Nature Medicine 2024 | TxGNN: 面向临床医生的药物再利用基础模型
今天介绍的是发表在 Nature Medicine 上的TxGNN工作,该研究提出了一种面向临床医生的药物再利用基础模型,试图系统性解决大量疾病缺乏有效治疗方案这一长期存在的医学难题。作者从真实临床需求出发,将药物再利用建模为零样本预测问题,使模型能够在几乎没有既有药物或分子机制信息的情况下,为疾病筛选潜在治疗候选物。TxGNN基于大规模医学知识图谱,统一刻画疾病与药物之间的复杂关系,并通过图神经网络与度量学习在不同疾病之间迁移医学知识,覆盖17080种疾病和近8000种药物。与以往方法不同,该模型不仅能够给出预测结果,还提供多跳、可解释的推理路径,帮助临床医生理解预测背后的生物学依据。研究在严格的零样本评估、真实电子病历数据以及人工专家评测中均显示出良好的临床相关性,展示了基础模型和可解释人工智能在推动药物再利用与精准医疗中的重要潜力。

获取详情及资源:
0 摘要
如果能够预测所有药物对所有疾病的疗效,就可以选择副作用更少的药物,设计针对疾病通路中多个作用点的更有效治疗方案,并系统性地将现有药物重新用于新的治疗用途。随着技术进步,通过对医学知识图谱的系统分析,现在已经可以将药物的作用前瞻性地匹配到新的适应症。这类策略通过分析药物对细胞信号传导、基因表达以及疾病表型的影响来识别潜在的治疗候选物。机器学习已被用于分析高通量的分子相互作用网络,从而揭示疾病中受到扰动的遗传结构,并辅助设计针对这些结构的治疗方案。为了给出治疗预测,基于大型医学知识图谱优化的几何深度学习模型,可以依据疾病中被扰动的网络,将疾病特征与潜在治疗候选物进行匹配。尽管计算方法已经为复杂疾病识别出了一些有前景的药物再利用候选物,但仍然存在两个关键挑战,若能解决将有助于提升再利用预测的临床相关性。首先,这些方法通常假设需要为已经存在药物的疾病进行治疗预测。虽然这一假设对部分疾病成立,但仍有大量疾病不满足这一前提。在该研究考察的17080种疾病中,92%并不存在任何适应症。此外,大约95%的罕见病没有获得FDA批准的药物,多达85%的罕见病甚至连一种在治疗、诊断或预防方面显示潜力的药物都尚未开发出来。这种缺乏治疗选择的疾病长尾问题仍然十分突出。
1 引言
目前迫切需要为许多尚无有效治疗手段的疾病开发新的疗法。在全球已知的7000多种罕见病中,只有约5%–7%拥有获得美国食品药品监督管理局批准的药物。通过药物再利用挖掘新的治疗适应症,充分发挥现有疗法的潜力,可以在一定程度上缓解全球疾病负担。药物再利用依托已获批药物已有的安全性和有效性数据,相比从零开始研发新药,能够更快实现临床转化并显著降低研发成本。其基本假设在于,药物往往具有超出其直接靶点作用机制之外的多效性。大约30%的FDA批准药物在上市后至少获得过一个新的适应症,且不少药物在多年间累积了十余个适应症。然而,大多数药物再利用的成功案例仍源于偶然发现,例如临床医生在超说明书用药过程中观察到的效果,或患者自身用药经验中的意外发现。
如果能够系统性地预测所有药物对所有疾病的疗效,就可以筛选出副作用更少的药物,设计针对疾病通路多个关键节点的更有效治疗方案,并有序地将现有药物用于新的治疗场景。得益于技术进步,通过对医学知识图谱的系统分析,药物作用已经可以前瞻性地与新的适应症进行匹配。这类方法基于药物对细胞信号传导、基因表达以及疾病表型的影响来识别潜在治疗候选物。机器学习也被广泛用于分析高通量分子相互作用网络,从而揭示疾病中受到扰动的遗传结构,并辅助设计针对这些结构的治疗策略。进一步地,基于大型医学知识图谱优化的几何深度学习模型,可以依据疾病中被扰动的网络特征,将疾病表征与潜在治疗候选物进行匹配。
尽管计算方法已经为多种复杂疾病识别出有前景的药物再利用候选物,但仍存在两个关键挑战,限制了这些预测在临床中的相关性。首先,现有方法通常假设目标疾病已经存在已知药物。虽然部分疾病符合这一假设,但大量疾病并不满足这一前提。在该研究考察的17080种疾病中,92%没有任何已知适应症。此外,约95%的罕见病没有FDA批准的药物,多达85%的罕见病甚至尚未开发出任何在治疗、诊断或预防方面显示潜力的药物。这类缺乏疗法且分子机制认识有限的疾病长尾现象,对药物再利用模型构成了严峻挑战。其次,再利用得到的适应症往往与药物最初研究的适应症并不相关。例如,沙利度胺最初用于缓解妊娠期晨吐,随后在1964年被重新用于治疗麻风病相关的自身免疫并发症,并在2006年再次被用于多发性骨髓瘤治疗。这两类问题统称为零样本药物再利用问题。要在临床上真正发挥价值,机器学习模型必须具备进行零样本预测的能力,即能够将治疗预测扩展到分子机制认识不完整、甚至完全没有FDA批准药物的疾病上。然而,现有模型在面对数据稀疏且没有已知疗法的疾病时,识别治疗候选物的能力会显著下降。
