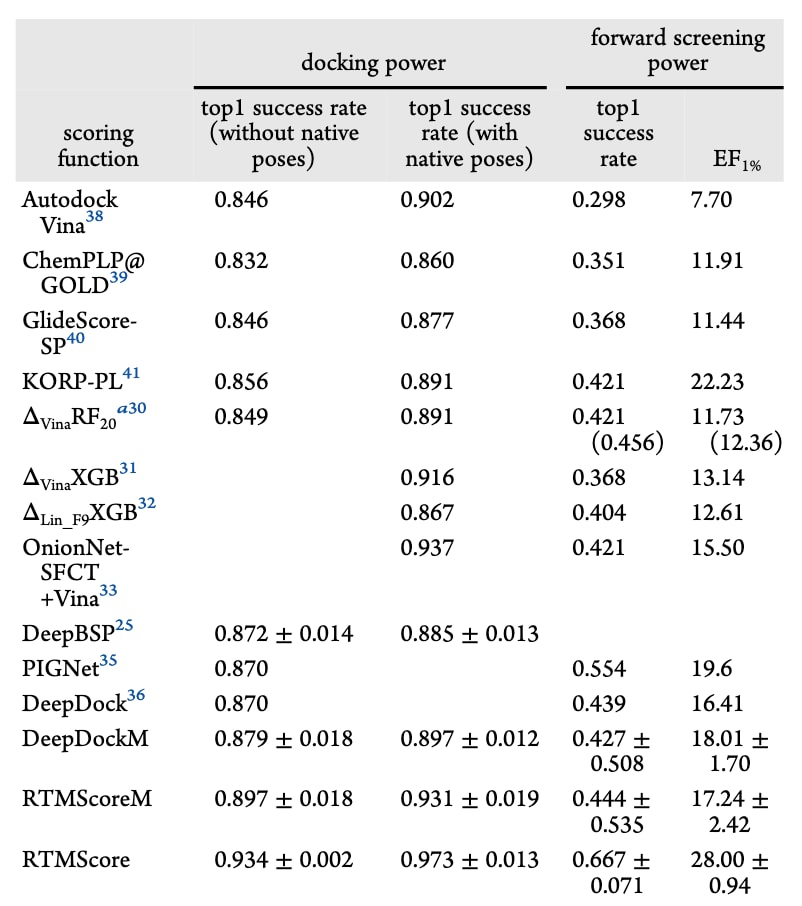
表4 | 在PDBbind-CrossDocked-Core数据集上的top1成功率比较,其中姿势由Surflex-Dock、Glide SP或AutoDock Vina生成
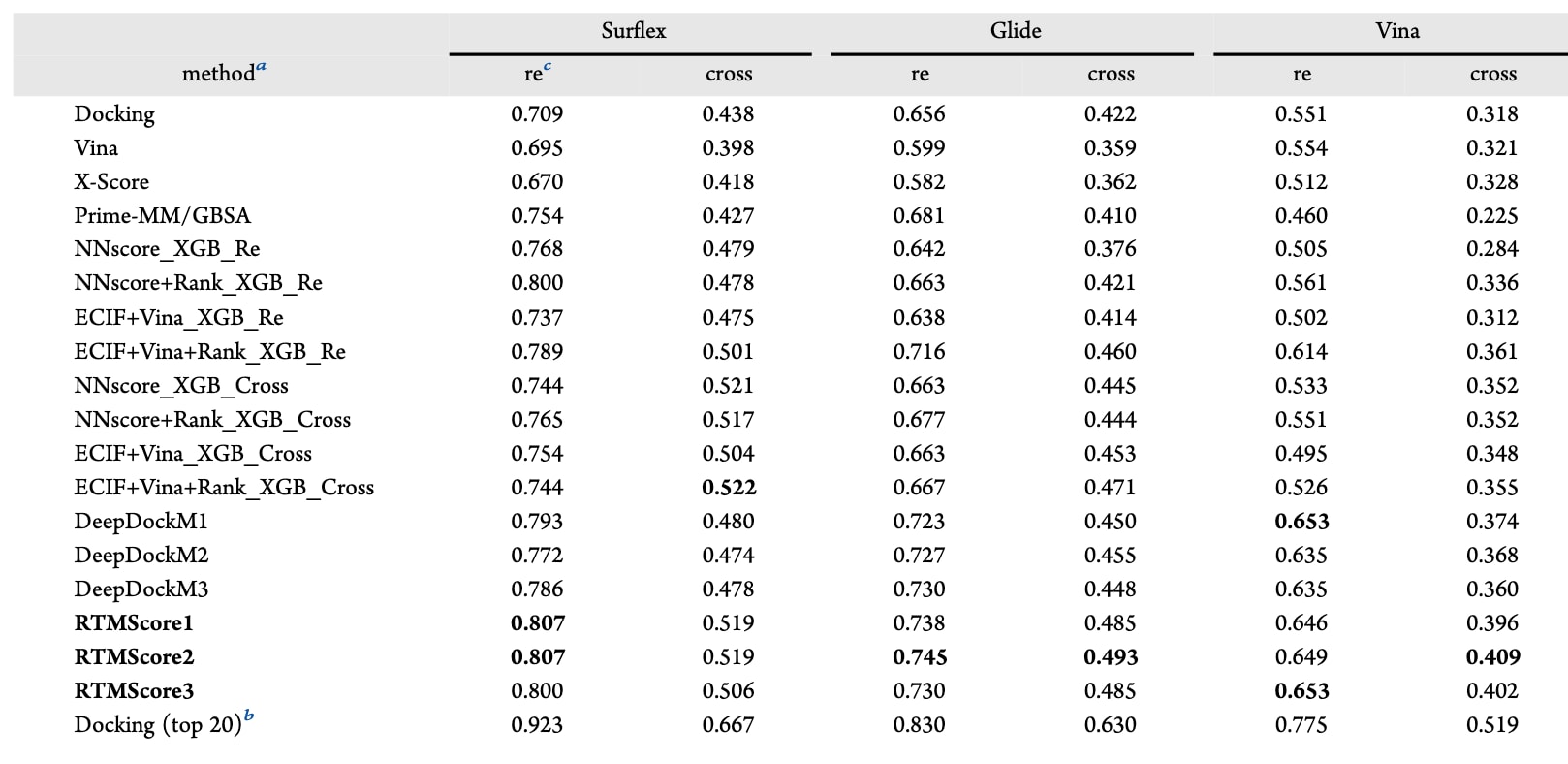
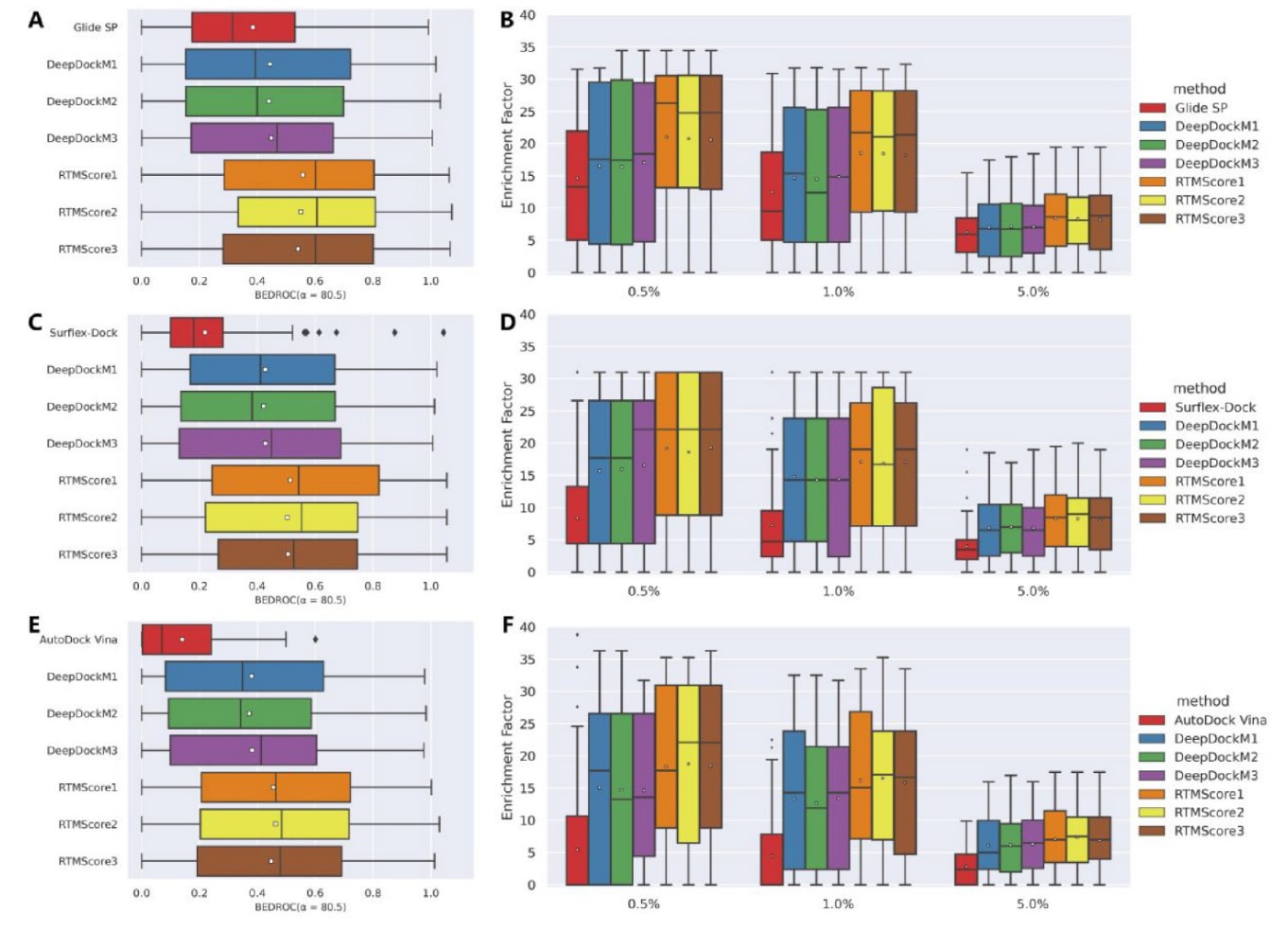
图3|展示了在DEKOIS2.0数据集上,各类打分函数的筛选能力。 其中(A、C、E)为BEDROC(α=80.5),(B、D、F)为在不同阈值(0.5%、1.0%、5.0%)下的富集因子,分别基于(A、B) Glide SP、(C、D) Surflex-Dock与(E、F) AutoDock Vina生成的对接姿势进行评估。箱线图中的白色方块表示各统计量的平均值。
2.3 RTMScore是高效的虚拟筛选重评分工具。
由于CASF用于筛选能力评估的decoy仅限于难以与特定靶点结合的晶体配体,其规模十分有限,因此虚拟筛选方法的评估往往需借助更大规模且包含更多活性分子与decoy的数据集,例如DUD、DUD-E与DEKOIS。尽管这些数据集因潜在偏差而备受争议,但由于此处的方法并未在它们上进行训练,因此这些基准结果仍具有参考意义,同时也能在一定程度上反映模型的泛化能力。
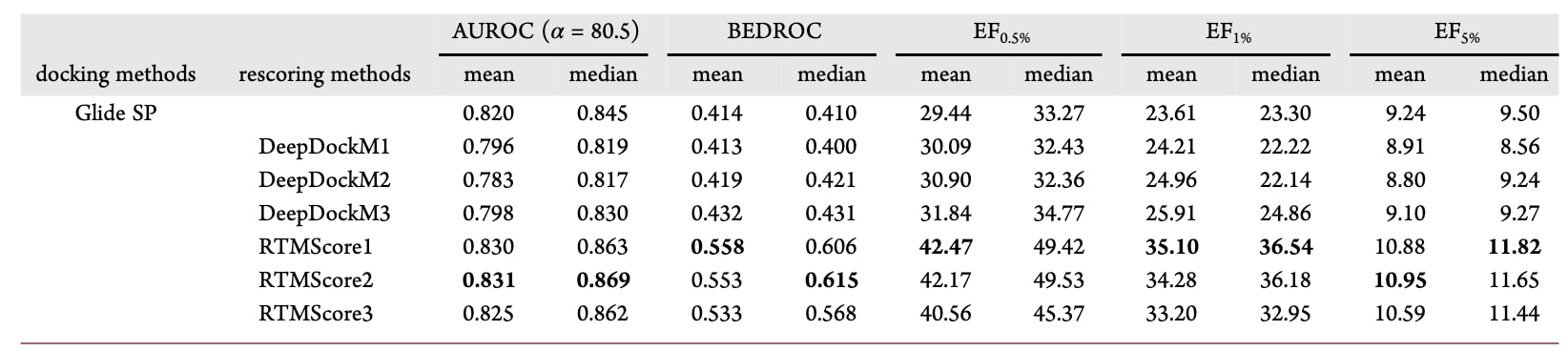
