ACS Cent. Sci. 2026 | LLMB:基于大语言模型的锂金属电池研究AI智能体
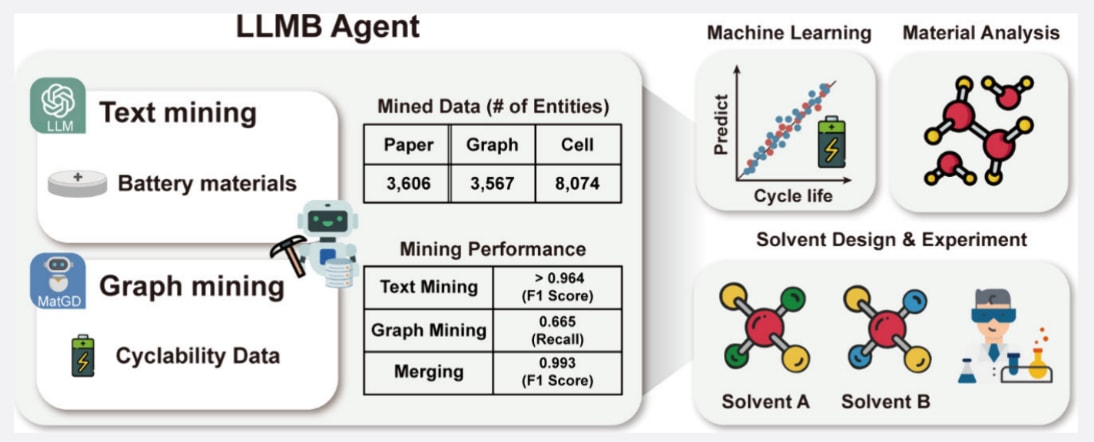
今天介绍的是发表在 ACS Central Science 上的一篇论文。该研究主要围绕锂金属电池领域中数据获取与性能预测难题展开,重点探讨了如何利用大语言模型与自动图像挖掘技术,实现对文献中材料组成、操作条件及循环性能数据的高效提取与整合,并在此基础上构建数据驱动的预测模型。研究提出了LLMB智能体,通过多模态信息挖掘构建包含8074个电池的数据集,并实现了对电池容量的准确预测,同时结合分子模拟与实验验证揭示了电解液溶剂结构对电池性能的关键影响。该工作为打通“文献数据—机器学习—材料设计”的闭环提供了新思路,对于加速电池材料发现与优化具有重要参考价值。

获取详情及资源:
0 摘要
近年来,数据驱动研究在揭示材料与其性能之间复杂关系方面展现出巨大潜力。该研究介绍了LLMB,这是一种面向锂金属电池研究的人工智能智能体,将用于分层文本挖掘的大语言模型与自动图像信息挖掘工具Material Graph Digitizer(MatGD)相结合。该智能体能够从多种数据来源中高精度提取电池材料数据及循环性能指标。通过文本挖掘,获取了15398个电池单元的组成信息和操作条件;同时,图像挖掘获得了10242个电池单元的循环性能数据。在对这些数据进行对齐与融合后,构建了一个包含8074个电池单元的综合数据库,其中涵盖了各组分的具体信息及容量数据。基于该数据库,进一步建立了首个利用电池各组成材料信息预测锂金属电池容量的机器学习模型。此外,还结合分子模拟与材料分析,阐明所识别的预测特征如何影响决定电池性能的物理化学性质。基于模型结果与材料分析,通过实验验证发现,由低EState VSA6溶剂诱导形成的弱溶剂化电解液,有助于形成以阴离子衍生为主的固态电解质界面(SEI),并促进高度结晶的锂沉积,从而验证了模型的可靠性。
1 引言
锂金属电池(LMBs)是一类有前景的下一代器件,由于金属锂具有极低密度(0.534 g cm−3)、高理论容量(约3860 mAh g−1)以及低电势(相对于标准氢电极为−3.04 V),因此以其作为负极可以实现高容量。然而,金属锂的高反应性对LMBs的长期循环性能构成了障碍,目前在多个研究领域中均开展了相关工作以克服这一问题。尽管如此,由于测量电池循环寿命所需时间较长,导致性能反馈存在延迟,从初始性能实现循环寿命的早期预测仍然是一个关键挑战,这一问题阻碍了材料与制造工艺的开发与验证过程。传统的试错方法耗时且效率低下,尤其是在面对各个电池组分的多样化材料选择时,风险较高。此外,这些方法通常仅控制一到两个变量(例如电解液和充放电条件),因此难以提供对材料—性能关系的全面认识。
