Acta Pharmacol. Sin. 2026 | VsNsbench: 评估AlphaFold3-embed诱导契合机制以增强虚拟筛选能力
今天介绍的是发表在 Acta Pharmacol. Sin. 上的一篇关于AlphaFold3在虚拟筛选中诱导契合建模能力评估的论文。该研究围绕一个核心问题展开:AF3不仅能否预测蛋白-配体复合物结构,还能否像实验holo结构一样,通过配体诱导形成更适合活性分子识别的受体构象。文章构建了新的基准数据集VsNsBench,并结合DUD-E子集,系统比较了AF3、AF2以及实验结构在虚拟筛选中的表现。结果表明,AF3生成的holo结构整体上显著优于apo结构和AF2,同时配体亲和力会明显影响其诱导效果,显示出AF3在结构基础药物发现中的重要潜力。

获取详情及资源:
0 摘要
虽然AlphaFold3(AF3)在AlphaFold2(AF2)的基础上进一步扩展到了holo结构预测,但其建模过程是否能够捕捉类似的诱导契合机制,目前仍不明确。该研究在两个数据集上系统评估了配体诱导的AF3 holo结构在虚拟筛选中的表现,包括DUD-E的一个子集以及专门用于避免序列层面信息泄漏而设计的VsNsBench。结果显示,在这两个数据集上,AF3 holo结构相比AF3 apo结构、实验apo结构以及AF2结构,都表现出显著更强的富集能力。与实验holo结构相比,AF3模型在DUD-E子集上的表现较弱,但在VsNsBench上的表现则略优。
进一步分析表明,AF3的诱导建模能力在很大程度上依赖于结合配体的亲和力:高亲和力配体能够诱导出有利于实现优异富集效果的构象,而低亲和力配体或随机配体通常只能得到较差的结果。此外,直接使用AF3进行虚拟筛选也能够取得较为令人满意的表现,但即使采用单轮多序列比对(MSA)生成策略,其计算效率对于大规模应用来说仍然是一个主要瓶颈。在一个关于DFG基序激酶的案例研究中,AF3以75%的成功率建模出了抑制剂特异性的构象。
这些结果表明,AF3已经能够有效整合诱导契合建模机制,但仍有进一步提升空间,尤其是在多状态构象集合建模方面。
1 引言
基于结构的虚拟筛选在药物发现早期阶段越来越多地被用于发现目标蛋白的新型配体。该流程通常首先获取目标蛋白的结构,随后将化合物库系统对接到结合口袋中,再根据结合亲和力评估结果筛选出排名靠前的候选分子。值得注意的是,蛋白结构的选择会显著影响筛选效果。已有研究表明,实验解析得到的holo结构,也就是与特定配体结合的结构,相比apo形式即无配体结构,通常具有更强的富集能力。这种差异源于holo结构中结合配体对结合位点产生的诱导优化作用。
AlphaFold系列对科学界产生了深远影响,尤其是在药物设计领域。AlphaFold2(AF2)能够直接从氨基酸序列有效预测蛋白质三维结构。然而,尽管AF2预测结构在虚拟筛选任务中通常优于其他计算方法生成的结构,其表现仍明显落后于实验解析的holo结构。AlphaFold3(AF3)则有望缩小这一差距,因为它将预测能力扩展到了几乎所有生物分子复合物,包括蛋白-配体系统。这一进展使AF3有潜力成为经典对接方法之外的一种有前景的替代方案,不仅可用于预测配体结合模式,也可用于估计结合亲和力。