首先采用小型数据集DEKOIS2.0对模型的筛选能力进行评估,并以Glide SP、Surflex-Dock与AutoDock Vina三种常见对接程序作为基线。需要注意的是,对接失败的配体(尤其在Glide SP中常见)或无法重评分的配体会被直接剔除,而不是赋予极低分值。图S3、图3A、3C、3E及图3B、3D、3F分别给出了整体AUROC、BEDROC与EF指标,结果汇总于表5,81个靶点的详细表现则以热图形式呈现(图4与图S4−S7)。
在DEKOIS2.0中,Glide SP被认为是表现最好的传统对接程序,其平均AUROC、BEDROC、EF0.5%、EF1%与EF5%分别为0.747、0.385、14.60、12.47与6.30。基于Glide SP生成姿势的DeepDockM在总体AUROC上并未超越Glide SP(0.737±0.004),但在反映早期识别能力的指标上取得更优表现(BEDROC=0.444±0.004、EF0.5%=16.66±0.35、EF1%=14.69±0.20、EF5%=7.07±0.06)。相较DeepDockM,RTMScore在所有指标上进一步提升,平均AUROC、BEDROC、EF0.5%、EF1%与EF5%分别达到0.764±0.007、0.550±0.009、20.78±0.21、18.39±0.16与8.33±0.11。当使用Surflex-Dock或AutoDock Vina生成姿势时,尽管性能略有下降,但RTMScore仍优于对应的对接方法,甚至在各项指标上超过Glide SP与DeepDockM。基于中位数的统计趋势一致,此处不再赘述。
