NMI 2025 | 评估深度学习在蛋白质-配体对接中的潜力
今天介绍的是一项发表在 Nature Machine Intelligence 上的研究,系统评估了深度学习方法在蛋白质-配体对接与结构预测任务中的实际能力与局限性.该研究提出了统一基准PoseBench,在更贴近真实应用场景的条件下,比较了多种主流深度学习对接与共折叠方法,以及传统对接算法在主配体与多配体体系中的表现.结果显示,尽管深度学习共折叠方法整体优于传统方法,但在面对新型结合口袋、多配体体系以及缺乏进化信息的目标时仍然存在明显挑战.该工作为理解当前方法的泛化边界提供了清晰证据,也为后续蛋白质-配体建模方法的发展指明了方向.

获取详情及资源:
- 📄 论文: https://doi.org/10.1038/s42256-025-01160-1
- 💻 代码: https://github.com/BioinfoMachineLearning/PoseBench
0 摘要
配体结合对蛋白质结构及其体内功能的影响,对现代生物医学研究和生物技术发展,尤其是药物发现等工作具有重要意义.尽管近年来已经提出了多种用于蛋白质-配体对接的深度学习方法和基准,但此前尚未有研究在更具普适性的应用背景下系统考察最新对接方法和结构预测方法的行为,这些背景包括:使用预测得到的(游离态)蛋白质结构进行对接,例如用于新蛋白的适用性评估;在同一目标蛋白上同时结合多个(辅因子)配体,例如用于酶设计;以及在完全未知结合口袋的情况下进行预测,例如评估对未知口袋的泛化能力.为了更深入地理解对接方法在真实应用场景中的实际效用,该工作提出了PoseBench,一个面向广泛应用场景的综合性蛋白质-配体对接基准.PoseBench使研究人员能够利用主配体和多配体两类基准数据集,对用于游离态到结合态蛋白质-配体对接以及蛋白质-配体结构预测的深度学习方法进行严格而系统的评估,其中多配体数据集是首次引入深度学习社区的.基于PoseBench的实证结果表明:深度学习共折叠方法整体上优于可比的传统对接方法和深度学习对接基线算法,但诸如AlphaFold 3等常用方法在面对具有新型蛋白质-配体结合构象的预测目标时仍然存在挑战;部分深度学习共折叠方法对输入的多序列比对高度敏感,而另一些方法则不具备这种敏感性;此外,在预测新的或多配体蛋白质靶标时,深度学习方法在结构准确性与化学特异性之间仍难以取得理想的平衡.
1 引言
药物发现领域长期面临一项关键挑战:确定配体分子与蛋白质及其他关键生物大分子形成复合物时的结构.准确解析此类复合结构,尤其是多配体结构,能够为理解体内众多蛋白质复合物的结合动力学和功能特性,从而评估其药用潜力,提供更深入的认识.因此,近年来在蛋白质-配体结构解析方面投入了大量资源,用于开发新的实验与计算技术.在过去十年中,用于结构预测的机器学习方法已成为大规模现代结构解析中不可或缺的组成部分,其中AlphaFold 2在蛋白质结构预测方面是一个标志性成果.随着研究逐步探索是否能够利用机器学习,尤其是深度学习技术,对蛋白质与其他类型分子形成的复合物进行可靠建模,一系列相关工作已显示出这些方法在蛋白质-配体结构解析方面的巨大潜力.然而,最新的基于对接或共折叠的深度学习方法在多大程度上能够泛化到新的或不常见的蛋白质-配体相互作用口袋,以及涉及多个相互作用配体的情形,例如可能改变多种酶化学功能的情况,仍有待验证;同时,这些方法是否能够真实刻画晶体结构中天然存在的氨基酸特异性蛋白质-配体相互作用类型,也尚不明确.为弥补这一认知空白,该工作提出了一个统一的蛋白质-配体对接与结构预测基准,系统评估了多种近期基于深度学习的方法,包括DiffDock-L、DynamicBind、NeuralPLexer、RoseTTAFold-All-Atom、Chai-1、Boltz-1和AlphaFold 3,以及传统算法P2Rank结合AutoDock Vina,在主配体和多配体对接任务中的表现.结果表明,深度学习共折叠方法整体上优于传统算法,但在面对新的或不常见的预测目标时仍然存在显著挑战.不同于若干近期依赖晶体蛋白结构进行蛋白质-配体对接的研究,该研究所报告的对接基准结果均基于标准化的输入多序列比对以及高精度、类游离态的蛋白质结构,即由AlphaFold 3预测得到的结构,且不预先指定已知的结合口袋,这一设置显著增强了研究结论的普适性.新提出的PoseBench基准为未来实现更准确、更具泛化能力的生物大分子结构预测提供了具体启示,包括深度学习方法在构象预测过程中难以同时兼顾天然蛋白质-配体相互作用指纹的真实建模与整体结构准确性,以及部分深度学习共折叠方法,如AlphaFold 3,相比Boltz-1和Chai-1,对输入多序列比对的依赖程度更高.此外,基准结果还强调了在评估未来深度学习方法时引入具有挑战性的分布外数据集的重要性,并指出有必要通过该研究提出的一种新的评价指标,衡量模型重现氨基酸特异性蛋白质-配体相互作用指纹的能力.
