Acc. Chem. Res. 2024 | 利用深度学习推进配体对接: 虚拟筛选中的挑战与前景
今天介绍的是发表在Accounts of Chemical Research上的一篇综述,主题是利用深度学习推进配体对接在虚拟筛选中的应用、挑战与前景。配体对接(LD)是结构基础虚拟筛选(SBVS)的关键步骤,传统方法依赖“搜索-打分”框架,往往在效率和精度之间难以兼顾。随着深度学习(DL)的发展,研究者逐渐突破传统模式,将图神经网络(GNN)、扩散模型等方法引入配体对接,显著提升了结合构象预测的速度与准确性。文章系统梳理了基于深度学习的打分函数与构象生成方法,总结了代表性模型(如DiffDock、EquiBind、KarmaDock)的性能与应用,并探讨了它们在泛化能力、物理合理性和复杂环境建模等方面的不足。最后,作者展望了DLLD的未来方向,包括在速度与精度间寻找平衡、融合生成式与回归式模型、以及考虑溶剂和金属离子等生理环境因素,为推动虚拟筛选与药物发现提供了重要启示。
Zhang, X.; Shen, C.; Zhang, H.; Kang, Y.; Hsieh, C.-Y.; Hou, T. Advancing Ligand Docking through Deep Learning: Challenges and Prospects in Virtual Screening. Acc. Chem. Res. 2024, 57 (10), 1500–1509. https://doi.org/10.1021/acs.accounts.4c00093.
0 摘要
分子对接,也称为配体对接(LD),是结构基础虚拟筛选(SBVS)中的关键环节,用于预测蛋白质-配体复合物的结合构象与亲和力。传统的LD方法依赖“搜索-打分”框架:利用启发式算法探索结合构象,再通过打分函数评估结合强度。然而,为满足SBVS的效率需求,这些算法和函数往往被简化,速度优先于精度。
深度学习(DL)的出现对自然语言处理、计算机视觉以及药物发现等领域产生了深远影响。DeepMind的AlphaFold2展示了其仅凭氨基酸序列即可准确预测蛋白结构的能力,凸显了DL在构象预测中的巨大潜力。这一突破绕过了LD中的传统搜索-打分框架,显著提升了预测精度与处理效率,从而推动DL算法在结合位点预测中的广泛应用。然而,某些方面仍缺乏共识。本文梳理了DL在VS框架中增强LD的现状,并结合已有研究成果探讨挑战与未来发展方向。
首先,文章概述了VS与LD的背景,并介绍了与传统框架差异显著的DL范式。随后,深入分析DL驱动的配体对接(DLLD)所面临的挑战,包括评价指标、应用场景以及预测构象的物理合理性。在算法评价方面,结合构象预测的精度(通常以成功率衡量)固然重要,但LD工具在VS中的地位使得打分/筛选能力与计算速度同样不可或缺。在应用场景上,早期方法聚焦于未知结合位点的盲对接,但近期研究显示,识别结合位点逐渐成为重点,相比之下,已知口袋的LD在VS中更具实用性。
物理合理性则构成另一大挑战。DLLD模型虽然往往比传统方法取得更高成功率,但可能生成局部结构不合理的构象,例如错误的键角或键长,这在可视化等后处理任务中十分不利。
