Biomed. Pharmacother. 2023 | 深度学习在单细胞基因组学与转录组学数据分析中的应用
今天介绍的是发表在《Biomedicine & Pharmacotherapy》上的一篇综述论文,题为《深度学习在单细胞基因组学与转录组学数据分析中的应用》。文章系统回顾了深度学习技术在单细胞测序分析中的最新进展,涵盖基因组学、转录组学、空间转录组学以及多组学整合等多个方向。单细胞技术的出现,使研究者能够在单细胞层面解析细胞异质性与分化动态,从而揭示复杂生物系统的组织规律与疾病发生机制。然而,单细胞数据通常维度极高且噪声显著,传统分析方法难以有效处理。深度学习凭借其强大的特征提取与非线性建模能力,成为解决这一难题的理想工具。论文详细介绍了基于自编码器、变分自编码器、生成对抗网络等模型的应用,这些方法在数据去噪、批次效应校正、缺失值插补及细胞聚类等方面均取得了显著成果。研究者认为,尽管深度学习在单细胞领域仍处早期阶段,但其在跨模态数据整合与精准疾病建模中的潜力巨大,未来有望成为推动生物医学智能化的重要引擎。

Erfanian, N.; Heydari, A. A.; Feriz, A. M.; Iañez, P.; Derakhshani, A.; Ghasemigol, M.; Farahpour, M.; Razavi, S. M.; Nasseri, S.; Safarpour, H.; Sahebkar, A. Deep Learning Applications in Single-Cell Genomics and Transcriptomics Data Analysis. Biomedicine & Pharmacotherapy 2023, 165, 115077. https://doi.org/10.1016/j.biopha.2023.115077.
0 摘要
传统的整体测序方法仅能测量细胞群体的平均信号,往往掩盖了细胞间的异质性与稀有亚群的存在。相比之下,单细胞分辨率的测序技术使对复杂生物系统与疾病(如癌症、免疫系统以及慢性疾病)的理解得以深化。然而,单细胞技术所生成的数据量极为庞大,且往往具有高维度、稀疏性和复杂性,使得传统计算方法难以胜任分析任务。为应对这些挑战,研究者逐渐将目光转向深度学习(DL)方法,视其为传统机器学习(ML)算法在单细胞研究中的潜在替代方案。深度学习是机器学习的一个分支,能够通过多层结构从原始输入中自动提取高层特征。与传统机器学习相比,深度学习模型在诸多领域与应用中均展现出显著的性能提升。该研究综述了深度学习在基因组学、转录组学、空间转录组学及多组学整合分析中的应用,并探讨深度学习技术是否能在这些领域中展现独特优势,或面临单细胞组学特有的挑战。系统的文献回顾表明,深度学习尚未彻底革新单细胞组学领域最为紧迫的难题。然而,在数据预处理与下游分析中,深度学习模型已展现出可观的潜力,且在诸多情形下超越了以往的主流方法。尽管深度学习在单细胞组学中的发展相对缓慢,近来的研究进展显示,其有望成为推动单细胞研究快速发展的重要工具。
1 引言
自从单细胞测序(sc-seq)在2013年被评为“年度方法”以来,单细胞水平的测序技术已成为研究细胞间异质性的常用手段。RNA和DNA的单细胞检测,以及近年来的表观遗传学与蛋白质水平分析,使得研究能够以极高的分辨率对细胞进行分层。单细胞RNA测序(scRNA-seq)能够在单细胞水平上测量整个转录组的基因表达,这种高分辨率使研究者能够根据特征区分不同细胞类型、组织细胞群并识别处于状态转变过程中的细胞。这类分析为理解组织结构及生物体发育过程中的动态变化提供了更全面的视角,也使得先前通过整体RNA测序被视为均一的细胞群体内部异质性得以揭示。同样,单细胞DNA测序(scDNA-seq)可用于揭示体细胞克隆结构,例如在癌症研究中,这有助于追踪细胞谱系发展并深入理解体细胞突变所驱动的进化机制。
单细胞测序带来了巨大的潜力,使研究者能够在单细胞层面重新评估预定义样本群体之间的差异假设,不论这些样本是疾病亚型、治疗组还是形态上不同的细胞类型。因此,近年来,针对生命基本单元的遗传物质进行筛查的研究热情持续高涨。人类细胞图谱(Human Cell Atlas)便是其中的代表性项目,旨在全面测序组成人体的各类细胞及其状态。得益于单细胞DNA与RNA研究的巨大潜力,相关实验技术得到了迅速发展,尤其是微流控技术与组合索引策略的出现,使得单次实验即可测序数十万细胞,甚至已有研究实现了对上百万细胞的同时分析。全球范围内越来越多的大规模单细胞测序数据集被公开(包含数万至数百万细胞),推动了单细胞分析平台的数据爆发式增长。
随着单细胞测序数据规模与数量的持续扩张,科学界面临新的关键问题:如何正确解读并分析日益复杂的单细胞测序数据集?如何整合不同类型的数据以更深入理解特定条件下的生物学动态?以及如何将所得信息转化为医学应用,从快速精准的诊断到个体化治疗与靶向预防?在慢性疾病增加、人口老龄化与资源有限的背景下,向智能化的数据分析与理解转变显得尤为必要。在这一转型中,机器学习(ML)作为核心工具迅速崛起。机器学习致力于建立能够从数据中学习规律的模型,而无需明确的编程指令。伴随过去十年生物医学的飞速进展,机器学习算法的开发与应用也取得了显著突破,其中以深度学习(DL)的发展最为突出。早期的深度学习算法旨在计算机上模拟人脑的学习机制,因此被称为“人工神经网络”(ANN)。深度学习模型通常由多层神经元节点构成,通过多层结构能够学习多层次的数据表示。计算硬件的进步使得深度学习模型的训练变得可行,并促成了其在多个领域的革命性应用。