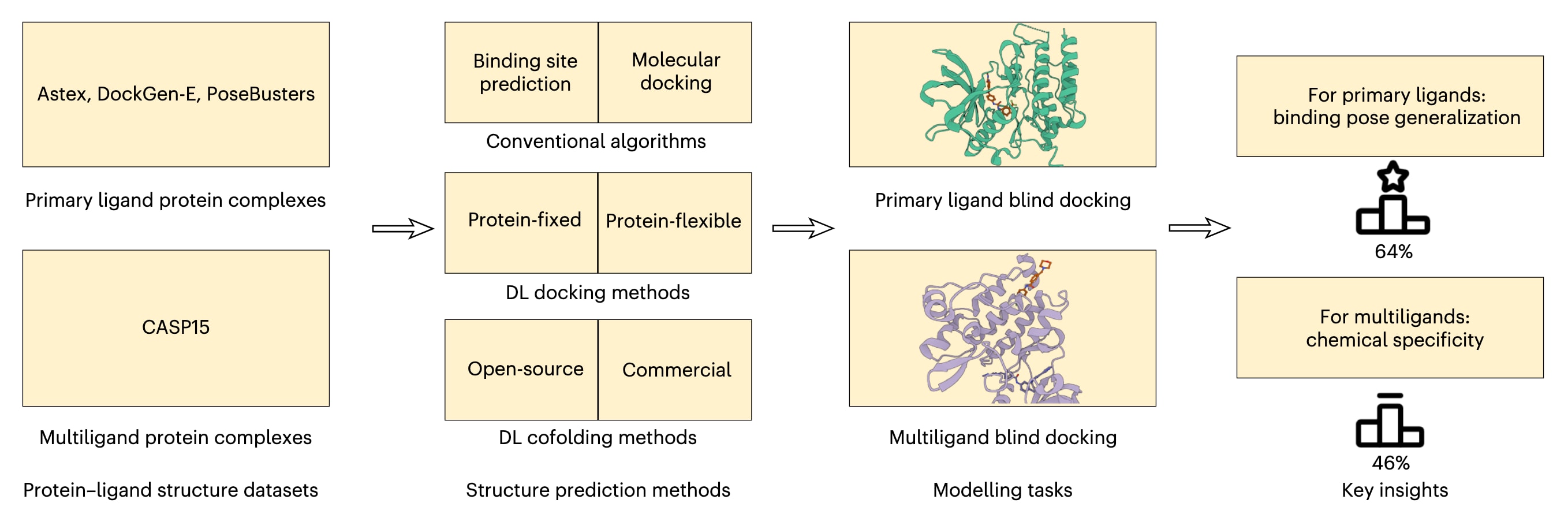
图1|PoseBench基准. 该图概述了PoseBench,这是一个面向主配体与多配体蛋白质复合物结构的、具有广泛适用性的深度学习建模综合基准.该基准中包含多种最新的深度学习对接与共折叠基线算法,涵盖开源方法与具有商业使用限制的方法,同时也包括用于对接的传统算法.基于PoseBench得到的关键观察结果表明,在面对新的或不常见的预测目标时,结构建模性能与相互作用建模性能之间存在明显脱节,同时若干关键的深度学习共折叠方法在实现高结构预测精度时对基于多序列比对的输入特征具有高度依赖性.
2 相关工作
2.1 蛋白质-配体相互作用复合物的结构预测
基于深度学习的蛋白质-配体结构解析研究,在很大程度上源于几何深度学习方法的发展,例如EquiBind和TANKBind,这些方法通过直接预测的方式,即基于回归的方法,对蛋白质复合物中结合态配体结构进行建模.值得注意的是,此类预测方法不仅能够估计配体在多条蛋白质链复合物中的局部结合构象,还可以预测相应复合物的结合亲和力.然而,除了预测精度本身仍然有限之外,后续研究发现这些方法在蛋白质原子与配体原子之间往往会产生明显的空间位阻冲突,这在很大程度上限制了它们在现代药物发现流程中的广泛应用.
2.2 蛋白质-配体结构预测与对接
在第一代蛋白质-配体结构预测方法出现之后不久,DiffDock等深度学习方法通过重新定义问题形式,展示了一种新的解决思路,即将蛋白质-配体对接视为生成式建模任务.在这一框架下,模型可以针对特定蛋白质靶标生成多个可能的配体构象,并利用预测得到的置信度评分对这些构象进行排序.这一思路激发了大量后续研究,提出了多种不同的生成式建模方案来解决同一问题.其中一些方法还能够较为准确地刻画配体结合过程中蛋白质的构象柔性变化,或者以较高精度预测蛋白质-配体的结合亲和力.
