NC 2024 | PocketVec: 通过结合位点描述符对人类可成药口袋进行全面检测与表征

获取详情及资源:
- 📄 论文: https://doi.org/10.1038/s41467-024-52146-3
- 💻 代码: https://gitlabsbnb.irbbarcelona.org/acomajuncosa/pocketvec
0 摘要
可成药口袋是蛋白质中能够结合有机小分子的区域,其表征对于基于靶点的药物发现至关重要。然而,提取口袋描述符具有较大挑战性,现有策略在适用性方面往往存在局限。PocketVec方法被提出用于通过对类先导化合物进行逆向虚拟筛选来生成口袋描述符。该方法在性能上可与当前主流方法相当,同时克服了若干关键限制。
在此基础上,对人类蛋白质组中的可成药口袋进行了系统性搜索,整合实验解析结构与AlphaFold2模型,在约20000个蛋白结构域中鉴定出超过32000个结合位点。随后为每个位点生成PocketVec描述符,并开展大规模相似性搜索,完成超过12亿次成对比较。结果显示,发现了结构或序列方法未能识别的可成药口袋相似性,在尚未获得晶体抑制剂结构的蛋白中揭示出相似口袋的聚类现象,为优先开展化学探针开发、系统探索可成药空间提供了新的策略方向。
1 引言
配体结合位点是蛋白质中与多肽或有机小分子等生物化学实体发生相互作用的区域,这一结合过程最终会对蛋白功能产生选择性调控。在传统药物研发中,一项极为成功的策略是基于结合位点的高分辨率三维结构,寻找能够激活或抑制与疾病相关蛋白的小分子。随着Protein Data Bank中蛋白质结构数量的持续增长,基于结构的方法已成为药物研发早期阶段的重要计算框架。通过聚焦配体结合位点,这类策略能够实现药物的理性设计与优化,并降低进入临床试验阶段化合物的失败概率。蛋白质—小分子对接是最常用的结构基础策略之一,其目标是在受体结合位点中预测给定配体的最优空间位置与构象。分子对接已成功应用于蛋白质组规模的研究,如逆向筛选,但由于评分函数具有明显的靶标依赖性,难以在不同蛋白或蛋白家族之间直接比较对接结果,构建通用对接评分函数仍然是一项挑战。因此,在全蛋白质组分析中,常采用逆向药效团筛选、结合位点相似性评估或相互作用指纹比较等替代策略。
多数此类方法要求以机器可读的形式对蛋白结合位点进行精细表征,从而为计算分析提供基础,这也使得借鉴相关领域的特征化技术成为可能。在化学信息学中,以编码拓扑或理化性质的数值向量表征小分子是一种常见策略,并构成基于小分子相似性原则的诸多药物发现项目的基础。同样,也可为蛋白等大分子构建描述符,通常基于氨基酸序列提取特征。然而,相比仅依赖序列信息,利用结构数据构建蛋白描述符提供了互补视角,更具潜力。蛋白质与配体之间的生物物理相互作用通常发生在蛋白表面的特定区域,即结合位点,并涉及有限数量的关键残基,因此推动了以这些区域为核心的结构基础蛋白描述符的发展。
口袋描述符通常依据其采用的结合位点表示方式进行分类,例如基于结合位点残基的方法FuzCav与SiteAlign,基于口袋表面表示的方法MaSIF,以及基于与已结合配体或探针显式相互作用的方法KRIPO、TIFP和BioGPS。随着深度学习在药物发现领域的兴起,数据驱动方法也被引入,通过借鉴计算机视觉技术构建口袋描述符,例如DeeplyTough与BindSiteS-CNN。除对结合位点本身进行表征外,口袋描述符还为结合位点相似性评估提供了高效手段,使得相似性比较可简化为向量间距离计算。结合位点比较即口袋匹配,已成为突破“单一药物—单一靶点—单一疾病”范式的重要方法,可用于分析多靶点结合等复杂情形。结合位点相似性在评估配体多靶性和预测蛋白功能方面发挥重要作用,即使在缺乏序列或折叠相似性的蛋白之间,也可识别出相似结合位点。该策略在药物再利用、多药理研究以及潜在远程脱靶预测中均取得成果。
将口袋编码为数值描述符还可将其纳入统一向量框架,与以相同格式表示的小分子、细胞系或疾病等生物化学实体进行整合。例如,在化学基因组学研究中,常将蛋白描述符与分子指纹结合,形成蛋白化学计量学方法。然而,现有口袋描述符方法存在若干内在局限。其一,许多方法依赖共晶配体以识别关键生物物理相互作用,从而将适用范围限制在全配体结构。其二,部分方法基于人工设计的结合位点表示,参数选择依赖特定数据集,在更广泛场景中表现不佳。此外,一些策略依赖结构比对,虽然有助于揭示相似性的结构基础,但计算成本较高。基于深度学习的方法则面临可解释性不足的问题。长期以来,三维结构数据的匮乏是结构基础药物发现的主要限制因素,但这一局面已发生改变。在高精度蛋白结构预测时代,尤其是AlphaFold2等方法出现之后,大量预测结构已覆盖重要生物体及宏基因组序列来源蛋白,使得几乎所有感兴趣的蛋白序列都可以获得结构表征。在此背景下,口袋描述符的应用为系统刻画完整蛋白质组的结合位点空间提供了可能,类似于分子指纹在小分子化学空间探索中的作用。
为部分克服现有口袋描述符的局限,提出基于“相似口袋结合相似配体”这一假设的方法,即相似口袋在结构基础虚拟筛选中应呈现相似的小分子排序结果。研究表明,在结合化学相似配体的口袋之间,对接评分往往具有更高相关性。因此,可以通过比较对接排序与富集结果来估计结合位点相似性。逆向虚拟筛选,即针对一个查询配体筛选一组靶标,亦被用于区分不同类型的结合位点。基于上述发现,虚拟筛选被视为构建口袋描述符的有前景策略。
在此基础上提出PocketVec方法,该方法基于相似口袋结合相似配体的假设,利用逆向虚拟筛选生成可解释且固定长度的蛋白结合位点描述符。具体而言,在相似口袋之间,小分子优先级排序的相关性应高于不相似口袋。该方法在多个基准数据集上进行了实现与性能评估。此外,结合已结合配体信息与口袋检测算法,对人类蛋白质组中实验解析结构及AlphaFold2预测结构进行了全面分析,系统识别药物结合口袋,并为所有口袋生成PocketVec描述符。最后,利用这些描述符对实验结构与预测结构中的所有口袋进行大规模比较,探索口袋相似性与小分子结合之间的潜在关系,并评估其与序列和结构基础方法的互补性,从而展示其在无关蛋白之间识别和表征相似结合位点方面的潜力。