值得注意的是,这类信息可能已经存在于大量已发表的文献之中。关键挑战在于如何高效提取相关数据以及应当分析哪些内容。随着人工智能的发展,已有研究尝试利用自然语言处理(NLP)和Transformer模型从电池文献中提取实验信息。然而,以往未引入领域知识的研究通常关注单个电池组分的特性,而非完整电池体系。此外,这些研究所涉及的实体数量较少,且无法提取诸如浓度或比例等定量信息。进一步而言,由于缺乏自动图像挖掘工具,从比容量和循环稳定性等性能曲线图中获取数据也较为困难。这些局限性阻碍了材料—性能关系的全面挖掘及其在机器学习研究中的应用。因此,为了充分释放新型电池技术的潜力,需要一种能够利用综合数据来理解电池循环过程的新方法。目标在于直接从数十年积累的研究中提取材料层面的洞见,以指导未来研究与创新。
该研究提出了一种新的多模态数据驱动方法,即用于电池研究的大语言模型智能体LLMB,该方法由大语言模型(LLM)和自动图像挖掘工具Material Graph Digitizer(MatGD)组成。该方法以96.4%的准确率自动提取电池材料的综合信息,达到了当前已知的最先进水平,并覆盖了共计29类实体,是目前报道中实体数量最多的一项工作。此外,首次实现了直接从循环曲线图中挖掘循环性能数据。基于这一规模独特且数据丰富的数据集,构建了能够预测电池容量的机器学习模型。这些模型不仅能够预测初始循环和第50次循环的容量,还通过SHapley Additive exPlanations(SHAP)方法提供了关于电解液分子结构与溶剂化结构如何影响循环性能的解释,该方法能够定量识别各化学特征对预测结果的贡献。进一步的实验验证表明,采用弱溶剂化溶剂(如二乙醚)可以提升循环性能,其表现为形成了阴离子衍生的薄SEI层以及具有结晶结构的锂沉积。
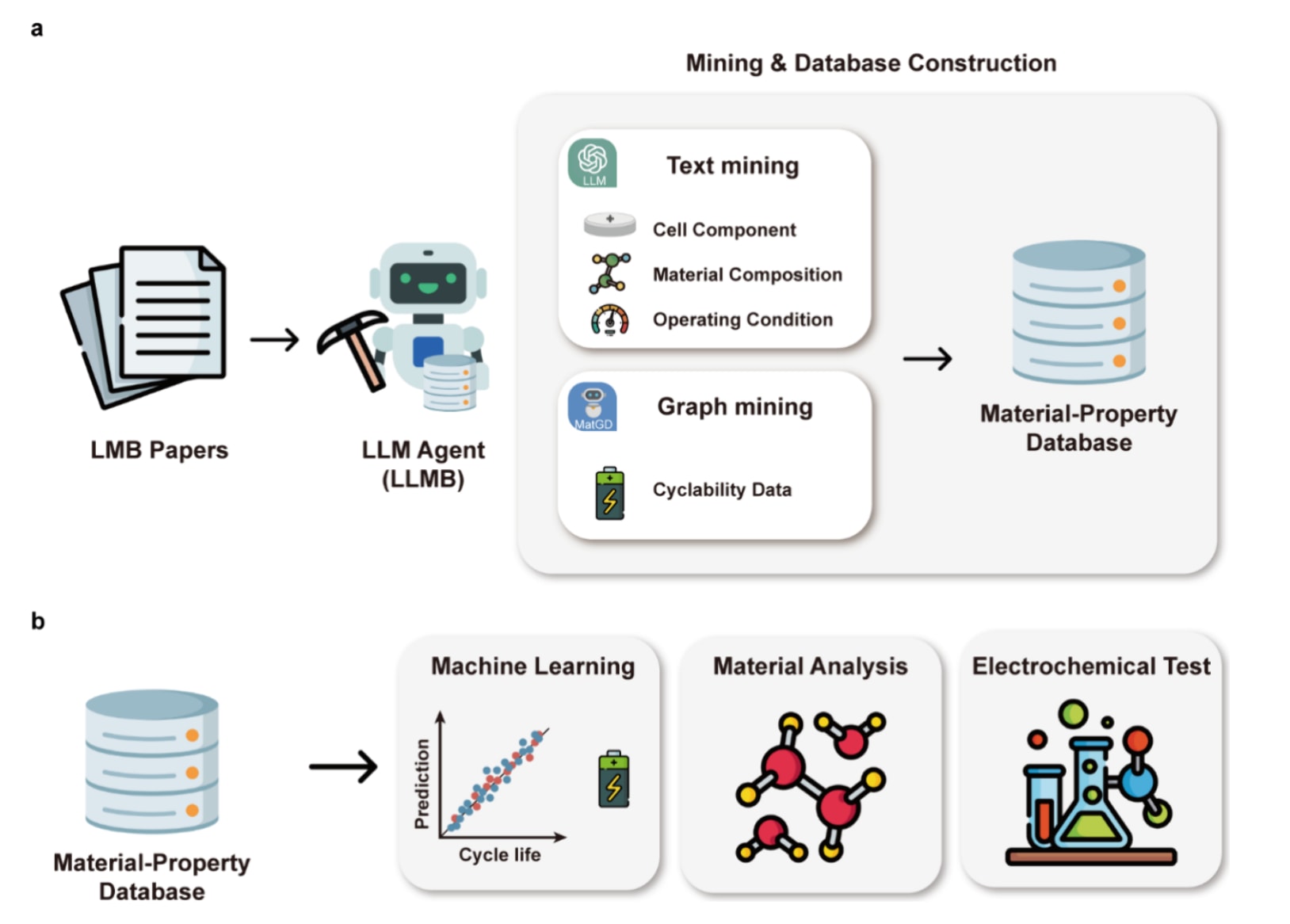
图1|电池科学中机器学习辅助的数据驱动研究方法示意图 a. LLMB 智能体从文献中自动提取文本和图结构数据。各阶段收集与电池材料及性能相关的信息,包括电池组成、材料成分、操作条件以及循环性能。 b. 构建的数据库用于机器学习、分子模拟与材料分析。
2 结果和讨论
2.1 总体工作流程
该研究的整体工作流程如图1所示。首先,采用基于LLM的人工智能智能体LLMB,对3606篇与锂金属电池相关的论文进行文本与图像相结合的多模态自动挖掘。电池研究论文通过Scopus API获取,重点选取Elsevier期刊,以在保证出版格式多样性的同时尽量减少版权与成本问题。该方法实现了对单个电池材料—性能信息的全面提取。