2.3 蛋白质-配体复合物的基准评测工作
随着大量新的蛋白质-配体结构预测方法不断涌现,近期研究提出了多种新的数据集和评价指标,用于系统评估新方法的性能.部分基准工作主要关注单配体蛋白质相互作用的建模,而另一些则专注于多配体蛋白质相互作用的评估.该研究提出PoseBench的一个重要动机,正是为了弥合这一差距,通过在两种相互作用场景下系统评估一系列最新的、对结合口袋不作先验假设的结构预测方法.具体而言,该基准同时涵盖了基于游离态蛋白质结构的对接方法,以及利用主序列直接预测完整生物组装体的、具有挑战性的深度学习共折叠方法.下一节中的基准结果表明,这一全面的新型评测体系对于推动未来蛋白质-配体建模研究具有重要的现实意义和应用价值.
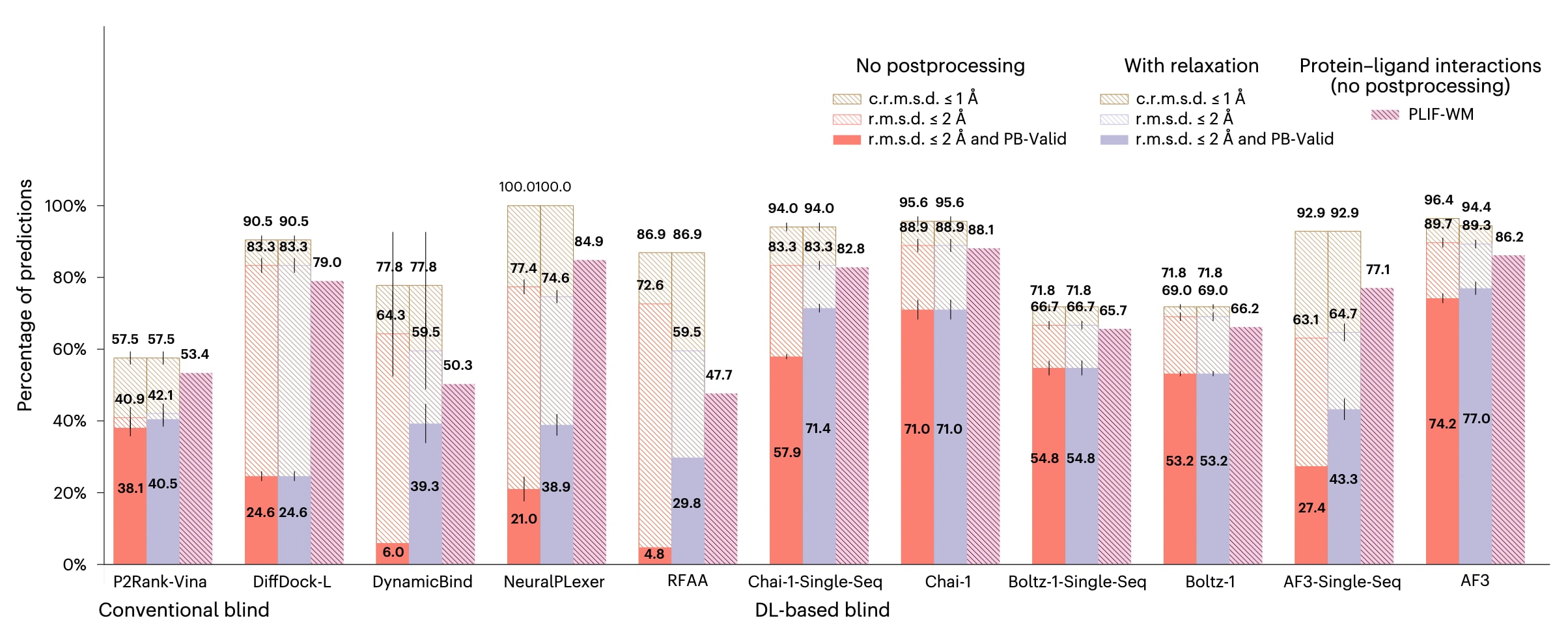
图2|Astex Diverse结果. Astex Diverse主配体对接的成功率(n=85个蛋白质-配体复合物).数据以每个复合物三次独立预测结果的平均值±标准差形式给出.
3 结果与讨论
该节给出了PoseBench在主配体与多配体蛋白质-配体对接及结构预测任务上的结果,并讨论其对未来研究的启示,整体概览如图1所示.需要说明的是,在所有实验中,对于生成式方法,性能指标均以每种方法三次独立运行结果的平均值和标准差进行汇报,以分析其跨运行的稳定性与一致性.核心评价指标包括:结构准确的配体构象预测比例,其判定标准为重原子质心均方根偏差小于2或1 Å,即(c.)r.m.s.d.≤2(1) Å;在此基础上同时满足化学合理性的构象预测比例,该合理性由PoseBusters软件套件判定,即r.m.s.d.≤2 Å且PB-Valid,该指标可能受到事后采用计算代价较高的分子动力学模拟进行结构弛豫的影响,即包含弛豫的情况;以及该研究新提出的氨基酸特异性蛋白质-配体相互作用指纹的Wasserstein匹配评分,即PLIF-WM.上述指标的形式化定义见Metrics部分.此外,在补充附录C中给出了各基线方法的平均运行时间与内存占用,以评估其在实际结构驱动应用中的效率,补充附录G中则汇总了补充结果.