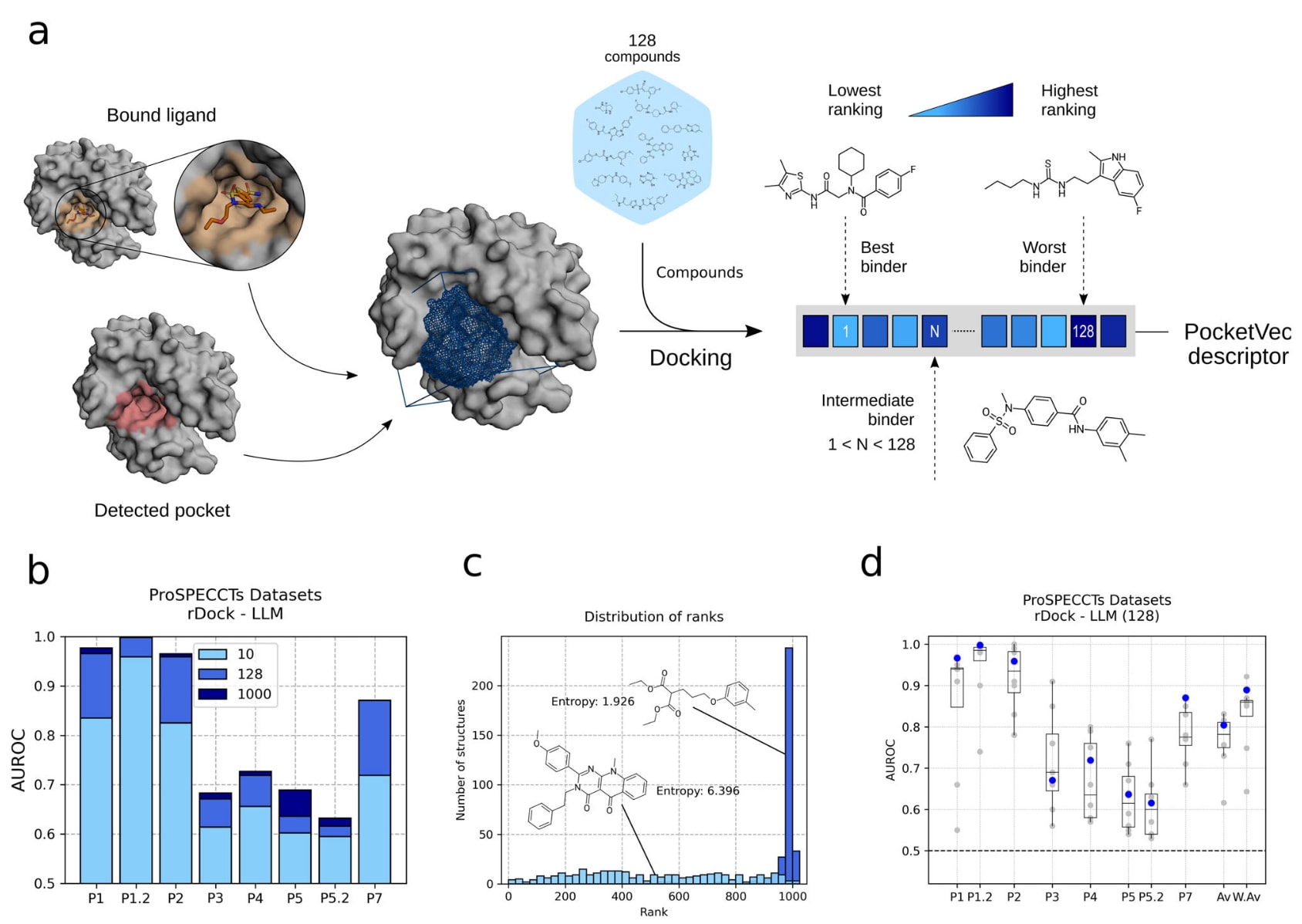
图1|PocketVec方法流程与基准测试结果。 a 给定一个蛋白质三维结构后,通过已结合配体的存在或利用口袋检测算法确定结合位点位置。随后,将预定义的小分子集合在标准PocketVec流程中为128个类先导分子对目标口袋进行对接。对应的对接评分被转换为排序结果,并以向量形式存储,用于表征该口袋。这些向量被称为PocketVec描述符。b 柱状图展示在ProSPECCTs各数据集上的性能表现,纵轴为AUROC,横轴为数据集编号,其中P6和P6.2未包含在内,具体说明参见方法部分BenchmarkSet。柱状颜色表示预定义分子数量,分别为10个、128个以及完整的1000个类先导分子集合,分子按熵值排序。这些结果对应于rDock刚性对接与类先导分子组合。其他所有分子数量组合的结果见图S7。c 高熵与低熵预定义分子示例。直方图展示在ProSPECCTsP1数据集中,最高熵类先导分子与最低熵类先导分子的排序分布情况,纵轴为分布频数,横轴为排序区间,分箱宽度为25。天空蓝表示高熵分子,深蓝表示低熵分子。图中同时给出相应分子的化学结构及对应熵值。d 不同口袋描述符在ProSPECCTs数据集上的性能比较,纵轴为AUROC,横轴为数据集编号,P6和P6.2未包含。灰色点表示现有口袋描述符策略的单独性能结果,共8种方法,详见表S1。箱线图显示中位数、25百分位数与75百分位数以及1.5倍四分位距范围内的最大值与最小值。蓝色点表示PocketVec描述符在128个类先导分子与rDock刚性对接条件下的性能。Av.表示各方法在所有ProSPECCTs数据集上的平均性能,W.Av.表示根据各数据集中样本对数量加权后的平均性能。原始数据见SourceData文件。
2 结果
已有研究表明,相似蛋白往往结合相似配体,这一原则构成了众多药物发现项目的理论基础。对该原则进行了重新评估,结果显示,来自同一蛋白家族的成员例如GPCR家族,通常具有更为相似的活性化合物,而不同家族蛋白之间的活性化合物相似性则较低。然而,即便在整体结构上差异较大的蛋白,只要其可成药口袋在理化性质与形状特征上相似,仍可能结合相似的配体。这一现象将化学生物组学原则进一步精细化为更具普适性的表述,即相似口袋结合相似配体。
PocketVec正是基于这一观察构建,用于生成向量化的蛋白小分子结合口袋描述符。与直接刻画蛋白腔体的形状和理化环境不同,该方法依赖预定义的小分子集合,并评估这些分子与特定口袋的潜在结合能力。具体而言,在获得蛋白三维结构后,首先识别可能具有可成药性的口袋,随后利用计算对接策略评估预定义小分子与该口袋的结合潜力。对接评分被转换为排序结果,并最终以向量形式存储。向量中的每一位对应一个预定义分子的排序位置,反映该分子相对于其他分子在目标口袋中的结合优劣。这一思想在概念上较为直接,但在具体实施过程中,需要对所使用的小分子集合、对接方法及基准评估策略进行系统优化。以下部分对各步骤的评估与优化过程进行说明。
2.1 方法流程的选择
为确定构建结合口袋描述符的最佳化合物集合,测试了两类不同分子。一类为Glide提供的化学多样性片段集合,包含667个分子,分子量范围为50–200g·mol⁻¹;另一类为从MOE v2019.01数据集中筛选的1000个类先导分子,其分子量范围为200–450g·mol⁻¹。此外,还评估了两种成熟的小分子对接策略,分别为rDock和SMINA,前者用于刚性对接,后者用于柔性对接,均采用默认参数。
为确定小分子集合与对接方法的最佳组合,采用了ProSPECCTs基准数据集进行评估。ProSPECCTs是一套专门用于评价口袋比较方法性能的数据集合,涵盖多种不同情境。该集合包含10个数据集,由蛋白—配体结合位点对组成,并依据不同标准划分为相似或不相似类别,包括同一蛋白的不同结构、含有人工突变结合位点的蛋白以及能够结合化学相似配体的无关蛋白对等。
方法流程的详细描述可参见“化合物集合选择”“小分子对接策略”及“对接后分析”等方法部分。
2.2 PocketVec参数选择与基准评估
针对每个ProSPECCTs数据集,均为所有由配体定义的蛋白结合位点生成PocketVec描述符,并通过描述符之间的余弦距离评估口袋相似性。PocketVec距离越小,表示口袋相似性越高。
首先比较了所有对接策略与化合物集合的组合,包括rDock刚性对接与SMINA柔性对接,以及1000个类先导分子与667个片段分子。结果显示,整体而言,类先导分子结合rDock刚性对接表现优于其他组合。对接评分为正值的情况代表分子无法合理嵌入口袋,这类异常排序在片段集合中较为少见,但在类先导分子集合中更为频繁,约35%的结构在rDock与类先导分子组合下至少出现一个异常分子。这表明类先导分子在区分口袋尺寸方面具有更强能力,并在所有ProSPECCTs口袋中产生更高的排序多样性。类先导分子往往能够覆盖更大比例的结合位点,而刚性对接有助于减少同一配体不同构象导致的排序噪声,从而整体提升rDock与类先导分子组合的判别能力。
基准结果还显示,部分分子在所有情境下均被系统性地评为弱结合体,对口袋相似性评估贡献有限。实践中发现,约100–200个分子即可在多数数据集中获得具有竞争力的性能。因此,为优化预定义分子集合,选取在所有ProSPECCTs数据集中具有较高排序多样性的类先导分子与片段分子。具体方法为计算每个分子在各数据集中的Shannon熵,经数据集内归一化后得到平均熵值,并优先保留熵值较高的分子,即排序多样性较高的分子。使用排序多样性最高的128个分子所得性能与使用完整集合时相近。
将对接分子数量从1000或667减少至128,不仅缩短了描述符长度,使其更便于与其他小分子和生物描述符整合,也显著降低了整体计算成本。低熵与高熵类先导分子的示例见图示结果。