最后,文章展望了DLLD的未来发展,强调需提升泛化能力、在速度与精度间寻求平衡、考虑蛋白质构象柔性,并增强物理合理性。同时,还讨论了生成式算法与回归式算法在该领域的对比,探索其各自优势与潜力。
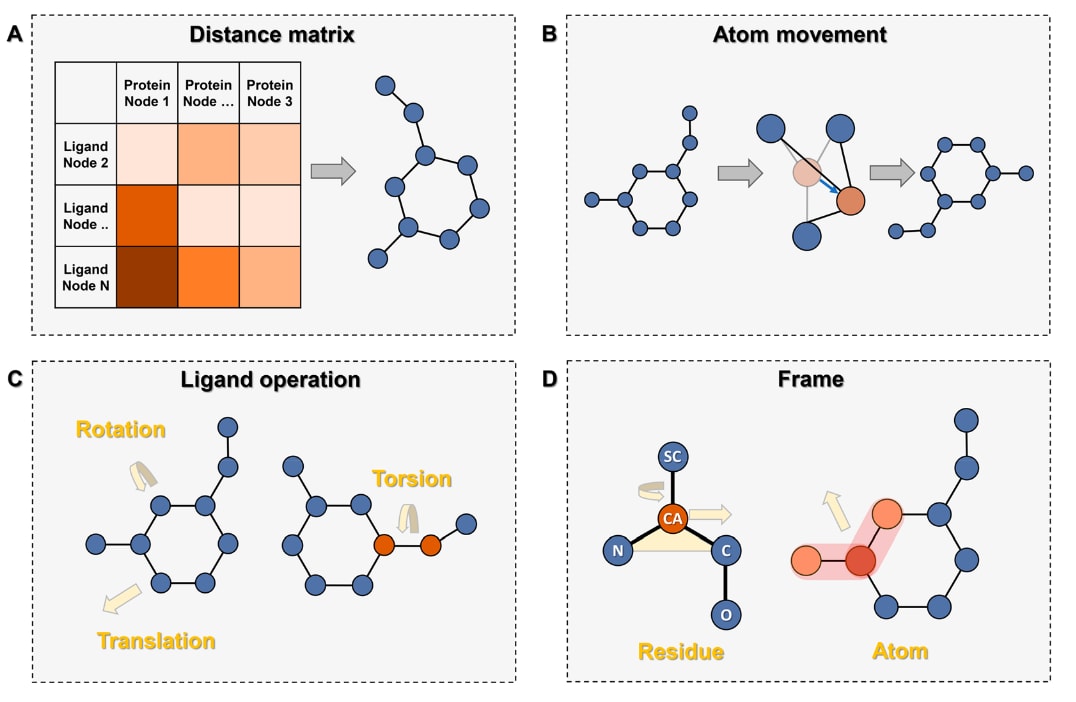
图1 | 深度学习在配体对接中的策略 (A) 通过预测蛋白-配体(PL)距离矩阵,并利用如梯度下降等优化算法生成PL结合构象。(B) 在每次消息传递迭代中预测配体原子的移动与方向。(C) 预测配体的平移、旋转与扭转,方式类似传统对接工具。(D) 构建蛋白与配体的组装框架,并结合基序运动的预测;图中SC表示侧链原子。
1 引言
虚拟筛选(VS)大致可分为两类主要方法:基于结构的虚拟筛选(SBVS)与基于配体的虚拟筛选(LBVS)。二者的区别在于是否利用蛋白质的三维(3D)结构信息:SBVS使用该信息,而LBVS则不使用。与LBVS相比,SBVS通常在计算效率上较低,但由于结合了蛋白质的三维结构,因此在发现具有更高多样性与新颖性的化合物方面更具优势。SBVS涵盖的技术包括分子对接、基于结构的药效团建模以及分子动力学模拟。其中,配体对接(LD)作为SBVS的核心环节,在蛋白-配体(PL)结合构象生成、结合亲和力预测、结合构象筛选及VS中都发挥着关键作用。
传统的对接方法多采用“搜索-打分”框架:通过搜索算法探索配体可能的构象,再借助打分函数(SFs)选择最优结合姿态并估计结合强度。为提升大规模VS的效率,常以遗传算法(GAs)等启发式方法替代穷举搜索,但这种方式存在遗漏关键结合构象的风险。同时,使用简化的力场(FFs)及经验能量项来估算结合能,往往会降低精度。过度简化的搜索算法与打分函数可能导致结合构象与亲和力预测不准确,从而削弱VS的富集能力。
深度学习(DL)的出现推动了包括自然语言处理、计算机视觉与药物发现等多个领域的变革,对配体对接亦有显著影响。几何图神经网络(GNN)的引入进一步提升了LD性能,凭借其强大的表征能力以及对物理对称性的内在偏好(如等变神经网络的应用),这一创新有望绕过传统“搜索-打分”范式,从而实现更高精度与更快速度的对接预测。
表1 | 各类图神经网络的消息传递机制

2 当前研究格局
2.1 基于深度学习的打分函数协议
在推动配体对接(LD)方法的发展之前,深度学习算法已被广泛用于开发基于深度学习的打分函数(DLSFs)。其中,基于图神经网络(GNN)的代表性模型包括IGN、PIGNet、DeepDock和RTMScore,它们在预测精度上表现突出。IGN通过构建蛋白与配体的交互图,直接预测结合亲和力;PIGNet预测受物理启发的能量项参数,并将其求和得到结合亲和力;DeepDock利用混合密度网络(MDN)学习蛋白-配体节点间的距离分布,并通过概率总和评估结合强度;RTMScore在DeepDock的MDN模块基础上进行了改进,通过更强的图表征与网络架构提升了对接能力与筛选能力。