一种思路是在实际虚拟筛选项目中直接对所有化合物使用AF3,这种做法在技术上是可行的,即使针对每个靶点只进行单轮多序列比对(MSA)生成,其计算成本依然十分高昂。另一种策略则是利用AF3生成更可靠的受体模板,再配合效率更高的对接流程开展后续的虚拟筛选。然而,一个关键问题仍未解决:AF3的建模过程是否能够重现实验holo结构中观察到的诱导契合优化现象,从而得到更适合虚拟筛选的蛋白构象。
此外,在生理条件下,只有有限一部分分子能够稳定结合到给定蛋白的结合口袋中,但AF3几乎可以为任意分子预测其结合构象。这意味着,由非天然配体或弱结合配体诱导形成的蛋白构象,其在虚拟筛选中的表现仍有必要进一步研究。
要严格评估AF3预测结构在虚拟筛选中的应用价值,需要经过精心设计的基准数据集。传统虚拟筛选数据集如DUD-E并不适合这一目的,因为其中可能包含AF3训练过程中使用过的蛋白结构,从而导致结构层面的数据泄漏与评估偏差。尽管近期提出的一些按时间划分的数据集,例如PoseBuster,能够有效降低直接的结构级泄漏风险,但仍然容易受到序列级信息泄漏的影响。具体来说,时间切分数据集中的蛋白结构虽然可以避免与AF3训练数据中的结构重叠,但对应靶点的其他实验构象仍可能已包含在AF3训练数据中。这样一来,这些靶点的序列在AF3开发阶段实际上已经暴露过,从而可能使预测偏向已有构象。为了尽可能降低这一风险,基准测试应优先选择具有新序列的靶点。
除了靶点选择之外,活性分子与诱饵分子的组成也是构建稳健虚拟筛选基准时的另一个关键因素。活性化合物应限制为经过实验证实的结合分子,但对于如何生成最优诱饵分子,目前仍缺乏统一共识。与此同时,不同的虚拟筛选工具,尤其是基于不同原理的方法,即使面对同一数据集,也常常会得到差异显著的性能结果。这说明在评估时采用多样化的诱饵选择策略以及多种筛选工具,对于提高结果客观性十分重要。
除了使用虚拟筛选指标评估结合口袋构象与活性配体之间的整体适配程度之外,分析特定蛋白结构域的构象变化,还能够为理解AF3建模holo结构时的诱导契合机制提供更深入的认识。以激酶为例,其结合口袋中存在一个高度保守的DFG基序,该基序会根据结合抑制剂类型的不同,呈现两种不同的构象状态,即DFG-in和DFG-out。因此,针对同一靶点在结合不同类型抑制剂时,评估AF3对DFG基序构象的预测准确性,也可以作为衡量AF3建模中诱导契合机制的重要补充指标。
该研究首先整理了经典DUD-E数据集的一个子集,命名为DUD-Esubset。为了进一步减轻蛋白结构预测中由数据泄漏带来的潜在偏差,又构建了一个新的基准数据集VsNsBench,其核心特征在于所有靶点的实验解析结构均发表于2021年10月之后。对于每个靶点,数据集中纳入了经过实验验证的活性化合物,并通过两种方式生成诱饵分子,一种是性质匹配生成,另一种是从商业化合物库中随机抽样。随后,研究使用两种不同的对接方法,即基于物理的Glide和基于人工智能的KarmaDock,针对多种类型的受体结构开展了系统基准测试。这些受体结构包括AF3预测的holo结构、实验解析的holo结构、AF3预测的apo结构以及AF2预测结构。