综合基准评估结果,最终确定采用rDock刚性对接结合128个类先导分子作为生成PocketVec描述符的标准方法。后续所有分析均基于该策略进行。所选类先导分子可在相关代码仓库中以SMILES和SDF格式获取,并附有商业名称信息。
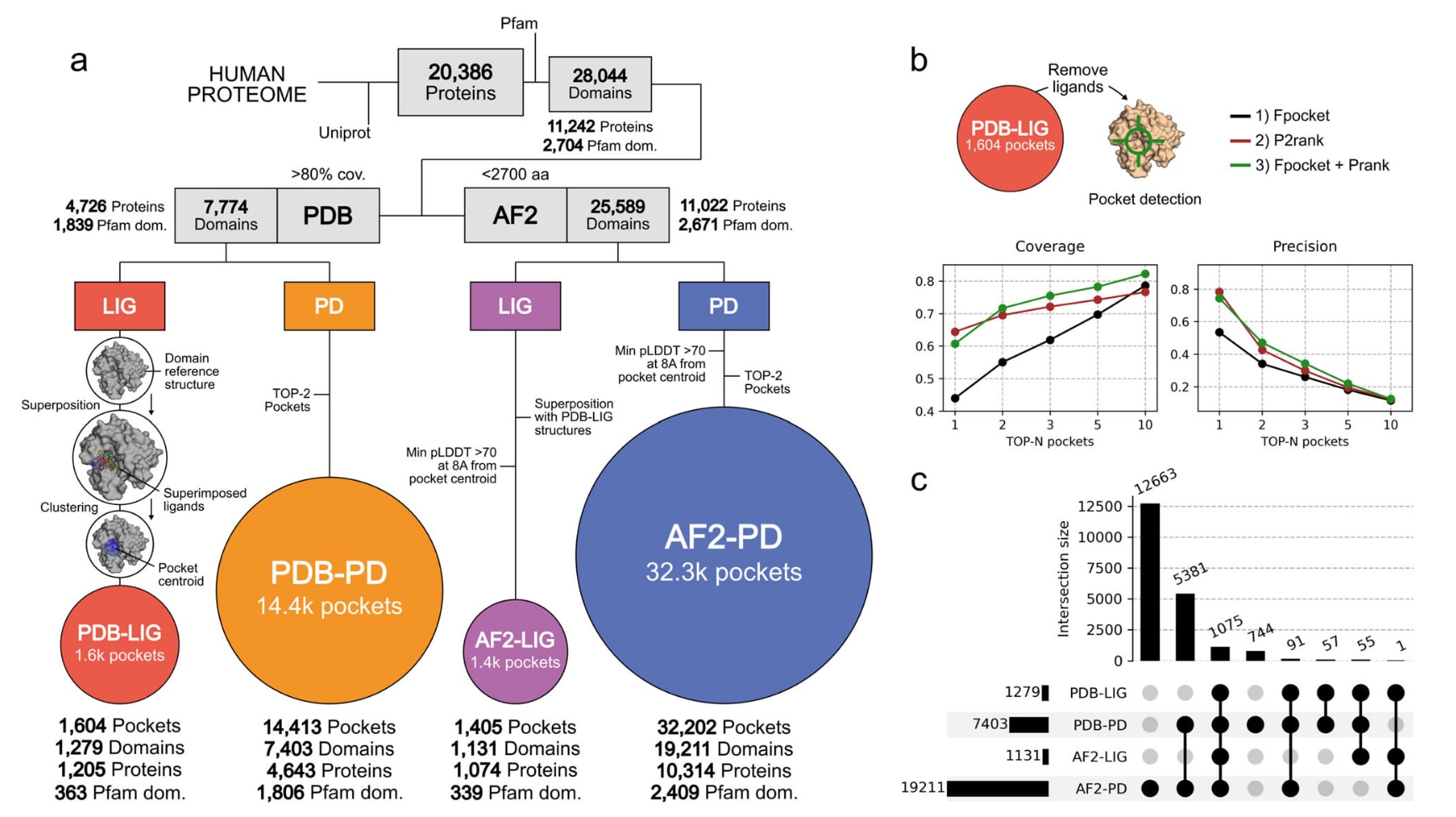
图2|在人类蛋白结构域中为所有可成药口袋生成PocketVec描述符。 a 用于收集人类蛋白Pfam结构域中所有可用可成药口袋结构数据的计算流程。以UniProt中定义的完整人类蛋白质组为起点,首先在实验解析结构即Protein Data Bank以及AlphaFold2预测模型中识别Pfam结构域。在PDB结构中,基于共晶配体的位置在全配体结构域中定义口袋,共得到1604个PDB-LIG口袋;在无配体结构域中则利用口袋检测算法识别口袋,共得到14413个PDB-PD口袋。在AF2预测结构中,通过将PDB-LIG口袋的位置直接叠加定义基于配体的口袋,共得到1405个AF2-LIG口袋;同时利用口袋检测算法在AF2模型中预测口袋,共识别出32202个AF2-PD口袋。关于该流程的更多细节可参见正文及方法部分“基于结构域的人类可成药口袋表征”。b 三种口袋检测策略的基准测试结果,包括Fpocket、P2rank以及两者组合。首先从参考PDB结构即PDB-LIG中移除已结合配体,然后评估上述方法在无配体结构中检测真实口袋的能力。下方图示展示覆盖率与精确率随每个结构域所考虑的最佳评分口袋数量变化的趋势。覆盖率表示真实口袋中被成功检测到的比例,精确率表示被检测口袋中真实口袋的比例。评估时分别考虑每个结构域中得分最高的1个、2个、3个、5个和10个预测口袋。c UpSet图展示不同口袋集合之间结构域的交集情况,其中PDB-LIG包含1279个结构域,PDB-PD包含7403个结构域,AF2-LIG包含1131个结构域,AF2-PD包含19211个结构域。原始数据见SourceData文件。
2.3 PocketVec在ProSPECCTs基准数据集上的性能表现
PocketVec描述符在ProSPECCTs各数据集上的性能以AUROC衡量,结果见图1d。在不同晶体配体定义同一口袋的情况下,PocketVec表现出较强鲁棒性,例如在P1数据集中AUROC为0.97。当进一步将定义限制为化学结构相似的配体时,性能达到最高,在P1.2数据集中AUROC为1.00。类似地,在蛋白构象变化即蛋白柔性影响的情境下,PocketVec同样保持稳定性能,在P2数据集中AUROC为0.96。此外,该方法能够区分完全相同的口袋与经5个人工突变后发生理化性质及形状变化的口袋。对于这类更具挑战性的情况,性能相对适中,在P3即仅理化性质变化条件下AUROC为0.67,在P4即同时包含理化和形状变化条件下AUROC为0.72。
进一步分析发现,人工突变数量从1个增加至5个时,对应AUROC值呈显著正相关,在P3和P4数据集中Pearson相关系数均大于0.98,p值小于0.005。这一结果表明,结合位点中突变数量增加时,PocketVec描述符对差异的识别能力同步增强。
在更具生物学意义的情境中,例如结构上差异较大的蛋白却结合相似小分子的情况,也对方法进行了测试。ProSPECCTs中P5与P7两个数据集专门用于评估此类情境。P5包含9类不同配体类别的口袋结构,如HEM、ATP、NAD等;P7则包含文献报道的真实相似结合位点对,其中部分来自结构无关的蛋白。在这两个数据集中,PocketVec分别获得0.64和0.87的AUROC,显示其能够在整体结构不相似的蛋白之间识别出相似口袋。
需要指出的是,即便两个结合位点具有相同或化学相似的晶体配体,从PocketVec角度看也未必被判定为相似。这一逻辑类似于相似性集合方法SEA,即通过比较靶标所结合配体集合的整体化学相似性进行定量评估。若两个靶标仅共享一个活性化合物,通常不足以被判定为显著相似。
为确定PocketVec距离阈值以将口袋对划分为相似或不相似,对不同截断值下的Matthew相关系数MCC进行了系统分析。结果显示,不同数据集对最佳阈值的要求不同。例如,在突变相关基准测试P3与P4中,最佳阈值约为0.13;而在文献报道的真实相似口袋数据集P7中,最佳阈值更低,约为0.08。为兼顾一般应用并尽量减少假阴性,最终基于P1数据集确定阈值。该数据集中,相似对定义为相同口袋结合化学不同配体,不相似对定义为无关口袋结合不同配体。MCC最大时对应的距离值为0.17,因此将0.17设定为PocketVec的推荐阈值。该阈值不应视为绝对标准,而是用于区分口袋相似性的通用参考。
为完整起见,还评估了不同对接方法包括rDock刚性对接与SMINA柔性对接,以及不同规模的化合物子集包括128个类先导分子和128个片段分子组合。结果表明,rDock结合128个类先导分子仍是最佳策略。此外,选取在不同口袋间排序结果变化最大的高熵分子,有助于区分P1数据集中的相似与不相似口袋。这一效果在片段分子中更加明显,因为其分子复杂度与分子量较低,易产生较高的多靶性与冗余性。所有ProSPECCTs数据集的ROC曲线、PR曲线以及PocketVec距离分布、对接评分与口袋体积分布等详细结果均可在相关代码仓库中获取。
2.4 与现有方法的比较
随后将PocketVec与当前主流方法进行了比较。相关研究已在文献中对多种口袋比较工具基于ProSPECCTs数据集进行了基准测试,其中包括六种基于口袋描述符的策略。为保证可比性,采用AUROC作为统一性能指标。同时,还为PocketVec提供了各数据集中精确率、准确率、灵敏度、特异性、Matthew相关系数以及F1分数等指标。
总体而言,在加权平均性能指标下,PocketVec以0.89的加权平均值位列第二,在除P3外的所有ProSPECCTs数据集中均超过中位数与平均性能。性能排名第一的方法为SiteAlign,该方法依赖结构比对,通过将残基描述符投影至三角离散化球面,并通过移动一个结合位点以最小化腔体指纹之间的距离来量化相似性。由于其专门用于成对比较口袋,并不为每个结合位点生成唯一描述符,因此不利于像分子指纹那样对口袋空间进行系统探索。