虽然这些模型在Cheng与Li提出的四大指标(即打分能力、排序能力、筛选能力和对接能力)中能超越传统打分函数,但尚无DLSF能在所有方面均表现优异。为此,研究者扩展了RTMScore,提出了通用蛋白-配体打分框架(GenScore),在MDN训练中引入可调节的结合亲和力项。GenScore不仅保持了RTMScore在对接/筛选上的优势,还在亲和力预测与排序任务上展现了更强性能。
2.2 基于深度学习的结合构象生成协议
2020年,Mahmoud等人提出了首个深度学习驱动的配体对接模型(DLLD)——PoseNetDiMa,通过预测蛋白-配体距离矩阵并经后处理生成结合构象。虽然当时未受到广泛关注,但AlphaFold2在蛋白质结构预测上的突破极大激发了研究者将DL应用于配体构象预测的兴趣。到2022年,Stärk等人提出EquiBind,利用E(n)等变图神经网络(EGNN)架构迭代优化配体原子坐标,取得显著进展。随后,Lu等人提出TankBind,延续PoseNetDiMa的距离矩阵预测思路,并通过优化算法生成结合构象。然而,这些方法因在原子层面建模,常出现物理约束不合理的问题,例如键角或键长异常。
为解决此问题,Corso等人提出DiffDock,采用扩散模型来预测配体的平移、旋转和扭转,更接近传统对接工具,提升了生成构象的物理合理性。尽管如此,除EquiBind外,大多数DL模型主要在盲对接场景(结合位点未知)中表现更优,而在实际VS应用中,结合口袋往往已知或可通过实验及预测工具获得,因此口袋已知的对接更具实用性。针对这一挑战,LigPose提出了一种口袋引导方法,结合EGNN与自注意力机制生成结合构象并预测亲和力,在成功率与速度上优于传统方法,但物理合理性仍有限。
为进一步改进,研究者提出KarmaDock,在保证速度与精度的同时,通过后处理确保生成构象的物理合理性。KarmaDock沿袭LigPose的思路,利用具备自感知能力的EGNN生成结合构象,并采用MDN而非线性层预测亲和力。其关键创新在于在EGNN前对MDN进行预训练,使其学习蛋白-配体最小距离的概率分布,从而为模型引入距离先验,有助于结合构象学习。此外,KarmaDock引入了力场优化与RDKit构象比对两种后处理方法,修正键长与键角误差。在多个数据集上的评测显示,KarmaDock在计算速度、构象与亲和力预测精度及富集能力方面均显著优于传统LD工具与其他DL方法。在针对白细胞酪氨酸激酶(LTK)的实际VS项目中,KarmaDock成功筛选出活性抑制剂,并经实验验证。
然而,当处理仅有游离态蛋白(apo)结构或AlphaFold2预测结构时,KarmaDock及其他DLLD模型的性能显著下降。此后,一系列柔性对接方法与de novo对接方法相继提出,能够在一定程度上生成配体构象并调整蛋白结构,甚至从序列直接生成蛋白与配体的构象,但往往牺牲了速度。
总体而言,DLLD生成结合构象的方式可分为四类:
- 预测蛋白-配体距离矩阵,并结合优化算法(如梯度下降)生成结合构象,如TankBind与EDM;
- 在消息传递迭代中通过EGNN预测配体原子的运动方向,如KarmaDock与EquiBind;