在该研究中,提出了TxGNN,一种面向多疾病零样本药物再利用的图基础模型,可在包括无治疗方案疾病在内的17080种疾病中预测药物再利用候选物。与为每种疾病单独训练模型不同,TxGNN作为单一的预训练基础模型,能够在多种疾病之间自适应迁移。TxGNN基于一个整合了数十年生物医学研究成果的医学知识图谱进行训练,利用图神经网络将药物和疾病嵌入到潜在表示空间中,使其几何结构反映知识图谱中的关系。为实现零样本治疗预测,TxGNN引入度量学习模块,将可治疗疾病中的知识迁移到尚无疗法的疾病上。模型训练完成后,无需额外参数或微调即可对新疾病进行零样本推断。为提升预测结果的可解释性,还开发了TxGNN Explainer模块,用于展示构成预测依据的多跳可解释路径。TxGNN的预测结果与解释已公开提供。人工评估结果显示,其解释在准确性、可信度、实用性和时间效率等多个方面均表现出较好的效果,且不少预测与大型医疗系统中临床医生的超说明书用药实践相一致,其预测逻辑也与医学推理相符。
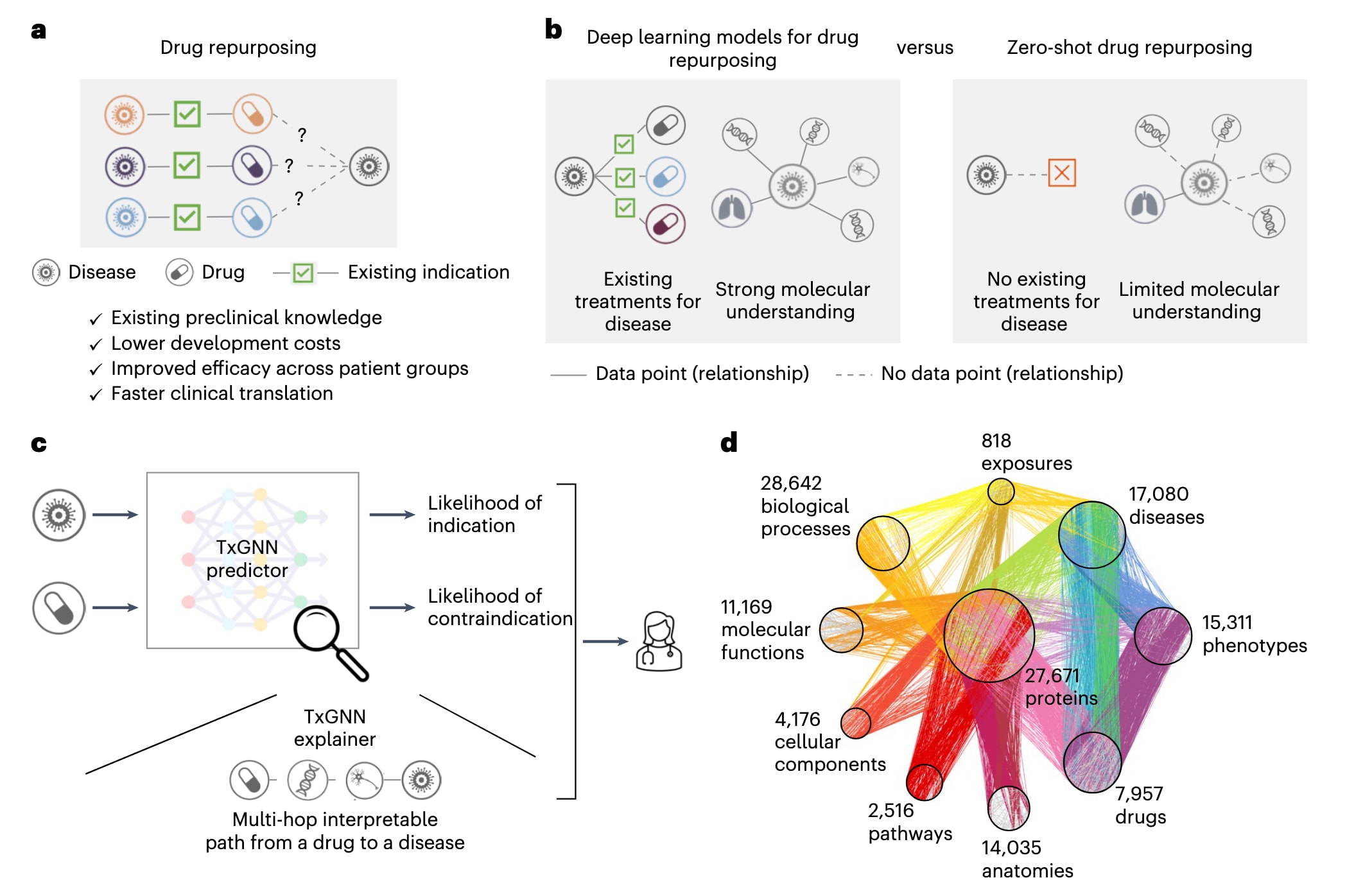
图 1 | TxGNN是一种用于药物再利用的图基础模型,旨在为治疗选择有限且分子数据不足的疾病识别候选药物。 a, 药物再利用通过为已有药物探索新的治疗用途来治疗疾病,利用既有的安全性和有效性数据,可以显著降低研发成本并缩短将挽救生命的治疗手段推向临床的时间。b, 传统计算药物再利用主要针对已有治疗方案且分子机制较为清楚的疾病展开,然而大量疾病既缺乏有效治疗,也缺少对其致病机制的完整认识,这些内在限制对人工智能模型提出了挑战。TxGNN通过将药物再利用表述为零样本预测问题来应对这一挑战。c, TxGNN提出了一套用于零样本药物再利用的人工智能框架,能够生成具有实际指导意义的预测结果。其几何深度学习模型整合了规模庞大且内容全面的生物医学知识图谱,用于准确预测任意疾病–药物组合的适应症或禁忌症概率。同时,TxGNN还能生成可解释的多跳路径,帮助人类理解预测结果如何基于医学知识得出。d, TxGNN模型基于一个医学知识图谱进行训练,该图谱覆盖了17080种疾病的疾病机制以及7957种药物的作用机制。
2 结果
2.1 TxGNN零样本药物再利用模型概述
零样本药物再利用旨在为治疗选择有限或完全缺乏治疗方案的疾病预测潜在的治疗候选物。如图1b所示,该问题在数学上可表述为:模型以一个待查询的药物–疾病对作为输入,并输出该药物作用于该疾病的可能性。用于评估模型的金标准标签来源于此前构建的医学知识图谱,如图1d及补充表4和5所示,其中包含9388条适应症关系和30675条禁忌症关系。该医学知识图谱覆盖了17080种疾病,其中92%没有FDA批准的药物,涵盖了大量罕见病以及机制尚不清楚的复杂疾病。同时,知识图谱还包含7957种潜在的药物再利用候选物,既包括已获FDA批准的药物,也包括正在临床试验中研究的实验性药物。
用于零样本药物再利用的TxGNN模型基于这样一个原则:有效药物要么直接作用于疾病中被扰动的网络,要么通过与疾病相关的网络间接传递治疗效应。TxGNN由两个模块组成:TxGNN Predictor模块用于预测药物的适应症和禁忌症,TxGNN Explainer模块用于寻找连接查询药物与查询疾病的可解释多跳知识路径,如图1c所示。TxGNN Predictor模块由一个在医学知识图谱关系上优化的图神经网络构成。通过大规模的自监督预训练,该图神经网络为知识图谱中的所有概念学习到具有语义意义的表示。随后,该预训练模型通过微调适配治疗预测任务,在无需或仅需极少额外训练的情况下,实现跨多种疾病的药物适应症和禁忌症预测。