此外,该研究还分析了由随机选择的配体以及不同结合亲和力配体所诱导的AF3受体构象在虚拟筛选中的表现。为了评估AF3本身对活性分子的富集能力,研究进一步仅使用AF3,在VsNsBench的性质匹配诱饵集上进行了独立虚拟筛选。最后,研究整理了12个激酶靶点,这些靶点均具有在2021年10月之后解析得到的DFG-in和DFG-out实验结构。基于相同的氨基酸序列,并结合各自晶体结构中不同类型的抑制剂,研究利用AF3为这些激酶建立复合物结构,系统考察不同抑制剂是否能够成功诱导出相应的DFG基序构象。该研究的关键模块如图1所示。
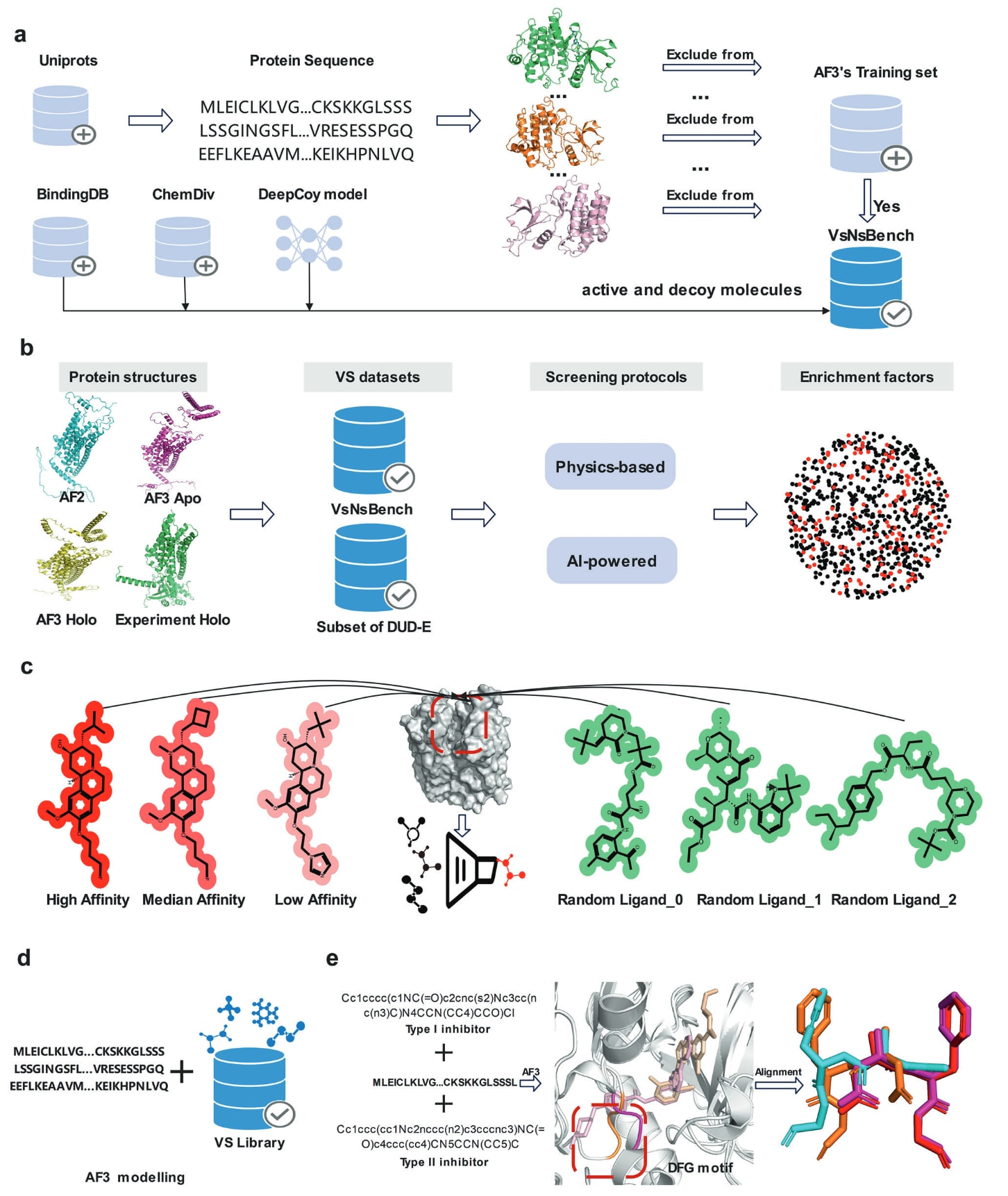
图1|本研究的关键模块。 a,VsNsBench数据集的构建流程。b,针对不同受体结构进行虚拟筛选性能基准测试的工作流程。c,评估AF3在结合不同配体时其建模诱导效应的实验设计。d,基于AF3的独立虚拟筛选流程,具体而言,基于AF3对相同蛋白序列以及虚拟筛选数据集中的全部化合物进行复合物结构建模。e,用于评估DFG构象状态的激酶建模流程。
2 方法
2.1 数据整理
本研究共使用了三个数据集,分别为VsNsBench、DUD-Esubset以及一个激酶数据集。VsNsBench和DUD-Esubset用于虚拟筛选基准测试,主要评估AF3建模得到的受体构象与实验结构在整体构象匹配上的一致性;激酶数据集则专门用于验证AF3对DFG基序构象的预测能力,考察不同配体是否能够诱导这一关键结构基序形成不同的构象状态。
VsNsBench基于人类蛋白靶点及其对应配体构建。首先,从UniProt数据库收集所有经过审查的人类蛋白靶点,并将其映射到RCSB PDB中已有的实验晶体结构,同时记录这些结构的解析日期。凡是在2021年10月之前已有任何晶体结构解析结果的靶点均被排除。随后,进一步去除缺少实验holo结构的靶点,以及在BindingDB中对应配体数量少于100个的靶点,最终得到35个高质量靶点纳入VsNsBench。
所有在BindingDB中可获得的配体都被提取出来,并使用RDKit工具包进行标准化处理。含有金属离子或化合价错误的配体被移除。对于其余配体,根据实验生物活性数据采用1μM作为划分阈值,涉及的活性指标包括IC50(半数抑制浓度)、
在诱饵分子生成方面,研究采用了两种互补策略。第一种方法利用DeepCoy模型,为每个活性分子生成50个性质匹配的诱饵分子。第二种方法则从大规模ChemDiv数据库中按活性分子与诱饵分子1:50的比例随机抽取诱饵分子,并独立重复三次,从而为每个活性分子得到150个诱饵分子,以保证更广泛的化学空间覆盖。VsNsBench数据集的详细特征见表S1。
