Nature 2026|OpenScholar:用检索增强语言模型综述科学文献
今天介绍的这项工作来自Nature。OpenScholar是一种面向科研文献综述的全开源检索增强语言模型:系统以4500万篇开放获取论文构建OpenScholar DataStore(OSDS),通过训练过的检索器与重排序器定位证据,再用自反馈迭代生成与引用核验输出带可追溯引用的长回答。配套流程支持将GPT-4o等现成模型接入,通过带检索的自反馈推理进一步提升回答的正确性与引用支持。作者还提出ScholarQABench基准,覆盖计算机科学、物理、神经科学与生物医学,并结合自动指标与专家量表评估。结果显示,尽管模型规模仅8B,OpenScholar-8B在多论文综合任务上超过GPT-4o与PaperQA2,引用准确性接近专家;相较之下,GPT-4o在需要引用近期文献的设定中仍频繁产生“看似可信但不存在”的引用。相关代码、模型、数据与Demo同步开源。

获取详情及资源:
- 📄 论文:https://doi.org/10.1038/s41586-025-10072-4
- 💻 代码:https://github.com/AkariAsai/OpenScholar
- 🧪 基准与评测:https://github.com/AkariAsai/ScholarQABench
- 🗂 数据:https://huggingface.co/datasets/OpenSciLM/OS_Train_Data;https://huggingface.co/datasets/allenai/openscilm_queries;https://github.com/AkariAsai/ScholarQABench/tree/main/data
- 🌐 在线Demo:https://openscholar.allen.ai
0 摘要
科学进展依赖研究者能够持续综合快速增长的文献。该研究提出OpenScholar,一种面向科研查询的检索增强语言模型,通过在4500万篇开放获取论文中定位相关段落,生成带可追溯引用的综合回答。为评估系统能力,作者构建ScholarQABench,一个多领域文献检索与综合基准,包含2967个专家撰写的查询与208个长答案,覆盖计算机科学、物理、神经科学和生物医学。尽管规模更小且完全开放,OpenScholar-8B在ScholarQABench的多论文综合任务上,正确性分别比GPT-4o和PaperQA2高6.1%和5.5%。在GPT-4o有78%~90%概率出现伪造引用的设置下,OpenScholar的引用准确性与人类专家相当。同时,OpenScholar的数据存储、检索器与自反馈推理循环也可以增强现成语言模型,例如OpenScholar-GPT-4o使GPT-4o的正确性提高12%。在人类评审中,专家分别有51%和70%的情况下更偏好OpenScholar-8B与OpenScholar-GPT-4o的回答,而GPT-4o仅为32%。该研究同步开源代码、模型、数据存储、数据集与公开Demo。
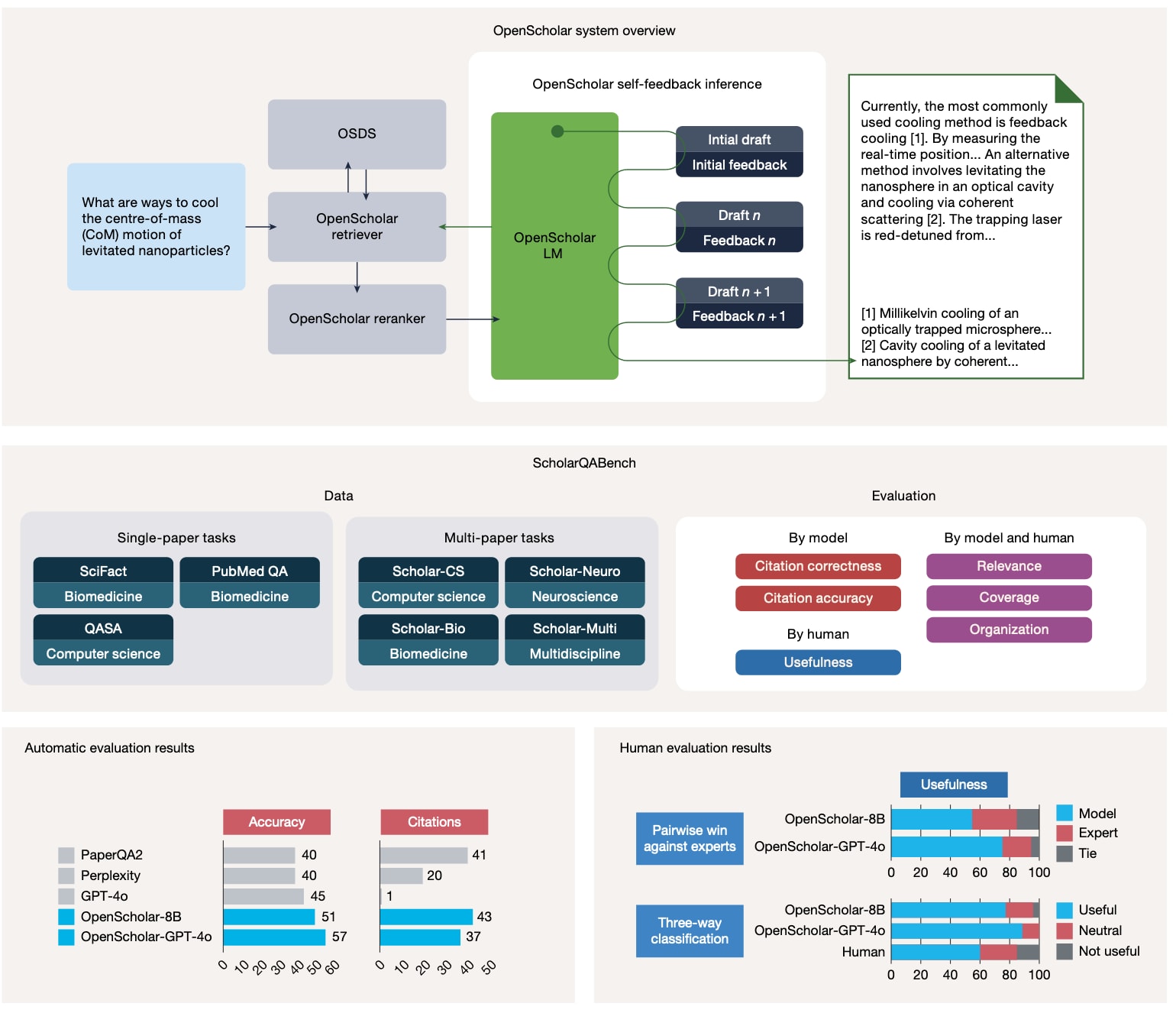
图1|OpenScholar、ScholarQABench与评估结果概览。