为实现零样本预测,TxGNN进一步引入了度量学习组件,基于疾病可能共享遗传和基因组相关网络这一认识,使模型能够将已充分注释疾病中的医学知识迁移到治疗选择有限的疾病上,从而提升预测性能,如图2a及补充图1所示。具体而言,模型根据每种疾病在知识图谱中的邻居节点以及其局部疾病相关网络的拓扑结构,为每个疾病构建一个疾病特征向量。疾病之间的相似性通过其特征向量的归一化点积进行度量。由于大多数疾病并不共享相同的病理基础,其相似性得分通常较低,而相对较高的疾病相似性得分大于0.2则提示其可能具有相似的致病机制,如图2b所示。在针对某一特定疾病进行预测时,TxGNN会检索与之相似的疾病,为这些疾病生成嵌入表示,并根据它们与目标疾病的相似度进行自适应聚合。聚合后的输出嵌入综合了来自相似疾病的知识,并与目标疾病自身的表示相融合。从几何机器学习的角度看,这一步可以理解为一种图重连技术,如补充图3所示。TxGNN在统一的潜在表示空间中处理不同治疗任务,例如适应症和禁忌症预测,并基于预测的可能性得分对药物进行排序,为给定疾病提供一个优先级明确的药物再利用候选列表。
尽管TxGNN Predictor能够给出药物再利用候选物的可能性得分,但仅有数值预测并不足以支撑可信的模型应用。医学专家通常需要理解预测背后的推理过程,以验证模型假设并深入认识潜在的治疗机制。为此,TxGNN Explainer通过解析医学知识图谱,提取并简洁地呈现相关医学知识。TxGNN采用了一种名为GraphMask的自解释方法。GraphMask生成一个稀疏但足以支撑预测的子图,其中包含被模型认为对预测至关重要的医学概念。TxGNN为知识图谱中的每一条边生成一个介于0到1之间的重要性得分,其中1表示该边对预测至关重要,0表示与预测无关。模型通过多跳路径将药物与疾病联系起来,这些路径共同构成TxGNN的预测依据。TxGNN Explainer结合药物–疾病子图与边的重要性得分,生成连接预测药物与疾病的多跳可解释推理路径。人工评估研究表明,这种细粒度的解释方式与医学专家的直觉高度一致。基于TxGNN的预测结果和多跳可解释路径,还开发了一种以人为中心的交互工具。在多种设计方案中,最终选择了基于路径的推理展示方式,因为人工评估结果显示,该设计能够显著提升临床医生的理解程度和使用满意度。
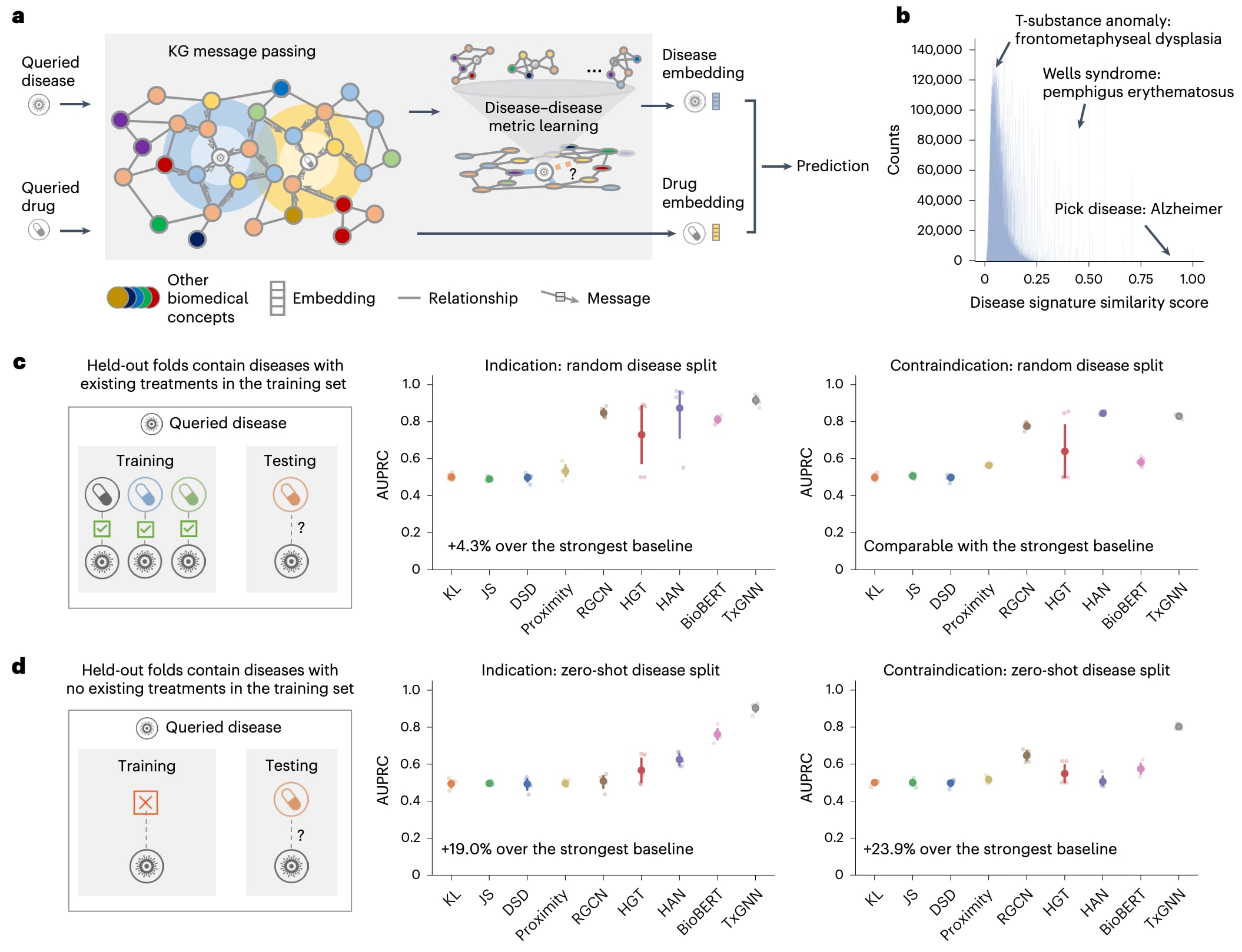
图 2 | TxGNN能够准确预测药物的适应症和禁忌症。 a, TxGNN是一种深度学习模型,能够在大规模知识图谱上进行推理,从而预测药物与疾病之间的关系。在零样本再利用场景中,被查询疾病仅具有有限的适应症和机制信息。该方法的核心思想源于生物系统的高度互联性,不同疾病尽管表型各异,但往往在底层机制上存在部分相似性并共享多种生物学通路。基于这一认识,引入了疾病池化模块,利用网络医学原理识别机制相似的疾病,并借助这些疾病的信息来增强对目标疾病的刻画,从而显著提升零样本条件下再利用候选物的优先级排序效果。b, TxGNN的疾病相似性评分为疾病之间关系提供了一种细致且具有生物学意义的度量,使模型能够发现相似疾病,并为缺乏治疗信息的目标疾病补充和丰富其机制理解。c, 传统基于人工智能的再利用评估通常在训练阶段已经接触过其他获批药物的疾病上评估适应症预测性能,在这一设置下,TxGNN与现有方法均表现出良好的性能。d, 为提供更加真实的评估,引入了一种新的零样本再利用评估设置,即在训练阶段没有任何获批药物的疾病上对模型进行测试。在这一更具挑战性的场景中,基线方法的性能出现了明显下降,而TxGNN则始终保持稳健表现,在适应症预测上相较最佳基线最高提升19%,在禁忌症预测上最高提升23.9%。这些结果凸显了TxGNN在面对缺乏治疗选择的疾病时所具备的推理能力。对于c和d,评估均采用AUPRC指标,并在五次随机数据划分下进行(n = 5),结果展示为平均性能,误差条表示95%置信区间。
2.2 治疗匹配与零样本药物再利用
在多种留出数据集上评估了模型在药物再利用任务中的性能。留出数据集通过从知识图谱中抽样疾病构建,这些疾病在训练阶段被刻意排除,在测试阶段用于评估模型对未见疾病的泛化能力。这些留出疾病要么随机选择,符合标准评估策略,要么专门用于评估零样本预测能力。该研究同时采用了这两类留出数据集。TxGNN与八种方法在治疗用途预测方面进行了比较,这些方法包括网络医学中的统计技术,如Kullback–Leibler散度和Jensen–Shannon散度,基于图论的网络邻近方法,扩散状态距离方法,以及多种先进的图神经网络模型,包括关系图卷积网络、异构图Transformer和异构注意力网络,此外还包括一种自然语言处理模型BioBERT。