为了降低VsNsBench中GPCR靶点占比过高可能带来的偏差,进一步整理了DUD-Esubset,即从经典DUD-E数据集中筛选出的一个精炼子集,初始包含102个靶点。只有当apo结构、holo结构以及AF2结构能够在RCSB PDB或AlphaFold Protein Structure Database中同时获得时,该靶点才会被纳入。含有金属离子或辅因子的结构被排除,并通过结构比对确认holo配体与AF2或apo结构中的结合口袋之间不存在空间冲突。经过这一严格筛选流程后,最终得到26个DUD-E靶点用于基准测试。完整的数据集说明见表S2。
直接利用AF3进行虚拟筛选是一个很有吸引力的研究方向。然而,基于AF3的蛋白-配体建模过程计算开销极大;即便去掉最耗时的MSA步骤,处理单个蛋白-配体对仍然需要1分钟以上,这限制了其在大规模测试中的应用。因此,从NsVsBench数据集中选取了17个活性分子数量少于100个的靶点,并在这些靶点上结合性质匹配诱饵分子,评估AF3对活性分子的富集能力。
对于激酶数据集,首先从UniProt数据库中收集所有激酶靶点,并在RCSB PDB中识别每个激酶可获得的所有holo结构。随后,借助KLIFS数据库判定每个holo结构中保守DFG基序的构象状态,即DFG-in或DFG-out。只有同时具有这两种构象的实验holo结构,且这些结构均在2021年10月之后解析得到的激酶靶点,才被纳入测试集合。按照这一严格标准,最终获得13个符合条件的激酶靶点,详细信息见表S3。
本研究中使用的晶体结构均来自RCSB PDB,并通过Schrödinger中的Protein Preparation Wizard在默认参数下进行预处理,包括添加氢原子、指定键级、补全缺失的侧链原子和环区、使用PROPKA在
2.2 筛选工具
本研究在虚拟筛选中采用了两种互补的对接工具,分别是基于物理的Glide和基于人工智能的KarmaDock。对于Glide,对接网格的中心设定为holo结构中参考配体的几何中心,网格盒大小设为16Å加上参考配体任意两个原子之间最大距离的0.8倍。对接计算使用标准精度(SP)评分模式完成。
KarmaDock建立在具备自注意力机制的
2.3 评估指标
本研究使用6个指标来评估虚拟筛选性能,分别为
在激酶建模实验中,DFG-in构象的特征是苯丙氨酸(F)和甘氨酸(G)残基朝向活性位点内侧,而DFG-out构象则表现为苯丙氨酸侧链向外翻转,远离ATP结合口袋。AF3预测得到的构象会与实验解析的DFG-in和DFG-out参考结构进行结构比对,随后通过比较苯丙氨酸残基的位置并计算RMSD来评估预测准确性。
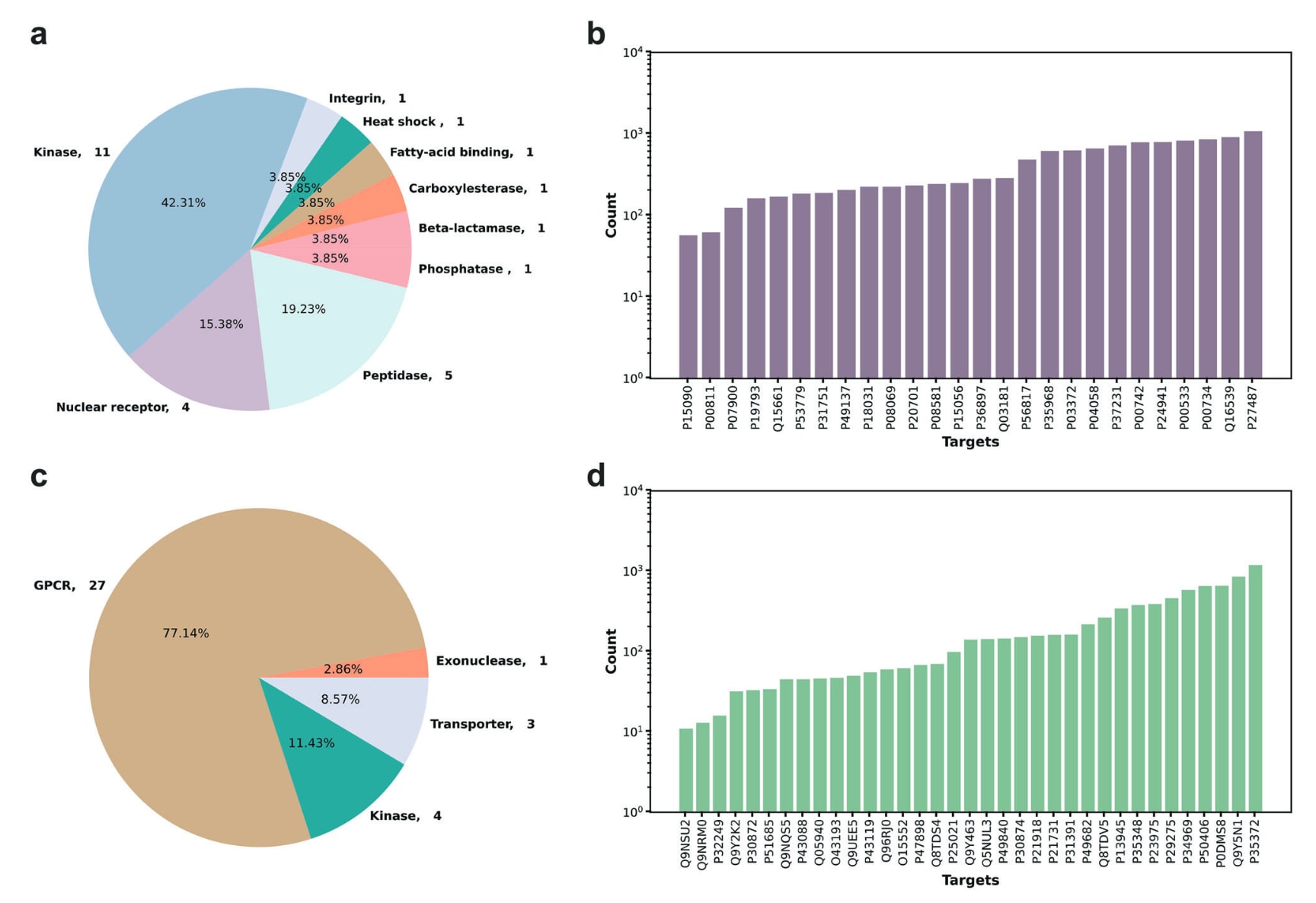
图2|DUD-Esubset与VsNsBench数据集的数据分布。 a,DUD-Esubset数据集中靶点类型的分布。b,DUD-Esubset数据集中每个靶点的活性化合物数量。c,VsNsBench数据集中靶点类型的分布。d,VsNsBench数据集中每个靶点的活性化合物数量。
3 结果
3.1 DUD-Esubset与VsNsBench数据集描述