在文本挖掘过程中,提取了与材料相关的信息,包括电池组分、材料组成以及操作条件。在图像挖掘过程中,重点提取电池性能数据,尤其是循环性能数据。通过将文本挖掘得到的材料信息与图像挖掘获得的性能数据进行整合,构建了一个包含8074个电池单元的材料—性能数据库。该过程的更多细节见后续“人工智能智能体:电池大语言模型”部分。
为分析材料—性能关系,基于所构建的数据库,开发了一个利用材料信息预测循环寿命的机器学习模型。通过特征重要性分析和SHAP分析,识别出影响循环性能的关键材料因素。模型的预测性能通过实验验证得到确认。此外,还基于挖掘得到的数据开展分子模拟,以研究电解液在原子尺度上的行为。通过这一集成方法(图1b),加深了对电池组分与循环性能之间关系的理解。
基于机器学习分析与分子模拟获得的认识,设计了一种新的溶剂分子,以优化循环寿命。其性能通过实验测试得到验证,结果表明该分子在提升电池性能方面具有有效性。
2.2 人工智能智能体:电池大语言模型
开发了一种基于LLM的自动化人工智能智能体LLMB,可从电池研究论文的文本和图像中提取全面的电池信息,并将其整合为结构化数据库。LLMB智能体通过三个主要阶段运行:(1)文本挖掘,(2)图像挖掘,以及(3)数据库构建。为高效执行这些任务,LLMB采用模块化架构,由多个LLM组成(未进行微调的GPT-4模型),每个模型在整体流程中负责特定任务。
为识别单个电池单元,电池名称提取语言模型首先从实验图的图注中识别用于循环测试的电池单元及其对应的图编号。提取的电池单元名称和图编号作为核心标识,用于区分后续挖掘过程中的目标电池单元。为进一步保证可追溯性,还将从XML文件中获取的元数据(如DOI)作为标签引入,以辅助识别每个电池单元。
与电池组分相关的信息(如电池组成、材料组成和操作条件)在论文中分散出现,分布于图注、结果和方法部分。为高效提取文本中的相关信息,采用了分层架构,将多个针对特定任务的语言模型进行集成。在文本挖掘的起始阶段,使用Python脚本从方法和结果部分中提取与目标电池单元相关的段落。这些提取的段落随后依次作为输入传递给一系列语言模型,用于分类和数值提取。在分类模型中,每个段落根据其所包含的信息类型进行分类,该过程包括主分类和子分类。分类后的段落被传递至对应的数值提取语言模型。针对每一类别,构建了专门的提示语言模型,用于提取该组分类型对应的相关性质及其单位,从而实现有针对性且准确的信息提取。所得数据共包含29类实体,包括材料名称、性质数值及其单位。