该综述旨在探讨深度学习在单细胞测序分析中的应用,阐述其在提升单细胞数据处理与分析中的关键作用。文章首先介绍深度学习的基本概念,以便更好地理解其在单细胞领域的应用。鉴于单细胞测序数据的高技术噪声与复杂性,文中还回顾了适用于此类数据的分析技术,以确保结果的稳健性与可重复性。最后,讨论了未来可能的发展方向,指出单细胞组学这一快速演进领域中所面临的新挑战与机遇。
2 深度学习基础
深度学习的发展历史悠久,其起点可追溯至1943年McCulloch与Pitts提出的MCP人工神经元模型。随后,Rosenblatt在此基础上提出了感知机的概念,为神经网络的发展奠定了理论基础。1974年,Werbos提出了反向传播算法,使得多层神经网络的训练成为可能。然而,直到2006年Hinton引入了一种新算法,成功解决了反向传播中梯度消失的问题,深度学习技术才真正展现出强大的潜能。
深度学习是机器学习的一个分支,其核心在于利用深度神经网络(DNN)对大规模复杂数据进行分析。深度神经网络由多层人工神经元构成,这些神经元的设计灵感来源于人脑神经元的工作方式。每个神经元接收输入信号的加权和,并通过非线性激活函数进行变换,常用的激活函数包括sigmoid、修正线性单元(ReLU)与双曲正切函数(tanh)。最基础的深度学习结构是深度前馈神经网络(DFNN),其通过堆叠多个神经元层构成。输入信息从输入层经由若干隐藏层传递,最终在输出层生成结果。神经元的大量可训练权重及非线性变换,使深度神经网络能够捕捉数据中潜在的复杂模式。训练过程的核心在于通过优化算法确定这些权重,以提升模型性能。深度学习模型的训练依赖反向传播机制,通过计算预测误差反向更新参数,实现模型的逐步优化。
根据学习方式的不同,深度学习可分为三类:监督学习、无监督学习与半监督学习。监督学习最常见于深度前馈神经网络中,其目标是将输入数据映射为可用于分类或回归等任务的表示。半监督学习则在仅有部分数据带标签的情况下进行训练,通过有限的标注信息指导未标注数据的表示与分类。无监督学习用于在无标签监督的情况下识别数据中的潜在结构或模式,常被应用于单细胞测序数据的降维与细胞聚类分析。
接下来的部分将概述几种在单细胞研究中常用的深度学习模型及其应用。
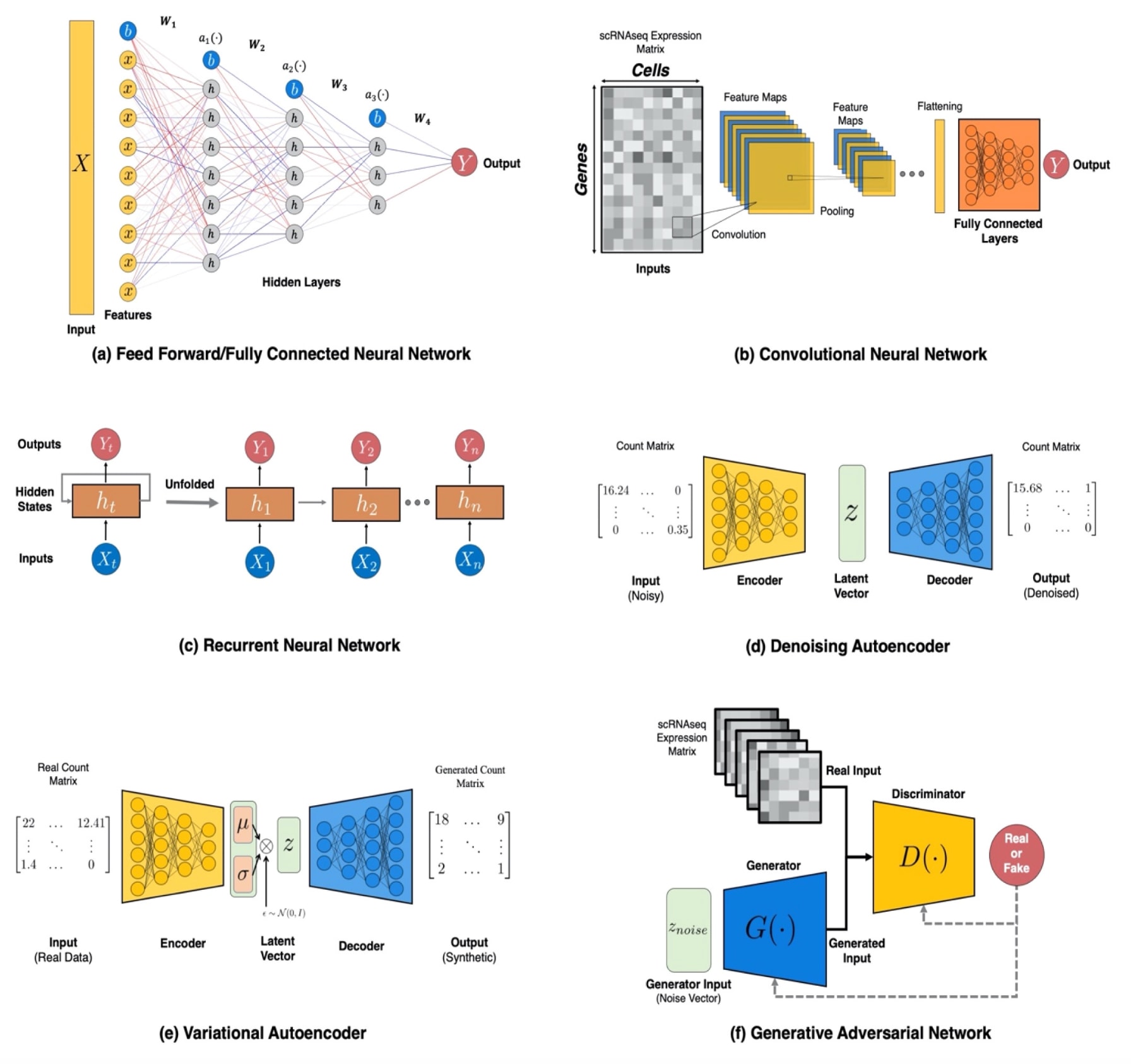
图1 (a) 前馈神经网络(FFNN)的结构示例。原始输入以X表示,权重张量记为Wi,激活层为αi,蓝色节点b表示偏置项。图中蓝色边代表正权重,红色边代表负权重,数值越小边的透明度越高,反之越深。(b) 卷积神经网络(CNN)用于分类的结构示例。在此假设性结构中,模型将输入依次经过三个卷积阶段(未绘出非线性激活部分)以提取特征,CNN输出随后输入至全连接神经网络以完成分类任务。(c) 循环神经网络(RNN)的结构与训练流程示意图。展开后的结构显示了依赖时间步长的输入、隐藏状态与输出的对应关系。(d) 去噪自编码器(Denoising AE)的示意图。自编码器由编码器与解码器组成,编码器用于提取关键信息并将其映射至潜在空间(通常维度远小于输入空间),解码器则接收编码器生成的潜在向量z,并将其还原至原始输入维度,实现数据重构。(e) 变分自编码器(VAE)的结构示意图,其目标是利用基因表达值生成合成的scRNA-seq数据。(f) 生成对抗网络(GAN)的示意图,用于生成模拟的scRNA-seq数据。在此示例中,scRNA-seq计数矩阵被转换为图像形式,并作为真实样本用于模型训练。
2.1 循环神经网络(RNN)
循环神经网络(RNN)是一类专用于处理序列数据的模型,常用于自然语言处理与时间序列分析。RNN按时间顺序逐步接收输入,并隐式保留先前输入序列的历史信息。其典型结构与前馈神经网络(FFNN)类似,不同之处在于每个隐藏状态的输出会反馈影响下一时刻的输入。若将不同时间步的隐藏单元输出视为多层网络中的不同神经元输出,RNN的工作机制便更为直观。然而,深层RNN在训练中容易出现梯度消失或爆炸的问题,同时由于层间依赖严格的时间顺序,模型难以并行化,训练成本较高。这些缺陷促使研究者开发了新的序列到序列模型以缓解RNN训练困难。其中,长短期记忆网络(LSTM)在一定程度上解决了梯度问题,而Transformer结构的出现则实现了更深层次、可并行的稳定序列建模。尽管这些模型在单细胞组学中的应用仍较有限,已有研究显示其潜力,例如利用LSTM预测细胞类型与运动性,或使用Transformer从稀疏的scRNA-seq数据中生成有意义的嵌入表示。
2.2 卷积神经网络(CNN)
卷积神经网络(CNN)是一种特殊类型的神经网络,其在至少一层中使用卷积操作代替FFNN中的张量乘法。这一操作使CNN特别适合处理具有网格状拓扑结构的数据,如图像。与其他人工神经网络相比,CNN具有稀疏连接、权重共享与等变表示三大优势。CNN在计算机视觉与时间序列分析中表现突出,但在单细胞测序分析中应用较少,因为sc-seq数据并不具备网格结构。然而,有研究通过将单细胞测序数据转化为图像形式,再利用CNN进行分析,取得了较为理想的结果。