如图2a所示,该研究从经典DUD-E数据集中筛选得到26个靶点,其中包括11个激酶、5个肽酶、4个核受体以及6个其他蛋白。这些靶点的实验holo结构、实验apo结构和AF2预测结构均来自RCSB Protein Data Bank(PDB)或AlphaFold Protein Structure Database。每个靶点对应的活性化合物数量介于57到1079之间,平均为434个(图2b)。
最终构建的VsNsBench数据集包含36个靶点,其中包括27个G蛋白偶联受体(GPCR)、4个激酶、3个转运蛋白以及1个外切核酸酶(图2c)。一个关键特点是,这些靶点的实验解析晶体结构均未被纳入AF3的训练集。每个靶点的活性化合物均来自BindingDB,数量范围为11到1192个,平均为224个(图2d)。在诱饵分子生成方面,研究采用了两种互补策略:一种是从ChemDiv数据库中按照活性分子与诱饵分子1:50的比例随机选择诱饵,并对每个靶点独立重复三次;另一种是使用DeepCoy模型为每个活性化合物生成50个性质匹配的诱饵分子。
3.2 DUD-Esubset上的虚拟筛选结果
研究首先在DUD-Esubset数据集上开展虚拟筛选实验,并分别采用Glide和KarmaDock作为对接工具。如图3a和3b所示,在使用Glide时,AF3预测的holo结构在早期富集指标上,即
总体来看,AF3 holo结构在大多数平均指标上优于AF3 apo结构、实验apo结构以及AF2预测结构,但仍然落后于实验holo结构。具体而言,不同受体结构类型(AF3 holo、实验holo、AF3 apo、实验apo和AF2)在六项指标上的平均值分别为:
当使用KarmaDock时(图3c和3d),AF3 holo结构与其他结构类型之间在虚拟筛选指标上的统计差异几乎消失。尽管如此,AF3 holo结构在全部六项指标上的表现与实验holo结构相当,而且这两类结构整体上优于其余结构类型。在实验holo结构上,Glide在
3.3 VsNsBench上的虚拟筛选结果
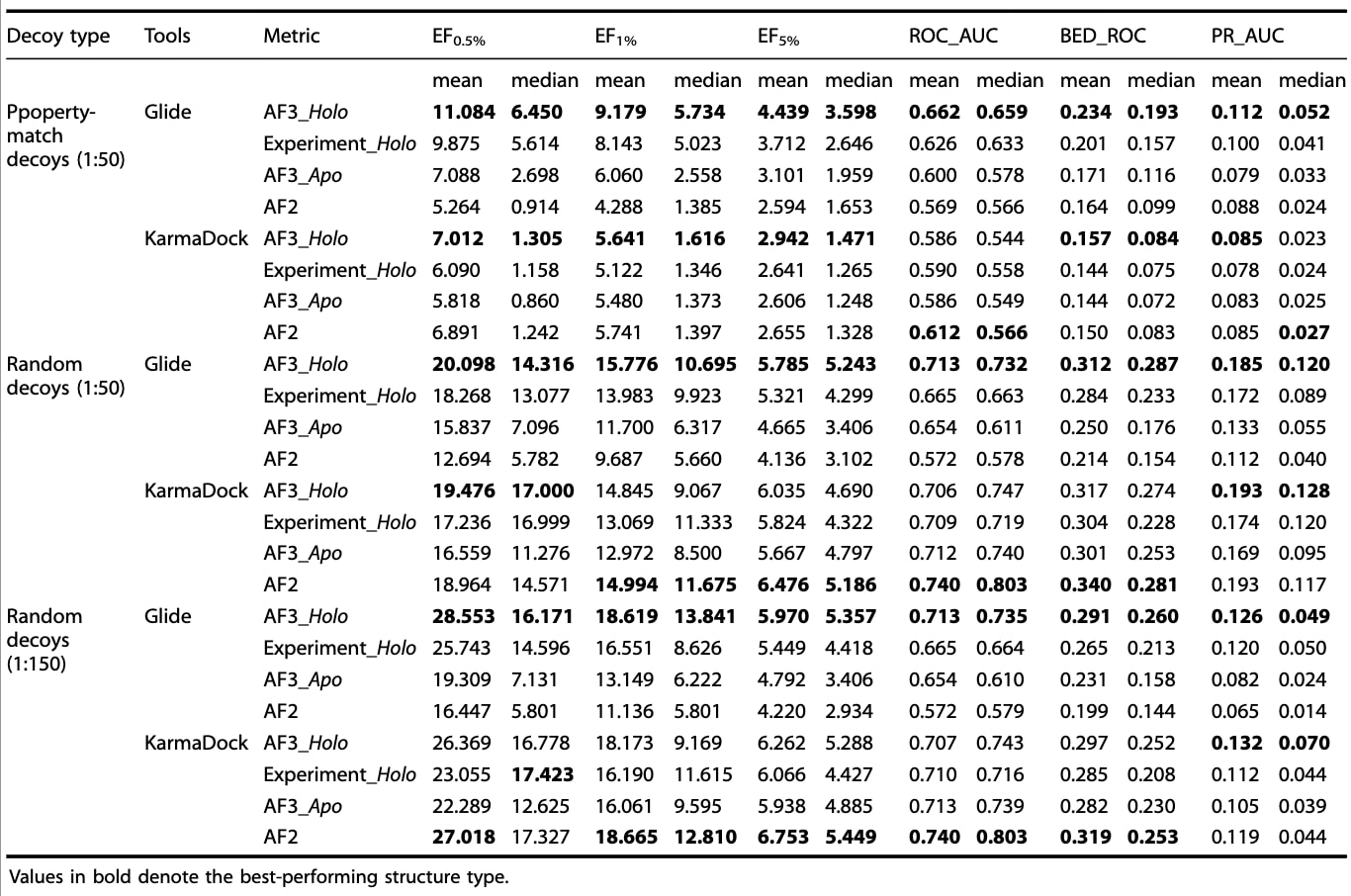
随后,研究进一步在VsNsBench数据集上进行评估,主要虚拟筛选指标的均值和中位数见表1,其分布见图S1至图S3。对于性质匹配诱饵数据集,当采用Glide作为筛选工具时,AF3 holo结构在多个指标上,包括EF类指标、ROC_AUC、BEDROC和PR_AUC,其均值和中位数均高于实验holo结构,但这些差异未达到统计显著性。值得注意的是,AF3 holo结构显著优于AF2结构和AF3 apo结构(
对于随机选择诱饵的数据集,AF3 holo结构和实验holo结构在基于Glide的筛选能力上都优于AF2和AF3 apo构象。值得注意的是,AF3 holo结构在全部六项指标上的平均值都略高于实验holo结构,但仍然没有统计显著性(图S2a)。KarmaDock的结果则呈现出另一种模式:AF2结构在大多数指标上的均值和中位数最高。然而,由于不同结构类型之间缺乏统计显著差异,这也进一步说明KarmaDock对构象差异的敏感性有限(图S2b)。在活性分子与诱饵分子比例为1:50和1:150时,这些趋势都保持一致(图S3a和图S3b)。此外,无论使用哪种对接工具,在性质匹配诱饵上区分活性分子的难度都高于随机诱饵,这说明诱饵分子的选择策略会对筛选性能产生关键影响。