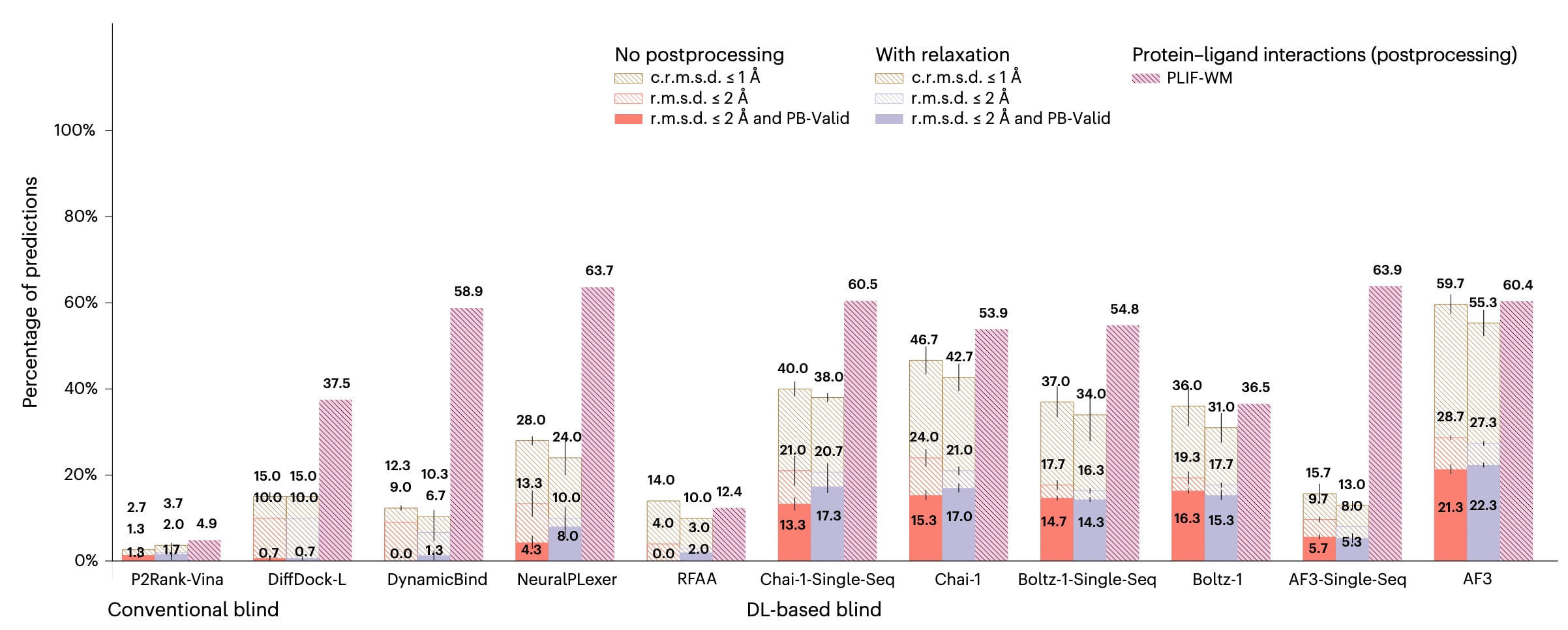
图3|DockGen-E结果. DockGen-E主配体对接的成功率(n=122个蛋白质-配体复合物). 数据以每个复合物三次独立预测结果的平均值±标准差形式给出.
3.2 Astex Diverse结果
Astex Diverse数据集包含截至2007年存入RCSB蛋白质数据银行的蛋白质-配体相互作用结构,该数据集中大多数结构已包含在各基线方法的训练数据中.然而,对该数据集进行的基准测试结果(n=85个蛋白质-配体复合物),如图2所示,表明只有深度学习共折叠方法在结构与化学准确性方面的表现,即r.m.s.d.≤2 Å且PB-Valid,超过了传统对接基线方法AutoDock Vina结合P2Rank进行结合位点预测以实现盲对接的结果.值得注意的是,几乎所有基线方法在约90%的情况下都能识别出正确的蛋白质-配体结合口袋,但只有深度学习共折叠方法Chai-1、Boltz-1以及AlphaFold 3在结构与化学准确性和化学特异性(PLIF-WM)之间实现了较为合理的平衡,其中AlphaFold 3的单序列版本,即去除MSA输入的版本,是一个显著的例外.这些结果表明,深度学习共折叠方法学习到了对该数据集输入序列最为全面的表征,但在缺乏多样化输入多序列比对的情况下,只有Chai-1仍能保持较强性能.一种可能的解释是,Chai-1在训练过程中除了利用输入MSA特征外,还引入了由蛋白质语言模型ESM2生成的氨基酸序列嵌入,从而为模型提供了丰富的、独立于MSA的生物大分子结构表征能力.