进一步按靶点家族分析(BEDROC、EF1%、EF5%,图5),DEKOIS2.0中的81个靶点可归为10类,剔除仅含1个靶点的类别后,结果显示RTMScore在转移酶、蛋白酶、激酶、核受体与水解酶五类中均优于传统方法,而在其他两类中稍弱于Glide SP。GPCR家族仅含两个靶点,因此性能波动较大。对于氧化还原酶家族,检查结构发现某些靶点(如INHA、11BSTAHSD1)的口袋中存在除共晶配体外的其他底物,它们与配体共同占据口袋并可能形成相互作用,从而影响模型重评分结果,导致性能下降。
为进一步验证模型在虚拟筛选中的能力,还基于更大规模的DUD-E数据集进行了评估。DUD-E包含102个靶点、8类蛋白家族,共22 886个活性分子,并为每个活性分子提供约50个decoy。使用最优的Glide SP生成姿势后进行重评分,结果见图6与表6。无论按均值或中位数统计,DeepDockM在DUD-E上的表现均未优于Glide SP,而RTMScore仍保持显著优势(平均BEDROC=0.548±0.013、EF0.5%=41.73±1.03、EF1%=34.19±0.95、EF5%=10.81±0.19)。靶点家族级别的分析(图7)同样表明RTMScore普遍优于Glide SP与DeepDockM。