上:OpenScholar由专用数据存储OSDS、检索组件与语言模型组成,并通过带检索的自反馈推理迭代改进回答。中:ScholarQABench概览,包含跨多个学科的2200个专家问题,并配套自动与人工评估协议。下:在Scholar-CS(100个计算机科学问题)上的自动指标与人工评估结果显示,OpenScholar在使用训练过的8B模型或以GPT-4o为生成器时均显著优于其他系统,且在人类评审中超过50%的情况下优于专家回答;人工评估由16名博士级专家在Scholar-Multi的108个问题上完成。
1 引言
从科学文献中综合知识对于发现新方向、改进方法,以及支撑基于证据的决策都很关键。但论文数量的快速增长,使研究者越来越难以持续跟进。有效的文献综合不仅需要更精确的检索,还需要把结论与证据进行细粒度对应,并尽可能覆盖最新研究。
通用LLM在写作与归纳上具备潜力,但在科学综述场景中常见问题包括内容幻觉、预训练知识滞后,以及引用归因能力不足。作者的实验显示,当要求GPT-4o在计算机科学和生物医学等领域引用近期文献时,有78%~90%的情况下会产生伪造引用。**检索增强语言模型(RAG)**通过在推理时接入外部知识,在一定程度上缓解上述问题,也推动了面向文献检索与综合的系统探索。但现有多数系统依赖黑盒API或通用大模型,缺少可复现的、面向科学领域的开放检索数据存储(带索引的处理后语料)。与此同时,文献综合任务的评测也相对薄弱,往往局限于单一学科,或者退化为选择题式的简化任务。
为应对准确性、覆盖性与透明性三方面挑战,该研究提出OpenScholar。系统核心由专用数据存储OpenScholar DataStore(OSDS)、自适应检索模块,以及带自反馈的生成机制构成。OSDS包含4500万篇科学论文与2.36亿个段落级嵌入,为训练与推理提供可复现基础。推理时,系统通过训练过的检索与重排序从OSDS取回证据,生成带引用的回答,并通过自反馈循环迭代修订,以提升事实性、覆盖度与引用准确性。同一套推理流程还用于生成高质量合成训练数据,从而在不依赖专有大模型的情况下,训练出紧凑的OpenScholar-8B及配套检索器。
为系统化评估OpenScholar,作者构建ScholarQABench。该基准强调开放式、多论文的科学综合,要求模型给出基于多篇近期文献的长答案。数据覆盖计算机科学、物理、神经科学与生物医学等领域,包含近3000个专家撰写的查询,并配套自动指标与人类量表,用于评估覆盖、连贯性、写作质量与事实正确性等维度。
为解决长答案难以稳定评估的问题,作者提出一套更严格的评测协议,将自动指标(例如引用准确性)与基于专家量表的rubric评估结合起来,用于更可靠地衡量长篇科学回答的覆盖、连贯性、写作质量与事实正确性。作者的专家分析显示,这种多维度评估与专家判断具有较高一致性,能够捕捉长回答中的关键质量差异。
在ScholarQABench上,作者评估了专有与开源模型(例如GPT-4o、Llama3.1 8B与70B),比较带检索与不带检索的设定,并对比PaperQA2等专用系统。结果表明,尽管GPT-4o的通用能力强,但在引用准确性与覆盖度上仍存在明显短板,常生成不准确或不存在的引用。OpenScholar在多项指标上超过了仅语言模型与标准RAG基线,也超过了专有与开源系统。值得注意的是,在完全开源的检查点设定下,OpenScholar-8B超过了依赖专有语言模型的PaperQA2,也超过了Perplexity Pro等生产系统,正确性分别提升约6%和10%。作者同时强调,OpenScholar使用更小、更高效的检索器,使整体推理成本显著降低。