- 构建蛋白与配体的框架,并结合基序运动预测,类似AlphaFold2的思路,如AlphaFold最新版本、RoseTTAFold-All-Atom与Umol;
- 利用去噪扩散概率模型(DDPM)预测配体的平移、旋转与扭转,如DiffDock与DynamicBind。
其中,方法1-3通常将LD视为回归任务,需依赖能量最小化等后处理来保证键长与键角的合理性;方法2的模型(如KarmaDock)在速度上通常最快,适合大规模VS;方法4则利用生成式DL算法直接生成多样化构象,往往能更好保持物理合理性。
2.3 数据集
与DLSFs类似,PDBbind数据库(包含19,443个高质量蛋白-配体复合物及其结合亲和力信息)被广泛用于KarmaDock及其他LD模型的训练与评估。由于PDBbind的general set与core set之间具有高度序列相似性,难以直接采用DLSFs中常用的训练-测试划分方式。KarmaDock还尝试了EquiBind提出的时间划分方法:将2019年之后发表的复合物作为测试集,其余作为训练/验证集。然而,DL方法在预测新型复合物构象时仍存在局限,常导致局部结构不合理或结合构象错误。为此,PoseBusters被引入作为额外测试集,提供更严格的指标以评估局部结构的真实性及其能量合理性。由于不同模型训练集差异较大,且部分样本可能与PoseBusters重叠,因此需要在具有不同相似度的样本上进行评测,以确保测试的严谨性。
2.4 图表示
配体、蛋白及其相互作用可以通过图表示有效刻画,包括分子图、蛋白图与交互图。在KarmaDock中,配体通常转换为分子图,其中原子作为节点,共价键作为边。节点特征(如元素类型、度、手性标签)和边特征(如键类型、长度、方向性)通常利用RDKit计算。相比之下,蛋白质有更丰富的表示方式:既可用残基/表面作为节点(粗粒度表示),也可用原子作为节点(细粒度表示)。KarmaDock选择基于残基的表示方式,原因在于:一方面,粗粒度模型不仅能编码残基类型、二面角等标量特征,还能捕捉骨架方向等几何向量;另一方面,这种表示方式能有效降低计算成本。在该框架中,边通过KNN算法定义。
当构建结合了配体与蛋白节点的交互图时,KarmaDock采用全连接图策略,即每个节点与其他所有节点相连,以应对节点间成对距离不确定性。虽然全面,但这种方法显著增加了计算量。为平衡效率与准确性,有两类改进思路:其一,在训练实例中对蛋白节点进行采样,从而减少计算负担并避免因记忆特定口袋而导致的偏差;其二,通过RDKit随机初始化构象,固定蛋白结构、变化配体构象,再基于这些构象构建KNN或半径图。这些策略旨在在计算效率与分子相互作用的精确刻画之间取得平衡。
2.5 神经网络架构
图神经网络(GNN)因其高效的计算性能与对原子间拓扑关系的天然捕捉能力,已成为DLLD方法演化的核心支柱。其核心机制是消息传递范式(见表1):沿边计算消息、聚合邻居节点的消息、再利用聚合结果更新节点特征。鉴于结合构象预测的几何属性,引入等变神经网络架构至关重要,它能在模型中注入物理对称性偏置,从而加速收敛。