2.3 自编码器(AE)
自编码器是一种通过非平凡映射重构输入数据的神经网络,其通常具有“沙漏”式结构,由编码器与解码器两部分组成。编码器负责将输入数据映射到低维潜在空间,实现特征提取与数据压缩;解码器则将潜在向量还原至原始空间,以重建输入数据。在理想情况下,解码器输出应接近训练样本的原貌。去噪自编码器(Denoising AE)是其中一种典型形式,通过学习在噪声干扰下的稳健重建能力。自编码器在单细胞RNA测序分析中应用广泛,包括批次效应消除、缺失值填补及多组学整合等,其在特征学习与降维分析中展现出显著优势。
2.4 变分自编码器(VAE)
变分自编码器是一类生成模型,能够同时学习潜变量模型与推断模型。与传统AE不同,VAE通过变分推断实现数据的重建,使模型不仅能复现原始数据,还能生成与原始分布相似的新样本。VAE在数学性质与训练稳定性方面优于生成对抗网络(GAN),但也存在两个主要问题。首先,经典VAE生成的样本往往较“模糊”,难以达到GAN那样清晰的生成效果。为此,Huang等人提出了内省变分自编码器(IntroVAE),通过在编码器与解码器间引入对抗机制,有效改善了生成质量,并在图像生成与超分辨率任务中超越了传统GAN。其次是“后验坍塌”问题,即变分后验分布与先验分布过于接近,导致生成质量下降。针对这一问题的研究主要集中于削弱生成模型能力、修改损失目标或调整训练策略等方向。如果能有效克服上述问题,VAE在训练效率与生成质量上均能与GAN媲美。由于VAE的潜空间结构良好,常被用于单细胞组学中的聚类与降维分析,同时也可用于缺失数据填补与合成样本生成,从而提升下游分析性能。
2.5 生成对抗网络(GAN)
生成对抗网络是一类能够生成逼真合成数据的深度生成模型,广泛应用于计算机视觉、自然语言处理、时间序列生成与生物信息学等领域。GAN由生成器(G)与判别器(D)两部分构成,两者通过零和博弈相互竞争。生成器的目标是产生与真实数据分布相似的伪样本以“欺骗”判别器,而判别器则学习区分真实样本与生成样本。通过多轮对抗训练,生成器逐步提升生成质量,判别器则持续强化辨别能力。GAN的强大生成能力来源于这种对抗机制,其可灵活学习任意分布,无需对先验分布作假设,也不受潜空间维度限制。然而,GAN训练极具挑战性,因生成器与判别器难以达到纳什平衡;同时,若判别器学习过快,梯度消失会导致生成器无法有效更新。此外,“模式崩溃”问题亦常出现,即生成器仅输出有限的样本模式。由于GAN学习分布的质量难以量化,评估通常需依赖对生成结果的直接观察。尽管诸如Wasserstein-GAN(WGAN)与Unrolled-GAN等变体在一定程度上缓解了这些问题,GAN的收敛性仍是难题。凭借生成逼真样本的能力,GAN正逐渐应用于单细胞组学分析领域,已在数据填补、数据增强及疾病进展预测(如阿尔茨海默症的分子演化预测)等方面展现出良好前景。
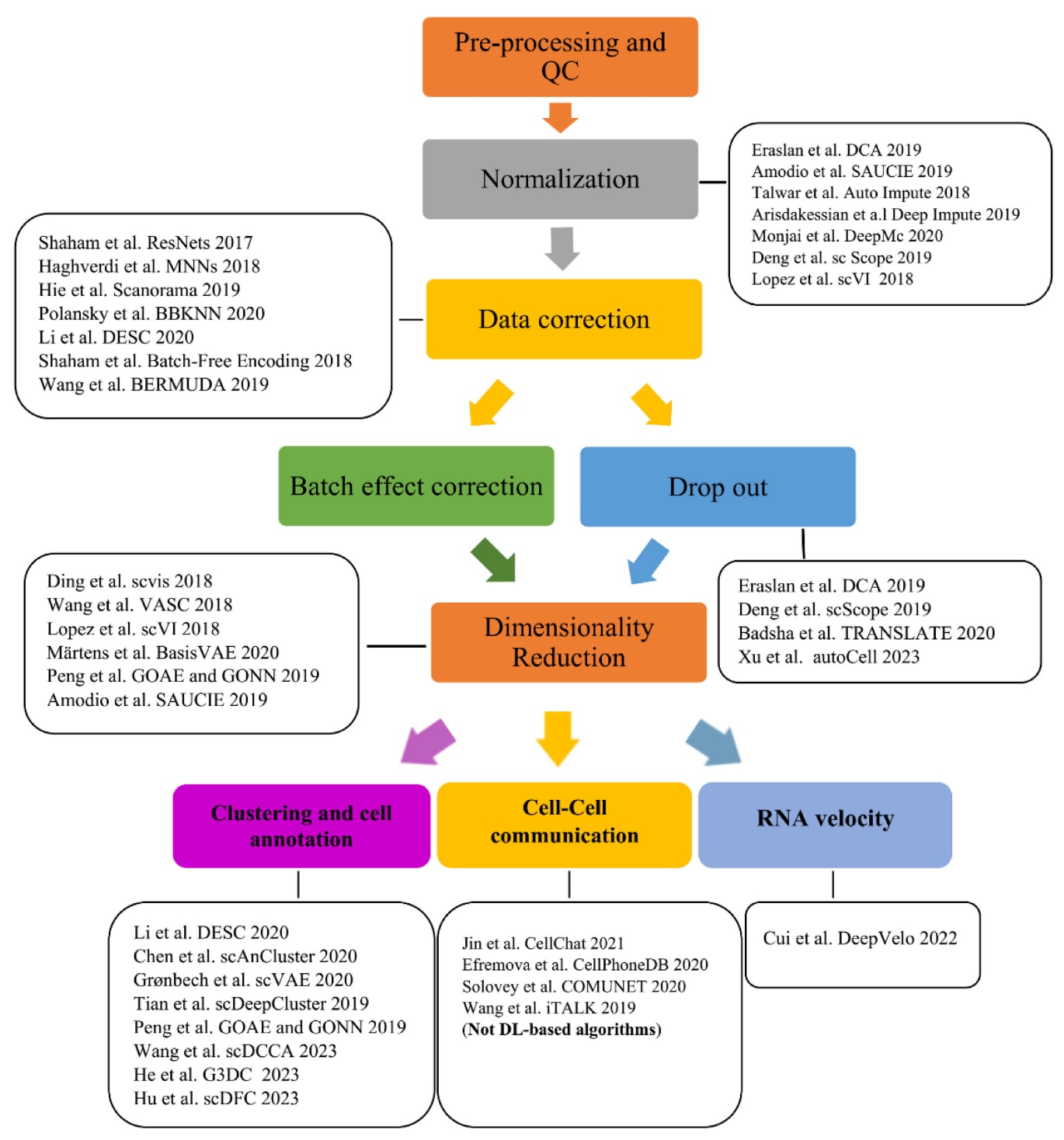
图2 | RNA测序数据分析的工作流程。
3 单细胞组学的基本概念
细胞状态主要由其基因组、表观基因组、转录组、蛋白质组与代谢组之间的相互作用所定义和表征。从这些层面获得的数据通常被统称为“组学”数据。然而,直到近年,由于单细胞分离及检测每个细胞中微量分子所面临的技术难题,在单细胞分辨率下获取多层组学数据仍不可行。随着实验技术与工程手段的快速发展,多种组学层面的信息如今已能在单细胞水平上被检测与测序。单细胞组学技术的出现,使研究者得以探索细胞间及群体内部的异质性,而这些差异在以往的整体测序中常被掩盖并误认为均一。
3.1 转录组学
转录组学研究的是转录组,即在特定条件下或特定细胞中由基因组产生的全部RNA转录本。通过高通量测序(如单细胞测序sc-seq)可以实现对转录组的系统分析。比较不同细胞类型或不同刺激条件下的转录组,可识别出差异表达基因。单细胞转录组学为理解细胞分化动态、细胞对刺激的响应以及转录活动的随机性提供了独特视角。近年来的技术进步使得单细胞转录组学能够用于构建健康人体组织、器官及系统的单细胞分辨率参考图谱,这对于多个生物学研究领域都具有重要意义。
3.2 基因组学
基因组学是一门研究基因组的结构、功能、进化、定位与编辑的学科。单细胞基因组学则利用组学技术在单细胞层面研究细胞的独特性,从而揭示复杂生物事件与系统的新机制。在单细胞水平上分析多种类型的突变,有助于揭示贯穿人类生命周期的遗传异质性,并提供对遗传多样性更深入的理解。
3.3 表观基因组学
表观基因组学研究的是DNA甲基化、组蛋白修饰、染色质可及性及染色体构象等物理性修饰,这些修饰使得具有相同基因型的细胞能够表现出不同的基因表达谱。单细胞水平表征表观基因组的实验技术取得了显著进展,使研究者得以更深入理解表观遗传过程及其与基因调控之间复杂的相互作用。近期的技术创新更进一步实现了对表观遗传维持与重编程动态过程的单细胞层面评估与识别,为揭示细胞命运调控机制提供了新的可能。
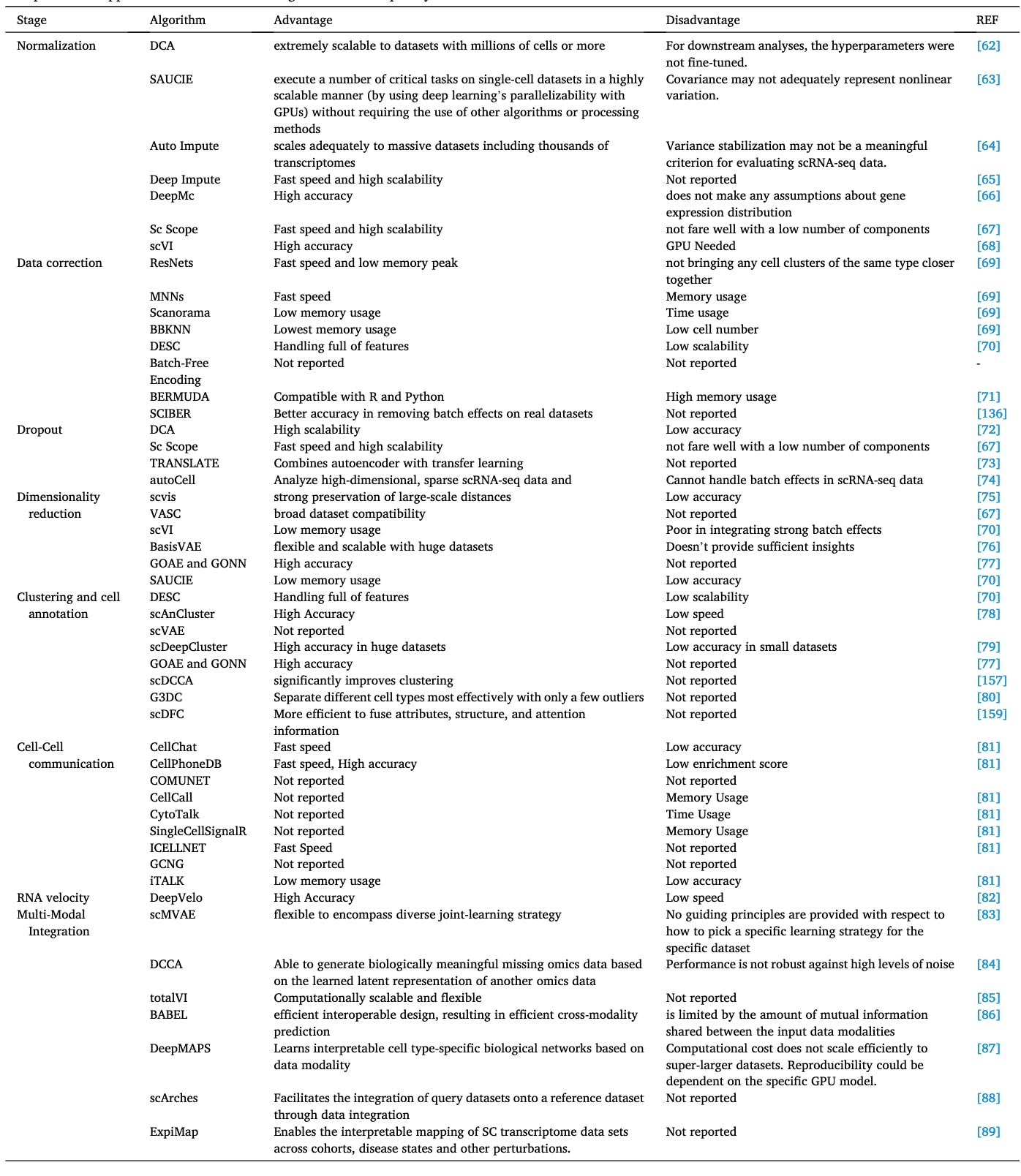
表1 | 单细胞RNA测序(scRNA-seq)分析各阶段的计算方法。