其他方法例如KRIPO、TIFP、DeeplyTough和BindSiteS-CNN在部分数据集中与PocketVec表现接近,但往往依赖训练数据,并生成难以解释的嵌入表示。综合来看,PocketVec是一种快速且性能稳定的口袋描述符生成策略,在克服现有方法局限性的同时,在口袋相似性评估方面优于大多数现有方法。
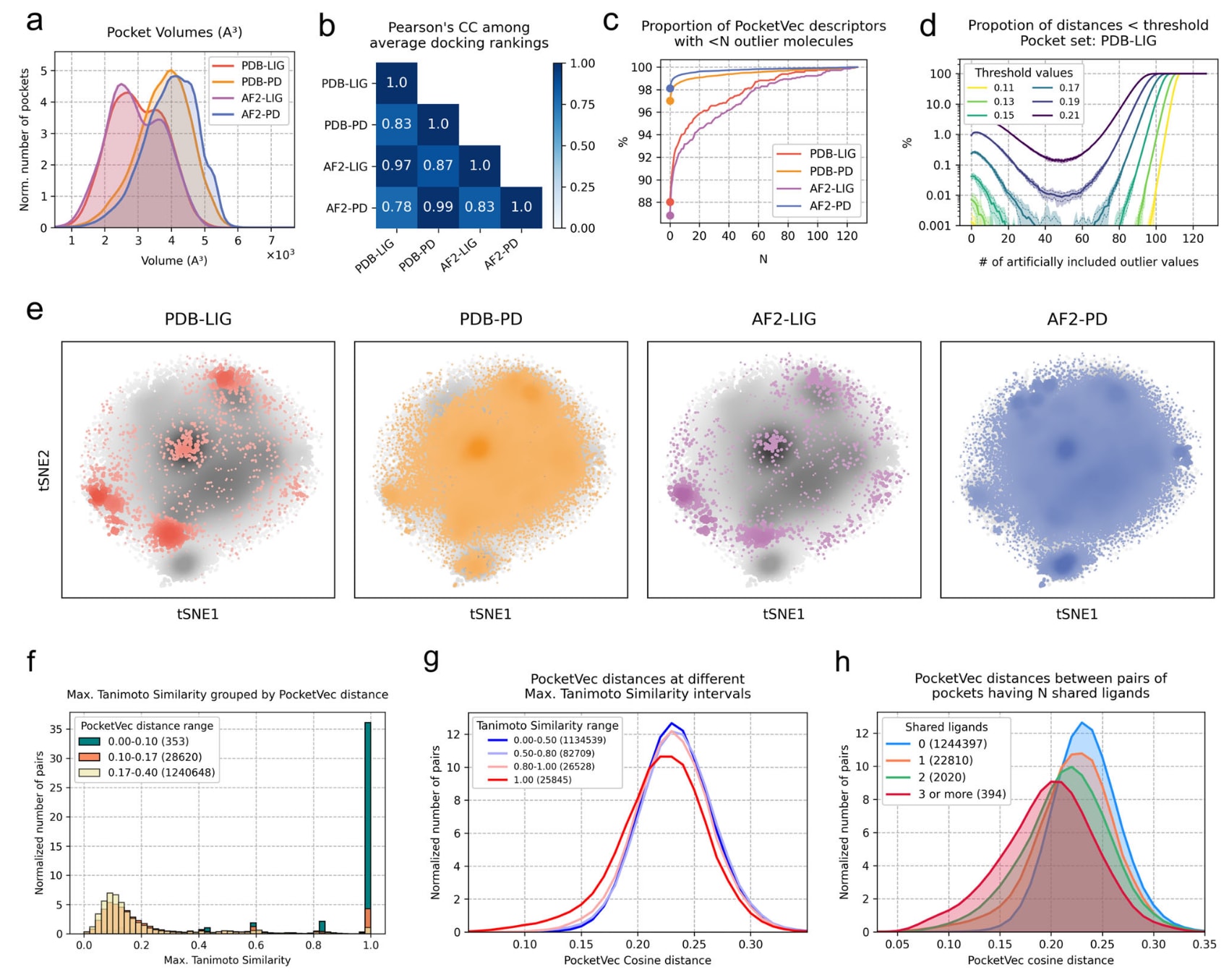
图3|利用PocketVec描述符对人类可成药口袋进行表征。 a 各口袋集合体积分布的归一化分布情况,纵轴为分布密度,横轴为体积,单位为×10³Å³。四类口袋集合分别为PDB-LIG共1604个口袋、PDB-PD共14413个口袋、AF2-LIG共1405个口袋以及AF2-PD共32302个口袋。对应的平均体积分别为2992.88ų、3764.1ų、2940.47ų和3972.66ų。口袋体积通过rDock中的CAVITY功能直接计算得到。b 各口袋集合之间平均对接排序的Pearson相关系数。所有10组比较的p值均小于
2.5 人类蛋白质组中可成药口袋的全面表征
PocketVec描述符为大规模且多样化的小分子结合位点包括apo与holo结构提供了统一的表征框架,使得在完整蛋白质组范围内系统探索口袋空间成为可能。基于这一目标,构建了一套计算流程,用于为人类蛋白结构域中所有口袋生成PocketVec描述符,流程示意见图2a,详细策略见方法部分“基于结构域的人类可成药口袋表征”。
首先,从UniProt数据库中获取全部20386个人类蛋白序列。为避免处理无序或高度柔性的区域,这类区域通常难以建模且不太可能包含可成药口袋,仅保留Pfam定义的自主结构单元即结构域。最终共保留28044个结构域,涵盖11242个人类蛋白,对应2704个唯一Pfam结构域。
随后对这些结构域进行结构注释,采用两种策略。一方面,通过检索Protein Data Bank中的实验解析结构,为7774个结构域找到至少一个PDB结构,涉及4726个蛋白和1839个唯一Pfam结构域。另一方面,从AlphaFold Protein Structure Database下载全部人类预测结构模型,为25589个结构域获得结构模型,涉及11022个蛋白和2671个唯一Pfam结构域。
关于是否应对AlphaFold2模型进行分子动力学精修以用于对接实验,学界仍存在讨论。但多数研究认为,AlphaFold2模型在对接实验中的准确性与实验解析的apo结构相当。近期研究亦显示,在使用PDB结构或AlphaFold2模型进行小分子对接时,实验验证成功率并无显著差异。
接下来针对每个结构域识别潜在可成药口袋,同样采用两种策略。第一种为基于配体的口袋定义方法,即检索与结构域共晶的小分子,并将满足以下条件的结合位点定义为可成药口袋:一是在PDBSUM中有相关注释;二不是20种天然氨基酸之一;三含有超过6个碳原子以排除溶剂及晶体相关分子;四溶剂可及性≤0.4或埋藏度≥15。共在1279个结构域中找到至少一个符合条件的小分子,涉及1205个蛋白和363个唯一Pfam结构域。其中503个结构域仅包含1个符合条件的配体,而254个结构域包含10个及以上配体。
为构建唯一的配体定义口袋集合,为每个结构域选择一个参考PDB结构,并将所有包含结合配体的结构叠加至参考结构。采用单链接聚类方法,将质心距离≤5Å且全局聚类质心与各分子质心之间最大距离≤18Å的配体归为同一口袋,最终聚类质心定义为口袋质心。最终共识别出1604个配体定义口袋,分布于1279个结构域中,涉及363个唯一Pfam结构域和1205个蛋白,该集合命名为PDB-LIG。
为将相同标准应用于AlphaFold2结构模型,将参考PDB结构叠加至对应的AF2模型,并转移已识别PDB-LIG口袋的位置。仅保留在距口袋质心≤8Å范围内所有残基pLDDT值均大于70的口袋。最终在1131个结构域中识别出1405个口袋,涉及339个唯一Pfam结构域和1074个蛋白,该集合命名为AF2-LIG。
作为补充策略并提升整体覆盖率,还尝试从头预测可成药口袋。为确定最佳预测策略,首先在移除共晶配体后的参考holo结构上,使用Fpocket进行口袋检测,并利用P2rank进行评分,以评估其对已定义PDB-LIG口袋的识别能力。基准测试显示,Fpocket用于检测结合位点、P2rank用于评分的组合效果最佳。当每个结构域保留评分最高的前2个预测口袋时,可检测到72%的真实口袋,同时预测口袋中有47%为真实口袋,分别对应覆盖率与精确率。
因此,在PDB参考结构上对每个结构域运行Fpocket进行口袋检测,并通过P2rank排序后保留前2个口袋。最终在7403个结构域中预测得到14413个口袋,涉及4643个蛋白和1806个唯一Pfam结构域,该集合命名为PDB-PD。
随后在AlphaFold2预测结构域模型上采用相同策略与标准,共识别出32202个口袋,分布于19211个结构域中,涉及10314个蛋白和2409个唯一Pfam结构域,该集合命名为AF2-PD。
2.6 可成药口袋检测的鲁棒性
通过对人类蛋白结构域进行结构注释并结合配体定义与从头预测两种策略,共汇总得到1604个PDB-LIG口袋、1405个AF2-LIG口袋、14413个PDB-PD口袋以及32202个AF2-PD口袋,总计覆盖20067个结构域。由此可以看出,从头预测方法具有显著的补充价值。在18788个结构域即93.6%的结构域中,所有口袋均仅通过口袋检测策略识别得到,其中12663个结构域即63.1%仅在AF2模型中检测到口袋。