当然,一些基于大量decoy训练或采用靶点特定训练策略的模型在DUD-E或DEKOIS2.0上可取得更亮眼的性能,如InteractionGraphNet在DEKOIS2.0上可获得BEDROC=0.762、EF0.5%=22.46、EF1%=22.23;SIEVE-Score的靶点特定模型在DUD-E上可获得平均EF1%=43.913;其他方法在DUD-E交叉验证中可达到极高的ROC enrichment数值。然而,这些方法通常因训练方式而记忆了数据集的隐藏偏差,从而在不同分布的独立测试集中表现不佳。相较之下,此处的方法完全基于实验解析的蛋白质–配体复合物进行训练,因而其优良表现更能体现模型的稳健性。
综上,各项结果充分证明RTMScore能够作为高效重评分工具显著提升传统对接程序在虚拟筛选中的能力。但需要注意的是,这种提升并非适用于所有靶点,如图4与图S4−S8所示。这部分原因在于该方法的原理更接近知识型打分函数,而Glide SP、Surflex-Dock与AutoDock Vina等经验型打分函数依赖亲和力区分活性分子与decoy;RTMScore由于打分与排序能力有限,主要依赖结合构象的合理性进行判断。因此对于特定靶点,仍可能需要额外评估。
表5 | DEKOIS2.0数据集上各类打分函数的筛选能力

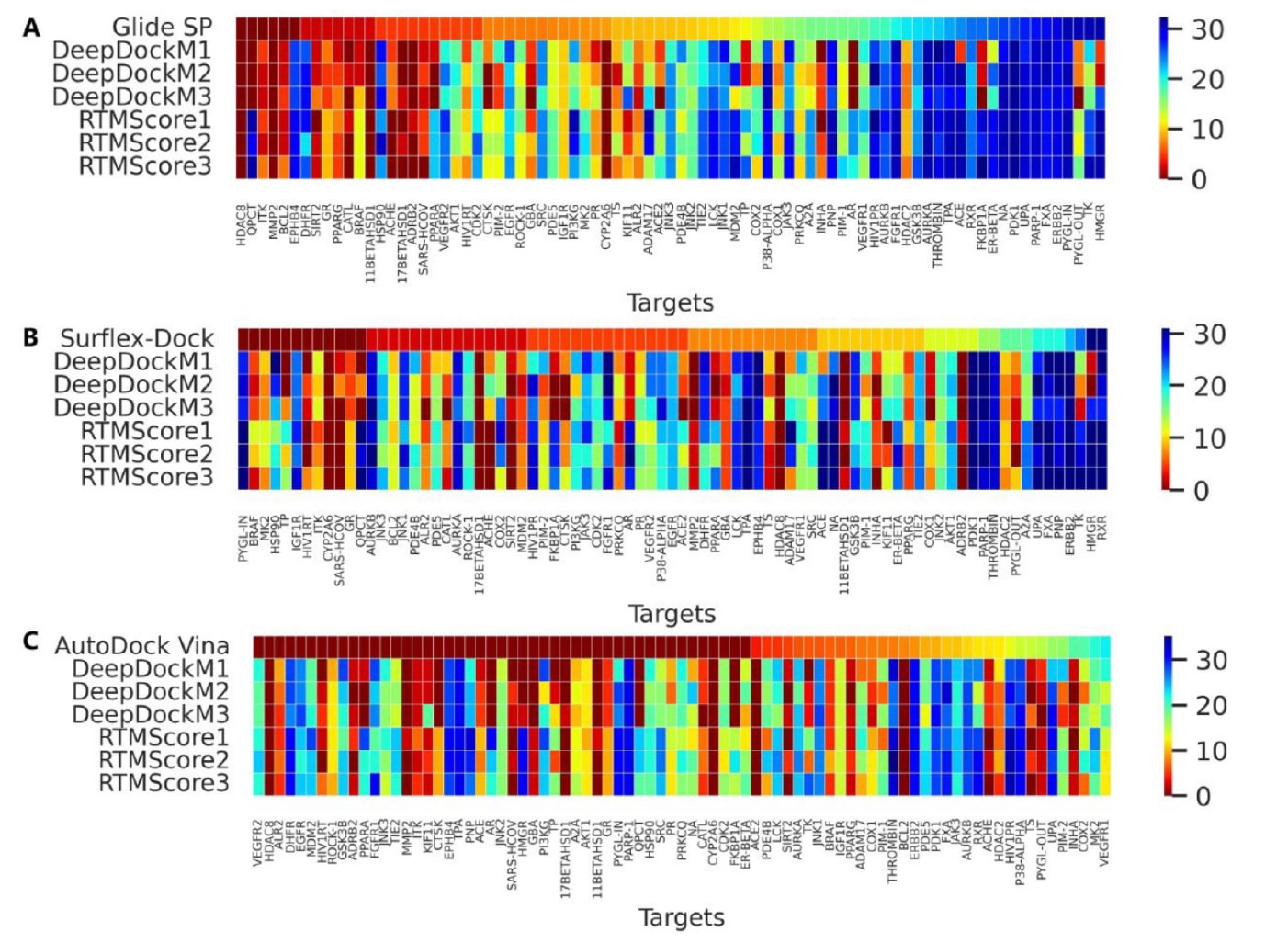
**图4|展示了在DEKOIS2.0数据集上,各类打分函数基于(A) Glide SP、(B) Surflex-Dock与(C) AutoDock Vina生成的对接姿势所得的EF1%数值。