OpenScholar管线还可以增强现成语言模型。例如以GPT-4o作为生成器时,OpenScholar-GPT-4o相较仅用GPT-4o,正确性提升12%。此外,尽管人类专家整体表现仍强于不带检索的GPT-4o等基线,OpenScholar系统在回答正确性与引用准确性上能够与专家相当,甚至在部分设定中超过。整体评测也凸显了关键组件的重要性,包括重排序、自反馈与引用核验,以及将不同检索来源组合并训练领域检索系统带来的收益。
除自动评测外,作者还邀请16名科学家在ScholarQABench的108个文献综合问题上,对OpenScholar与专家撰写答案进行成对偏好与细粒度对比评审。结果显示,OpenScholar-GPT-4o与OpenScholar-8B相较专家答案的赢率分别为70%与51%;相对地,不带检索的GPT-4o信息覆盖不足,赢率仅31%。作者也发布了据其所知首个面向科学文献综合的公开Demo,发布以来已有超过3万名用户使用,并收集了近9万条来自不同学科的查询。
2 OpenScholar在ScholarQABench上的表现
2.1 基线模型
作者比较三类设定:(1)参数化语言模型(不检索):Llama3.1 8B与70B以及GPT-4o(gpt-4o-2024-05-13版本),直接生成回答与论文标题列表;随后验证标题是否真实存在,并在可行时抓取摘要作为引用。(2)RAG基线:使用OSDS(RAGOSDS)检索Top-N段落,与输入拼接后生成,沿用标准RAG流程。(3)OpenScholar:使用包含训练过检索器与重排序器、自反馈迭代生成与引用核验的定制推理管线,并分别以自训8B模型、Llama3.1 70B与GPT-4o作为生成器,对应OpenScholar-8B、OpenScholar-70B与OpenScholar-GPT-4o。在多论文任务上,作者还测试Perplexity Pro;由于其无API,作者通过Selenium收集最终输出,无法抽取引用用于评估。同时作者也对比PaperQA2;由于PaperQA2的数据存储不公开,作者使用OSDS作为其检索来源。
2.2 主要结果
在单论文任务上,OpenScholar在最终正确性与引用准确性上持续优于其他模型。OpenScholar-8B与OpenScholar-70B在带检索与不带检索的Llama3.1 8B与70B之上均取得更高的正确性与引用F1;OpenScholar-70B在PubMedQA与QASA上甚至能够与GPT-4o相当或更好。与此同时,与标准RAG基线相比,OpenScholar在引用准确性上也呈现出更稳定、幅度更大的提升。
在多论文任务上,作者把Scholar-CS的rubric得分作为主要正确性指标,即模型回答满足的专家标注rubric条目的数量,具体评分细节见Methods;同时在Scholar-Multi上用LLM裁判评估整体写作质量,并在各数据集上跟踪引用准确性。结果显示,OpenScholar-8B、OpenScholar-70B与OpenScholar-GPT-4o均表现强劲。尤其是OpenScholar-GPT-4o相较GPT-4o本体在Scholar-CS上提高12.7分,相较标准RAG提高5.3分。将OpenScholar管线与自训OpenScholar-8B结合后,整体表现进一步增强,体现出领域化训练带来的收益。