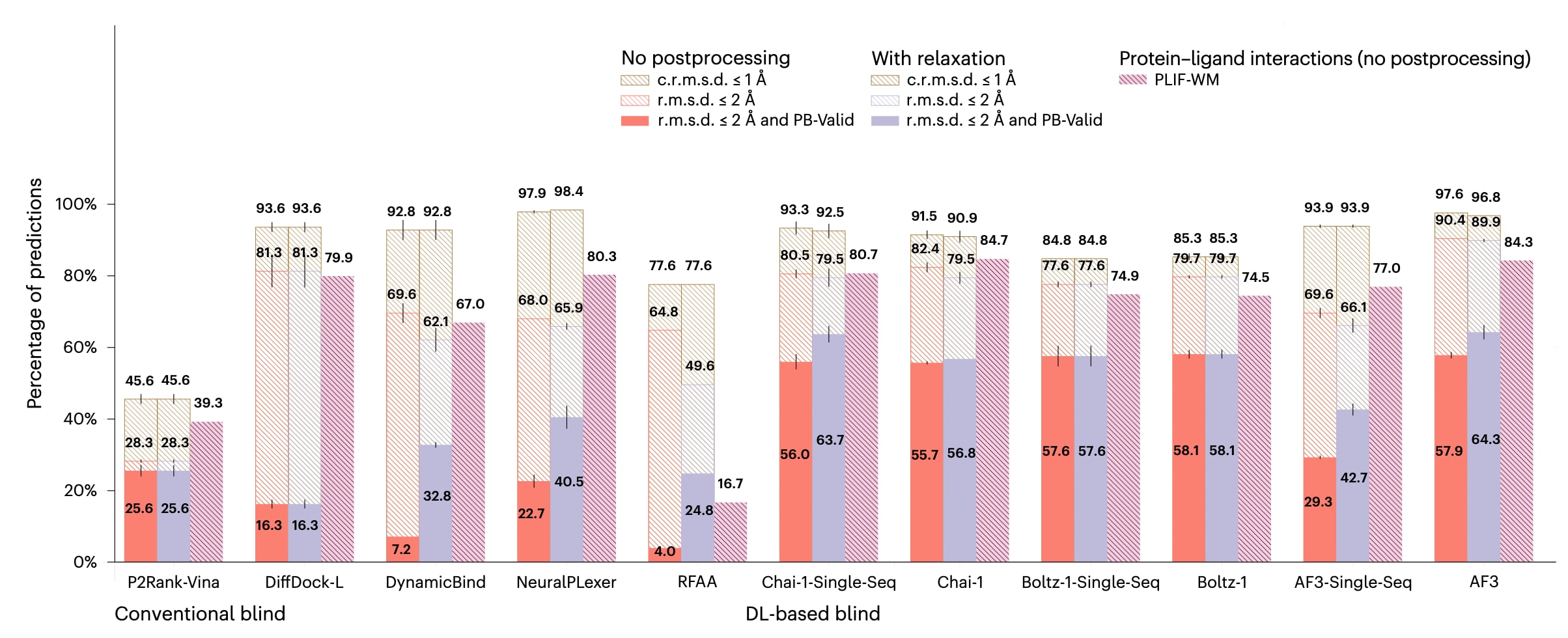
图4|PoseBusters Benchmark结果. PoseBusters Benchmark主配体对接的成功率(n=130/308个蛋白质-配体复合物).数据以每个复合物三次独立预测结果的平均值±标准差形式给出.
3.3 DockGen-E结果
如图3所示,在新的DockGen-E数据集上进行的实验结果表明,该数据集包含截至2019年存入PDB的具有生物学相关性的蛋白质-配体相互作用复合物(n=122个蛋白质-配体复合物),只有最新的深度学习共折叠方法才能定位到其中相当一部分结构准确的结合构象.鉴于这些方法在训练阶段可能已经见过部分相关结构,即便如此,最新的AlphaFold 3模型在超过75%的复合物上仍未能识别出同时满足结构与化学准确性的构象,这一点尤为引人关注.此外,对于Chai-1、Boltz-1和AlphaFold 3,其单序列版本在化学特异性方面的表现反而优于基于MSA的版本,这可能表明,对于这些方法而言,MSA特征在一定程度上掩盖了主序列信息,转而强化了进化平均化的、即氨基酸非特异性的表征.各方法在该数据集上整体较低的PLIF-WM取值范围,进一步反映出该数据集相较于Astex Diverse数据集在化学建模方面具有更高难度.造成这一困难的一个潜在原因在于,该数据集中的每个复合物都对应于功能上彼此不同的蛋白质-配体结合口袋,这一点可由ECOD结构域分类加以刻画,而这些结构与2019年之前存入PDB的数据相比具有更高的多样性.因此,Chai-1、Boltz-1和AlphaFold 3很可能对PDB中最常见的蛋白质-配体结构类型产生了一定程度的过拟合,从而忽略了自然界中存在的若干不常见结合口袋类型.