在图像挖掘阶段,采用了自动图像数字化模型MatGD。循环曲线图通过MatGD进行处理,去除文本标签、标记、箭头等非数据元素,仅保留数据曲线。当图中存在库仑效率(CE)曲线时,基于Python算法利用其通常位于循环图顶部这一特征将其移除。该筛选过程使得仅提取与各电池单元对应的循环性能数据成为可能。每条提取的数据曲线均与对应的图例标签一同保存。
最后,利用数据匹配语言模型对文本挖掘与图像挖掘结果进行整合,其输入分别为两种方法提取的电池组分名称和数据曲线标签。材料和操作条件等区分性特征隐含于标签之中,这些特征对于区分不同电池单元具有关键作用。该方法在与名称对齐时能够保证较高的合并准确率。同时,该过程还对前序步骤中生成的虚假电池单元进行了修正。为支持材料分析和机器学习建模等下游任务,进一步引入了后处理模型。该模型用于处理数千篇文献中存在的命名方式和单位差异问题。对于由分子或聚合物构成的组分(如粘结剂、导电材料和电解液),将其名称转换为简化分子线性输入规范(SMILES)格式,以文本字符串形式编码分子结构。最后,对于涉及不同量纲的单位(如电解液浓度和体积比),通过分子量和密度进行统一换算。
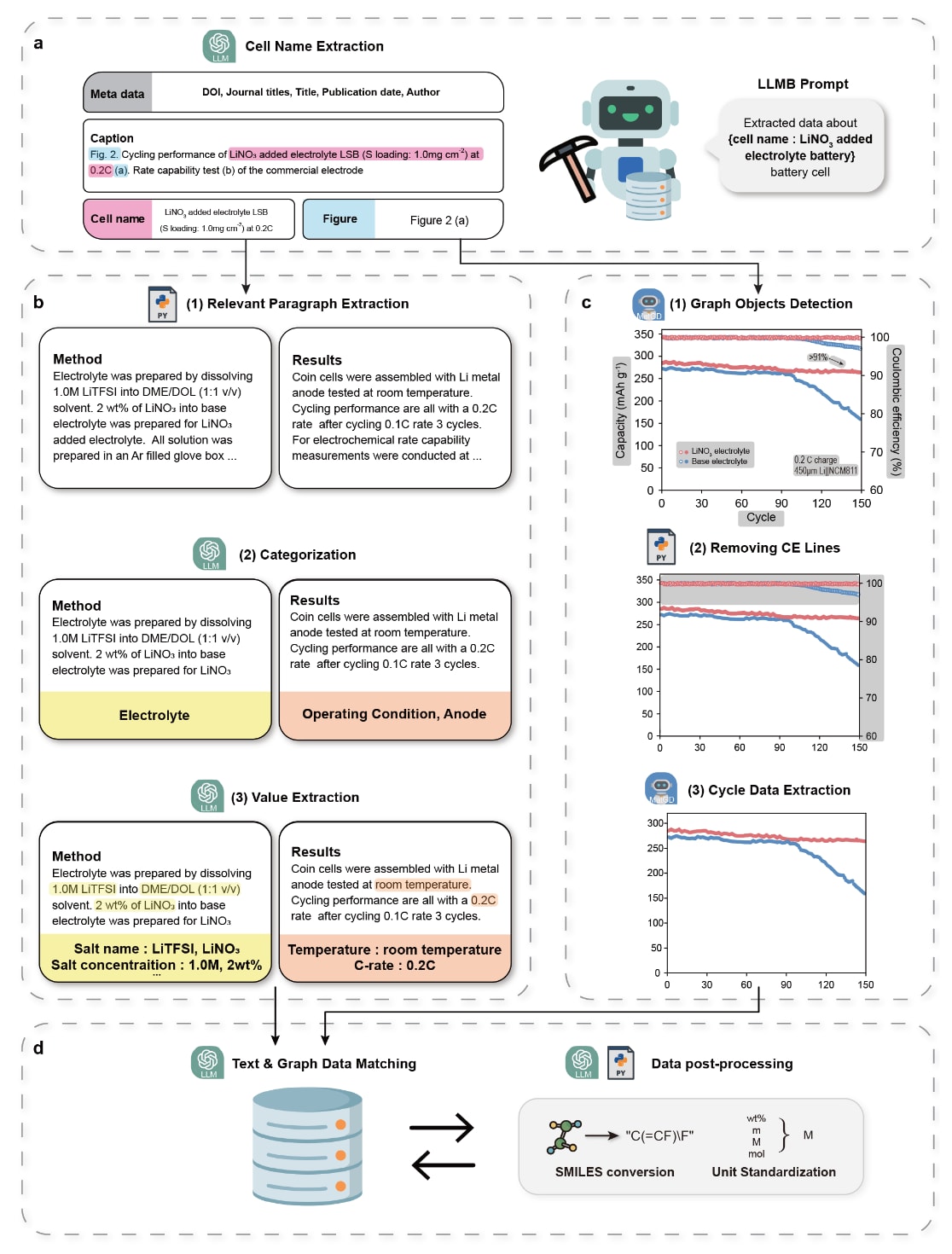
图2|LLMB 智能体的示意图 a. 电池名称提取语言模型示例,用于提取电池名称和图编号。 b. 文本挖掘阶段示例。通过由文本解析、分类和数值提取组成的逐步语言模型,提取材料组成数据。 c. 利用 MatGD 从图像中逐步提取循环性能数据点的过程。 d. 文本与图数据匹配语言模型的示意图,并附有元数据、电池名称、图编号和材料名称标注。为促进有效的下游分析,还进行了后处理,包括将收集的材料名称转换为 SMILES 以及单位标准化。
2.3 数据挖掘性能
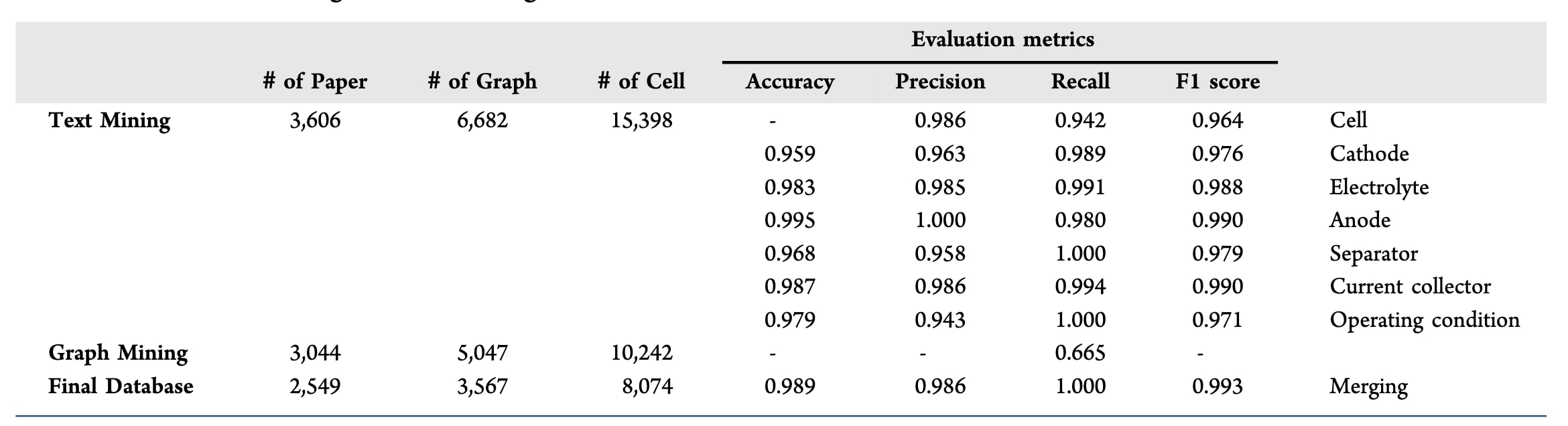
LLMB智能体性能的统计结果和评估指标汇总于表1。为评估各阶段(即文本挖掘、图像挖掘和数据库整合)的准确性,对提取的论文数量、图像数量以及电池单元数量进行了统计,并使用标准指标对各步骤进行评估,包括准确率、精确率、召回率和F1分数。总体而言,从Elsevier期刊获取的3606篇锂金属电池(LMB)论文中共提取了15398个电池单元。
为评估文本挖掘过程的性能,从100篇论文中随机选取384个电池单元进行人工分析。各组分的提取均表现出较高性能,其中集流体识别的F1分数达到0.990。即使是性能最低的类别,即电池名称提取,其F1分数也达到0.964。由于文本挖掘智能体具有较高准确性,文本挖掘阶段提取的电池单元数量被用作评估图像挖掘召回率的基准值。