作者还指出,OpenScholar-8B在rubric得分上明显超过GPT-4o、Perplexity Pro与PaperQA2等系统,并特别提到PaperQA2在段落重排序、摘要与回答生成等环节依赖GPT-4o。尽管PaperQA2在引用准确性上能够与OpenScholar相当甚至更高,但其回答常只依赖一两篇论文,对每段检索片段逐段摘要,导致覆盖不足,从而在Scholar-CS的rubric得分与Scholar-Multi的LLM评分上落后。这些结果强调了文献综合需要同时平衡精确性与召回率。作者也强调,通过由轻量级bi-encoder、cross-encoder与自研模型组成的高效检索管线,OpenScholar-8B与OpenScholar-GPT-4o在保持高性能的同时显著降低成本,相比PaperQA2可低出数量级。
表1|ScholarQABench结果(单论文任务、多论文任务与成本)。
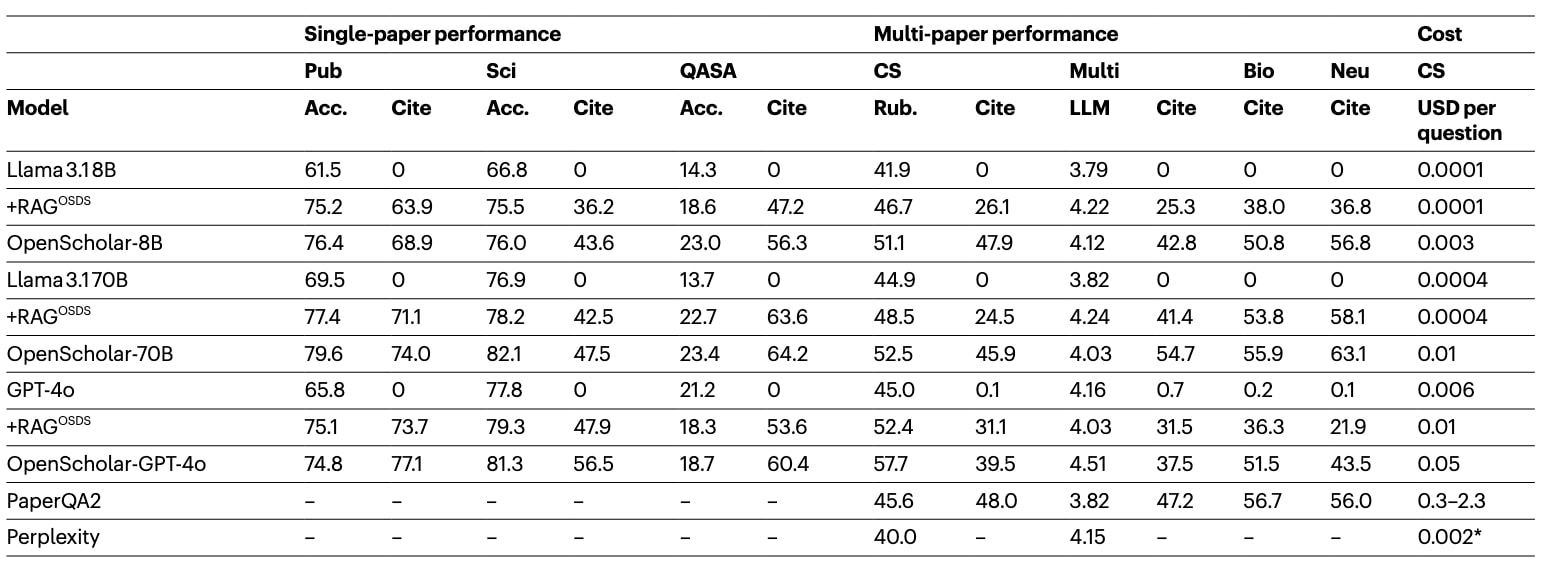
表1中,PubMedQA、SciFact与QASA为三类单论文任务;Scholar-CS、Scholar-Multi、Scholar-Bio与Scholar-Neuro为多论文综合与长文本生成任务。单论文任务的正确性指标为Acc:PubMedQA与SciFact使用准确率,QASA使用ROUGE-L。Scholar-CS的主要正确性指标为Rub(rubric量表得分),引用质量以引用F1衡量。Scholar-Multi的LLM评分为Prometheus预测的组织、相关与覆盖三项平均分。PaperQA2基于GPT-4o,其成本与推理时使用的PDF文件数量有关。8B与70B模型的成本虽然在本地机器上完成评测,但作者按TogetherAI的定价进行估算。Perplexity Pro需要每月20美元订阅,作者按Pro订阅允许的最多9000次查询把订阅费折算到单问题;由于其界面不提供每条引用对应的片段,作者无法评估其引用准确性。
3 参数化语言模型的局限
在单论文与多论文任务上,作者观察到不带检索的基线普遍表现不佳:检索几乎总是有助于提升表现;而完全不检索的模型往往既难以生成正确引用,也在多论文任务上呈现覆盖不足。表2统计了四种模型输出中被引论文的情况,其中“幻觉引用数”通过验证被引论文标题是否真实存在得到,验证过程依赖Semantic Scholar的API。结果显示,尽管这些模型常能生成看似合理的参考文献列表,但真正存在的标题比例非常低:不同模型中有78%~98%的标题是伪造的,且生物医学领域最严重。作者认为,这与语言模型在长尾、低覆盖知识上更容易幻觉的既有观察一致,并且在开放网络覆盖更弱的科学领域会被放大。将同一分析扩展到GPT-5(作者注明其于2025年8月发布)可将标题级幻觉比例降到39%,但伪造引用仍然常见。模型回答示例与论文标题列表见补充表19与表20。作者也指出,即便引用指向真实论文,多数引用也无法被对应摘要支撑,导致引用准确性接近于零。
作者还发现,不带检索的模型在覆盖度上也明显不足。在Scholar-Multi上,非检索模型(Llama3.1 8B、70B与GPT-4o)的平均评分持续低于带检索的模型,这一差距主要由覆盖得分显著偏低导致。例如,Llama3.1 8B的覆盖得分为3.45,而Llama3.1 8B+OSDS(标准RAG基线)可将覆盖得分提高到4.01。这些结果表明,在科学领域仅依赖模型的参数化知识尤其困难,且对小模型更为不利。