3.4 PoseBusters Benchmark结果
PoseBusters Benchmark数据集约有一半的蛋白质-配体相互作用结构是在AlphaFold 3和Boltz-1可用的最大训练数据截止日期2021年9月30日之后存入PDB的,该数据集共包含308个蛋白质-配体复合物,经筛选后用于后续分析的为130个.其结果如图4所示,再次表明深度学习共折叠方法相较于传统方法和深度学习对接基线方法具有最优性能.然而,还观察到一个值得注意的现象,即Chai-1在不使用输入MSA的情况下,在结构与化学准确性以及化学特异性之间实现了与表现最优的AlphaFold 3相当的平衡,这可能意味着在该数据集上Chai-1相较于AlphaFold 3具有更强的结合构象泛化能力.同时,对于AlphaFold 3的单序列版本,再次观察到其整体性能出现显著下降,而在为Chai-1提供输入MSA时,其化学特异性有所提升,但结构准确性相较于单序列模式略有下降.这些现象凸显了未来研究中系统分析生物大分子结构生成模型训练过程的重要性,特别是需要深入理解多样化输入MSA的可用性及其组成方式如何在不同程度上影响模型性能.
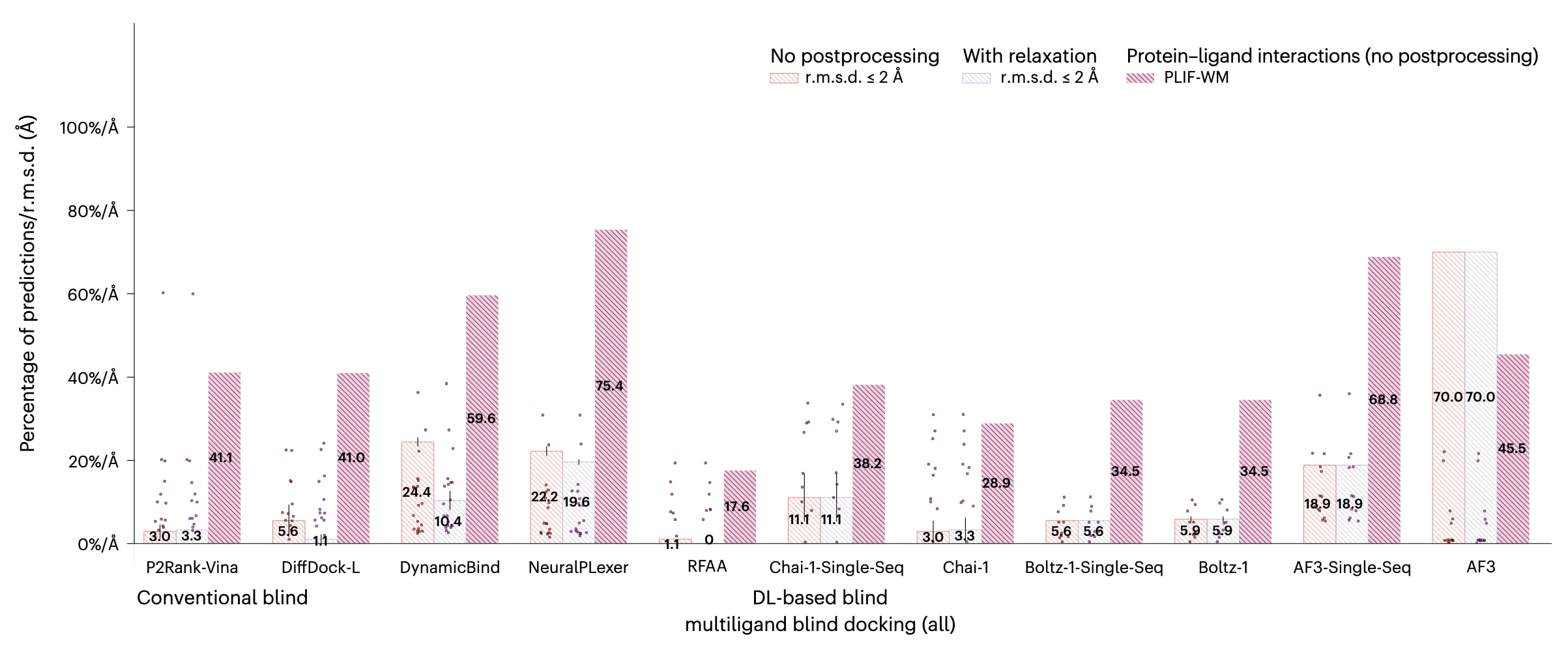
图5|CASP15多配体结果. CASP15多配体对接的成功率(n=13个蛋白质-配体复合物).数据以每个复合物三次独立预测结果的平均值±标准差形式给出.