首先采用了文献中常见的标准基准评估策略,即随机打乱药物–疾病治疗对,并将其中一部分作为留出测试集,如图2c所示。在这种设置下,作为留出测试的疾病在训练数据中仍然具有部分药物适应症和禁忌症信息,因此模型的泛化目标是为已有部分药物的疾病识别新的治疗候选物。该评估方式与多数已有研究保持一致。评估指标选用精确率–召回率曲线下面积AUPRC,用于衡量模型在不同阈值下的精度与召回权衡。在这一设置中,实验结果显示八种现有方法中有三种达到了AUPRC大于0.80,其中HAN表现最佳,AUPRC为0.873。TxGNN在该设置下与这些方法表现相当,在适应症预测任务中,TxGNN的AUPRC达到0.913,相较HAN提升了4.3%。这些结果表明,机器学习模型能够为已有FDA批准药物的疾病识别出更多潜在候选药物。然而,也有研究指出,这类模型往往是通过检索与已有治疗相似的药物来进行预测,这意味着标准评估策略并不适合用于评估完全没有FDA批准药物的疾病。
基于这一局限性,进一步在零样本药物再利用场景下评估模型性能。具体做法是随机留出一组疾病,并将与这些疾病相关的所有药物一并移至测试集,如图2d所示。从生物学角度来看,这要求模型在缺乏任何已知治疗信息的情况下预测治疗候选物,即无法依赖药物相似性信息。在这一更具挑战性的场景中,TxGNN相较所有现有方法均表现出显著优势,在适应症预测上较次优方法提升了19.0%的AUPRC,在禁忌症预测上提升了23.9%。尽管传统方法在常规评估中表现尚可,但在这种困难设置下往往性能大幅下降,而TxGNN是唯一在所有评估设置中均保持稳定表现的方法。
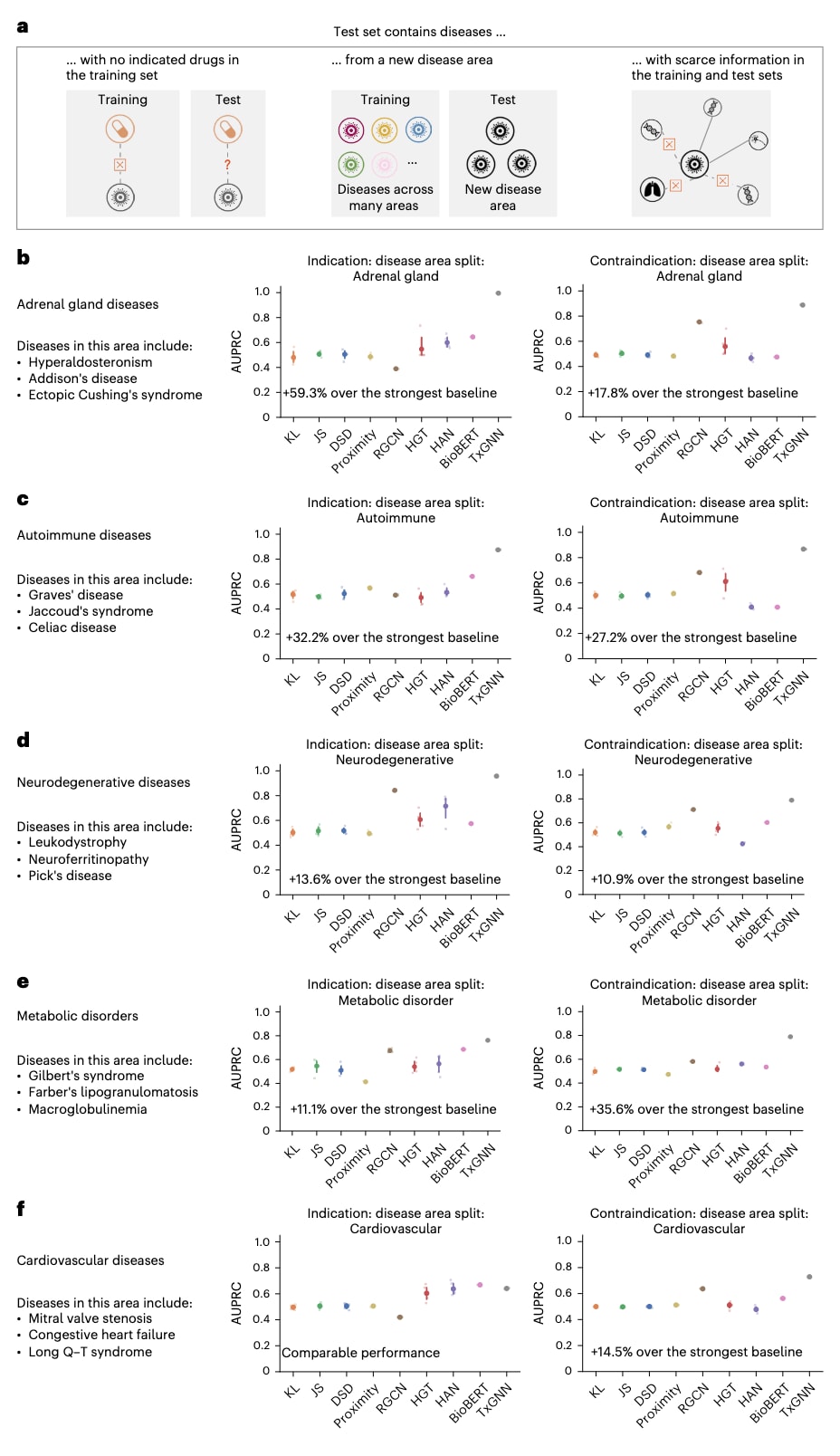
图 3 | TxGNN在分子数据规模较小且具有挑战性的疾病领域中预测药物适应症和禁忌症。 a, 构建了九个“疾病领域”数据划分,用于评估各模型在仅使用有限疾病相关分子数据且不包含任何治疗信息的情况下,对新疾病的泛化能力。留出集合中的疾病具有以下特征:(1)在训练阶段没有任何获批药物;(2)由于刻意排除了相似疾病,与训练疾病集合的重叠程度有限;(3)由于在训练集中有意移除了其生物学邻居节点,因而缺乏分子数据。这些数据划分构成了具有挑战性但贴近真实应用的评估场景,用以模拟零样本药物再利用设置。b–f, 分别展示了与肾上腺疾病(b),自身免疫性疾病(c),神经退行性疾病(d),代谢性疾病(e)以及心血管疾病(f)相关的留出评估结果。另外四个疾病领域——贫血,糖尿病,肿瘤和精神健康——的结果见补充图7,原始评分见补充表1和2。以AUPRC衡量候选药物排序性能时,TxGNN相较次优基线方法最高可提升59.3%。每种方法在每一种数据划分下均进行了五次随机划分实验(n = 5),图中展示的是平均性能,误差条表示95%置信区间。
2.4 不同疾病领域上的零样本药物再利用评估
共享致病机制的疾病往往也会共享有效药物。例如,选择性5-羟色胺再摄取抑制剂可以用于多种精神类疾病,包括重度抑郁障碍、焦虑障碍和强迫症。如果模型在训练阶段学会了某种此类药物适用于重度抑郁障碍,那么在测试阶段将其推荐用于强迫症并不困难。这种现象被称为捷径学习,是许多深度学习模型失败的根源之一。捷径决策规则在标准基准测试中往往表现良好,但在更具挑战性的情形下会失效,例如预测完全没有治疗方案的罕见病,或机制差异显著的复杂疾病亚型。
为评估模型在这些困难疾病上的表现,构建了一个更加严格的留出数据集,其中包含若干生物学上相关的疾病集合,称为疾病领域。对于每一个疾病领域,训练数据中移除了该领域内所有疾病的药物适应症和禁忌症关系,同时还移除了知识图谱中药物与其他医学概念之间的一部分关系。该数据划分用于评估模型在分子数据有限且无现有药物的疾病上的预测能力,如图3a所示。在这一设置下,测试集中疾病的邻居节点数量显著少于训练阶段,如补充图6所示。该研究共考虑了九个多样化的疾病领域留出数据集,其特征见补充表3,并按疾病领域规模递增依次包括:与糖尿病相关的疾病,如妊娠期糖尿病和脂肪萎缩性糖尿病;肾上腺疾病,包括艾迪生综合征和异位库欣综合征;自身免疫性疾病,包括乳糜泻和格雷夫斯病;贫血相关疾病,如地中海贫血和血红蛋白C病;神经退行性疾病,包括皮克病和神经铁蛋白病;精神健康障碍,包括神经性厌食症和抑郁障碍;代谢性疾病,包括巨球蛋白血症和吉尔伯特综合征;心血管疾病,包括长Q–T综合征和二尖瓣狭窄;以及肿瘤性疾病,包括神经纤维瘤和莱迪希细胞肿瘤。