**每个子图中的所有靶点均按照对应对接方法测得的EF1%数值由高到低排序。

**图5|展示了在DEKOIS2.0数据集上,不同蛋白家族的筛选能力结果。**其中(A、D、G)为BEDROC(α=80.5),(B、E、H)为EF1%,(C、F、I)为EF5%,分别基于(A−C) Glide SP、(D−F) Surflex-Dock与(G−I) AutoDock Vina生成的对接姿势进行评估。箱线图中的白色方块表示各统计量的平均值。由于同工酶、连接酶与other类别仅包含一个靶点,因此未在图中展示。
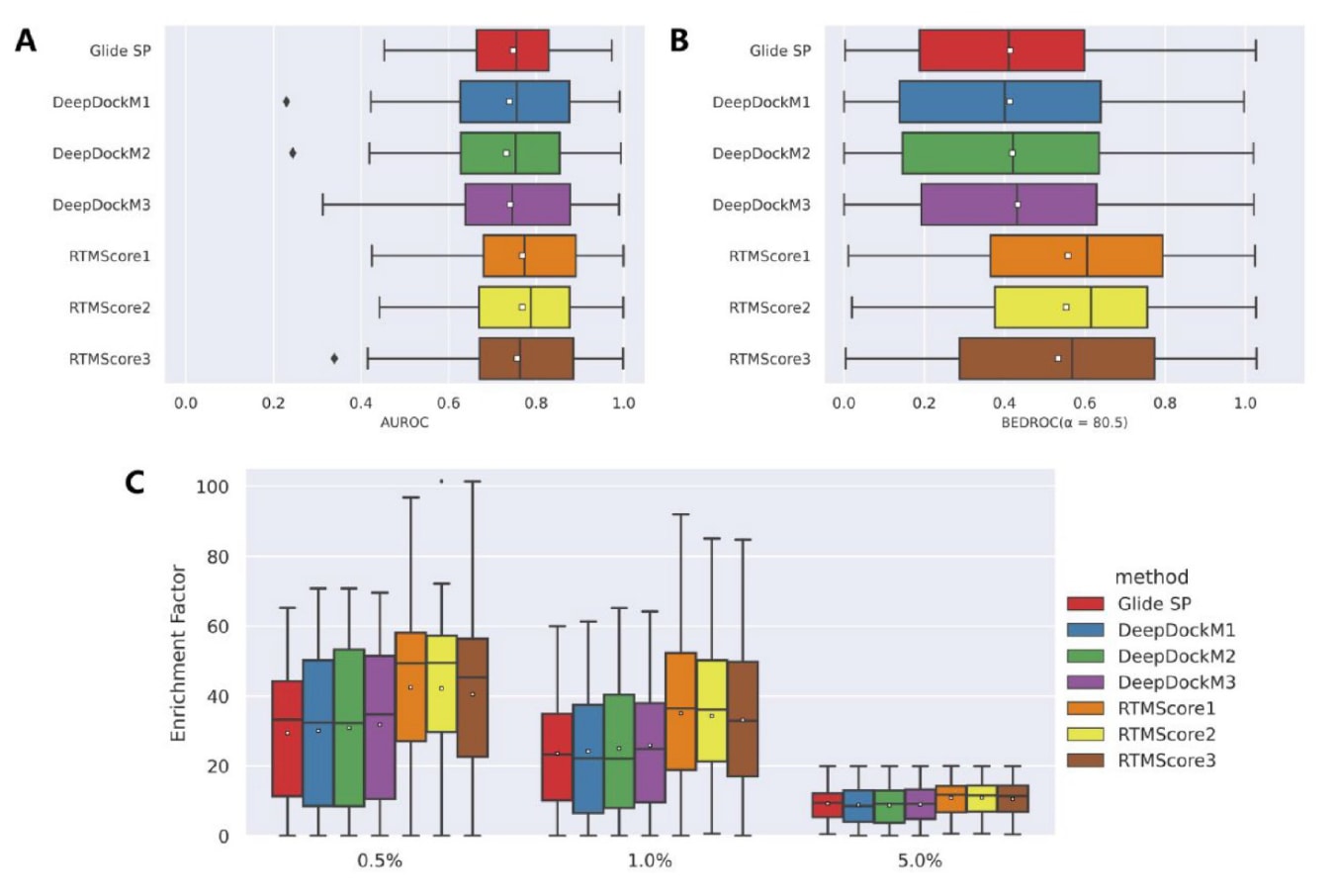
**图6|展示了在DUD-E数据集上,各类打分函数的筛选能力。**其中(A)为AUROC,(B)为BEDROC(α=80.5),(C)为不同阈值(0.5%、1.0%、5.0%)下的富集因子,均基于Glide SP生成的对接姿势进行评估。箱线图中的白色方块表示各统计量的平均值。
表6|DUD-E数据集上各类打分函数的筛选能力
2.4 RTMScore对蛋白质旋转不敏感
为检验方法是否受蛋白质旋转影响,随机选取CASF测试集中的两个复合物(1uto与4f9w),并分别围绕X轴、Y轴与Z轴以30°为步长进行旋转,旋转中心设在原点。结构旋转通过Schrödinger 2022的Python API编写脚本完成。图8显示,DeepDockM的预测评分在旋转过程中出现一定波动,而RTMScore的评分保持不变。