在已识别的15398个电池单元中,利用MatGD成功提取了10242个电池单元的循环性能数据,对应召回率为0.655。该召回率反映了MatGD基于颜色的图像分离方法的局限性,该方法可能限制可提取数据点的数量。所有提取的循环性能数据均经过人工验证以确保准确性,从而保证数据库的可靠性。在对选定论文中的265个文本—图像匹配结果进行评估时,F1分数达到0.993。
综合来看,这些评估结果表明所提出的文本与图像联合挖掘策略具有较高的效率和鲁棒性。基于LLMB智能体,成功构建了一个经过验证的数据库,其中包含8074个电池单元的组分信息和循环性能信息。
表1|提取的论文、图像和电池数量汇总,以及挖掘过程各阶段的准确率、精确率、召回率和 F1 分数
2.4 提取数据的定量分析
通过LLMB,从锂金属电池研究论文中收集了多种研究主题。首先,使用无监督模型潜在狄利克雷分配(LDA),基于论文的标题和摘要识别LMB论文的主要主题。结果识别出25个不同主题,并按照所修饰材料的类型进行分组。与电解液相关的主题最为常见,频繁出现的关键词包括“lithium metal”“high performance”“stability”和“ionic conductivity”,表明研究重点在于提升负极的循环稳定性。这些结果表明,锂金属电池研究主要集中在电解液以提升循环稳定性,其次是以提高容量为目标的正极材料。
电解液材料及其对应容量保持率的年度变化趋势显示,随着时间推移,所研究的溶剂和盐的种类不断扩展,同时容量保持性能也得到提升。基于醚类和碳酸酯类的溶剂及其对应盐类(如LiTFSI、LiNO3和LiPF6)被最频繁使用。溶剂与盐的组合关系进一步反映了这一趋势,并围绕正极兼容性对其关系进行了分析,重点关注氧化稳定性和工作电压需求。
通过整合文本与循环曲线数据,识别出不同正极材料的容量变化趋势。NCM和LFP正极的初始容量显著低于硫正极(约150−200 mAh g−1),而硫正极具有更高的理论比容量1675 mAh g−1。三种正极的寿命末期性能对比表明,LFP和NCM通常表现出优于硫基锂金属电池的长期稳定性。这与锂硫电池的已知局限性一致,即尽管在较低倍率下运行,其循环稳定性仍较差。这一现象归因于多硫化物的溶解以及穿梭效应,在长时间循环过程中导致活性物质损失和副反应发生。
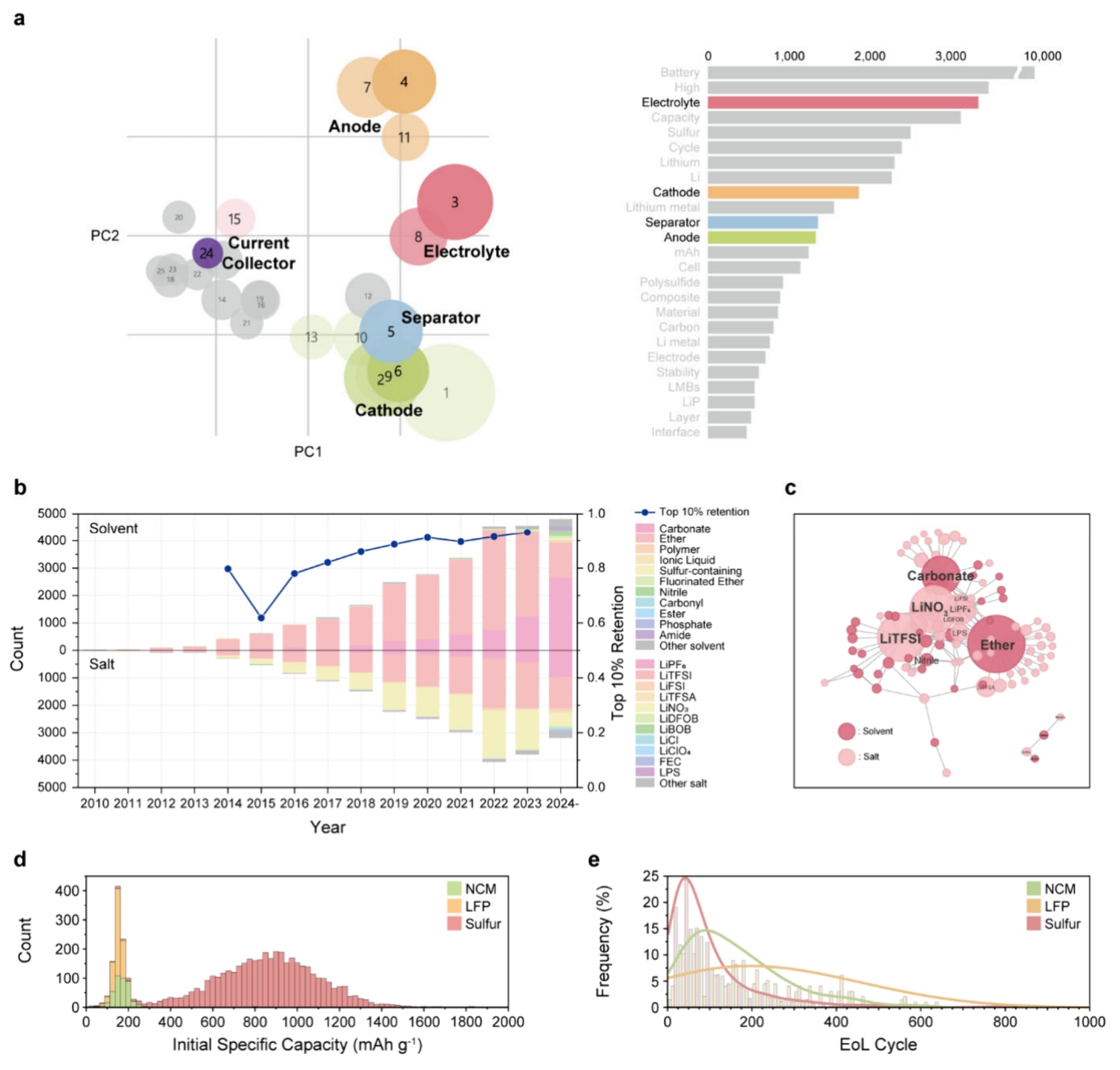