在这些严格的留出数据集上对TxGNN进行了系统评估,如图3b–f及补充图7所示。结果显示,TxGNN在所有疾病领域中均一致优于现有方法。在适应症预测任务上,TxGNN在九个疾病领域中的相对AUPRC提升范围为0.5%–59.3%,平均提升25.72%;在禁忌症预测任务中,相对提升为11.8%–35.6%,平均提升18.67%。在基线方法中,BioBERT在九个疾病领域中的七个在适应症预测上表现最佳,而RGCN在九个领域中的八个在禁忌症预测上表现最佳。然而,TxGNN在所有九个疾病领域的两项任务中均超越了所有对比方法,显示出其在零样本药物再利用任务中的广泛泛化能力和高预测精度。对TxGNN Predictor潜在表示的可视化结果表明,模型能够将来自无关疾病的知识迁移到数据有限的疾病上。其他评估指标,包括AUROC和召回率,详见补充图9–11。消融实验验证了TxGNN Predictor中各个组成模块对整体性能均至关重要。进一步的压力测试表明,在不同数据划分、极少疾病连接、局部邻域遮蔽以及多种知识图谱配置条件下,TxGNN仍然能够保持较强的预测性能。
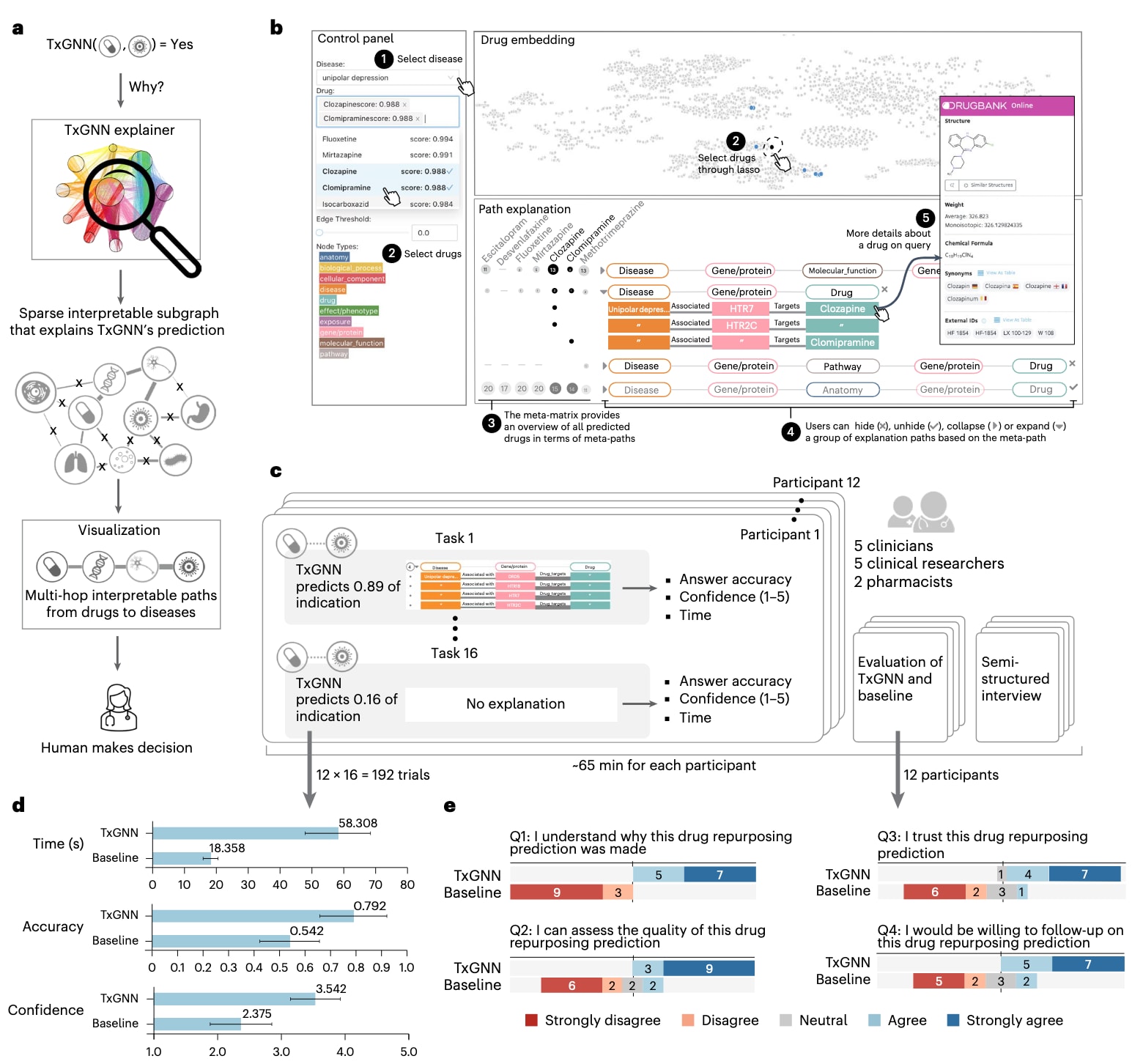
图 4 | TxGNN Explainer中多跳可解释路径的开发,可视化与评估。 a, 仅有预测结果往往不足以支撑机器学习模型的可信部署。为辅助人工专家决策,开发了TxGNN Explainer,利用图人工智能的可解释性技术揭示模型预测依据。TxGNN Explainer能够识别支撑模型预测的稀疏且可解释的子图,并针对每一个药物候选物生成一条由生物医学概念构成的多跳路径,将疾病与药物连接起来。随后,可视化模块将这些子图转化为符合人类认知方式的多跳路径展示。b, 一个交互式工具,用于帮助专家探索TxGNN的预测结果及其解释。“控制面板”允许用户选择疾病并查看排序靠前的预测结果;“边阈值”模块用于调节解释的稀疏程度,控制所显示多跳路径的密度;“药物嵌入”面板用于将选定药物在潜在空间中的位置与整个再利用候选库进行比较;“路径解释”面板则展示TxGNN治疗预测所依赖的关键生物学关系。c, 通过一项用户研究评估TxGNN解释的实用性,参与者包括5名临床医生,5名临床研究人员和2名药师。参与者被展示了16组药物–疾病对及TxGNN的预测结果,其中12条预测是正确的,并基于所提供的解释判断是否同意这些预测。d, 将TxGNN Explainer与无解释基线在用户答题准确率,任务完成时间和用户信心方面进行比较。结果基于192次试验(12名参与者×16项任务)汇总,显示在提供解释的情况下,准确率(P = 0.044),信心(P = 0.004)以及思考时间(P = 0.0013)均显著提升。误差条表示95%置信区间,中心点为平均性能,统计检验采用双侧Tukey HSD方法且未进行多重检验校正。e, 用户研究结束后收集的定性可用性问题结果。人工专家普遍认为,TxGNN提供的解释有助于评估药物再利用候选物,并且相较于仅使用预测结果,这些解释显著增强了对TxGNN预测的信任度。
2.4 以人为中心的TxGNN药物候选评估
为考察TxGNN生成的多跳可解释路径在人工专家评估中的实用性,开展了一项由临床医生和科研人员参与的初步人工研究(研究界面见补充图17)。参与者包括5名临床医生、5名临床研究人员和2名药师(7名男性、5名女性,平均年龄34.3岁,如图4c所示)。在评估药物–疾病适应症预测时,参与者被要求对TxGNN给出的16条预测进行判断,其中12条为正确预测。研究记录了每条预测的判断准确率、探索时间和信心评分,共计192次试验(16条预测×12名参与者,见补充表4和5)。整项用户研究平均耗时约65分钟,包括对TxGNN药物–疾病适应症预测的评估、可用性问卷以及半结构化访谈。
在评估药物再利用候选物时,当预测结果配有解释时,参与者的判断准确率显著提升(+46%,P = 0.0443),信心显著增强(+49%,P = 0.0041)。参与者在有解释的情况下投入了更多时间进行思考(P = 0.0014),将TxGNN的解释与自身专业知识相结合,从而做出更有信心的决策(信心提升49%,P = 0.0041)。在任务后的问卷和访谈中,参与者普遍认为使用TxGNN Explainer比基线方案更令人满意(图4e),12名参与者中有11名(91.6%)表示同意或强烈同意TxGNN提供的预测和解释具有价值。相比之下,在没有解释的情况下,有8名参与者(75.0%)表示不同意或强烈不同意依赖TxGNN的预测结果。当引入TxGNN Explainer时,参与者对TxGNN给出的正确预测表现出显著更高的信心(t(11)=3.64,P<0.01,采用双侧Tukey HSD检验)。部分参与者指出,多跳可解释路径在分析TxGNN Explainer识别的分子靶点相互作用以及评估潜在不良药物事件时具有重要帮助。
2.5 TxGNN预测依据与医学证据的一致性