3.5 CASP15结果
作为一个全新的、具有挑战性的蛋白质-配体相互作用复合物数据集,CASP15上的方法在训练阶段均未接触过该类数据.其多配体结果(n=13个蛋白质-配体复合物),如图5所示,表明大多数方法难以对多配体预测目标实现有效泛化.然而,在提供输入多序列比对的情况下,AlphaFold 3在这一任务中表现突出.由于CASP15中的许多多配体目标对应于体量较大且高度对称的蛋白质复合物,额外的进化信息,即MSA,很可能增强了AlphaFold 3对高阶蛋白质-蛋白质相互作用的预测能力.但值得注意的是,其结构准确率的提升是以蛋白质-配体化学特异性的下降为代价的,相较于其单序列版本尤为明显.对于CASP15数据集中的单配体结果,即主配体任务(n=6个蛋白质-配体复合物),其结果见扩展数据图1,呈现出相反的趋势,传统对接方法以及开源的深度学习共折叠方法,如AutoDock Vina、NeuralPLexer和Boltz-1,在对晶体结构中的蛋白质-配体相互作用指纹建模方面优于其他近期的深度学习共折叠方法,同时在结构准确性上保持了相当的水平.鉴于CASP15数据集规模较小,可以合理地认为,深度学习方法,尤其是部分最新的共折叠方法,在预测包含新型蛋白质-配体相互作用的复合物时仍面临显著挑战.在Exploratory analyses of results部分中,通过分析常见PDB训练数据与该基准评测数据集之间的蛋白质-配体结合相似性,对这一问题进行了更为深入的探讨.
3.6 结果的探索性分析
为总结该研究所采用基线方法的常见失败模式,并为药物发现领域未来的研究与开发工作提供新的方向,对一系列问题进行了探索性分析.
研究问题1.哪些类型的蛋白质-配体复合物是所有基线方法都难以预测的.为回答这一问题,首先收集了所有在结构与化学准确性方面均未被任何方法正确预测的配体构象,其判定标准为r.m.s.d.≤2 Å且PB-Valid.随后,针对每一个失败的配体构象,提取PDB中该蛋白质-配体复合物对应的功能注释,并构建直方图以统计这些失败复合物注释的频率.分析结果如扩展数据图2所示,其中可以看到,金属转运蛋白、黄素蛋白、生物合成蛋白、RNA结合蛋白、免疫系统蛋白以及氧化还原酶等类型,在包括Chai-1和RoseTTAFold-All-Atom在内的所有基线方法中均被频繁误预测,这表明当前最新的深度学习蛋白质-配体结构预测方法在很大程度上尚未充分覆盖这些蛋白类别.为进一步明确未来研究方向,在后续分析中,专门考察这一模式在性能最优的深度学习共折叠方法AlphaFold 3中是否仍然存在.
研究问题2.像AlphaFold 3这样高精度的深度学习共折叠方法最难预测哪些类型的蛋白质-配体复合物.针对这一问题,将AlphaFold 3所有失败的配体预测结果与PDB中对应的蛋白功能注释进行关联,以识别其在预测覆盖范围内最具挑战性的蛋白质-配体相互作用类型.与研究问题1的结论类似,扩展数据图3显示,按预测难度排序,AlphaFold 3在配体结合的RNA结合蛋白、免疫系统蛋白、金属转运蛋白、生物合成蛋白、黄素蛋白、裂解酶以及氧化还原酶等类型上,最难生成同时具有高结构与化学准确性的配体构象.鉴于其中若干蛋白类别在过去50年中在PDB中的代表性较低,例如免疫系统蛋白和生物合成蛋白,未来研究中有必要确保新的深度学习蛋白质-配体结构预测方法能够扩展其性能,以支持对这些不常见配体结合蛋白的准确建模,或者提出一种对不常见相互作用具有广泛适用性的微调策略.
研究问题3.蛋白质-配体结合构象与PDB训练数据的同源性缺乏是否与各方法的预测准确性呈负相关关系.为评估蛋白质-配体结合构象相似性对各基线方法性能的影响,利用PLINDER数据资源,基于每个复合物的配体结构与特征重叠评分SuCOS以及其蛋白质结合口袋在结构与序列层面的相似性,从PoseBusters Benchmark数据集中筛选出41个聚类代表复合物.该子集中所有预测目标均未包含在任何方法的训练数据中.随后,使用SciPy 1.15.1,计算各方法在这些复合物上的预测准确性,即配体构象r.m.s.d.,与该复合物相对于2021年9月30日之前存入PDB的任意复合物的最大SuCOS-结合口袋相似性之间的Pearson相关系数和Spearman相关系数及其P值.扩展数据图4表明,所有深度学习方法的性能均与复合物相对于常见PDB训练数据的相似性存在相关性,其中基于MSA的Boltz-1、AlphaFold 3和Chai-1表现出最强且统计显著的相关性(P<0.05).与并行研究中对共折叠方法在新预测场景下性能的评估结果一致,这些发现表明,尽管当前一代深度学习模型,无论是对接方法还是共折叠方法,在个别情况下能够对真正全新的蛋白质-配体复合物,即SuCOS-口袋相似性小于30的情形,作出准确预测,但在很大程度上仍依赖于重现训练阶段所见过的蛋白质-配体结合模式来实现对未知复合物的准确预测.值得注意的是,这一趋势在诸如P2Rank-Vina等传统对接方法中并未观察到.最后,通过扩展数据图5总结并展示了各基线方法的不同失败模式,其中可以看到,诸如RoseTTAFold-All-Atom和AlphaFold 3等深度学习方法在准确预测配体结合的生物合成蛋白和免疫系统蛋白结构方面普遍存在困难,这表明这些不常见类型的蛋白质-配体相互作用尚未被当前一代基于深度学习的结构预测方法充分覆盖,从而为面向特定相互作用类型的建模研究,例如通过微调或偏好优化,提供了潜在的发展空间.