表2|计算机科学与生物医学领域的“幻觉引用”统计。

作者进一步强调,不带检索的LLM预测中存在大量并不存在的被引论文,而在OpenScholar的输出中未观察到这一问题。
4 ScholarQABench上的人类表现
作者也分析了专家在这一文献综合任务上的人类表现。具体而言,作者在ScholarQABench中两个带长答案人工标注的子集上评估专家撰写答案:Scholar-CS与Scholar-Multi,并对人类答案应用与模型输出相同的自动评估流程,以衡量rubric得分与引用准确性。对于Scholar-Multi,自动rubric评估不可用,但作者在后续章节对人类与模型答案都开展了专家评审,并对结果进行比较。
表3对比了人类答案与OpenScholar-GPT-4o、OpenScholar-8B、PaperQA2以及不带检索的GPT-4o。整体分析显示,人类专家答案仍是质量与相关性上的强基线:在rubric评估中,人类答案比不带检索的GPT-4o高9.6分,也比OpenScholar-8B高2.9分。PaperQA2的引用准确性较高,但其rubric得分以及组织、覆盖与相关等指标更低。相对而言,OpenScholar-GPT-4o的rubric得分甚至高于人类专家,OpenScholar-8B的引用准确性也可达到专家水平。作者还观察到,OpenScholar往往给出更全面的回答,平均长度更长、引用论文更多;这既反映覆盖提升,也可能在偏好评审中带来长度相关的干扰。作者在补充信息第6节中进一步分析了人类与模型答案差异,并讨论了提升科学文献综合能力的关键因素。
表3|人类与模型回答的长度、引用数量与质量统计。

表3中,“长度”为回答的平均长度,“引用数”为最终回答中被引论文的平均数量;“精确率”与“召回率”分别表示引用精确率与引用召回率;“组织”“覆盖”“相关”为由LLM裁判评估的组织结构、覆盖程度与相关性。作为参考,表中也包含了对人类评审查询集进行评估的不带检索GPT-4o输出;对于GPT-4o的引用数,仅统计可验证的有效引用。
5 消融与分析
5.1 推理组件消融
作者对推理组件进行消融,分别移除:(1)重排序(仅使用OSDS检索Top-N结果);(2)自反馈(只生成一次再做归因);(3)引用核验(省略最终核验)。对OpenScholar-8B,作者还进行训练消融:在相同推理管线下,用未专门训练的Llama3.1 8B替换自训8B模型(对应OpenScholar-GPT-4o的做法)。扩展数据表2显示,移除任一环节都会在正确性与引用准确性上带来明显下降,其中去掉重排序的损失最大。作者还发现,去掉自反馈对GPT-4o的伤害大于对自训8B的伤害,可能因为自训8B在训练中已部分学习到反馈模式;而跳过事后归因会同时降低引用准确性与最终正确性。自训与未训8B之间的差距,也进一步强调了领域化训练的价值。
5.2 检索消融
作者比较了仅OSDS(稠密检索)、仅S2(Semantic Scholar关键词API)、仅Web(You.com)以及三者组合的检索设定。为隔离检索影响,作者在不启用自反馈与引用核验的情况下使用8B语言模型生成,并用OpenScholar重排序器将候选重排到Top15。以Scholar-CS为例,Web-only表现最差(正确性45.9、引用F1为12.6),S2-only在引用上改善明显(正确性47.9、引用F1为39.1),而组合检索表现最佳(正确性49.6、引用F1为47.6)。作者据此指出,面向文献的定制检索(稠密检索+数据库API+重排序)能够带来更强的事实性与引用归因。