图3|锂金属电池的发展趋势与研究探索 a. 基于 LDA 分析得到的锂金属电池论文主题间距离图及其分布。 b. 对 3,606 篇论文中不同电解液溶剂和盐材料分布的堆叠直方图,折线表示不同年份容量保持率前 10%。 c. 溶剂与盐之间的力导向网络图,出现频率更高且常共同使用的分子显示得更大且彼此更接近。 d. 初始容量的直方图(8,687 个电池)以及 e. 合并数据库中的寿命终点(EOL)数据(1,736 个电池),其中 NCM、LFP 和硫正极电池分别以绿色、橙色和红色表示。
2.5 机器学习结果
基于挖掘得到的材料—性能数据库,对材料组成、操作条件以及溶剂化结构进行了量化处理以构建输入特征。此外,将分子特征与通过RDKit获得的物理化学描述符相结合,构建了579维输入向量。采用机器学习方法预测初始容量和第50次循环容量,并通过实验测试对预测结果进行验证。
初始容量预测中,随机森林(RF)模型在NCM正极初始容量预测中取得最高性能,
SHAP分析表明,正极中Ni、Mn和Co的化学计量比是最重要的输入特征。过渡金属的氧化还原反应直接涉及电子转移,是容量的主要来源。Mn
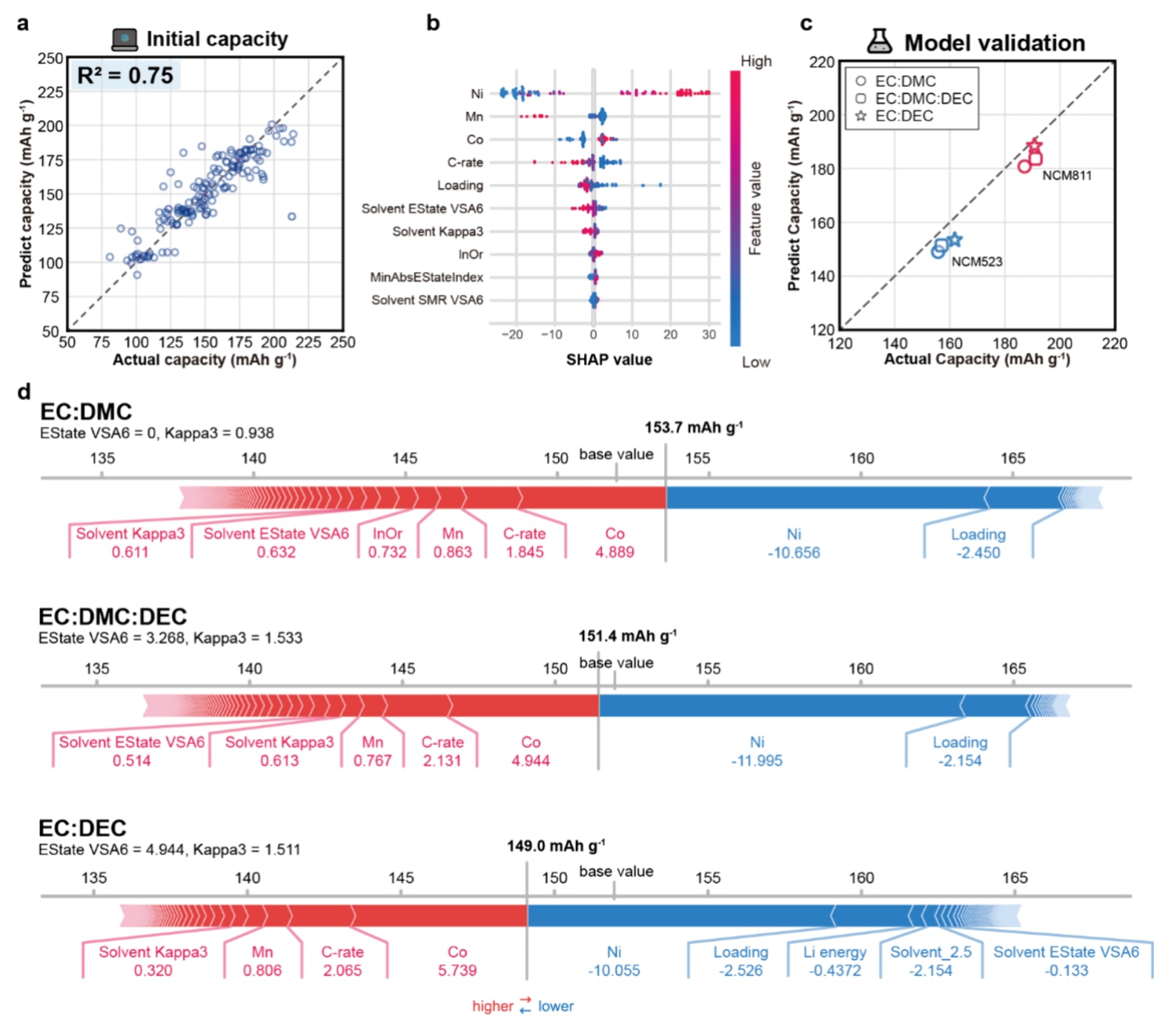
图4|初始容量预测与分子结构分析 a. 基于随机森林模型对初始容量的预测结果(使用挖掘数据库)。 b. SHAP 分析结果。 c. 在 1C 倍率下对 NCM523 和 NCM811 正极初始容量的实验验证,其中圆形、方形和星形分别表示 EC:DMC、EC:DMC:DEC 和 EC:DEC 体系中的 1 M LiFSI。 d. 针对 NCM523 正极在不同电解液体系下的系统参数分析(对应 c 部分)。红色和蓝色箭头分别表示该特征对初始容量预测的正向和负向贡献,每个特征下方的数值表示其 SHAP 值。
除上述特征外,电解液的分子特征同样影响初始容量,其中EState VSA6和Kappa3在SHAP值分布中表现出较大差异。EState VSA6表示EState值在1.54至1.81之间的原子表面积。该范围内的原子通常具有接近零的部分电荷,这是由于电子向邻近氧原子的转移所致,该过程增强了分子的极性。Kappa3表示分子结构复杂度,并与EState VSA6呈正相关。在SHAP分析中,较低的EState VSA6和Kappa3值与初始容量呈正相关。在高倍率和高Ni正极条件下也观察到类似趋势。
为验证模型,将不同正极和电解液组成的电池初始容量实验结果与模型预测结果进行对比,结果显示两者具有良好一致性。进一步通过比较不同电解液体系下NCM523电池的特征贡献,分析电解液分子结构的影响。结果表明,在EC:DEC体系中,较高的EState VSA6值对初始容量产生负面影响,而随着EState VSA6降低,其他溶剂表现出更高的正向贡献。这表明溶剂极性会影响充放电初期Li