等变GNN主要分为三类:基于消息传递的架构、基于向量的架构以及基于群论的架构。基于消息传递的架构以EGNN为代表(如KarmaDock采用的框架),在迭代过程中不仅更新节点标量特征,还引入方向向量,将节点间的方向矢量与标量消息相结合,生成向量消息,再经聚合用于更新节点坐标。与此类似,向量基架构(如GVP)在图构建阶段直接引入向量特征,并通过独立线性变换保持其方向属性。
基于群论的架构(如DiffDock)则利用不可约表示(irreps)保证等变性:通过节点和边特征计算边权,将距离向量投影到球谐函数的不可约表示,再通过张量积生成消息。这些消息分为标量与向量两部分,用于更新节点坐标。其中,向量更新进一步细分为平移向量、旋转向量(SO(3))和扭转向量,扭转向量可转化为旋转矩阵,使配体构象能通过平移+旋转-扭转矩阵运算完成更新。
在计算效率上,基于消息传递的架构往往更具速度优势,KarmaDock便是突出的例子,尤其适用于大规模VS。然而,该类框架容易忽略物理约束,导致部分预测构象缺乏合理性。相比之下,群论驱动的方法能在标量与向量特征上执行更复杂的运算,从而完成如旋转向量预测等高阶任务。因此,群论方法在DLLD领域中潜力更大,值得未来进一步探索。
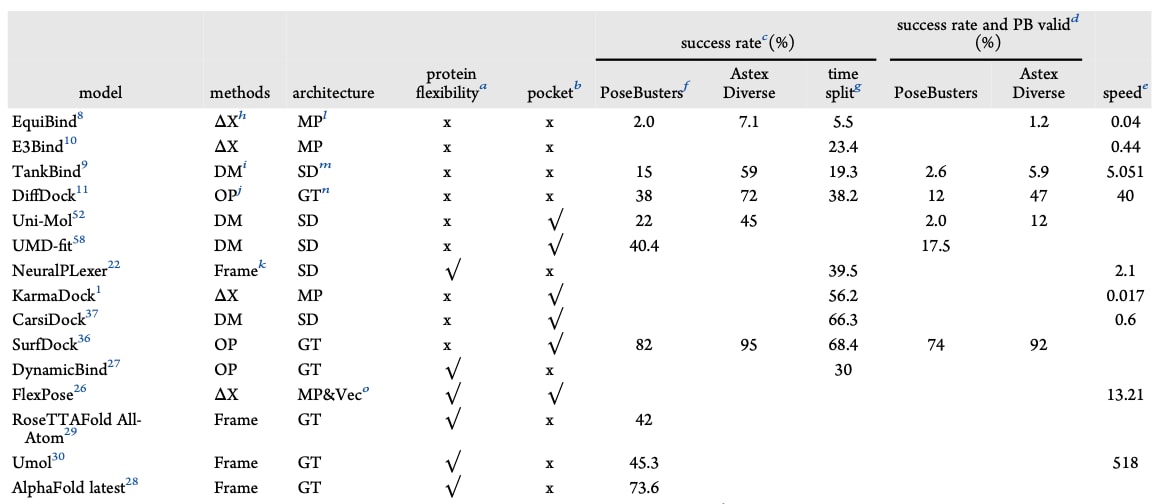
表2 | 构象生成模型的结构与性能
2.6 对接性能与实际应用
表2展示了不同DLLD方法的对接准确性(以成功率衡量)。由于各方法采用的测试集存在差异,仅列出了被普遍接受的标准测试集结果。在半柔性盲对接中,DiffDock表现最佳;在半柔性口袋特异对接中,SurfDock是效果最突出的工具;在柔性盲对接中,最新版本的AlphaFold(尚未正式发表)展现出更高成功率。而KarmaDock虽不是最准确的方法,却是速度最快的DLLD模型。需要指出的是,并非所有DLLD方法都能预测结合亲和力,因此其打分精度难以直接比较。但已有部分DLLD模型实现了结合构象与亲和力的同时预测,并在实际场景中经受了实验验证。例如,KarmaDock被应用于白细胞酪氨酸激酶(LTK)的虚拟筛选:在8.4小时内筛选约177万化合物,选出25个用于MTT实验,最终在IC₅₀阈值5 μM时获得24%的命中率,在10 μM时命中率高达72%,展现了DLLD在药物发现中的巨大潜力。
3 挑战
3.1 评价指标
在评估LD算法精度时,常以成功率作为主要指标,即预测结合构象与真实值的RMSD≤2 Å的比例。然而,仅凭成功率不足以全面衡量性能,因为LD在VS中还必须兼顾打分能力与筛选能力。打分能力指计算亲和力与实验值的线性相关性(通常用Pearson相关系数与回归标准差评估);筛选能力指从大规模分子库中区分真正结合分子的能力,常用富集因子(EF)与BEDROC指标进行衡量。少数DL方法(如KarmaDock)在CASF-2016上展示了增强的对接与筛选能力,其中的关键在于引入MDN模块学习蛋白-配体距离分布,从而更准确地评估结合强度。在DEKOIS 2.0基准中,KarmaDock的筛选精度(BEDROC=0.519)明显优于TankBind(0.107)及传统方法Glide@SP(0.378)。