3.4 基于不同配体诱导蛋白结构的虚拟筛选表现
为了系统评估不同结合配体对蛋白构象变化的诱导作用,研究设计了一组受控实验:在DUD-Esubset和VsNsBench两个数据集中,针对每个靶点分别选取3个具有代表性的活性化合物,对应高亲和力、中等亲和力和低亲和力,以及3个来自ChemDiv数据库的随机诱饵(图4a)。然后将每个靶点的这6个配体输入AF3模型,预测其诱导形成的蛋白构象,再仅使用Glide在两个数据集上进行后续的基于对接的虚拟筛选。这是因为此前分析显示,Glide对蛋白结构差异具有更高的敏感性。
DUD-Esubset上的结果(图S4)表明,由高亲和力配体诱导得到的受体构象在多项指标上始终表现出最佳的整体虚拟筛选能力。这一效应在早期富集指标
在采用性质匹配诱饵的VsNsBench数据集上,这一趋势更加明显(图4b)。高亲和力配体在不同评估指标上均显著优于随机选择的配体(
在VsNsBench中使用随机抽样诱饵的虚拟筛选结果(图4b)进一步验证了这一总体趋势:高亲和力配体在不同指标上整体优于随机配体和低亲和力配体。与中等亲和力配体相比,高亲和力配体在EF指标的中位数上也表现出明显优势,但统计显著性相对较弱。值得注意的是,在所有靶点上,随机选择的不同配体之间并未观察到稳定一致的性能差异。低亲和力配体的整体表现通常与随机诱饵相当,或仅略好于随机诱饵。
以晶体结构中的配体作为参考时,高亲和力配体在DUD-Esubset以及VsNsBench中的性质匹配诱饵集上能够达到与其相当的表现,但在VsNsBench的随机诱饵集上则表现稍弱。总体来看,这些结果揭示出一个清晰趋势:高亲和力配体更容易诱导形成有利于结合口袋适配的受体构象,从而带来最佳的虚拟筛选性能;中等亲和力配体次之;而低亲和力配体和随机选择的配体表现最弱。
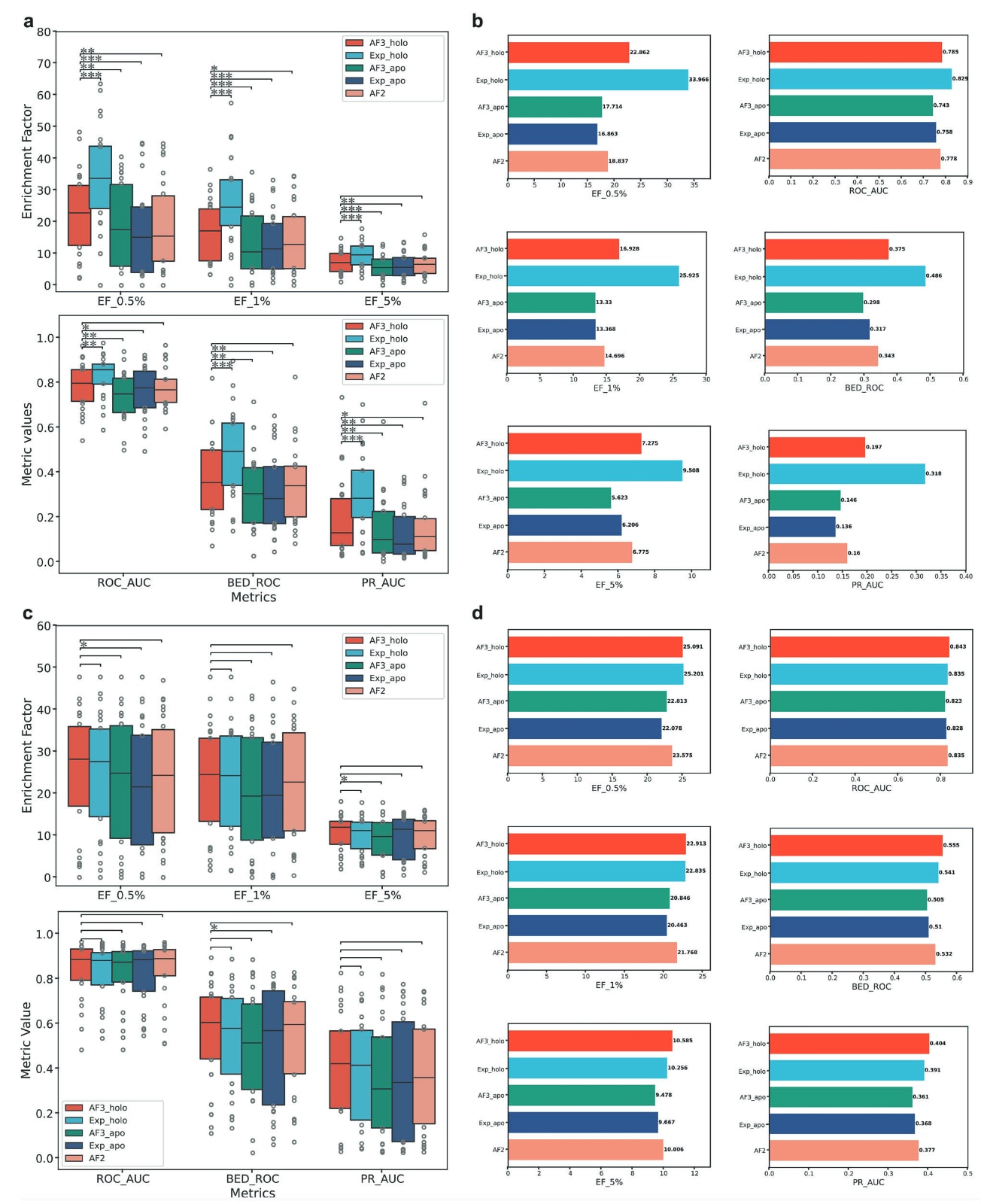
图3|DUD-Esubset上的虚拟筛选结果。 a,Glide得到的六项指标分布,包括
表1|基于不同筛选方案,不同蛋白结构类型在VsNsBench数据集上的虚拟筛选表现。
3.5 直接使用AF3进行虚拟筛选
随后,研究直接使用AF3在NsVsBench数据集中17个靶点的性质匹配诱饵上开展虚拟筛选实验。为了提高计算效率,计算开销极大的MSA过程对每个靶点只执行一次,随后生成的比对结果被重复用于所有配体结合蛋白构象的建模。尽管进行了这一优化,在H800 GPU上处理单个分子仍然需要1分钟以上,具体时间还取决于蛋白序列长度和配体大小。因此,如果筛选一个包含100万个分子的化合物库,大约需要700天,这对大规模虚拟筛选应用构成了显著挑战。
在筛选准确性方面,AF3在六项指标上均表现出显著优于Glide和KarmaDock的结果(
3.6 对激酶DFG基序构象的预测表现