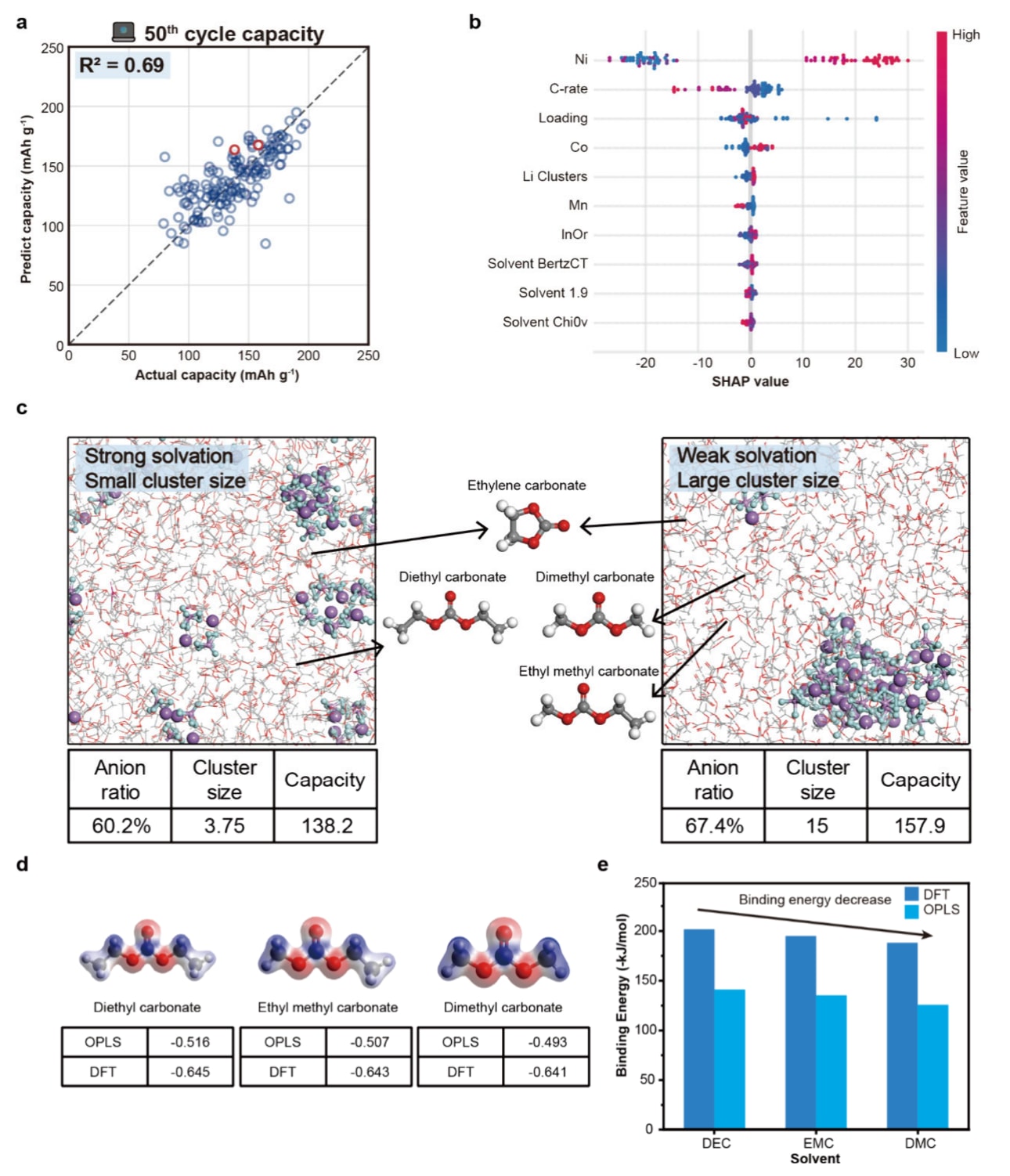
图5|第 50 次循环容量预测与溶剂化结构分析 a. 基于挖掘数据库的随机森林模型对第 50 次循环容量的预测结果。 b. SHAP 分析结果。 c. 不同溶剂体系下 NCM811 电池的分子动力学(MD)模拟溶剂化结构,其中氧、碳、氢、氟、磷和锂原子分别以红色、灰色、白色、青色、紫色和紫罗兰色表示。 d. 基于 OPLS 和 DFT 计算得到的 DEC、EMC 和 DMC 分子的原子电荷分布。 e. 通过 MD 和 DFT 计算得到的 Li⁺−溶剂结合能(红色和蓝色分别表示电子积累与电子耗减;等值面设置为 0.05 e Å⁻³)。
第50次循环容量预测中,构建了用于预测第50次循环容量的模型。随机森林模型在NCM正极中取得
分子动力学模拟显示,在相同测试条件下,不同溶剂体系中Li
基于上述分析,设计并评估了新的溶剂体系以验证模型预测。选择了三种未包含在原始训练数据中的非氟化醚类溶剂:二乙醚(DEE)、二丙醚(DPE)和二甘醇二甲醚(DEGDME)。与DEGDME相比,DEE和DPE的EState VSA6和Kappa3值显著较低,表明其极性更弱。DFT计算结果表明,DEE和DPE的Li
基于较低极性和较弱溶剂化能力,DEE和DPE被认为具有更优电化学性能。实验结果表明,在1C电流密度下,DEE和DPE电解液表现出更高初始容量和更稳定的循环性能,而DEGDME体系容量衰减较快。
冷冻透射电子显微镜结果显示,DEE和DPE体系形成了均匀致密的SEI层,其厚度约为8和9 nm,并含有Li
结果表明,低EState VSA6和弱溶剂化电解液有利于形成阴离子主导的SEI组分,而高极性、强溶剂化电解液由于大量有机溶剂分子与Li
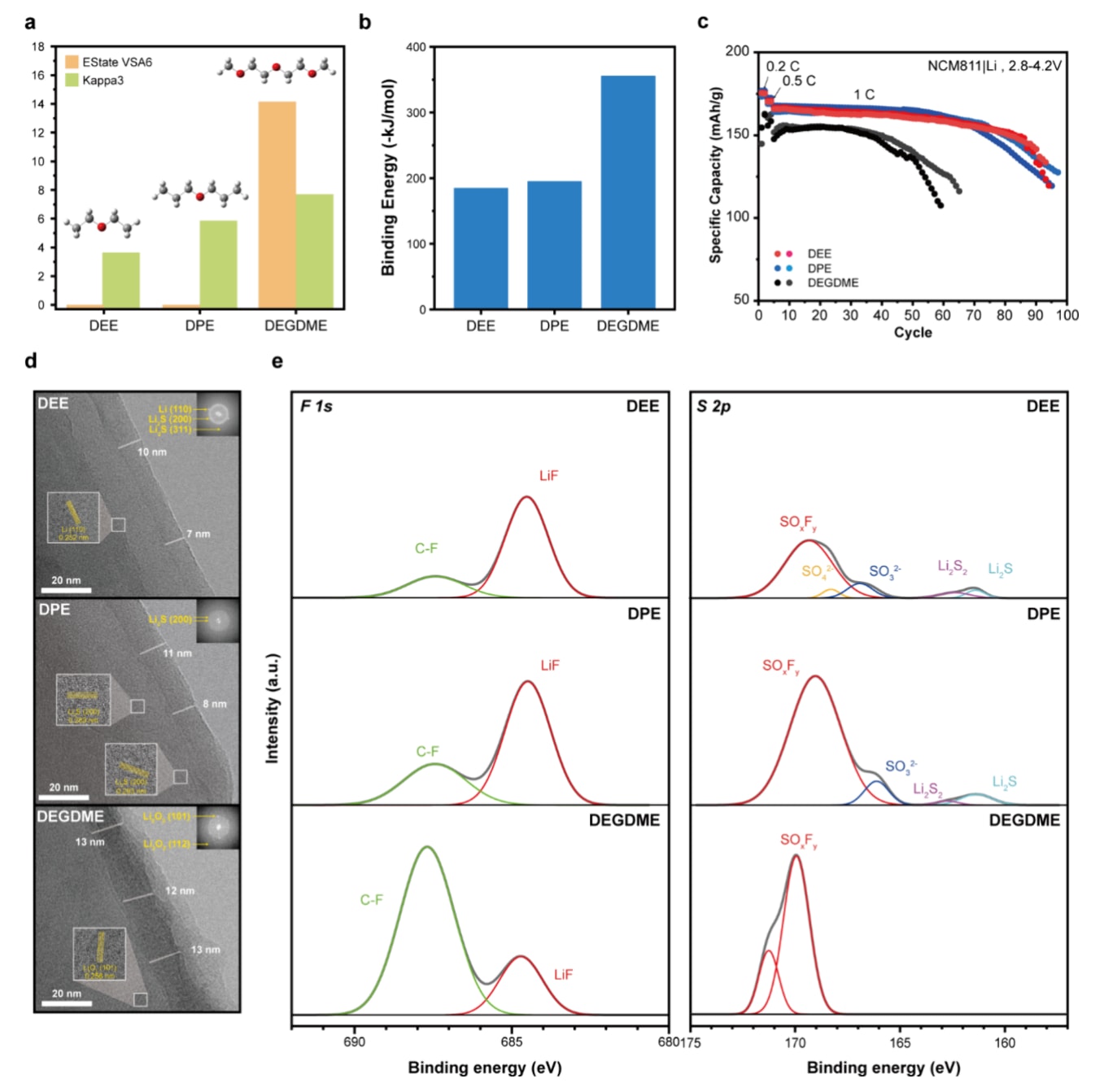
图6|溶剂化效应对循环性能与 SEI 形貌的影响 a. 溶剂的分子特征(EState VSA6 和 Kappa3)及其结构。 b. 溶剂的 Li⁺ 结合能。 c. 在 1C 倍率下,采用 2 M LiFSI DEE、2 M LiFSI DPE 和 2 M LiFSI DEGDME 电解液的 Li||NCM811 扣式电池循环性能(预先进行 0.2C 和 0.5C 的两个预循环)。 d. Li 金属沉积(1C)形成的 SEI 层的冷冻透射电子显微镜(cryo-TEM)图像,插图为对应的快速傅里叶变换(FFT)图像。 e. 在 DEE、DPE 和 DEGDME 电解液体系下循环后的电池 SEI 层中 F 1s 和 S 2p 信号的去卷积 XPS 光谱。
2.6 向锂硫电池的扩展