在对1000个PDB-PD结构域子集进行方法学鲁棒性评估时发现,在对结构进行平移与旋转后,预测结果存在轻微差异。这一现象在PDB结构与AF2模型中表现一致。在考虑每个结构域得分最高的前2个口袋时,仅约85%与86%的预测口袋在旋转与平移后仍被一致识别。然而,在无论初始取向如何均能稳定识别的口袋中,其评分表现高度一致,在PDB结构与AF2模型中的Pearson相关系数均约为0.98。
进一步比较PDB与AF2结构中检测到的口袋一致性,发现相对于参考PDB结构,仅约59%与49%的预测口袋分别在PDB与AF2结构中被一致识别。尽管如此,在同时在PDB与AF2结构中被识别的口袋中,评分仍具有较好的稳健性,其Pearson相关系数在PDB结构中约为0.88,在AF2模型中约为0.62。
此外,还比较了真实即基于配体定义的口袋与预测即通过检测得到的口袋在理化性质方面的差异,包括体积与埋藏度等指标。结果显示,较为显著的差异体现在体积方面,真实口袋平均体积约为3000ų,而预测口袋平均体积约为3800ų。埋藏度分析亦得到一致结论,因为口袋体积与埋藏度之间存在负相关关系。
总体而言,这些结果揭示了口袋检测策略的一些局限性,包括对初始结构取向的轻微敏感性、对结构差异的依赖性较强,以及预测口袋在理化性质例如体积方面可能偏离已知真实口袋的特征。
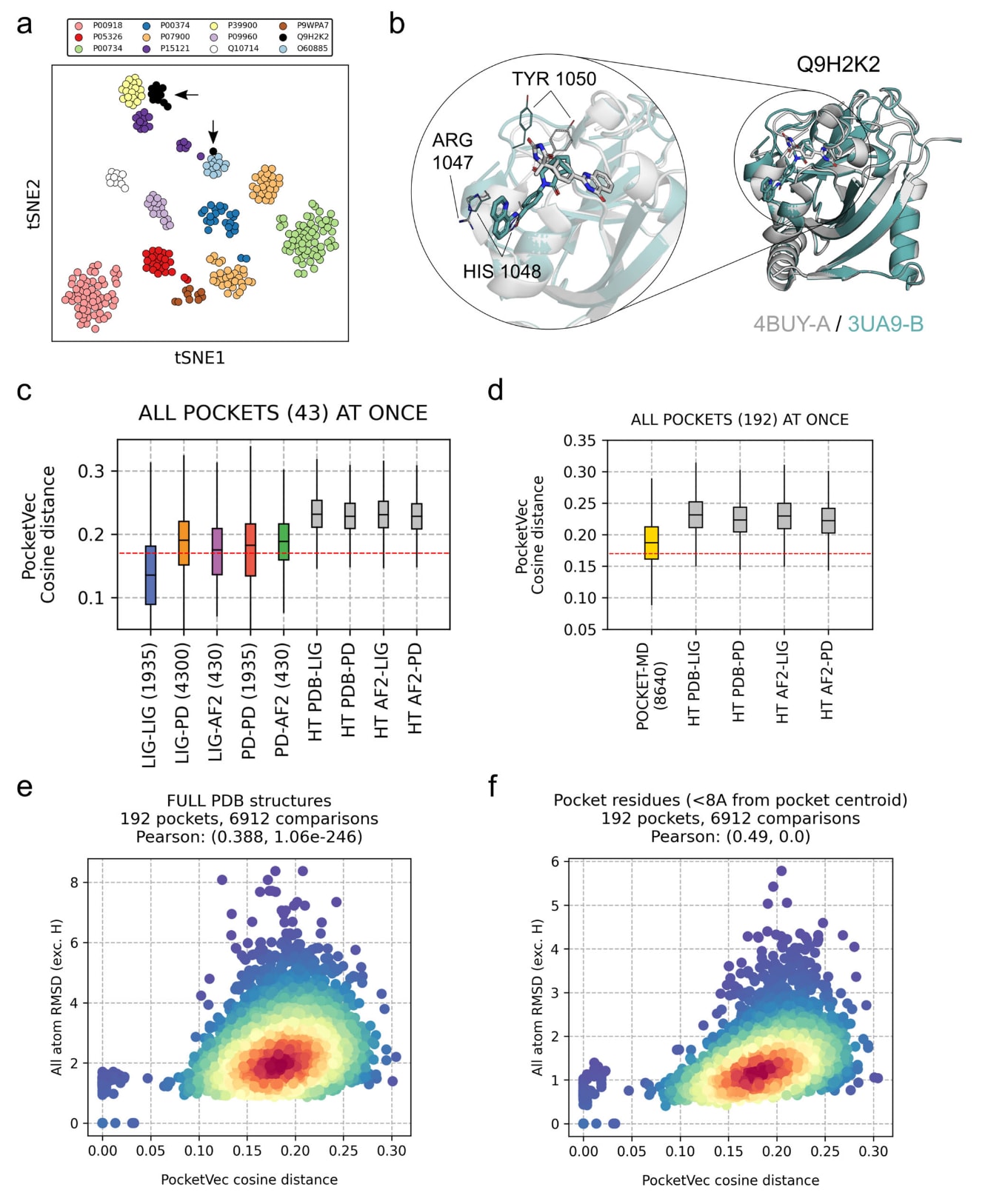
图4|蛋白柔性影响的评估。 a 326个PocketVec描述符的二维tSNE表示,这些描述符对应12个结合不同配体的口袋构象集合,来源于ProSPECCTsP1数据集。黑色箭头标示Poly-ADP polymerase tankyrase-2相关结构。b 使用TM-align对4BUY_A白色结构与3UA9_B青绿色结构进行结构叠合的结果。c 蛋白柔性与构象变化引起的PocketVec描述符变异性。每个箱线图表示同一口袋在不同结构比较情境下的PocketVec距离分布,包括i)holoPDB结构之间LIG-LIG共1935对,ii)holo与apoPDB结构之间LIG-PD共4300对,iii)holoPDB与AF2结构之间LIG-AF2共430对,iv)apoPDB结构之间PD-PD共1935对,v)apoPDB与AF2结构之间PD-AF2共430对。此外,还比较holoLIG、apoPD及AF2结构与研究中预先生成的四类PocketVec描述符集合即PDB-LIG、PDB-PD、AF2-LIG及AF2-PD之间的距离分布,样本数分别为1439382、12974304、1255170及29039577。箱线图显示中位数、25百分位数与75百分位数以及1.5倍四分位距范围内的最大与最小值。d 分子动力学模拟结构所导致的PocketVec描述符变异性。POCKET-MD表示同一口袋不同MD构象之间的距离共8640对,其余箱线图表示这些MD来源描述符与预先计算的四类PocketVec集合之间的距离分布,样本数分别为3060480、27586560、2668800及61745280。箱线图表示方式同上。e PocketVec余弦距离与全原子RMSD不含氢原子之间的相关性,横轴为PocketVec距离,纵轴为全结构RMSD。f PocketVec余弦距离与仅口袋残基RMSD之间的相关性。分析涉及192个口袋,其中8个来自PDB-LIG,184个来自PDB-PD,均包含MD模拟数据每个重复3帧共3个重复。两图均以密度着色表示,颜色越红表示密度越高。原始数据见SourceData文件。
2.7 PocketVec描述符的系统化生成
在通过四种不同策略识别人类可成药口袋后,按照既定流程为所有口袋系统生成了PocketVec描述符。大规模口袋集合使得可以全面分析构建描述符所用类先导分子与口袋表征之间的潜在依赖关系。结果显示,对接排序与分子性质如分子量或重原子数之间不存在显著相关性。相反,多数分子在不同口袋中的排序覆盖完整范围1至128,但排序分布也表明部分分子在多数口袋中倾向于获得较好评分,而另一些分子则多被排在较后位置。这一趋势在所有口袋定义策略中均一致存在,并且不同口袋集合之间类先导分子的平均对接排序呈显著相关。PDB与AF2结构生成的PocketVec描述符之间表现出高度一致性,但LIG与PD两类口袋之间存在一定差异,Pearson相关系数低于0.88。
进一步分析发现,在PDB-LIG与AF2-LIG集合中,分别有88.0%与86.8%的PocketVec描述符不包含任何对接评分为正的异常分子,而在PDB-PD与AF2-PD集合中该比例分别达到97.0%与98.1%。这一结果与口袋体积差异一致。较小口袋体积小于3000ų时更容易出现异常分子,在所有口袋集合中Fisher精确检验结果显示OR大于70,p值小于
为评估异常分子是否会显著影响PocketVec描述符质量,随机向描述符中插入异常值,并计算原本不相似的口袋对即距离大于0.17是否因异常值增加而被误判为相似即距离小于0.17。结果显示,即便插入多达80个异常分子,在128个分子中所占比例极高,假阳性率仍仅约0.039%。因此,在后续分析中仅剔除异常分子超过80个的极少数描述符,分别为PDB-LIG10个、PDB-PD45个、AF2-LIG15个以及AF2-PD43个。
2.8 蛋白柔性对PocketVec描述符的影响
蛋白质是动态分子,其三维构象会受到环境因素如配体结合影响,并表现出侧链柔性。因此,单一X射线结构难以全面反映蛋白整体构象行为,单个PocketVec描述符更应被视为特定结构状态下的快照。ProSPECCTs基准数据集已部分评估描述符对结合位点定义变化即同一口袋结合不同配体以及蛋白柔性影响的敏感性。结果表明,同一口袋不同结构之间的描述符变异明显低于随机口袋对,AUROC达到0.97,对应距离小于0.17,而不相似口袋对仅有1.2%的距离低于该阈值。
在比较holo结构与对应apo结构或AF2模型时,PocketVec描述符表现出更高变异性,反映出无配体结构的构象异质性。然而,holo与apo结构以及holo与AF2模型之间的距离分布相近,分别有51%与55%的口袋对距离低于0.17阈值。