作者还分析了检索段落数量Top-N对性能的影响,对比标准RAG与OpenScholar,并分别使用自训8B与Llama3.1 8B进行评估。扩展数据图3与图4汇总了结果。尽管Llama3.1被训练为可接收最多128000个token,但其性能会在上下文过长后下降:将Top-N从5增加到10能提升正确性,但进一步增大N会同时损害正确性与引用准确性。这表明即便具备长上下文能力,小模型也可能难以在缺少专门训练的情况下有效利用大量段落。相比之下,自训8B在N=20以内仍保持较强表现,而更大的模型(例如Llama3.1 70B)对更长上下文更为稳健。
6 OpenScholar有效性的专家评估
为补充自动指标并检验OpenScholar的优势与边界,作者开展了专家评审,对比人类专家撰写答案与多种LLM系统生成答案。该研究覆盖100多个文献综述问题,参与者超过15人,包括博士生、研究科学家与大学教授等,并累计收集了400多条针对人类与模型答案的细粒度专家评估。
6.1 评估设计
作者选取Scholar-Multi中由专家撰写的108组问答,并评估三种设定:不带外部检索的GPT-4o、以GPT-4o为生成器的OpenScholar(OpenScholar-GPT-4o)、以及使用自训8B模型的OpenScholar(OpenScholar-8B),三者均输出带引用的回答。作者随后招募另一组博士级领域专家,将模型答案与专家答案进行对比评审。每次评审会同时展示问题、模型答案与人类答案,评审者对两份答案进行细粒度打分,并给出成对偏好判断。细粒度评估采用Methods中定义的五档量表(覆盖、相关与组织),同一套rubric同时用于模型与人类答案。对总体有用性,评审者以1~5分打分,并被映射为三类:无用(1、2)、中性(3)与有用(4、5),随后统计“有用”占比。成对偏好判断允许选择其中一份答案或标记平局;评审者也可选择性给出偏好理由。
6.2 专家撰写者细节
用于撰写问题与答案的专家撰写者共有12人,均为来自美国研究机构的博士生与博士后,具备至少3年的科研经验,并在所在领域发表过多篇论文。其覆盖领域包括计算机科学(自然语言处理、计算机视觉、人机交互)、物理(天体物理、光子学与光学)以及生物医学(神经科学、生物成像)。作者将标注任务按专业领域进行分配,平均报酬为每人35~40美元。
6.3 专家评审者细节
共有16名来自上述三类领域的专家参与评审,其中12人也参与了答案撰写。所有评审者满足与答案撰写者相同的资格要求。为减少偏差,作者确保评审者不会评估自己所撰写问题的模型回答,并将任务分配给不同专家组。每个实例由1~3名专家评审,带平局的成对比较一致性为0.68;若将平局合并处理,则一致性为0.70。平均而言,每位专家评审每个实例花费约5分钟,报酬范围为25~35美元。
6.4 专家评审结果
6.4.1 总体结果
表4给出了各维度的平均分以及相对人类答案的赢率、平局与败率。作者指出,OpenScholar-GPT-4o与OpenScholar-8B在超过50%的问题上优于人类答案,其优势主要来自更广、更深的信息覆盖。相对地,不带检索的GPT-4o覆盖显著不足,赢率低于35%,总体有用性也明显低于人类与两种OpenScholar设定。作者据此强调,即便对最强的通用模型而言,回答科学文献综述问题仍然具有挑战性。总体上,OpenScholar-GPT-4o与OpenScholar-8B分别在80%与72%的查询中被评为“有用”。