为将数据驱动方法扩展至锂硫电池(LSB),基于挖掘数据考虑了该体系独特的结构复杂性。在LSB中,硫被引入宿主材料中,而宿主材料的结构与性质对容量性能具有关键影响。然而,将多样化的宿主复合结构表示为机器学习输入仍然是一个重要挑战。与以往方法类似,若忽略宿主材料信息,仅依赖其他电池组分,则难以准确预测LSB的比容量。因此,将LSB电池的初始容量作为输入特征,用以表征宿主材料特性。该方法实现了对第100、200和300次循环长期比容量的准确预测。在第200次循环预测中,使用了包含752个LSB电池数据的数据集,并按70:30划分为训练集和测试集。梯度提升回归(GBR)模型在第200次循环预测中取得
为评估模型性能,对13种不同LSB电池进行循环测试,这些电池在正极、电解液用量及倍率方面存在差异,且未包含在训练数据中。模型预测结果与实验结果具有良好一致性。部分电池(编号3和9)预测精度较低,其循环曲线表现出斜率突变和较长的活化阶段等不稳定行为,表明可能存在组装相关问题。这类异常在实际数据中较为常见,但在文献中较少报道,因此未包含在文本挖掘数据集中。
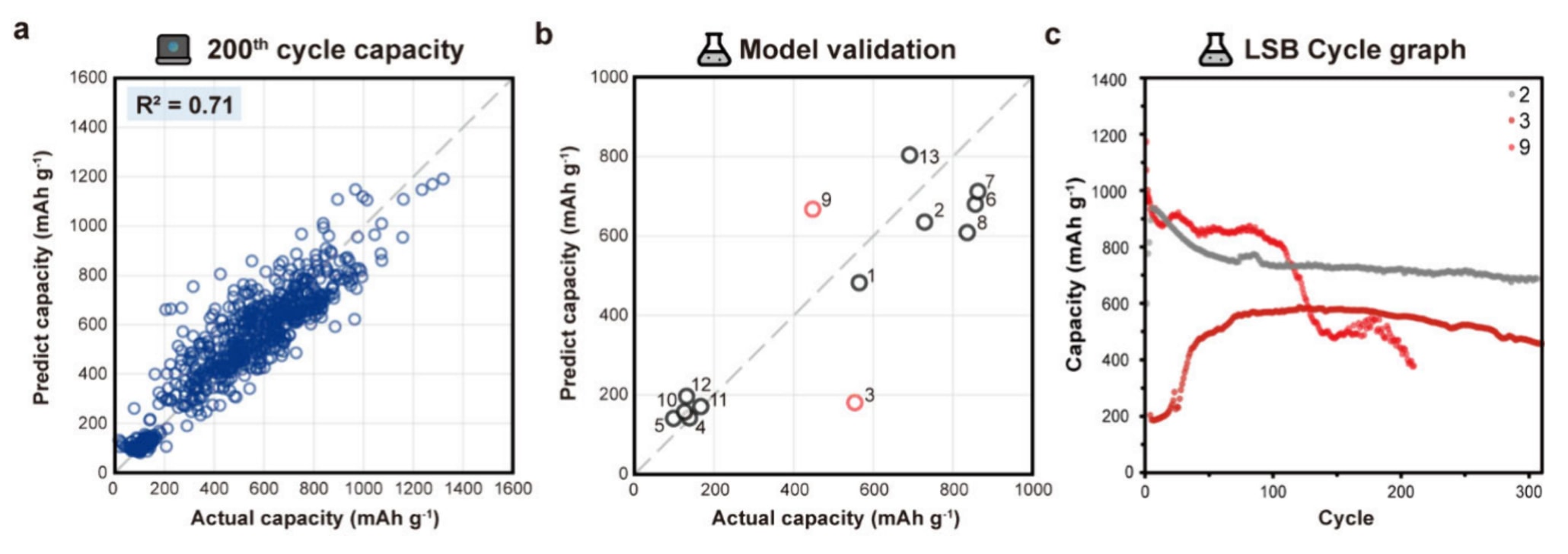
图7|锂硫电池中第 200 次循环容量的预测与实验验证 a. 基于 GBR 模型对锂硫电池第 200 次循环容量的预测结果。 b. 预测值与实际容量的实验对比结果,其中红色数据点表示异常值。 c. 代表性电池的循环性能曲线,突出显示异常电池(红色)与正常电池(灰色)。
3 结论
在该研究中,开发了LLMB智能体,用于从研究论文中自动提取电池信息。通过在分层LLM架构下整合文本挖掘与图像挖掘模型,克服了器件层面数据提取中的关键挑战,包括准确性不足、难以从图像中提取性能数据以及缺乏器件层级挖掘框架等问题。基于提取的数据,构建了能够在循环测试之前根据材料组成和操作条件预测电池容量的早期预测机器学习模型。LLMB使原始数据能够转化为关于电解液性质、容量以及锂沉积行为之间关系的认识。结果表明,低极性、弱溶剂化溶剂可以提高初始容量,并促进稳定且具有结晶特征的锂沉积,这一结论也通过实验验证得到支持。
从数据提取到电化学分析的整体流程表明,LLMB智能体不仅是一种数据挖掘工具,同时也是数据驱动电池材料发现的基础。该框架的预测能力还可以通过增加高质量、系统整理的数据集进一步提升。LLMB提取的部分特征由于报道较少,未能纳入机器学习模型中,例如与锂金属负极相关的一些参数,这些参数被认为对电池性能具有重要影响但数据数量不足。通过更加标准化的数据报告以及结合自驱动实验室生成补充数据,有望加速材料创新在更广泛科学领域中的发展。