为进一步系统评估蛋白柔性与构象变化的影响,从PDB-LIG集合中筛选具有不少于10个holo与10个apo结构且拥有高置信度AF2模型的口袋,共获得43个唯一口袋对应903个描述符。分别计算同一口袋holo与holo、holo与apo、apo与apo、holo与AF2以及apo与AF2之间的PocketVec距离,并与预编译描述符背景分布进行比较。结果显示,holo结构之间的描述符具有较高一致性,AUROC为0.90。holo与apo之间以及apo与apo之间AUROC分别为0.77与0.80,反映出无配体结构带来的额外变异。值得注意的是,holo与AF2结构之间的相似性高于holo与apo结构之间,AUROC为0.82,这与多项研究结论一致,即AF2预测结构在构象上与apo结构相当,甚至在一定程度上更接近holo结构。
此外,还对来自PDB-LIG与PDB-PD集合的192个口袋进行分子动力学模拟,每个口袋采样10个构象,并计算所有构象之间的PocketVec距离。结果显示,描述符能够反映蛋白柔性变化,同时仍能识别同一口袋的不同构象,AUROC为0.78。PocketVec距离与全结构RMSD之间呈弱相关,Pearson相关系数为0.39;若仅考虑口袋残基即距口袋质心小于8Å的残基,相关性提升至0.49。
金属离子在许多口袋中对催化或结构稳定具有重要作用,但该研究未显式考虑辅因子或金属离子的存在,以确保在不同结构来源例如PDB与AF2以及不同口袋定义策略之间保持一致性。为评估金属结合蛋白的影响,对所有含金属原子的PDB-LIG与PDB-PD口袋进行分析,并比较包含与不包含金属原子的PocketVec描述符。结果显示,尽管描述符并非完全相同,但大多数金属结合口袋在有无金属原子情况下的描述符仍保持相似,Mann–Whitney检验p值小于
总体而言,PocketVec描述符能够有效捕捉口袋柔性与构象变化,对口袋形状改变具有敏感性,并适用于holo与apo的PDB结构包括金属结合蛋白以及AF2预测模型。
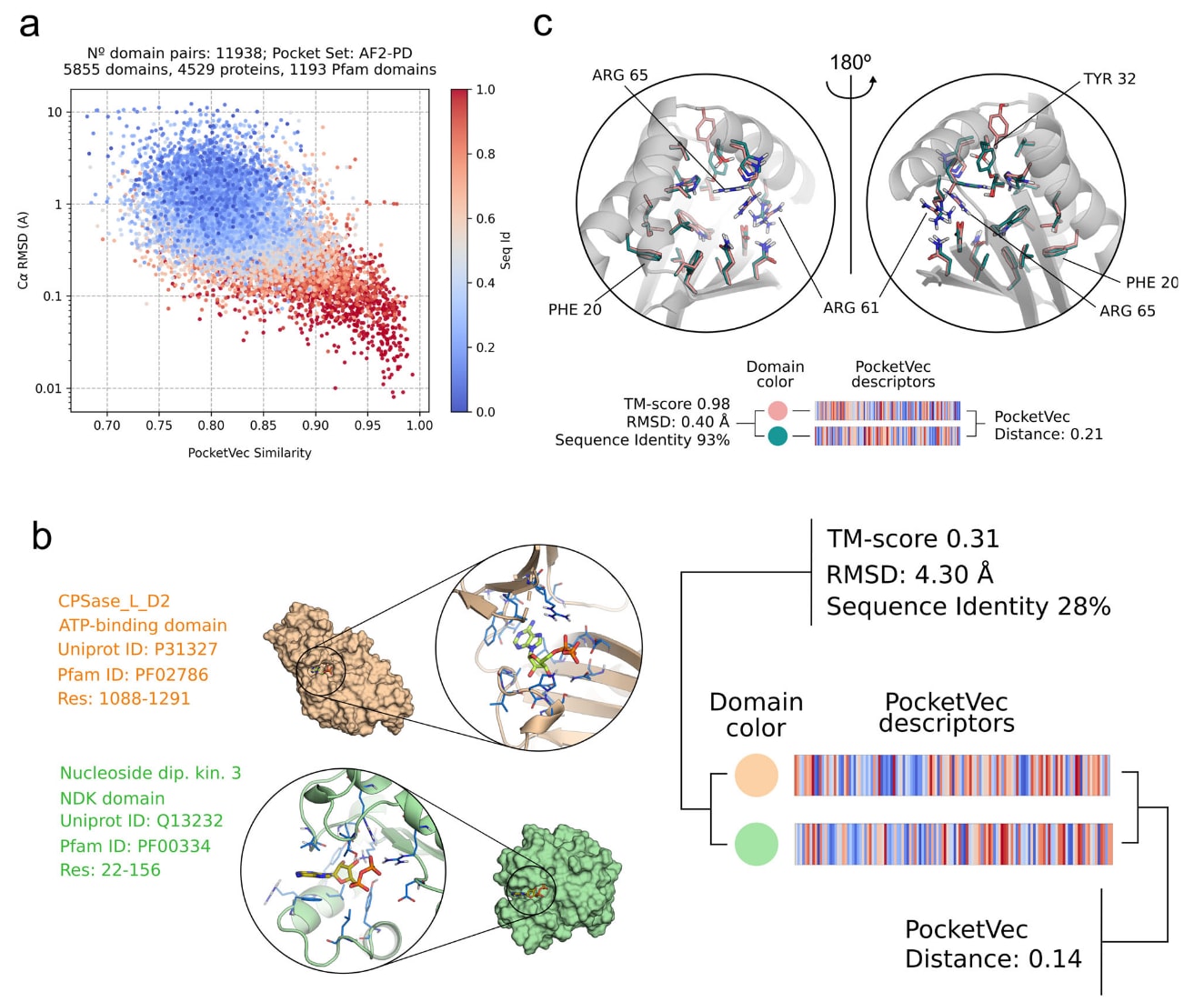
图5|利用PocketVec描述符评估全蛋白质组口袋相似性并获得传统方法难以实现的洞见。 a 在AF2-PD口袋集合中,同一Pfam结构域最多10个口袋之间的PocketVec相似性横轴定义为1减去PocketVec距离、结构相似性纵轴为CαRMSD以及序列一致性颜色编码之间的关系。PocketVec相似性与序列一致性的Pearson相关系数为0.55,p值约为0;PocketVec相似性与RMSD之间的Pearson相关系数为–0.35,p值约为0。b 在结构差异显著的结构域中发现相似口袋。一个口袋位于CPSase_L_D2 ATP-binding domain即Carbamoyl-phosphate synthase蛋白Carbamoyl-phosphate synthase的1088–1291位残基区域,PDB编号5DOU;另一个口袋位于NDK domain即Nucleoside diphosphate kinase 3蛋白Nucleoside diphosphate kinase 3的22–156位残基区域,PDB编号1ZS6。两个口袋均属于PDB-LIG集合,PocketVec距离为0.14低于0.17阈值,尽管两个结构域序列一致性仅为28%,结构相似性较低TM-score为0.31且RMSD为4.3Å。c 在高度相似结构域中发现不相似口袋。两个口袋分别位于NIPSNAP domain结构域中,一个来自Protein NipSnap homolog 3B蛋白Protein NipSnap homolog 3B146–245位残基区域的AF2模型,另一个来自Protein NipSnap homolog 3A蛋白Protein NipSnap homolog 3A146–245位残基区域的AF2模型。前者作为参考结构灰色表示。两个口袋均属于AF2-PD集合,PocketVec距离为0.21高于0.17阈值,尽管结构域序列一致性高达93%,结构相似性亦极高TM-score为0.98且RMSD为0.4Å。原始数据见SourceData文件。
2.9 人类可成药口袋的全局两两比较
PocketVec描述符的向量化特性使其能够通过简单的余弦距离进行快速比较,从而支持蛋白质组范围内的系统性相似性搜索。首先,对所有PocketVec描述符进行t-SNE降维可视化,以直观展示人类口袋空间的整体结构。结果显示,基于共晶配体定义的口袋PDB-LIG与AF2-LIG主要分布在较为明确的区域,而通过口袋检测策略得到的PDB-PD与AF2-PD显著扩展了口袋空间覆盖范围,尤其是AF2模型的引入进一步增强了这一扩展。值得注意的是,PDB-PD与AF2-PD映射中存在若干高密度区域,这些区域目前尚无任何结合化合物的实验结构支持。
随后系统验证了PocketVec构建背后的化学生物组学假设,即相似口袋结合相似配体。对1594个PDB-LIG口袋进行约127万次两两比较,利用ECFP指纹计算已结合配体之间的最大Tanimoto相似性,并按PocketVec余弦距离分组。结果显示,当PocketVec距离小于0.10时,口袋对往往具有更高的配体最大Tanimoto相似性大于0.85;而当距离大于0.17时,这种现象显著减少,Fisher精确检验OR大于90,p值小于
然而,相似配体并不必然意味着相似口袋。总体而言,随着配体最大Tanimoto相似性提高,PocketVec距离并未显著降低。仅在配体几乎完全相同时Tanimoto相似性等于1时,PocketVec距离才略有下降,AUROC为0.59。这一结果与ProSPECCTsP5与P5.2的表现一致,表明单一共同配体不足以形成稳定一致的排序模式。只有当多个配体在两个口袋中系统性获得较高排序时,才会形成相似的PocketVec描述符。这与相似性集合方法SEA的逻辑一致,即共享配体数量越多,靶标间关系越显著。