进一步考察了TxGNN预测的药物及其多跳解释是否与医学推理一致,选取了三种罕见病进行分析。评估流程分为三个阶段(图5a)。首先,由人工专家使用TxGNN Predictor查询某一特定疾病的潜在再利用药物,模型给出候选药物,并提供预测置信度及其在所有候选物中的相对排序。随后,调用TxGNN Explainer解释为何该药物被认为适合再利用,模型通过多跳可解释路径展示疾病与药物之间经由中间生物学相互作用相连的推理过程。最后,收集并分析独立的医学证据,对模型的预测及解释进行验证。
首先分析了TxGNN对Kleefstra综合征的预测,该罕见病由EHMT1基因突变引起,表现为语言发育迟缓、自闭谱系障碍和儿童期肌张力低下,常伴随大脑发育不全和神经通路低活性。TxGNN Predictor将唑吡坦列为排名第一的药物再利用候选物(图5b)。起初,考虑到唑吡坦通过作用于γ-氨基丁酸A型受体(GABRG2基因)产生镇静效应,其用于发育不全的大脑似乎存在风险。然而,TxGNN Explainer指出,唑吡坦对GABRG2的作用可能降低自闭症易感性并改善前额叶皮层功能。已有研究发现,唑吡坦在某些神经系统疾病中可表现出刺激作用,能够暂时唤醒低活性的神经元,提示其在神经发育障碍中的潜在治疗价值。这种反常改善在部分严重脑损伤或神经发育障碍患者中可增强语言能力、运动功能和警觉性,已有个案报道和部分临床研究予以支持。尽管这些临床案例未被模型在训练中见到,TxGNN的预测及其解释逻辑仍与现有医学证据相一致。
随后考察了TxGNN对Ehlers–Danlos综合征的预测,该病是一种罕见的结缔组织疾病,发病率约为每10万人中1–9例,由编码胶原蛋白的基因COL1A1和COL1A2突变引起,其特征包括伤口愈合受损和异常瘢痕形成。TxGNN Predictor将维A酸类药物全反式维甲酸(常用于治疗痤疮)列为首位再利用候选物。TxGNN的预测依据显示,全反式维甲酸通过白蛋白(ALB)转运并作用于ALDH1A2,有助于减轻胶原蛋白流失和炎症(图5c),表明其预测逻辑与医学推理一致。全反式维甲酸可能通过刺激皮肤胶原生成,改善Ehlers–Danlos综合征患者的伤口愈合能力和瘢痕外观。此外,有研究报道Ehlers–Danlos综合征的某些亚型与ALB基因的致病突变相关,并与ALDH1A1存在较弱关联。TxGNN Explainer所揭示的连接全反式维甲酸与该疾病的通路与这些证据保持一致。
最后分析了一种罕见疾病,即肾源性抗利尿不当综合征,其特征是由AVPR2基因突变引起的水和钠代谢失衡。充血性心力衰竭患者同样面临液体潴留问题,该病与AVPR2和NPR1基因均存在较强关联。TxGNN Predictor将亚硝酸戊酯列为前五位候选药物之一(图5d)。TxGNN Explainer显示,肾源性抗利尿不当综合征与亚硝酸戊酯之间的关联路径涉及AVPR2、充血性心力衰竭以及NPR1。AVPR2和NPR1基因通过互补但不同的通路在体液和电解质平衡调控中发挥关键作用,其中AVPR2促进水潴留和尿液浓缩,而NPR1则促进血管扩张、降低血压并增强水排泄。增强NPR1活性有望抵消AVPR2受体功能异常导致的过度水重吸收。亚硝酸戊酯作为NPR1的作用药物,因而成为一种潜在的治疗选择,这一结论进一步验证了TxGNN解释与医学证据的一致性。

图 5 | TxGNN生成的药物再利用预测及其多跳可解释路径与医学证据高度一致。 a, 在三种罕见病上评估了TxGNN识别的药物再利用候选物是否符合既有医学推理。流程首先由TxGNN Predictor根据所查询的疾病筛选潜在可再利用药物,随后由TxGNN Explainer给出解释性路径以说明筛选依据。案例分析最终通过独立的临床知识对TxGNN的预测进行验证,展示了模型推荐结果与医学认知之间的一致性。b, 对于以发育迟缓和神经系统症状为特征的Kleefstra综合征,TxGNN预测通常作为镇静剂使用的唑吡坦为潜在再利用候选物。尽管唑吡坦在传统认知中对大脑具有抑制作用,TxGNN Explainer指出其可能增强前额叶皮层活动并改善患者的认知功能。这一看似反直觉的推荐与逐渐增多的临床证据相一致,即唑吡坦能够唤醒处于低活性状态的神经元,从而可能改善神经发育障碍患者的语言、运动能力和警觉性。c, TxGNN将全反式维甲酸识别为治疗Ehlers–Danlos综合征的首选候选物,其预测依据源于该药物与白蛋白(ALB)及ALDH1A2的相互作用,这与医学上关于Ehlers–Danlos综合征中胶原流失和炎症缓解机制的认识相符。d, TxGNN将亚硝酸戊酯识别为肾源性抗利尿不当综合征(NSIAD)的潜在治疗选择。NSIAD由AVPR2基因突变引起,导致水和钠代谢失衡。TxGNN Explainer通过分析调控电解质平衡的基因相互作用(AVPR2和NPR1),指出NSIAD与亚硝酸戊酯之间可经由充血性心力衰竭这一具有相似液体潴留特征的疾病相连。