4 深度学习在单细胞组学中的应用
4.1 单细胞转录组学中的深度学习
近年来,单细胞RNA测序(scRNA-seq)极大地推动了对生物过程的理解。通过对人类、小鼠、斑马鱼、青蛙及涡虫等多种生物的细胞异质性研究,单细胞转录组学揭示了许多此前未知的细胞亚群,同时凸显出对更强大的计算分析方法的需求,以便处理日益庞大且复杂的scRNA-seq数据。目前,大量scRNA-seq数据已公开可用,主要托管于Gene Expression Omnibus(GEO)、Human Cell Atlas以及10x Genomics等数据库。下文将概述单细胞RNA测序分析各阶段的主要计算方法(见图2与表1)。
4.1.1 预处理与质量控制
在scRNA-seq实验中,细胞条形码(barcode)用于区分样本中的不同细胞群。然而,条形码有时可能错误地标记多个细胞(称为“双细胞”)或未标记任何细胞(称为空液滴或空孔),因此质量控制(QC)是分析流程中的关键步骤。常用的原始数据预处理工具如Cell Ranger、indrops、SEQC和zUMIs等均可执行QC操作。测序生成的计数矩阵维度取决于条形码与转录本的数量。尽管测序读数与计数数据中的噪声水平因实验而异,大多数分析流程仍使用相似的预处理策略。scRNA-seq数据虽然信息量丰富、可揭示更深层次的生物学规律,但其噪声与复杂性远高于整体RNA测序,给后续分析带来挑战。偏差与技术伪影等非期望变异需通过严格的质量控制与归一化加以校正。常用的QC指标包括每个条形码的总计数(测序深度)、检测到的基因数目及线粒体基因计数比例。此外,样品在解离过程中受损等实验因素亦可能导致低质量文库,影响后续分析结果。因此,如何在文库构建阶段高效识别并过滤低质量细胞仍是当前研究的难题。
深度学习算法因具备多任务处理与可扩展性,被视为构建端到端单细胞分析流程的关键工具。与传统依次执行不同任务的分步框架不同,深度学习模型可同时执行质量控制、数据校正与下游分析,并使各任务相互促进。此类模型有望超越传统分析流程。尽管目前端到端的深度学习模型仍处于早期阶段,一些初步研究(如scVI框架)已显示出显著潜力,证明深度学习在单细胞数据分析管线的构建中具有广阔前景。鉴于当前有关预处理与质量控制的研究相对有限,以下重点讨论深度学习在归一化、数据校正及下游分析中的应用。
4.1.2 归一化
归一化是scRNA-seq预处理阶段的重要环节,旨在校正由低输入量或系统性测量偏差引起的差异。其目标在于消除不同样本或基因间因技术伪影或非目标生物学效应(如批次效应)导致的测量差异。传统的整体RNA测序与微阵列数据归一化方法常被直接用于scRNA-seq数据,但这些方法往往忽略了单细胞数据的特有属性。针对scRNA-seq数据,研究者提出了多类归一化策略,如基于比例缩放的技术、基于回归的偏差校正方法,以及利用外部RNA标准(ERCC)序列的归一化方案。然而,这些方法往往依赖具体实验设计,难以普适应用。尽管已有部分基于深度学习的归一化模型尝试自动化解决技术噪声问题,但如何在归一化阶段全面建模scRNA-seq特有的技术变异仍是该领域的重要研究方向。
4.1.3 数据校正
归一化虽能减少数据噪声与偏差,但处理后的数据仍可能存在额外的变异来源,如批次效应、基因丢失(dropout)及细胞周期差异等。数据校正阶段旨在处理这些技术与生物学变量。通常建议将两类协变量分别建模,因为其来源与影响机制不同。由于这些问题的复杂性,目前尚无广泛应用的深度学习模型可同时解决数据校正的主要挑战。
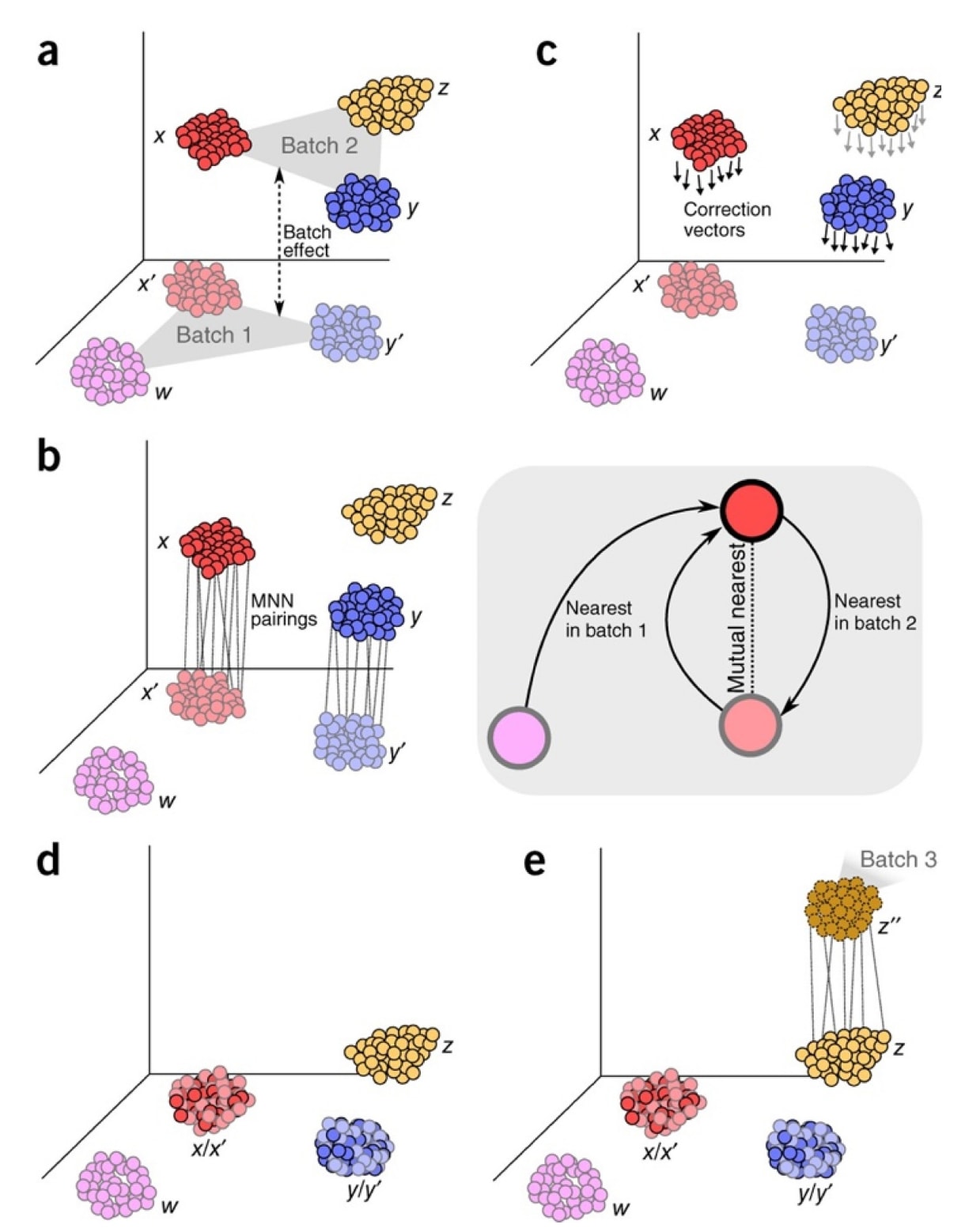
图3 | 通过互为最近邻(MNN)进行批次效应校正示意图。 (a) 在高维空间中,批次1与批次2存在几乎正交的批次效应差异。(b) 通过识别细胞间的MNN配对,算法能够找到匹配的细胞类型(灰色框所示)。(c) 在每一对MNN细胞之间计算批次校正向量。(d) 将批次1作为参考,通过减去校正向量将批次2的数据对齐并整合至参考批次。(e) 整合后的数据作为新的参考,用于与后续批次重复该校正与整合过程。
4.1.3.1 基因丢失(Dropout)
与整体RNA测序相比,scRNA-seq数据具有更强的稀疏性与噪声特征,其中最显著的问题之一是“dropout”现象——即某基因在部分细胞中高表达,而在其他细胞中未被检测到。该现象可能源于文库构建阶段单细胞mRNA含量极低,或源自基因表达的随机性。一般而言,较短的基因具有更低的读数与更高的dropout率。RNA捕获效率低会导致无法检测到已表达的基因,从而产生“假零值”;某些接近零的表达值也可能属于此类。dropout事件会显著增加技术噪声,干扰聚类及拟时分析等下游任务。因此,区分“真零值”(即基因确实未在该细胞类型中表达)与“假零值”(技术缺失)至关重要。前者反映细胞类型特异性表达,应予保留;后者则需通过填补(imputation)进行修正。
针对bulk RNA测序开发的传统插补方法并不适用于单细胞数据,因为单细胞数据具有更高的细胞间异质性和更严重的缺失问题。当前的插补方法大致分为两类:一类对所有基因表达进行整体修正,如MAGIC与SAVER;另一类仅针对零值或近零值进行填补,如scImpute、DrImpute与LSImpute。然而,这些方法往往难以捕捉数据的非线性结构。随着大规模scRNA-seq数据集的普及,插补方法亟需具备处理数百万细胞的能力。许多早期算法在大规模数据下效率低下,因此研究者逐渐转向深度学习模型以应对精度与计算效率的双重挑战。