随着分子库规模的急剧扩大(如ZINC20中超过2.3亿个可购化合物),亟需开发适合超大规模VS的高效方法。现有加速策略包括改进搜索算法(QuickVina 2、FWAVina)、利用GPU并行计算(Vina GPU、AutoDock GPU)、主动学习(MolPAL、Pareto优化)以及DL预测亲和力与结合构象。表2表明,KarmaDock在计算效率上具备显著优势,但总体上仍需在精度与速度间找到更优平衡。
3.2 应用场景
LD可分为两类:盲对接(结合位点未知)与口袋对接(结合位点已知)。此外,根据分子柔性程度又可细分为柔性对接(允许配体与蛋白均发生构象变化)、半柔性对接(配体可变、蛋白固定)与刚性对接(两者均固定)。早期研究多强调半柔性盲对接,希望DL能同时解决结合位点预测与结合构象生成。但最新研究发现,这类方法更偏向于结合位点识别,而非精确构象预测。而在实际VS中,结合口袋往往已知或可实验确定,因此口袋对接逐渐成为主流,并推动了相应DLLD方法的发展(如KarmaDock)。
在柔性层面,最初认为半柔性DLLD足以覆盖大部分VS场景,也与传统对接程序的设计相符。但近年来,随着仅能获取游离态蛋白(apo)结构的场景增多(如来自PDB或AlphaFold2、RosettaFold、ESMFold预测),人们对柔性对接与直接从序列生成PL复合物的de novo方法的兴趣快速增长。由于apo结构与结合态(holo)差异显著,而大多数DLLD训练于holo数据集,因而其在apo场景下泛化性有限,成为未来需要重点突破的方向。
3.3 物理合理性
物理合理性指分子构象在键长、键角以及芳香环平面性等方面是否符合已知物理规律。尽管DLLD方法(如KarmaDock)在传统精度指标(如成功率)上优于传统LD方法,但其预测的构象往往存在物理合理性不足的问题。DiffDock在这一方向上作出了开创性尝试,为后续研究提供了范例。然而,仅依赖成功率来评估合理性并不充分,还需要引入额外指标。
Buttenschoen等人提出了一系列评价指标,包括键长、键角、分子内位阻冲突,用以检验化学有效性与一致性、分子内合理性以及分子间合理性。只有通过所有检查的构象才被称为“PB-valid”。在评估DLLD方法时,应同时关注成功率与PB-valid指标。PoseBusters的研究及表2结果显示,所有DLLD方法(包括DiffDock)在经过PB-valid检查后成功率均有所下降,而传统LD方法下降幅度较小,这说明DLLD仍存在显著改进空间。
值得注意的是,DiffDock在物理合理性评价下的性能下降尤为明显。其原因包括:(1) 通过RDKit生成的初始配体构象未能满足化学有效性标准;(2) 部分预测样本偏离训练分布,导致模型泛化性下降。这些问题常表现为扭转角预测不准以及分子间冲突。这一现象在DLLD中普遍存在,已有多项研究指出DLSFs往往学习到的是数据集偏差,而非真正捕捉蛋白-配体的复杂相互作用动力学。因此,提升DLLD模型的泛化能力,是增强预测构象物理可信度的关键途径。
4 前景展望