实际分析显示,在PDB-LIG集合中,共享3个及以上配体的口袋对其PocketVec距离明显更小,AUROC达到0.75;而仅共享1个配体时差异较小,AUROC为0.58。在未共享配体的口袋对中,仅2.1%距离小于0.17,而当共享3个及以上配体时该比例增至26.1%。
考虑到实验数据可能存在配体遗漏,进一步采用纯计算策略验证。对128个标准类先导分子进行刚性对接,并将排名前1%的分子标记为活性。结果显示,127个分子至少在一个口袋中被标记为活性,近20000对口袋共享至少一个活性分子。结果再次确认,共享活性分子越多,PocketVec距离越小,比较无共享与共享3个及以上活性分子的口袋对时AUROC达到0.87。
接下来分析PocketVec与序列及结构相似性的互补关系。在AF2-PD集合中,同一Pfam结构域内的口袋比较显示,PocketVec相似性与序列一致性呈正相关Pearson0.55,与CαRMSD呈负相关Pearson–0.35,p值均小于
在四个口袋集合之间进行全局两两比较,共完成超过12亿次比较,发现超过350万个在序列一致性低于30%且TM-score低于0.35的结构域中仍具有相似口袋即PocketVec距离小于0.17。例如,在CPSase_L_D2ATP结合结构域PF02786的Carbamoyl-phosphate synthase蛋白与NDK结构域的Nucleoside diphosphate kinase3蛋白中发现PocketVec距离为0.14的相似口袋,尽管序列一致性仅28%,TM-score为0.31且RMSD为4.3Å。晶体结构证实两者均可结合ADP,进一步支持相似性判断。
相反,也识别出超过29000对在序列一致性大于40%且TM-score大于0.50情况下仍表现出口袋差异显著即PocketVec距离大于0.20的口袋对。例如,在NIPSNAP结构域PF07978中,ProteinNipSnap homolog3B与ProteinNipSnap homolog3A的AF2模型具有93%序列一致性和0.98的TM-score,但对应口袋的PocketVec距离为0.21,显示明显差异。
2.10 PocketVec相似性与实验确定的化合物—靶标关系
为进一步验证PocketVec识别相似口袋的能力,分析了口袋相似性与实验确定的化合物—靶标关系之间的关联。整合来自ChEMBL与BindingDB的836654个化合物和6933个蛋白靶标数据,并选取具有至少一个已知结合小分子的蛋白对,共评估2055378个蛋白对。由于实验数据未区分具体口袋,因此取每对蛋白之间的最小PocketVec距离作为代表。
结果显示,PocketVec距离越小,共享化合物数量越多;当距离大于等于0.2时,几乎不存在共享化合物的蛋白对。进一步计算不同阈值下的富集倍数,在距离小于等于0.17、0.10与0.05时,共享至少5个化合物的蛋白对分别富集约2倍、50倍与200倍;若共享20个及以上化合物,则富集倍数分别提高至约5倍、300倍与700倍。
为避免不同口袋集合来源带来的偏倚,限制比较为PDB-LIG与其他集合之间,结果趋势保持一致。
此外,在一项包含407个片段分子与5951个蛋白的系统测试数据集中,筛选出301个片段与525个具有PocketVec描述符的蛋白进行分析。尽管样本规模较小约14万蛋白对,但结果同样显示口袋相似的蛋白更可能共享片段分子。在该数据集中,由于片段分子特异性较低,距离小于等于0.17未观察到显著富集;但在距离小于等于0.10与0.05时,共享至少3个片段的蛋白对分别富集约8倍与30倍。
总体而言,这些结果表明,PocketVec距离较低即口袋相似性较高时,蛋白共享相同实验化合物的概率显著增加,从而进一步验证了该方法的有效性。
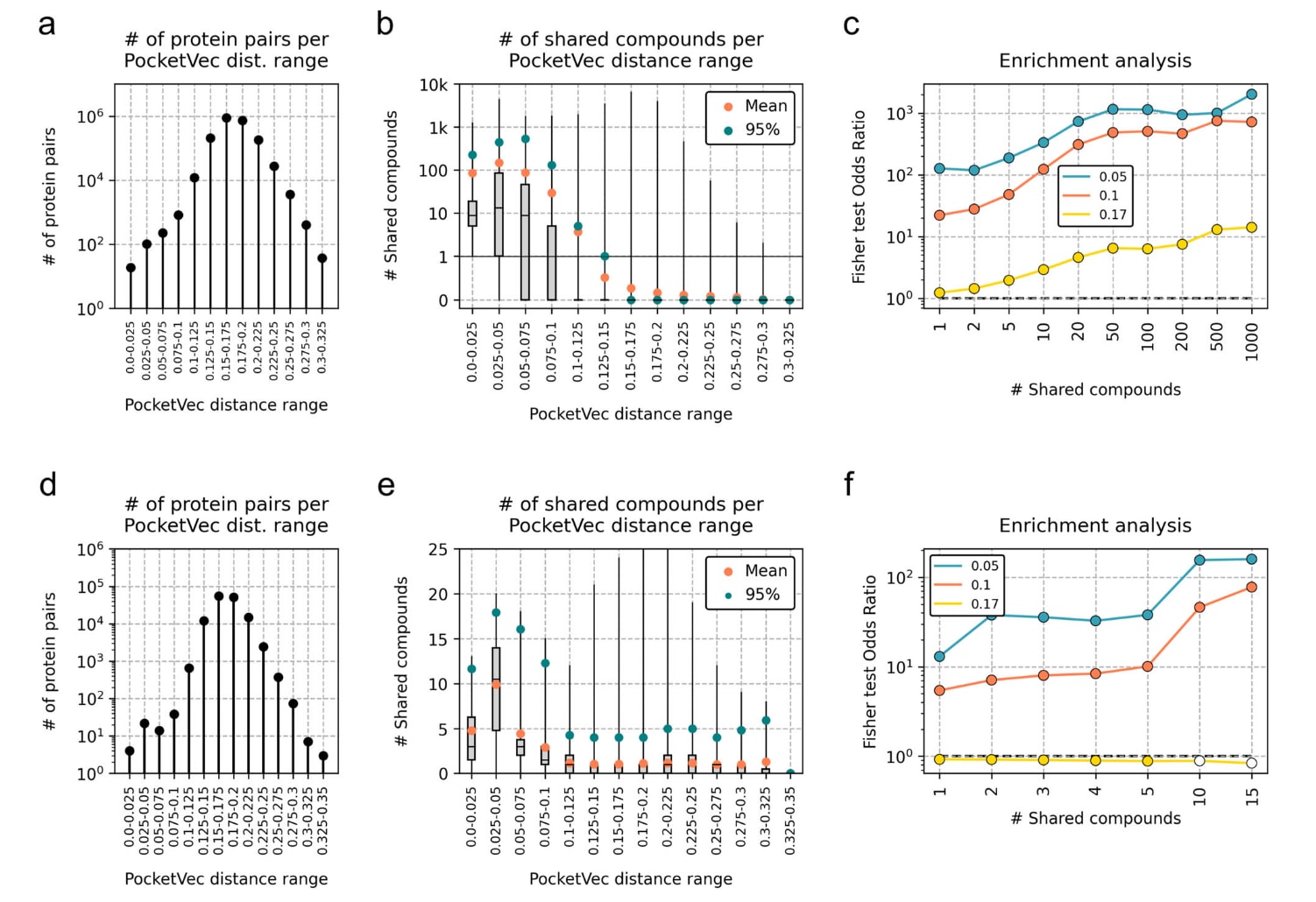
图6|PocketVec相似性与实验确定的化合物—靶标关系之间的关联。 在整合PDB-LIG、PDB-PD、AF2-LIG和AF2-PD四类PocketVec描述符后,进行全局两两比较,分析PocketVec距离与在ChEMBL和BindingDB中具有实验结合数据的蛋白之间共享化合物数量的关系a、b、c以及d、e、f。a、d 各PocketVec距离区间内蛋白对数量纵轴为蛋白对数量,横轴为PocketVec距离区间。b、e 在指定PocketVec距离范围内所有蛋白对之间共享化合物数量的分布。每个箱线图中的数据点数量见图6a和6d。橙色点表示平均值,绿色点表示前5%蛋白对中的下限值。箱线图显示中位数、25百分位数与75百分位数以及最大值和最小值。c、f 在不同PocketVec距离截断值0.05、0.10和0.17下,随着共享化合物数量增加,Fisher双侧检验的优势比OR变化趋势纵轴为OR,横轴为共享化合物数量。彩色点表示p值小于0.001,灰色点表示p值小于0.05,白色点表示p值大于0.05。原始数据见SourceData文件。
2.11 利用PocketVec描述符识别抑制谱相似的激酶
蛋白激酶长期以来一直是药物发现的重要研究对象,主要由于其在肿瘤发生中的关键作用。自2001年伊马替尼获FDA批准以来,截至2022年11月,已有72种小分子激酶抑制剂获批用于临床治疗。然而,由于人类激酶普遍共享高度保守的ATP结合口袋,设计具有高度选择性的抑制剂极具挑战性。许多激酶抑制剂表现出显著的多靶性,而部分则较为选择性。从激酶角度来看亦存在类似差异,一些激酶可被多种抑制剂结合,而另一些则更为专一。
在人类蛋白可成药口袋系统表征中,在蛋白激酶结构域内共识别出1286个潜在结合位点,分别在PDB-LIG、PDB-PD、AF2-LIG与AF2-PD集合中生成了229、404、195与458个PocketVec描述符。基于此,进一步探讨不同激酶口袋与其实验确定的小分子抑制谱之间的相关性。