大多数用于填补单细胞RNA测序(scRNA-seq)中“基因丢失”(dropout)事件的深度学习算法以自编码器(AE)为基础。2018年,Talwar等人提出了AutoImpute模型,利用过完备自编码器对整个基因表达矩阵进行重建,从而推断缺失值。AutoImpute通过学习输入scRNA-seq数据的潜在分布,对缺失值进行填补,同时仅对生物学上无活性的表达值做最小修改。该模型通过将基因表达模式映射到高维潜空间,学习单细胞中的表达分布与结构,最终重构出完整的表达矩阵模型。研究者指出,AutoImpute在当时是唯一能够在不耗尽内存的情况下,对其测试的最大数据集(约6.8万个外周血单核细胞,68K PBMC)进行插补的模型。
Eraslan等人随后提出了Deep Count Autoencoder(DCA),其在建模计数分布时采用负二项分布(可选是否包含零膨胀),以处理数据的过度离散性并捕捉基因间的非线性依赖。由于DCA的计算复杂度随细胞数线性增长,该模型可扩展至百万级细胞数据集。DCA利用基因间相似性进行降噪,在真实与模拟数据上均提升了传统scRNA-seq分析的准确性。其优点之一在于用户仅需指定噪声模型。相较其他方法,DCA在插补质量与速度上均表现出色,可计算每个零表达值的“dropout概率”,仅在概率较高时进行填补,从而有效区分“真零值”与“假零值”。但在处理非零表达值时,DCA可能产生偏差。
Badsha等人提出了基于迁移学习的TRANSLATE模型,其前身为LATE(Learning with AutoEncoder),同样基于自编码器结构。两者均假设scRNA-seq数据中的零值为缺失值。实验结果显示,该方法能有效恢复非线性基因间关系,降低均方误差,并改善细胞类型区分。LATE与TRANSLATE具有良好的可扩展性,利用GPU可在数小时内完成百万级细胞训练。与DCA相比,TRANSLATE在推断技术性零值上表现更优,而DCA在识别生物学零值方面更具优势。
SAUCIE(Sparse Autoencoder for Unsupervised Clustering, Imputation, and Embedding)是一种带正则化的自编码器,通过重构信号实现去噪与插补。该方法能在高噪声输入下恢复基因间重要关系,从而改善表达谱与下游差异基因分析。ScScope是一种循环自编码器网络,通过循环层迭代执行插补操作,当循环步数设为1时即退化为传统AE结构。其运行效率与其他AE模型相近。
除自编码器外,亦有部分非AE模型用于scRNA-seq数据的插补与去噪。DeepImpute通过多个子神经网络对基因群进行插补,每个子网络利用与目标基因强相关的信号基因进行预测。研究表明,DeepImpute在性能上优于DCA,这得益于其分而治之的架构。Mongia等人提出的Deep Matrix Completion(deepMC)则基于深度矩阵分解原理,利用反向前馈神经网络处理缺失值,在多数实验中均超越现有方法,且无需对基因表达分布作先验假设,具有高性能与简洁性。
Lopez等人开发的Single-cell Variational Inference(scVI)是一种基于深度神经网络的层次贝叶斯模型,假设基因计数服从负二项或零膨胀负二项分布。scVI能够准确恢复基因表达信号并填补零值项,从而提升下游分析的可靠性而不引入伪信号。Patruno等人随后比较了19种去噪与插补方法,从表达谱恢复、细胞相似性、差异基因识别与计算时间等维度进行评估。结果显示,ENHANCE、MAGIC、SAVER及SAVER-X在效率、精度与稳健性方面表现最佳。2023年,Xu等人提出了autoCell,一种基于深度学习的scRNA-seq缺失插补与特征提取方法。该模型结合变分自编码器、图嵌入及概率高斯混合模型,以处理高维稀疏的单细胞数据,提供可视化、聚类、插补及疾病特异性基因网络识别等完整功能。
总体而言,尽管传统插补方法在部分场景中仍有效,但其难以适应大规模单细胞数据的分析需求。随着百万级scRNA-seq数据集的普及,基于深度学习的模型将在处理dropout效应及区分技术零值与生物学零值方面展现更大优势,因此未来仍需进一步优化此类算法以实现更高精度的缺失填补与信号恢复。
4.1.3.2 批次效应校正
当样本分批处理时,因技术差异引入的系统性变异被称为“批次效应”。不同测序仪器、实验平台、实验环境、样本来源乃至操作人员都可能导致批次差异。批次效应的校正通常是推荐步骤,但其效果在不同研究中差异较大。自微阵列时代起,批次校正便是活跃研究方向。Johnson等人早期提出了基于参数与非参数经验贝叶斯框架的批次调整方法。随着测序数据复杂度的提升,出现了更多复杂的校正策略。然而,大多数现有方法最初为整体RNA或微阵列数据设计,需要明确的生物学分组信息,因此并不完全适用于单细胞数据分析。批次效应若未能妥善处理,会严重影响生物信号的准确性并导致错误结论。