上述虚拟筛选结果从定量角度反映了配体诱导的蛋白构象在多大程度上能够维持与已知活性化合物相兼容的结合口袋。为了进一步阐明AF3在复合物结构预测中的诱导机制,尤其是关键结构基序构象变化方面的表现,研究选择了13个激酶靶点进行深入分析。激酶结合口袋中的DFG基序高度保守,在结合不同抑制剂后会呈现不同构象状态,这种差异主要体现在苯丙氨酸(F)和甘氨酸(G)残基相对于活性位点的取向变化上。
如图5a和5b所示,研究利用AF3在相同氨基酸序列和不同配体条件下建立复合物结构,并评估其重现正确DFG构象的能力。这里重点关注了两种已获FDA批准的酪氨酸激酶抑制剂,即imatinib和dasatinib,它们分别诱导两种不同的DFG构象状态,即DFG-in和DFG-out。在分别使用这两种抑制剂完成酪氨酸激酶复合物建模后,研究将预测得到的DFG基序与对应的晶体结构进行比对,对应的PDB编号分别为2GQG和2HYY。图5b中间部分表明,AF3成功重现了预期的DFG构象,这是因为这两个晶体结构均包含在AF3的训练集中。
在此基础上,研究进一步将分析扩展到另外12个激酶靶点,这些靶点都具有在2021年10月之后解析得到的DFG-in和DFG-out实验结构。AF3预测的DFG基序构象与实验结构进行比对后,其均方根偏差(RMSD)结果如图5d所示。对于O75116、P08581和Q92581,实验DFG-out结构与AF3预测构象之间的RMSD均大于5Å,明显高于其他靶点。值得注意的是,这三个靶点的预测DFG-out基序与实验DFG-in结构却高度一致,其RMSD小于2Å,这表明对于这些激酶,AF3倾向于优先预测DFG-in构象,而不受结合抑制剂类型的明显影响(图5e)。对于其余靶点,尽管RMSD存在一定波动,但所有偏差都处于可接受范围内,即小于3Å。对这些DFG基序进行结构叠合的结果(图S5)也进一步支持了其构象预测的准确性。总体来看,AF3在正确重现配体特异性DFG状态方面的成功率达到75%。
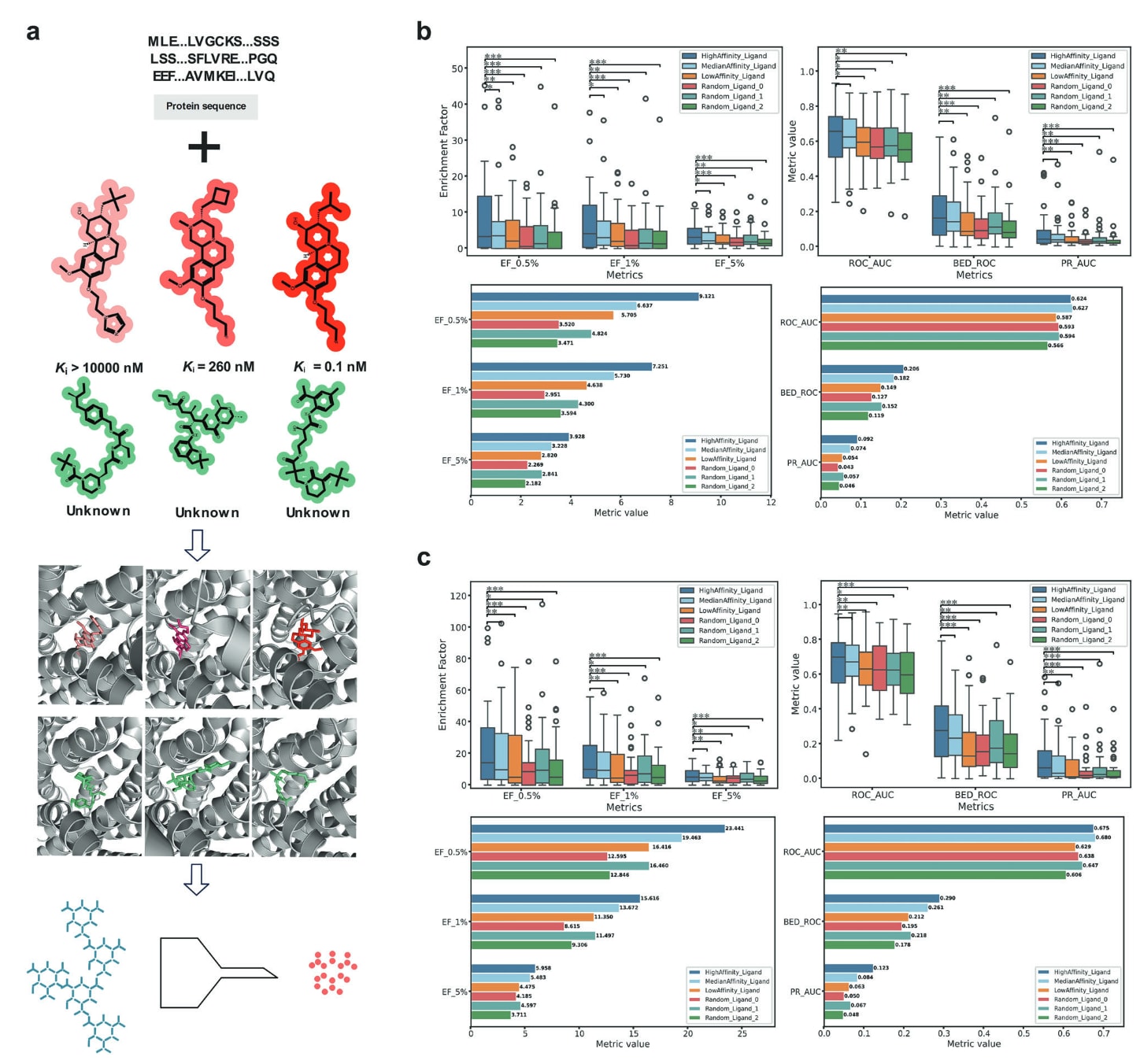
图4|VsNsBench数据集中使用不同配体诱导的受体构象所得到的虚拟筛选表现。 a,生成不同配体诱导受体构象的工作流程。b,在VsNsBench数据集的性质匹配诱饵上,Glide得到的
4 讨论
基于结构的虚拟筛选能否成功,在很大程度上取决于模板蛋白结构的构象状态。实验解析得到的holo结构由于考虑了配体诱导的口袋优化,通常比apo结构具有更好的虚拟筛选表现。相较于AF2,AF3在复合物结构预测方面能力更强,因此为基于结构的药物发现带来了新的机会。该研究系统考察了AF3构象建模中的诱导机制如何影响虚拟筛选结果。通过使用多种筛选工具,研究在经过整理的经典DUD-E子集和自行构建且避免氨基酸序列泄漏的VsNsBench数据集上,对AF3 holo结构、实验holo结构、AF3 apo结构和AF2结构进行了基准评估。
考虑到蛋白质在生理条件下通常只会与特定分子伙伴相互作用,而AF3几乎能够预测其与任意分子的复合物结构,研究进一步比较了由不同配体建模得到的蛋白结构在虚拟筛选中的表现,以评估配体依赖的构象效应。此外,为了评估AF3本身富集活性分子的能力,研究在不引入额外打分函数的条件下,仅使用AF3开展虚拟筛选实验。最后,研究以激酶中保守的DFG基序为代表案例,分析了AF3重现配体诱导构象变化的能力。