这一现象符合预期,因为DeepDockM中的蛋白图使用的是相对笛卡尔坐标作为边特征,容易受到坐标变换的影响;而该研究方法的初始空间表征仅依赖于不受旋转影响的距离与二面角。评分的稳定性表明,方法在蛋白质坐标变化下仍能保持优异表现,这也可视为相较DeepDock的另一项优势。
**图7|展示了在DUD-E数据集中,各类蛋白家族对应的打分函数筛选能力。**其中(A)为AUROC,(B)为BEDROC(α=80.5),(C)为EF1%,(D)为EF5%,均基于Glide SP生成的对接姿势进行评估。箱线图中的白色方块表示各统计量的平均值。由于同工酶、连接酶与other类别仅包含一个靶点,因此未在图中展示。
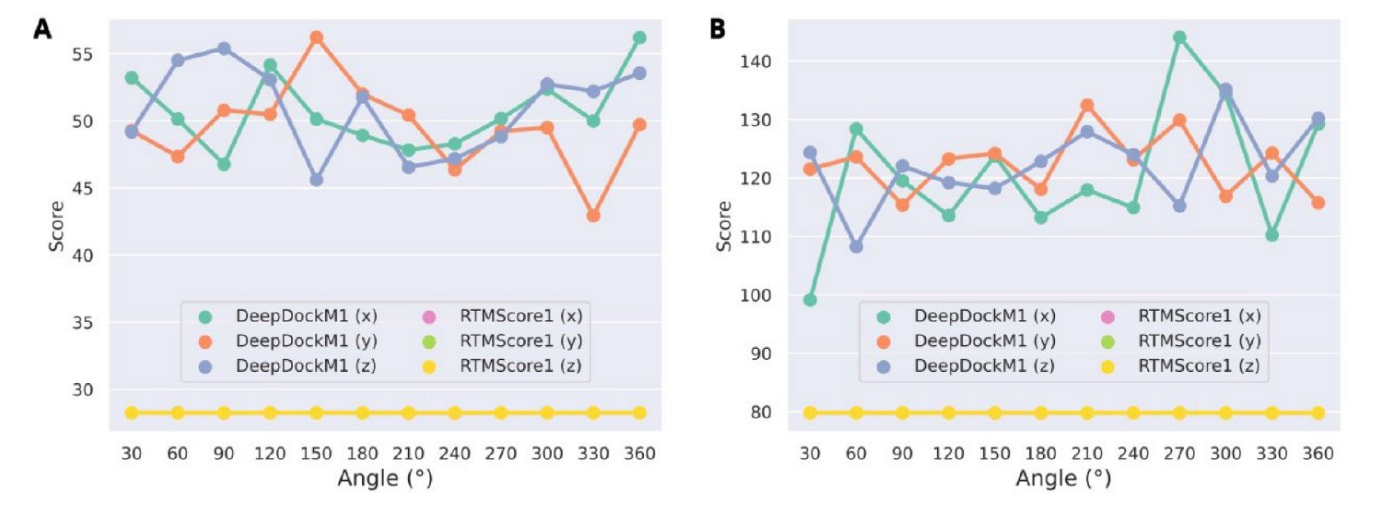
图8|展示了(A) 1uto与(B) 4f9w复合物预测评分的波动情况。 x、y与z分别表示复合物围绕X轴、Y轴与Z轴以30°为步长、以原点为中心进行旋转后的结果。
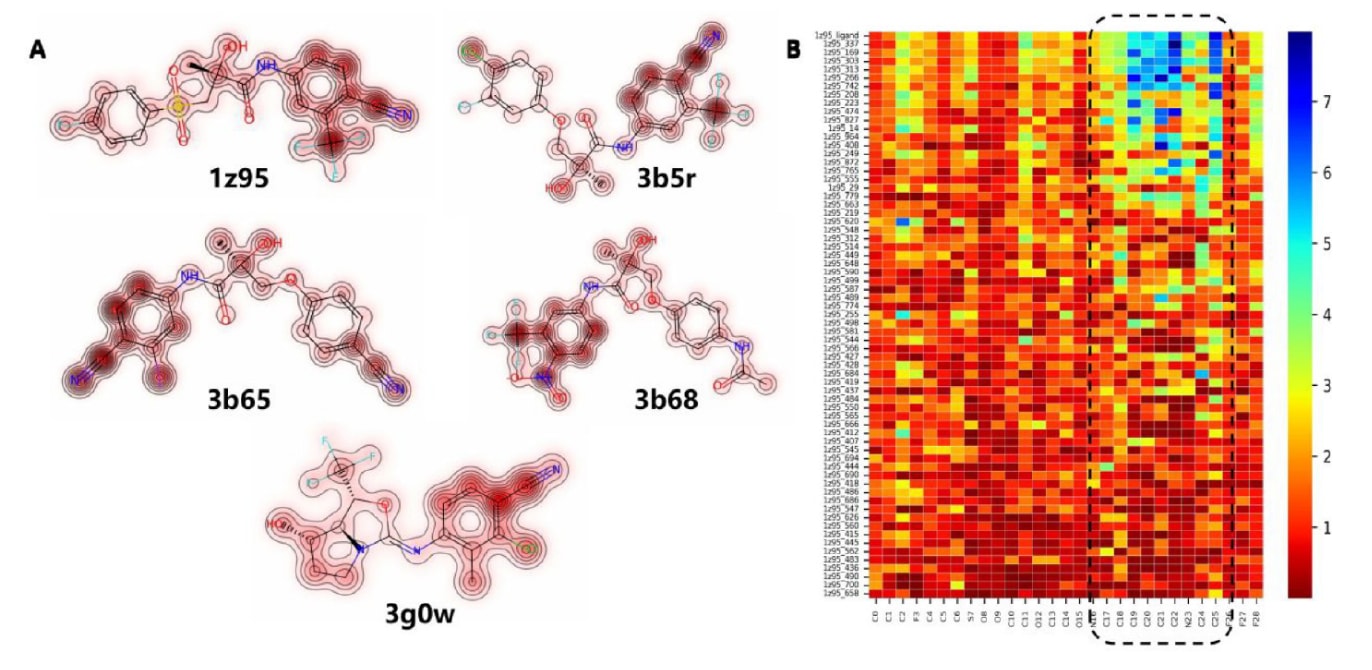
图9|展示了RTMScore在原子层面的分解结果。 (A)显示了CASF-2016测试集中雄激素受体(AR)的五个共晶配体的原子贡献分布,颜色越深代表得分越高。(B)展示了AR代表性配体(1z95)的多个对接姿势的原子贡献情况,其中红色表示较低得分,蓝色表示较高得分。X轴表示1z95配体中的各个原子,Y轴表示不同姿势,各姿势按照相对于天然姿势的RMSD由小到大排序。
2.5 RTMScore能够在原子或残基层面提供额外信息。