2.6 基于电子病历的TxGNN评估
TxGNN的优异表现表明,其提出的新颖预测,即尚未获得临床批准但被TxGNN高度排序的药物,可能具有潜在的临床价值。由于这些疗法尚未被批准,缺乏可直接对照的金标准。鉴于临床中长期存在的超说明书用药实践,采用某一医疗系统电子病历中疾病–药物对的共现富集程度,作为潜在适应症的替代指标。基于西奈山医疗系统的电子病历,构建了一个包含1272085名成年患者的队列,每名患者至少具有一次药物处方和一次疾病诊断(图6a)。该队列中男性占40.1%,平均年龄为48.6岁(标准差18.6岁),人口统计学分布见图6b,c。纳入分析的疾病要求至少有一名患者被诊断,药物要求至少被10名患者处方,最终得到包含478种疾病和1290种药物的数据集(图6d)。
在这些病历数据中,通过计算某一药物用于某种疾病的优势比相对于用于其他疾病的优势比,衡量疾病–药物共现的富集程度,得到619200个药物–疾病对的log(OR)值,并进行了必要的统计校正。结果显示,FDA批准的药物–疾病对具有显著更高的log(OR)值(图6e)。禁忌症可能成为潜在混杂因素,因为不良药物事件可能增加药物–疾病对的共现频率。然而,对禁忌症的分析未发现显著共现富集,表明不良反应并非主要混杂来源。
对于478种在电子病历中表型化的疾病,TxGNN生成了药物再利用候选的排序列表。已知与疾病相关的药物被排除,其余新候选物被划分为首位、前五位、前5%以及后50%,并计算各组的平均log(OR)值(图6f)。排名第一的预测药物,其平均log(OR)比后50%预测高出107%,表明TxGNN给出的首选候选物在病历中具有显著更高的共现富集度,从而更可能对应真实适应症。随着纳入候选物比例的扩大,log(OR)逐渐增加,说明TxGNN的预测得分能够有效反映适应症的可能性。尽管整体平均log(OR)为1.09,但TxGNN预测的首位候选药物的log(OR)达到2.26,接近FDA批准适应症的平均log(OR)值2.92,提示TxGNN高排名预测中富集了大量真实存在的超说明书用药。
以威尔逊病为例,该罕见病以铜过度沉积为特征,常在儿童中引发肝硬化(图6g)。TxGNN对大多数药物给出的预测概率接近于零,仅有少数药物被认为高度可能为适应症。TxGNN将去铁胺衍生物deferasirox列为最有前景的候选药物。威尔逊病与deferasirox在电子病历中的log(OR)达到5.26,且已有文献表明其可能有效清除肝脏铁沉积。另在一项独立分析中,对知识截止日期之后新近获批的10种FDA药物进行了评估,TxGNN能够稳定地给予这些新药较高排名,并在其中两种情况下将其排入预测药物的前5%。
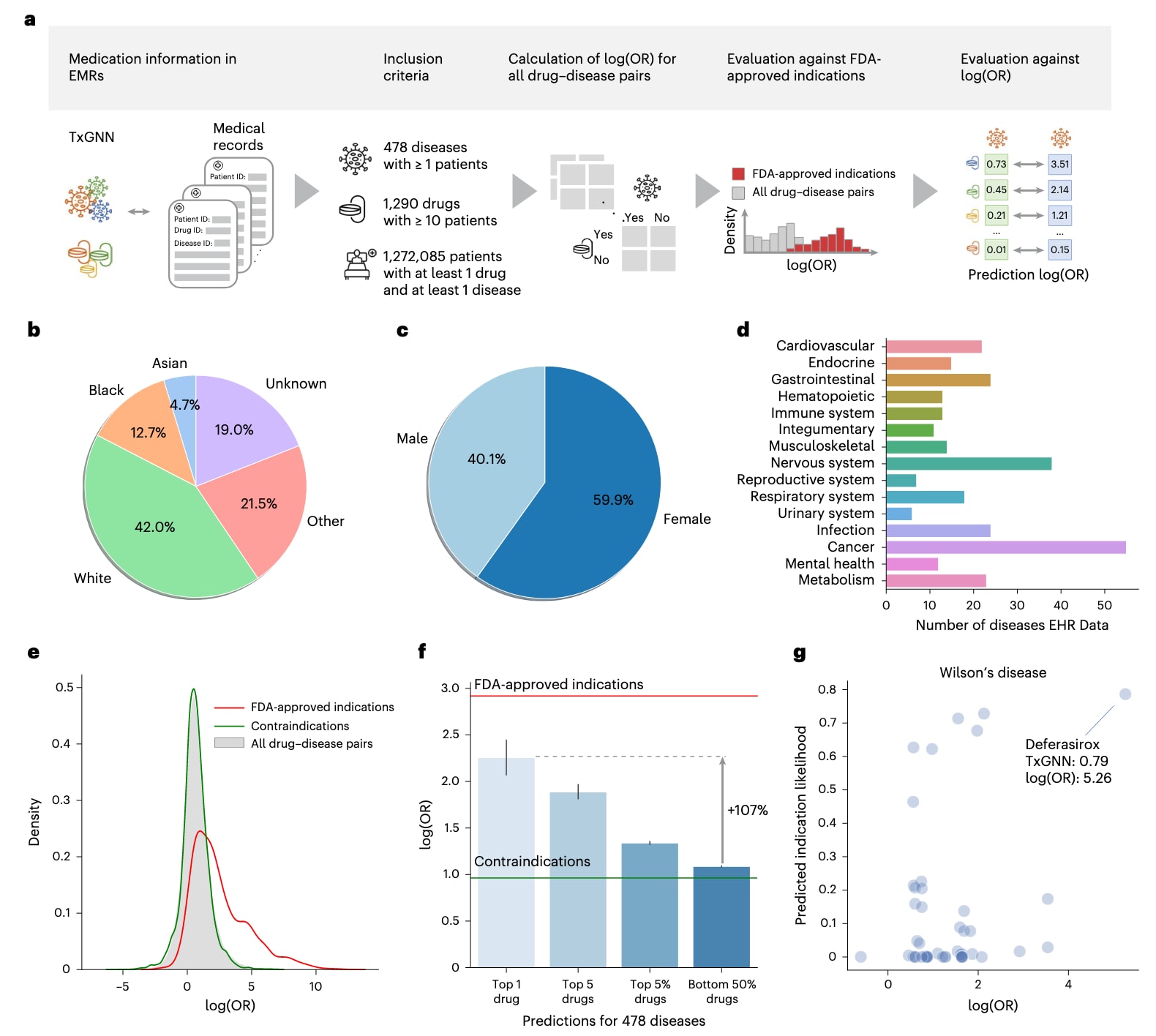
图 6 | 在大型医疗系统中评估TxGNN的预测结果。 a, 利用电子病历评估TxGNN新适应症预测的流程。首先,将TxGNN知识图谱中的药物和疾病与电子病历数据库进行匹配,构建了一个包含约127万名患者的队列,覆盖478种疾病和1290种药物。随后,计算每一对药物–疾病的log(OR),用于刻画特定药物在特定疾病中的使用倾向。通过将药物–疾病对与FDA批准的适应症进行比较,验证log(OR)作为临床用药代理指标的合理性。最后,评估TxGNN提出的新预测,检验其log(OR)值是否在医疗记录中呈现富集。b, 患者队列中的种族构成分布。c, 患者队列中的性别分布。d, 电子病历数据覆盖了多个主要疾病领域,疾病类型具有高度多样性。e, FDA批准药物对应的log(OR)值显著富集,验证了log(OR)作为临床处方代理指标的有效性,尽管大多数药物–疾病对的log(OR)值仍然较低。此外,禁忌症对应的log(OR)值与一般非适应症药物–疾病对相近,表明诸如不良药物反应等潜在混杂因素的影响较小。f, 对TxGNN提出的新适应症进行log(OR)评估。纵轴表示疾病–药物对的log(OR)值,用作临床使用的代理指标。对每种疾病,按TxGNN预测结果进行排序,并分别计算排名第一的药物(n = 470)、前五名药物(n = 2314)、前5%的药物(n = 27618)以及后50%的药物(n = 123718)的平均log(OR)值。红线表示FDA批准适应症的平均log(OR),绿线表示禁忌症的平均log(OR)。结果显示,TxGNN预测的药物与临床医生的超说明书用药决策具有一致性,误差条表示95%置信区间。g, 以威尔逊病为例,展示TxGNN预测得分与log(OR)之间的关系。图中每一个点代表一个治疗候选物,TxGNN识别出的最可能药物被特别标注,显示其对应的TxGNN得分和log(OR)值。