在DUD-Esubset数据集上,AF3 holo结构相较于AF3 apo结构、AF2预测结构和实验apo结构,都表现出显著增强的虚拟筛选能力,但与实验holo结构相比仍存在明显性能差距。而在VsNsBench数据集上,无论面对性质匹配诱饵还是随机选择诱饵,AF3 holo结构都略微优于实验holo结构。此外,不论诱饵类型如何,AF3 holo结构和实验holo结构都稳定优于AF2和AF3 apo结构。不过,当KarmaDock作为筛选工具时,这种趋势不如Glide明显,这很可能是因为基于人工智能的对接方法通常对受体构象变化不如基于物理的方法敏感。
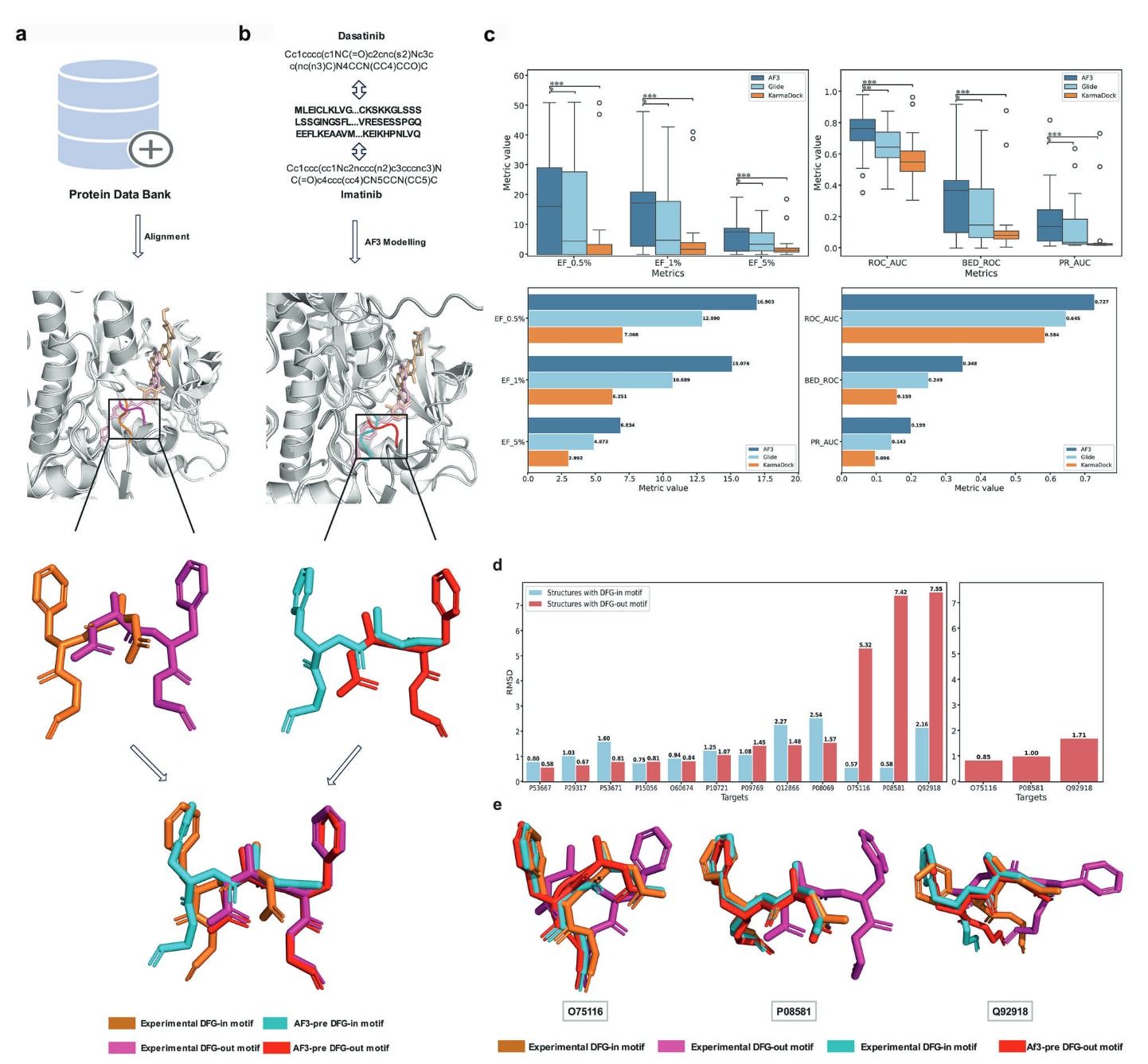
图5|基于AF3的虚拟筛选与激酶DFG基序构象预测。 a,ABL激酶晶体结构中DFG基序的结构比对(上图),分别为与dasatinib结合的结构(PDB:2GQG,DFG-in)和与imatinib结合的结构(PDB:2HYY,DFG-out),以及AF3预测的DFG基序与其实验解析对应结构的叠合结果(下图)。b,DFG基序构象的预测流程。c,在VsNsBench数据集性质匹配诱饵上,不同筛选工具得到的
DUD-Esubset与VsNsBench之间表现差异的一个重要原因,在于两者蛋白组成不同。VsNsBench以GPCR靶点为主,而DUD-Esubset则包含更加多样化的蛋白靶点。进一步分析显示,虚拟筛选表现与结合配体的亲和力之间存在很强的相关性。被高亲和力配体占据的蛋白口袋始终表现出最佳虚拟筛选能力,其次是中等亲和力配体,再之后是低亲和力配体和随机选择的配体。这一现象说明,高亲和力配体更容易诱导出与活性化合物兼容性更高的结合口袋构象,这一结论对基于结构的虚拟筛选中的受体建模具有重要参考价值,尤其适用于缺乏实验holo结构的情形。
此外,如果在虚拟筛选项目中直接使用AF3为所有化合物建立复合物结构,也能够获得令人满意的表现,这说明柔性对接在虚拟筛选中具有重要价值。但即便只进行一次MSA生成,计算效率仍然是大规模应用中的主要瓶颈。另一方面,在更具挑战性的激酶DFG构象状态预测任务中,AF3在12个靶点中成功重现了9个正确的DFG构象,成功率达到75%。
总体而言,AF3增强的复合物结构预测能力显著提升了虚拟筛选表现,而且AF3建模受体结构的质量与其所结合配体的亲和力之间存在明确相关性。这些结果表明,AF3已经整合了有效的诱导契合建模机制,能够生成更适合活性化合物结合的蛋白构象,并展示出其自身富集活性分子的潜力。然而,AF3仍然不能完全捕捉激酶DFG区域的动态构象变化,说明这一方面仍需进一步优化。后续工作可重点沿两个方向展开。一方面,可以探索集合建模方法,以更好地表征动态构象状态,尤其需要关注蛋白结构中的关键功能基序。另一方面,可以探索AF3模型的多层次优化策略,以加快推理效率,从而推动其在大规模虚拟筛选中的实际应用。