由于RTMScore将所有独立的残基–原子距离似然值以加和方式整合为最终统计势能,因此可轻松分解得到每个配体原子或每个蛋白口袋残基的贡献分量。尽管该评分难以反映复合物的真实结合亲和力,但能够在很大程度上体现形成的三维结合构象的稳定性。
以雄激素受体(AR)为例说明评分在原子与残基层面的表达方式。图9A展示了CASF基准中AR的五个配体,其中颜色越深、等高线越密的原子对总分贡献越大。可以观察到,4-氰基-3-三氟甲基(或卤代)苯基片段的原子普遍具有更高得分,提示该区域在与靶点的结合中更为关键。实际上,这一片段已广泛应用于已批准的AR拮抗剂如比卡鲁胺与恩扎鲁胺中,并被视为此类化合物的核心药效团。
图9B展示了1z95在CASF对接集中各对接姿势的原子贡献分布,其中4-氰基-3-三氟甲基苯基区域得分越高的姿势往往越接近天然结合姿势,进一步验证了该区域在形成合理结合方式中的重要性。
同样可以从残基层面解释模型,如图10A所示。促进配体结合的关键残基(如LEU704、MET742、MET745与MET764)被赋予更高权重,而这些残基层面得分较高的姿势通常在空间上更接近天然构象。图10B给出了1z95的天然结合姿势,可以看到这四个残基恰好环绕着配体的4-氰基-3-三氟甲基苯基片段,这也部分解释了其重要性。图10C示例了一个典型错误姿势,其4-氰基-3-三氟甲基苯基区域远离上述四个残基,因此总体得分较低。
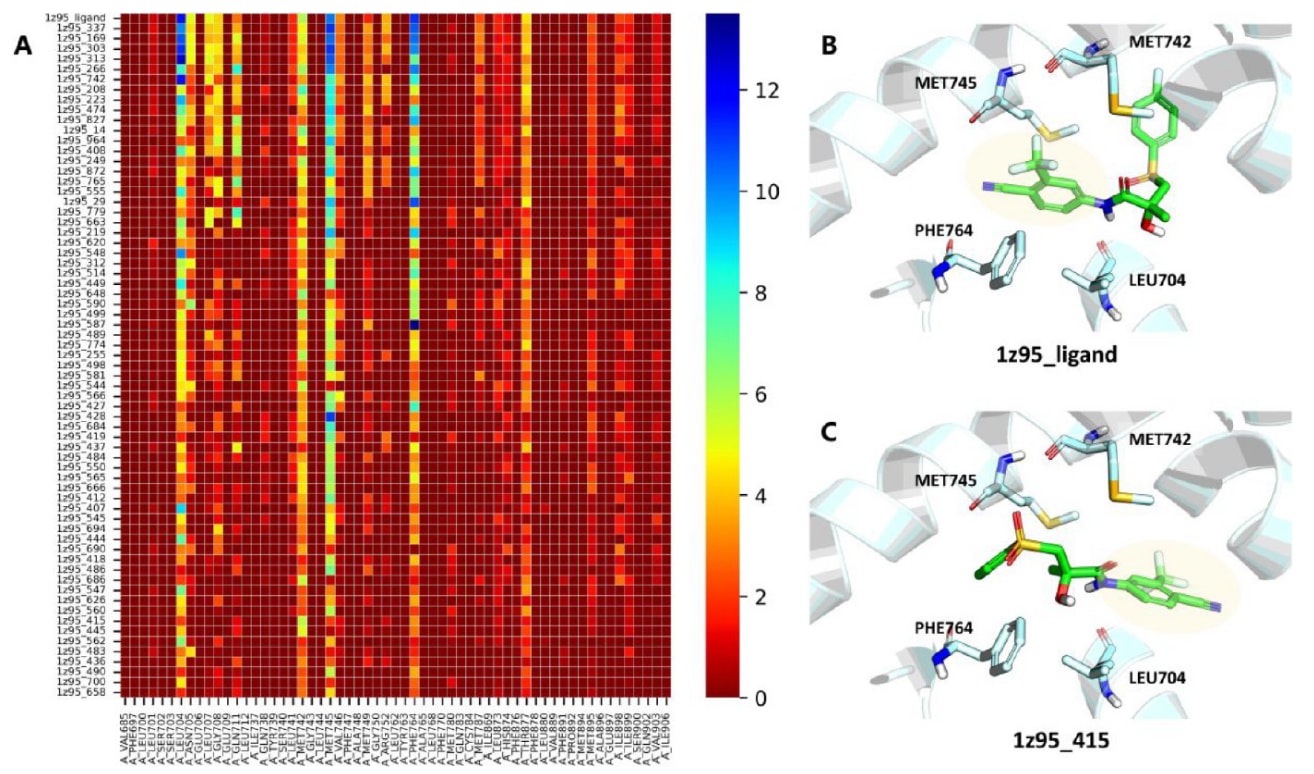