表4|专家评审结果汇总。

表4中,细粒度维度以1~5分计,括号内为相对人类答案的差值;正值表示模型更高,负值表示人类更高。
尽管开源8B模型的OpenScholar已在总体偏好上超过人类专家,但其输出被评为不如当前最强的专有LLM版本OpenScholar那样“有组织、流畅”。作者观察到,GPT-4o更能有效吸收反馈,且倾向生成更长、更流畅的输出,从而在组织结构得分上显著高于OpenScholar-8B与人类答案。
6.4.2 回答长度控制的影响
作者注意到,模型输出相较人类答案存在显著长度差异:OpenScholar-GPT-4o与OpenScholar-8B的平均长度分别是人类答案的2.4倍与2.0倍,这可能影响偏好判断。为检验长度因素,作者在随机抽取的50个问题上对OpenScholar-GPT-4o进行长度控制:提示GPT-4o把回答摘要到少于300个英文单词,使OpenScholar回答平均约333词,接近人类答案长度。随后重复人工评审。结果显示,缩短后的GPT-4o在组织、覆盖与相关上分别得到4.5、4.6与4.6的平均分;缩短后的OpenScholar-GPT-4o在75%的问题上仍被偏好或与专家答案持平。这表明OpenScholar的优势并非仅由“更长”带来。作者也提到,评审者的解释常指出,缩短后的OpenScholar与人类答案仍可通过加入更多细节进一步提升,暗示300词限制可能压低了回答的有用性上限。
6.4.3 成对偏好解释分析
作者从带自由文本解释的成对偏好样本中随机抽取59例,手工分析哪些因素影响总体偏好。分析将解释划分为四类:组织、相关、覆盖与引用;其中引用类还包含对被引论文质量的评价,例如是否包含该领域的代表性工作。作者在补充信息表27中报告,12%、23%、29%与9%的解释分别提到了组织、相关、覆盖与引用准确性。该结果表明,覆盖在人工判断中起到关键作用,评审者往往因为模型回答覆盖更广、信息更深入而偏好模型输出;同时评审者也指出模型引用仍可改进,例如推荐论文偶尔过时,或相较更具代表性的工作不够相关。
7 讨论
为推动能够帮助科研人员应对持续增长文献的语言模型系统研究,作者提出OpenScholar与ScholarQABench。据作者所知,OpenScholar是首个完全开源的检索增强系统,使用开源权重语言模型与训练过的检索模型,通过迭代自反馈改写长文本输出,以缓解幻觉与引用不准等问题。ScholarQABench作为大规模新基准,为跨多个科学领域的文献综述自动化提供了更标准化的评估方式。基于ScholarQABench的评测显示,OpenScholar相较GPT-4o与当时并行的专有系统PaperQA2等实现了显著提升。跨三个学科的专家评审也显示,OpenScholar生成的答案在有用性上超过了需要约1小时完成标注的专家答案:OpenScholar-8B与OpenScholar-GPT-4o相对人类答案的赢率分别为51%与70%。作者同步开源代码、数据、模型检查点、数据存储与ScholarQABench,并发布公开Demo以支持后续研究。作者指出,未来可利用Demo收集的用户反馈继续改进检索质量、提升引用准确性并优化系统可用性。