3 讨论
药物再利用作为一种药物发现策略,已被广泛采用以应对全新药物研发在成本、上市周期以及内在风险方面的生产力问题。尽管传统的“单一疾病–单一预测模型”方法被用于提升药物再利用的成功率,但大多数成功案例仍然源自临床或临床前体内研究中的偶然发现。基于这一现状,可以认为,通过多疾病联合预测策略,有望实现更加系统和全面的药物再利用。现有预测模型通常假设所查询的疾病或与之密切相关的疾病已经存在有效药物,这一假设忽略了大量疾病——在所分析的17080种疾病中占92%——它们既缺乏既有适应症,也缺乏已知的分子靶点相互作用。满足这些疾病的治疗需求,其中许多属于复杂疾病、被忽视疾病或罕见病,是当前临床研究中的重要优先事项。该挑战被定义为零样本药物再利用问题。
为直接应对这一问题,提出了TxGNN这一图基础模型,专门面向数据有限且治疗机会匮乏的疾病。TxGNN通过利用以疾病–治疗机制为核心的网络医学原理,在药物再利用任务上实现了领先性能。当需要为某一疾病推荐治疗候选物时,TxGNN能够识别在通路、表型和病理机制上存在共性的疾病,提取相关医学知识并将其融合到目标疾病中。通过建模疾病之间的潜在关系,TxGNN能够对训练阶段从未见过的疾病执行零样本推断,从而在治疗选择稀缺的疾病上实现有效泛化。TxGNN的整体设计不仅支持高效的零样本药物再利用,还可以扩展应用于其他场景,例如药物靶点发现和精准治疗方案选择。
TxGNN作为一个统一模型,可在17080种疾病范围内同时预测药物适应症和禁忌症,适用于跨多个治疗领域的早期药物再利用研究。研究结果表明,多疾病预测模型相比单一疾病领域的方法,能够发现更多潜在的再定位药物候选物。预测得到的药物与电子病历中的超说明书用药比例一致,并且与人工专家形成的医学共识相符。尽管这些结果提示现有药物可能具有有益的治疗潜力,但预测药物仍需经过系统而全面的筛选,以验证其安全性和有效性,并进一步明确诸如给药剂量、治疗顺序和治疗时机等关键参数。
TxGNN还能生成多跳可解释的预测依据,为药物预测结果提供合理解释。这些解释可用于分析预测药物是否可能引发额外的生物学反应,并结合模型识别的原始适应症或分子靶点相互作用进行评估。初步的人工评估结果显示,与其他解释可视化方式相比,多跳解释更有助于专家有效审查预测药物并识别潜在失效环节。这些发现进一步强调了在将机器学习模型引入药物发现流程时,同时考虑临床需求和模型可解释性的重要性。
尽管TxGNN在零样本药物再利用方面展现出良好性能,其能力仍依赖于医学知识图谱的质量。这类图谱可能需要补充更加全面的宿主–病原体相互作用信息,以支持传染病药物再利用,同时还需纳入遗传变异致病性相关信息,这对于遗传病的再利用机会识别尤为关键。医学知识图谱中潜在的数据偏倚以及信息滞后问题同样需要加以解决。应对这些问题的策略包括引入持续学习和模型编辑技术,以及在新数据出现时自动更新知识图谱的数据管理方法。另一个值得探索的方向是结合不确定性量化技术,以评估模型预测结果的可靠性。此外,将患者个体信息与医学知识图谱相结合,有望实现更加个性化的药物再利用预测。
人工评估研究仅纳入了数量有限的临床医生和科研人员(n = 12),优先选择对少量高水平专家进行深入分析,而非开展覆盖更大但专业程度可能较低人群的研究。尽管结果具有积极意义,且这一参与者规模与评估高度专业化工具的相关研究相当,但在未来,扩大样本规模的人类评估研究将有助于覆盖更广泛的专业背景,并探讨多种药物再利用应用场景。与此同时,尽管TxGNN在电子病历数据上的预测表现令人鼓舞,未被充分考虑的混杂因素和选择偏倚仍可能限制对药物富集得分的解释能力。
TxGNN的零样本药物再利用能力使其能够为治疗选择有限且信息稀缺的疾病预测潜在药物。多跳可解释的预测依据有助于实现模型的透明使用,增强信任并辅助人工专家决策。TxGNN在疾病特异性数据集匮乏、制约药物研发进程的情况下,显著简化了药物再利用预测流程。以TxGNN为代表的多疾病模型凸显了人工智能在推动新型治疗手段开发方面的潜力。