针对单细胞特性的统计模型包括线性回归方法ComBat及非线性模型如Seurat的典型相关分析(CCA)与scBatch,它们在尽量保留生物异质性的同时减少技术偏差。此外,limma、MAST与DESeq2等差异分析框架也将批次效应作为协变量纳入建模。Haghverdi等人提出的MNN方法通过识别数据集中“互为最近邻”(mutual nearest neighbors)细胞来建立映射关系,并计算平移向量以对齐数据集,从而在共享空间中重构并消除批次差异。该方法能生成可直接用于下游分析的标准化表达矩阵,适应不同批次间组成差异。
随后,Scanorama与BBKNN两种算法基于降维空间中的MNN关系实现批次整合。Scanorama通过识别并合并不同研究中共享的细胞类型,有效去除批次效应并保持对稀有细胞状态的识别能力,可扩展至百万级细胞。BBKNN则基于图结构连接跨批次的相似细胞,计算效率极高,默认近邻模式下速度可快于其他方法1–2个数量级。
近年来,深度学习在批次效应校正中的应用取得显著进展。残差神经网络(ResNet)与自编码器是两种常用结构。Shaham等人提出基于分布匹配ResNet的非线性批次校正方法,通过最小化不同批次间多维分布的最大均值差(MMD)实现对齐,能够在不改变样本生物特征的情况下消除批次效应。Li等人提出的DESC算法是一种无监督深度学习模型,可同时进行“软聚类”和批次校正。DESC通过深度神经网络将原始数据映射至低维特征空间并迭代优化聚类目标函数,从而同时考虑生物与技术变异。研究显示,DESC在保持细胞类型差异的同时,比基于MNN的方法能更准确地去除技术批次效应。
Shaham还提出基于对抗变分自编码器(VAE)的无批次编码方法,通过对抗训练实现仅依赖生物特征的编码表示,有效减少生物信息损失。Wang等人则开发了BERMUDA框架,利用深度自编码器无监督校正不同批次的scRNA-seq数据,通过批次间信息传递增强生物信号。BERMUDA特别适用于细胞群差异显著的样本,注重跨簇相似性而非群体组成差异。
2023年,Gan等人提出了SCIBER算法,通过差异表达基因匹配批次间的细胞簇,并以参考数据为基准实现快速批次校正。SCIBER在准确性与效率上均优于复杂的先进方法,且适合将用户自有数据与标准数据库(如Human Cell Atlas)整合。总体来看,基于深度学习的批次效应校正方法正迅速发展,为生物数据整合提供了更高效、鲁棒的新思路。
4.1.3.3 降维分析
降维是单细胞RNA测序(scRNA-seq)数据可视化中的关键步骤,因为典型数据集中往往包含数千个基因特征(维度)。常见的降维方法包括主成分分析(PCA)、t分布随机邻域嵌入(t-SNE)、扩散映射(Diffusion Map)、高斯过程潜变量模型(GPLVM)、多核学习的单细胞解释模型(SIMLR)以及统一流形近似与投影(UMAP)。在线性投影的低维空间中,诸如PCA的方法难以捕捉单细胞数据的复杂结构;而非线性降维方法如t-SNE与UMAP在多种应用中表现优异,已被广泛用于单细胞数据处理。然而,这些方法也存在缺陷,包括对随机采样敏感、无法同时捕捉全局与局部结构、参数敏感性强以及计算代价高等问题。
近年来,多种基于深度学习的scRNA-seq降维方法被提出,其中以变分自编码器(VAE)与自编码器(AE)模型最为常见。Ding等人提出了基于VAE的scvis模型,用于从高维空间学习到低维嵌入的参数化映射,从而估计潜在变量的后验分布。与t-SNE等方法相比,scvis能够更好地保留数据的全局结构、具备更高的可解释性并对噪声具有更强的鲁棒性。然而,其计算耗时较长,且在分离细胞群体方面效果略逊。Wang等人提出了VASC模型,一种用于无监督降维与可视化的深度VAE架构,包含一个零膨胀层以模拟基因丢失事件。与PCA、t-SNE及ZIFA等方法相比,VASC能捕捉数据中的非线性模式,在样本量较大时表现出更高的精度与兼容性。
Märtens等人提出的BasisVAE是一种通用的VAE框架,可同时实现降维与特征聚类。该模型通过在VAE解码器中引入层次贝叶斯聚类先验,从而在过度设定聚类数K时仍能获得稀疏解。Peng等人进一步提出结合基因本体论(GO)与深度神经网络的AE模型,通过“基因本体自编码器”(GOAE,非监督)与“基因本体神经网络”(GONN,监督)实现低维表示。结果显示,结合GO先验知识能提升聚类的可解释性与精度,优于现有降维方法。Armaki通过系统评估发现,AE模型在降维方面表现最佳,而VAE在某些方面甚至不如线性PCA。这可能与VAE潜空间的先验假设(如高斯分布)不适用于单细胞数据有关,若改用更合适的先验(如负二项分布)可能改善效果。总体而言,开发高效的深度学习降维算法是未来的关键方向,因为其有潜力进一步提高低维表示的质量。
4.1.3.4 模拟生成与数据增强
由于单细胞数据的获取成本高且样本量有限,利用计算机生成(in-silico)数据进行模拟与增强成为一种高效、可靠且经济的解决方案。数据增强在文本与图像分类等机器学习任务中已是标准实践。随着深度学习的发展,传统的几何变换或噪声注入方法逐渐被基于生成模型(如VAE与GAN)的深度生成技术取代。在计算基因组学中,这两类模型在组学数据生成中均展现出良好性能。