8 局限
作者强调多方面局限,并指出该研究并不主张LM系统可以完全自动化科学文献综合。为推动该方向的发展,作者将ScholarQABench与OpenScholar发布给社区。
8.1 ScholarQABench的局限
首先,专家标注成本高且耗时,导致带人类长答案的评估集规模仍然较小,例如计算机科学长答案子集约110个问题,Scholar-Multi为108个专家答案,这可能引入方差与标注者专业偏差。作者开源数据与标注流程以便后续扩展。
其次,自动评估并不能完美刻画质量。在Scholar-CS中,作者以启发式权重组合长度、摘录与rubric条目;而标注者常要求一些并非严格必要的附加元素(背景、展开、挑战等),语言模型往往会补充这些内容,可能导致得分膨胀或被特定写作风格“利用”。尽管自动分数与专家判断相关性较高,评分关注点与聚合方式仍有改进空间。引用精确率与召回率按句子计算,在相邻句共同承担证据时可能过严。标注对应特定时间点(Scholar-CS为2024年7月,Scholar-Multi为2024年9月),为公平比较应排除这些时间之后发表的论文。作者建议使用OSDS或将来源限制到2024年10月之前的出版物,并计划持续更新基准。
第三,ScholarQABench作为静态公开基准,存在未来训练或检索污染风险。尽管多论文综合数据由专家新写,公开后仍可能在训练或搜索过程中被暴露。作者表示将持续更新并监测其使用情况。
最后,该基准主要覆盖计算机科学、生物医学与物理,尚未包含社会科学等其他工程与科学领域,因此结论可能无法完全推广到更多学科,尤其是论文数据访问更受限的领域。
8.2 OpenScholar的局限
尽管OpenScholar在ScholarQABench与专家评审中表现强劲,专家评审者仍指出若干限制。首先,OpenScholar并不总能检索到最具代表性或最相关的论文;未来可引入引文网络、发表时间等元信息改进检索。其次,OpenScholar输出可能包含事实错误或缺少证据支持的信息,尤其是在基于8B模型的版本中,其指令遵循与科学知识容量更有限。作者认为后续可通过进一步训练提升OpenScholar-8B的可靠性。
同时,尽管OpenScholar-GPT-4o具备竞争力,但其依赖通过OpenAI的API调用专有GPT-4o,模型随时间演进会使结果精确复现更具挑战。作者也强调,OpenScholar在推理时不使用受许可保护的论文。围绕检索增强语言模型中的数据公平使用仍有持续讨论,如何在合规前提下更好地纳入受版权保护内容仍是开放问题。
作者鼓励后续研究继续解决这些局限,推动面向科学文献综述的LM系统不断改进。
8.3 专家评审流程的局限
在人工评审中,评审者对覆盖、相关、组织与有用性等维度进行细粒度打分,而引用精确率与召回率等指标由独立流程评估。因此在判断“有用性”或成对偏好时,评审者可能更关注写作质量与信息覆盖,而未必逐条核对事实与引用,这需要谨慎解读人类偏好结论。作者也表示,将在未来工作中对引用准确性、引用有效性与事实性开展更细致的人类分析。
作者还指出,该研究的人工评审由16名博士生与博士后参与,作者尽力将其专业与被评审主题对齐,但科研问题往往需要更深的领域知识,评审者可能难以捕捉超出其直接研究范围的问题中的细微差异。此外,评审仅覆盖三个学科的108个问题,结论也可能无法完全泛化到其他领域或任务分布。