首先收集系统化化学蛋白质组学研究数据,包括2017年数据集520个激酶与243个抑制剂的测试结果,以及2023年数据集318个激酶与1183个抑制剂的测试结果。采用30nM作为活性阈值构建二元抑制矩阵。在2017年数据集中识别出111个激酶与94个抑制剂之间的相互作用,其中43个激酶仅被单一化合物抑制,18个激酶与5种及以上抑制剂相互作用。2023年数据集中包含73个激酶与164个抑制剂之间的相互作用,其中19个激酶仅与1种抑制剂相互作用,27个与5种及以上抑制剂相互作用。
基于Jaccard相似性比较二元抑制谱发现,仅12.3%与9.7%的激酶对分别在两个数据集中共享至少一个抑制剂。相比之下,利用PocketVec描述符比较时,距离小于0.17即口袋相似的激酶对比例分别为40.5%与41.4%。这一比例显著高于随机口袋集合约2%的水平,Fisher检验OR大于30,p值接近0。这一结果符合预期,因为所有激酶均包含至少一个相似的ATP结合口袋。
与人类口袋总体分析结果一致,共享抑制剂数量越多,激酶口袋的PocketVec距离越小。然而,即便未共享抑制剂,ATP结合口袋之间的相似性仍较为显著,提示在分析激酶多靶性时应采用更严格的距离阈值。进一步将抑制矩阵转换为每个激酶的抑制谱向量,并评估PocketVec距离与抑制谱相似性之间的关系。结果显示,在PocketVec距离小于0.17时,抑制谱相似的激酶对显著富集,2017年数据集中OR为3.2,p值小于0.0003;2023年数据集中OR为4.1,p值小于0.003。当采用更严格阈值距离小于0.10时,富集倍数分别超过118与125,p值小于
与传统结构和序列相似性分析相比,结构相似性高即最大TM-score大于0.85的激酶对亦显示一定程度的抑制谱富集,OR约为2.4与1.7;序列一致性大于35%的激酶对富集更为明显,OR约为4.8与5.5。然而,综合比较发现,在部分案例中,仅PocketVec能够识别出抑制谱相似的激酶对,共9对;也存在少数情况共8对,序列或结构方法可识别而PocketVec未能检测。总体而言,各策略之间具有一致性与互补性,PocketVec在揭示传统方法难以发现的抑制谱相似性方面展现出独特优势。
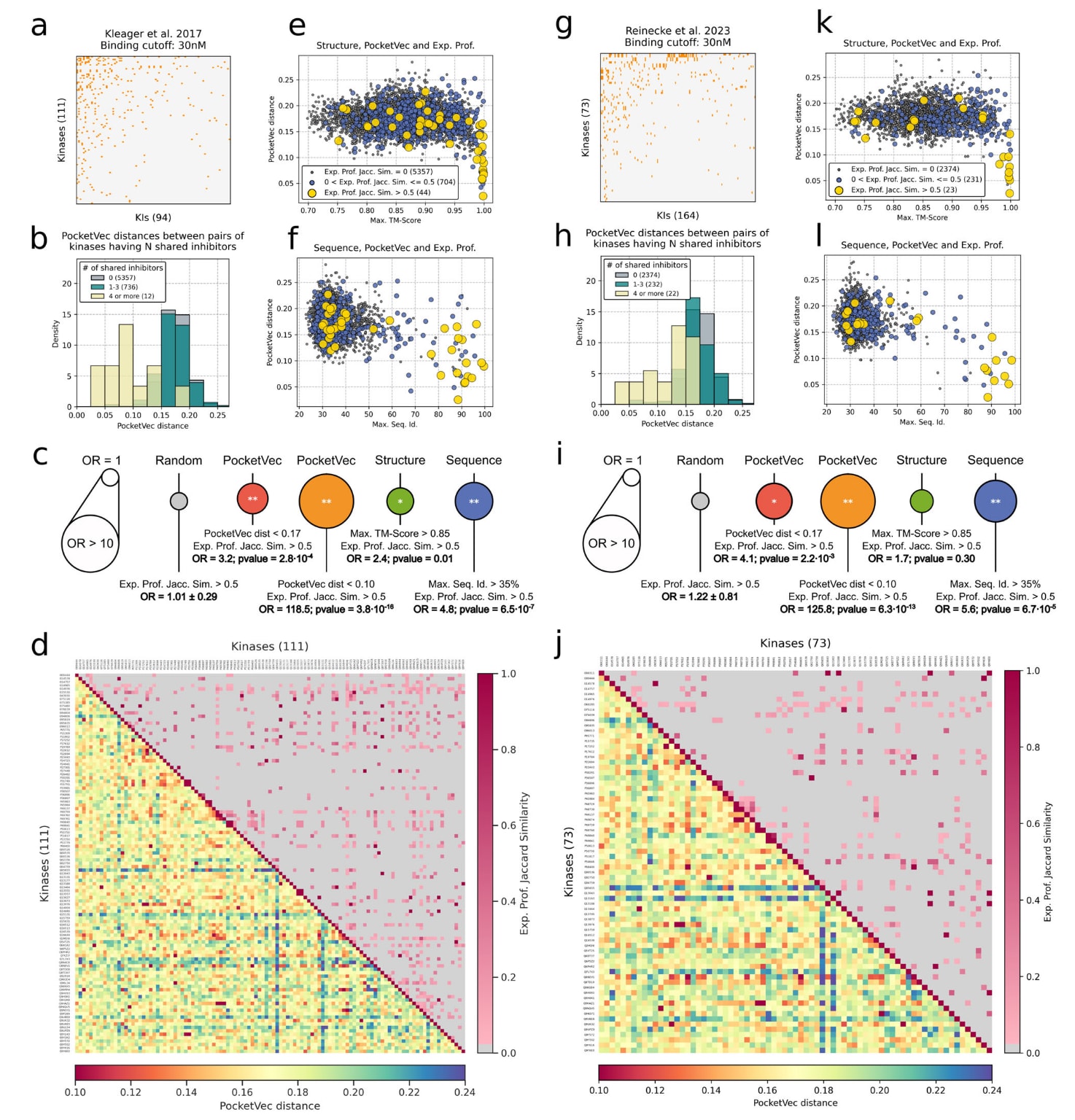
图7|抑制谱与PocketVec描述符之间的相关性。 所有分析基于Kleager等人数据集和Reinecke等人数据集完成,右侧面板对应前者,左侧面板对应后者。a、g 在30nM阈值下二值化的蛋白激酶与小分子激酶抑制剂之间的抑制矩阵。激酶与抑制剂均按照活性抑制事件数量排序。橙色点表示存在抑制作用,白色点表示无抑制作用。b、h 按激酶之间共享抑制剂数量分组的PocketVec距离分布,分组为0个、1–3个以及4个及以上。括号中标注各分组对应的激酶对数量。c、i 对PocketVec距离相似红色小于0.17、橙色小于0.10、结构相似性TM-score大于0.85以及序列一致性大于35%的激酶对,其抑制谱相似Jaccard相似性大于0.5的富集情况,采用双侧Fisher精确检验。灰色为随机选择激酶对的对照结果。圆圈面积与对应优势比OR成比例,中心标注p值,*表示p值小于0.05,**表示p值小于0.001。d、j 激酶两两比较矩阵。行与列为按UniProtID字母顺序排列的激酶。上三角矩阵基于实验确定的抑制谱进行比较,每个方格表示两个靶标抑制谱之间的Jaccard相似性,相似性越高表示抑制谱越相似。下三角矩阵基于PocketVec描述符进行比较,采用蛋白激酶结构域中所有PocketVec描述符之间的最小距离。每个方格颜色表示两个靶标之间的最小PocketVec距离,距离越小红色表示口袋层面越相似。e、k 激酶对之间结构相似性横轴最大TM-score与PocketVec距离纵轴之间的关系。每个点代表一对激酶,颜色与大小根据实验抑制谱相似性编码。f、l 激酶对之间序列相似性横轴最大序列一致性与PocketVec距离纵轴之间的关系。每个点代表一对激酶,颜色与大小根据实验抑制谱相似性编码。原始数据见SourceData文件。
3 讨论
提出了PocketVec方法,该方法基于逆向对接与化学生物组学原则即相似口袋结合相似配体,构建向量化蛋白口袋描述符。系统基准评估表明,其性能位列当前最佳方法之列,并克服了若干重要局限。通过结合实验解析结构与AF2模型,在人类折叠蛋白质组中系统识别出超过32000个结合位点,覆盖20000多个蛋白结构域,并为每个结合位点生成PocketVec描述符,随后进行超过12亿次两两比较的全局相似性分析。
PocketVec描述符与传统序列和结构方法具有互补性,能够识别结构或序列方法未能揭示的口袋相似性。应用示例显示,低PocketVec距离与实验确定的共享化合物之间存在明确关联;在激酶体系中,口袋相似性亦对应于实验抑制谱相似性。
与近期其他蛋白质组层面口袋识别研究相比,该方法以配体为中心的策略、较高准确性以及系统全面的识别与表征流程,使得能够在广泛尺度上分析蛋白结构变化对口袋定义与小分子结合的影响。预计算的人类口袋描述符资源为生物信息学与化学信息学领域提供了重要工具。
这些描述符主要用于全局分析,例如人类可成药口袋的系统刻画。分析揭示多个蛋白中存在尚无抑制剂共晶结构的相似口袋簇,为优先开发化学探针以覆盖可成药空间提供了新方向。描述符亦可根据特定任务进行调整,例如优化预定义分子集合或调整相似性阈值以探索特定蛋白家族底物特异性。
在预测潜在脱靶以及指导合理多靶药物设计方面亦具有重要意义,尤其是在设计可同时作用于两个蛋白的单价分子时。更重要的潜在影响可能体现在蛋白化学计量学方法中,通过结合配体与靶标描述符训练机器学习模型。结构基础描述符在区分药物选择性方面往往优于序列基础方法,而AF2模型生成的口袋描述符弥补了缺乏结构信息的不足。
未来可将小分子与口袋描述符结合,用于训练生成式人工智能模型,以设计能够结合特定口袋的新化学实体。合成可及的药物样分子空间估计达到