Marouf等人提出了scGAN与cscGAN两种基于GAN的单细胞数据生成模型,统称为scGAN。该模型基于Wasserstein-GAN结构,能够学习scRNA-seq数据的潜在流形并生成逼真的合成样本。scGAN生成的细胞类型与真实数据几乎难以区分,且通过向数据集中加入合成样本,可显著提升稀有细胞群的分类准确率。Heydari等人提出了基于VAE的ACTIVA模型,以改进GAN的训练稳定性与速度。ACTIVA是一种条件对抗变分自编码器,利用细胞类型信息进行条件化生成,从而在单一框架下快速生成指定类型的细胞样本。实验表明,ACTIVA在生成质量上可与scGAN相当,而训练速度快约17倍。
这两类生成模型不仅能为算法基准测试提供数据支持,还能辅助分类器评估与标志基因检测,进而在样本量受限的研究中减少对动物与患者样本的依赖,促进早期生物医学探索。
4.1.4 下游分析
预处理完成后,下游分析用于提取生物学意义并揭示潜在的分子机制。例如,具有相似基因表达的细胞可形成簇群;相似细胞间细微的表达差异可反映连续分化轨迹;而基因间的共表达模式则提示潜在的共调控关系。
4.1.4.1 聚类与细胞注释
聚类是scRNA-seq研究中的核心步骤之一,用于识别细胞亚群并将其归类为生物学上相关的群体。随着单细胞聚类算法的进步,多项细胞图谱项目得以开展,如小鼠细胞图谱、果蝇脑衰老图谱与人类细胞图谱等。传统聚类方法虽能区分主要细胞类型,但深度学习模型在复杂聚类任务中表现更为优越,尤其在高维图像与文本领域,因此研究者也将其引入单细胞分析。
Li等人提出的DESC模型基于AE结构,通过自训练目标分布进行聚类,同时具备去噪与批次效应消除功能。DESC在多个数据集上均取得较高准确率,且在无需预定义批次的情况下保持稳健表现。Chen等人提出scAnCluster框架,将无监督聚类算法scDMFK与scziDesk扩展为端到端的监督聚类与注释系统。该模型利用多项分布建模并结合模糊K均值算法,实现了软聚类与神经网络参数优化,能够在不同数据集间进行细胞类型识别与注释,并有效检测新的细胞类型。
Tian等人提出scDeepCluster,将DCA与DESC结合,采用非线性降维与聚类联合优化。该方法在多项聚类评价指标上超越主流算法,计算复杂度随样本线性增长,且内存占用更低。Peng等人利用DNN与基因本体结合的策略优化细胞聚类,实现了全转录组水平的特征降维与高精度聚类。
此外,基于VAE的scVAE模型能直接使用原始计数数据作为输入,无需复杂的预处理步骤;而scDCCA结合去噪自编码器与对比学习模块,实现了特征学习与聚类一体化的端到端分析。He等人提出的G3DC方法引入基因网络图损失与重构损失,提升了聚类的可辨识性与生物学解释性。Hu等人提出的scDFC算法利用特征聚类与注意力机制模块,实现了多特征类型的高效融合与聚类。
尽管深度学习方法在聚类性能上总体优于传统算法,但仍存在细胞簇数未知、类型未固定与可扩展性不足等问题。此外,技术伪影(如双细胞滴度)可能导致聚类结果混淆。未来研究需在模型稳定性、噪声建模及聚类生物意义验证方面继续探索。
4.1.4.2 细胞间通讯分析
单细胞测序已成为分析组织中细胞通讯的强大工具。细胞间通过配体–受体相互作用调控发育、分化及炎症等过程。多种算法基于配体–受体数据库推断细胞类型间的信号通路。DeepCCI是首个基于深度学习的细胞通讯分析方法,利用图卷积网络(GCN)捕获配体–受体对的全局拓扑特征,并结合细胞配对的基因表达预测通讯关系。GCNG则将空间数据编码为图结构,通过监督学习整合空间与表达信息,能够发现新的细胞外相互作用基因对。由于目前细胞间通讯缺乏可靠的“真值”验证,评估仍依赖低通量实验,未来亟需建立标准化、低成本的验证框架。
4.1.4.3 RNA速度
RNA速度为研究细胞分化提供了新思路。其反映了基于剪接前后mRNA比例的基因表达变化率,即预测单个细胞未来的转录趋势。RNA速度向量可揭示短时间尺度上的细胞命运变化,弥补传统谱系追踪与成像方法的不足。当前算法如VeloViz与scVelo已能在低维空间可视化速度估计,但对复杂系统的理解仍有限。Cui等人提出的DeepVelo模型结合深度图卷积网络(GCN),能在无预设动力学假设下预测RNA速度,尤其适用于具有复杂谱系与异质细胞类型的系统。未来的研究将进一步发展基于深度学习的RNA速度建模,以阐明细胞命运决定与发育轨迹的机制。
4.2 深度学习在单细胞基因组学中的应用
传统测序方法仅能获得细胞群体的平均信号,掩盖了细胞异质性与稀有亚群。相比之下,单细胞测序在解析细胞多样性及其临床相关分子特征方面具有显著优势。与scRNA-seq类似,单细胞基因组学广泛应用于DNA/RNA结合蛋白特异性预测、增强子及顺式调控元件识别、甲基化状态检测、基因表达调控、剪接控制及基因型–表型关联分析。然而,单细胞基因组数据庞大且复杂,仅通过传统可视化分析难以揭示其潜在规律。
深度学习在该领域的应用迅速增长,凭借其可扩展性与自动特征提取能力,成为解析单细胞基因组与表观基因组的重要工具。应用包括细胞类型识别、DNA甲基化模式分析、染色质可及性预测、转录因子–基因调控关系建模及组蛋白修饰识别等。相关数据可从公共数据库如NCBI、Ensembl及DDBJ下载。后续章节将重点介绍深度学习在单细胞DNA测序数据分析中的具体应用(见图4)。