图神经网络(GNN)在DLLD模型的发展中发挥了核心作用,使预测精度从5.5%提升至68.4%。尽管取得了显著进展,该领域仍面临亟需解决的诸多挑战。
4.1 提升泛化能力
现有DLLD方法(包括KarmaDock)普遍存在泛化能力不足的问题:在与训练集相似的样本上表现出色,但面对分布外样本时性能显著下降,甚至生成物理不合理的构象。提升泛化性的策略包括:整合现有数据集或针对不同蛋白靶点进行对接,以扩充数据量与多样性;不仅涵盖蛋白-配体复合物,还应包括纯蛋白结构与蛋白-生物分子相互作用,从而学习更普适的相互作用模式。另一种方案是在大规模对接构象上进行预训练,再在PDBbind等结晶结构上微调。简化图表示也是可行方向,避免无关特征干扰模型泛化。引入动态结合口袋与随机扰动可防止模型死记结构,增强鲁棒性。同时,架构设计同样关键,基于群论的先进架构(如AlphaFold2与RoseTTAFold的设计)有望显著提升DLLD的泛化能力。
4.2 平衡速度、柔性与物理合理性
当前的de novo方法因具备灵活对接能力,能减少对预定义蛋白结构的依赖,但在VS中应用受限于计算缓慢,且常需额外的弛豫步骤以保证结构合理性。即使如DiffDock等在结构完整性方面表现较好,也可能因扭转角修正而降低处理效率,并在分布外样本上生成局部不合理的构象。因此,研究者亟需在计算效率、蛋白柔性与结构准确性之间找到最佳平衡。对于VS而言,不必为每个化合物都预测完整的蛋白结合构象,更可行的方向是发展能高效调整已有或预测结构的柔性对接方法,如结合AlphaFold2结果进行LD。未来可探索的策略包括:开发快速原子运动预测与能量最小化方法、基于配体片段的平移/旋转运动建模、以及采用自回归方法在原子水平逐步预测配体构象。这些方向将有助于在速度与物理合理性之间实现突破。
4.3 生成式模型与回归模型
在配体对接中,生成式模型与回归模型均有应用。生成式模型能够生成多个候选构象,但其效果高度依赖于模型是否能从多样化的训练数据中学习到能量上更优的结合位置。这一过程本身就颇具挑战性,还需要借助打分函数来准确识别最优结合构象。此外,生成式模型(如扩散模型)的运行速度偏慢,难以满足虚拟筛选对高通量的需求,因此回归模型常被视为更可行的替代方案。例如,DiffDock的单次推理约需40秒,而KarmaDock仅需0.017秒,大幅缩短了计算时间,在速度与精度的权衡中展现出明显优势。
4.4 复杂环境条件
配体对接中的另一重大挑战在于准确表征复杂环境因素,如溶剂作用与金属离子存在。这些变量在传统对接策略与打分函数中往往被忽略,但它们对生物体系的真实表征以及结合能的精确计算至关重要。目前大多数DLLD方法仅能预测蛋白-配体结合构象,而未考虑这些复杂环境因素。RoseTTAFold All-Atom是首个公开可用的方法,能够同时建模蛋白、核酸、金属、小分子及共价修饰等所有生物分子实体的构象,但其仍忽视了溶剂对结合构象的影响。此外,该方法需要针对每个分子重新建模蛋白,计算效率远低于分子对接软件,因此难以适用于大规模VS。由此可见,从虚拟筛选的角度出发,发展能够融合复杂环境因素的分子对接方法具有重要意义。