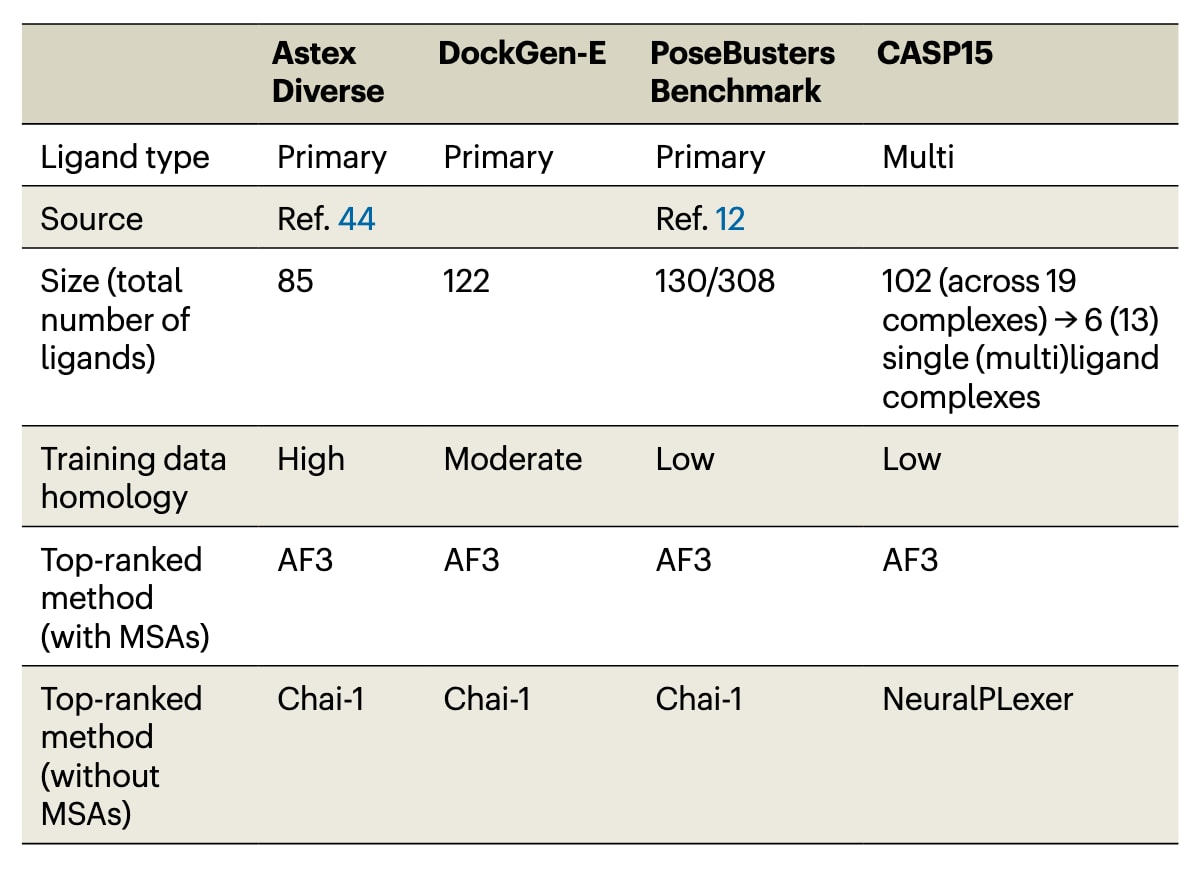
表1|PoseBench用于评测的蛋白质(多)配体结构数据集
4 结论
该研究提出了PoseBench,一个统一且具有广泛适用性的基准与工具集,用于系统研究蛋白质-配体对接与结构预测方法的性能.基于PoseBench的基准测试结果如表1所示,总体表明深度学习共折叠方法在性能上优于传统方法和深度学习对接基线,但在预测包含新型蛋白质-配体结合构象的复合物时仍然面临显著挑战.当目标蛋白存在高质量、多样化的深度多序列比对时,AlphaFold 3的整体表现最佳,而在缺乏此类信息的情况下,Chai-1表现更为稳健,这一结论与是否存在同源蛋白无关.此外,研究发现多种深度学习方法在预测构象的结构准确性与诱导的蛋白质-配体相互作用的化学特异性之间难以取得平衡,这提示未来方法可能需要引入物理化学相关的损失函数或更先进的采样策略,以缩小这一性能差距.最后,结果还表明,部分但并非所有深度学习共折叠方法在实现高结构预测精度时高度依赖多样化输入MSA的可用性,例如AlphaFold 3,而Chai-1和Boltz-1则不具备这种强依赖性,这进一步强调了未来研究中有必要系统阐明MSA以及蛋白质语言模型嵌入的可用性对生物大分子结构预测方法训练动力学的影响.作为一个公开可用的资源,PoseBench具备良好的扩展性,能够灵活地整合新的数据集、方法和分析框架,以支持蛋白质-配体对接与结构预测领域的持续发展.