图10|展示了RTMScore在残基层面的分解结果。 (A)为雄激素受体(AR)代表性配体(1z95)的多个对接姿势的残基贡献分布,红色表示较低得分,蓝色表示较高得分。X轴为蛋白结合口袋中的各个残基,Y轴为不同姿势,各姿势按照相对于天然姿势的RMSD由小到大排序。(B)为1z95的共晶配体(1z95_ligand)的天然结合姿势。(C)为1z95的一个典型错误结合姿势(1z95_415)。
3 总结
该研究提出了一种基于残基–原子距离似然的打分函数RTMScore,用于蛋白质–配体结合姿势预测。该方法继承了DeepDock的整体架构,包括用于获取蛋白与配体节点表征的特征提取模块、节点特征拼接模块以及用于学习每对配体–蛋白节点距离概率分布的混合密度网络,同时引入了针对蛋白口袋的残基级图表示策略,并采用多层图Transformer进一步提取蛋白与配体的特征。这些改进显著提升了模型在结合姿势预测与虚拟筛选任务中的准确率与泛化能力。
此外,残基级图表示不仅支持传统的原子层面解释,还能够在残基层面对评分进行分解,从而增强方法的可解释性。凭借稳健表现与更广泛的适用范围,RTMScore在基于结构的药物设计中展现出良好前景。一方面,可与主流对接程序直接结合,用作结合姿势预测或虚拟筛选的重评分工具,也可像Gnina一样嵌入现有对接工具(如AutoDock Vina)以发展为新的对接程序;另一方面,还能够与主流分子生成算法耦合,用于开发新的去 novo 分子设计流程,这将是未来值得探索的方向。