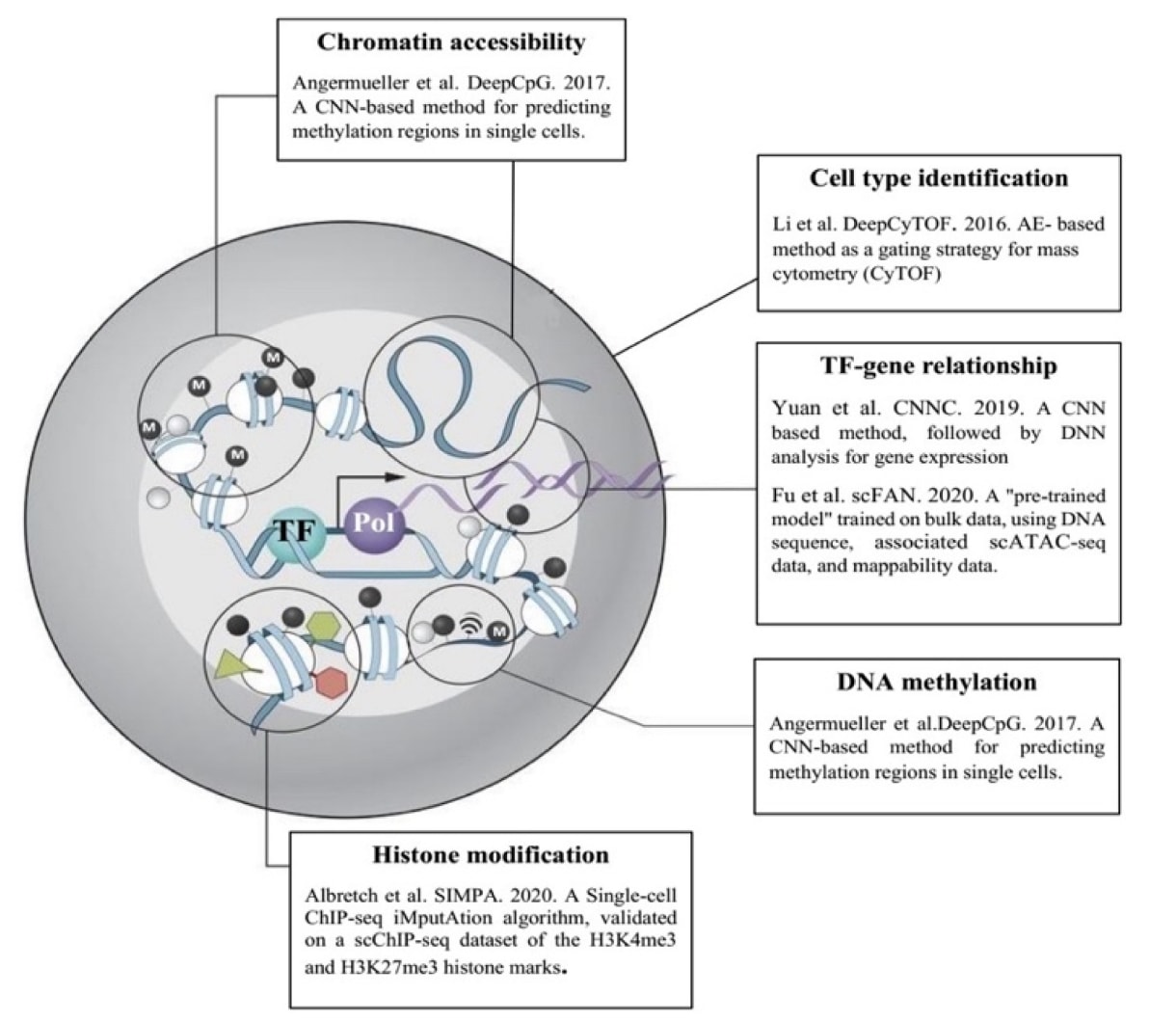
图4 | 单细胞基因组学分析中不同阶段所使用算法的概览。
4.2.1 细胞类型识别(CyTOF)
在基因组学研究中,准确识别并聚类不同类型的细胞是一项关键且具有挑战性的任务。Li等人提出了基于自编码器(AE,包括堆叠AE与多层AE)的质量控制与门控方法,用于质谱流式细胞术(CyTOF)的数据分析。CyTOF是一种新兴的高维多参数单细胞分析技术。研究者提出了DeepCyTOF模型,这是一种基于多层AE网络的标准化框架,融合了领域自适应(domain adaptation)原理,用于在监督学习的条件下实现源域(参考样本)与目标域(待校准样本)之间的分布对齐。DeepCyTOF仅需一个样本的标注数据,即可实现多个样本的自动门控。
研究者在两组免疫细胞CyTOF数据上验证了该模型:(a)感染过西尼罗河病毒(WNV)的患者样本;(b)不同年龄的健康人样本。在每个数据集中,他们手动标注一个基线参考样本,并利用DeepCyTOF自动标注剩余未校准样本。结果表明,该方法与人工门控的结果一致性超过99%。此外,他们利用堆叠自编码器(DeepCyTOF的关键模块之一)在FlowCAP-I竞赛中完成半自动门控任务,结果优于其他参赛模型。总体而言,堆叠自编码器结合领域自适应策略可实现CyTOF与流式细胞术数据的高精度半自动门控,仅需手动标注一个参考样本,即可准确识别其余细胞类型。
4.2.2 DNA甲基化
技术的进步使得DNA甲基化得以在单细胞水平上检测。Angermueller等人提出了DeepCpG模型,一种基于卷积神经网络(CNN)的甲基化区域预测算法。DeepCpG由三个模块组成:DNA模块用于提取序列特征,CpG模块用于提取单细胞CpG邻域特征,多任务联合模块则整合二者信息以预测目标CpG位点的甲基化状态。该模型可用于多种下游任务,如推断低覆盖甲基化谱、识别与甲基化状态相关的DNA序列基序以及细胞间异质性。DeepCpG在小鼠与人类数据上均显著优于传统方法。
此外,DeepCpG还被应用于研究人诱导多能干细胞(iPSC)的分化过程,与转录组测序结合以识别外显子跳跃等可变剪接现象。Linker等人进一步表明,单细胞剪接变化可根据局部序列组成与基因组特征精确预测。利用DeepCpG的联合建模策略,他们建立了基于CpG与基因组信息的细胞类型特异性模型,并在细胞分化过程中揭示了DNA甲基化与剪接变化之间的关联,为单细胞水平的可变剪接机制提供了新见解。
另一项新兴的单细胞表观遗传测序方法是scATAC-seq(Assay of Transposase Accessible Chromatin sequencing),用于检测染色质开放区域。其通过Tn5转座酶标记并切割开放染色质区域,再通过双端测序实现高分辨率分析。scATAC-seq数据的预处理流程与scRNA-seq类似,但由于信号稀疏且近似二元(有信号/无信号),在分析上面临更高噪声与复杂性。当前已有多种scATAC分析工具,但普遍存在局限,尚无公认的标准流程。
scATAC-seq不仅能揭示细胞类型及可及区域差异,还可解析顺式调控元件(如启动子与增强子)和反式因子(如转录因子)之间的调控网络。然而,大多数现有工具仅将基因活性矩阵与转录组数据整合,而忽略了全基因组可及性的重要信息。针对整体ATAC-seq已有多种深度学习模型,例如LanceOtron的CNN峰值检测模型与CoRE-ATAC功能分类模型。后者在单核ATAC-seq数据上仍能保持较高准确率(平均精度从0.80下降至0.69),显示其良好的可迁移性。
由于scATAC-seq数据的二值特征,常规的变异基因选择(如PCA)不再适用,取而代之的是潜语义索引(LSI)等方法。然而,LSI为线性方法,难以捕捉峰值间复杂依赖。为此,Xiong等人提出了SCALE模型,结合深度生成框架与高斯混合模型(GMM)先验,以学习scATAC特征的非线性潜空间。SCALE不仅能实现去噪与缺失数据插补,还能在降维任务中优于PCA与LSI,并可扩展至约8万细胞的数据集。然而,其假设所有细胞的测序深度一致,且未考虑批次效应。
为解决这些问题,研究者进一步开发了SAILER模型。SAILER受VAE启发,设计为可扩展且具抗干扰能力的表示学习框架,能够从潜空间中剔除技术性混杂因素,同时保留生物学信号。该方法可处理百万级细胞数据,并在多样本整合中有效消除批次效应,从而构建无混淆的染色质可及性图谱。总体而言,SCALE与SAILER均为单细胞ATAC-seq数据的统一分析框架,兼具降噪、聚类与插补功能。
4.2.3 转录因子–基因关系预测
理解转录因子(TF)与基因间的调控关系对于揭示基因调控机制及细胞异质性至关重要。传统上,研究者利用基因表达数据推断基因间共表达关系、功能关联与调控通路。然而,这些任务通常需分别建模。深度学习方法则能够通过联合学习同时完成多任务,从而更有效地推断基因关系。
Yuan等人提出了卷积神经网络共表达模型(CNNC),这是一种基于CNN的基因关系推断方法。其核心思想是将基因对的共表达数据转化为共现直方图(类似图像),再通过CNN分析不同表达水平下的关联模式。CNNC可用于预测转录因子靶基因、识别疾病相关基因及推断调控路径,并能扩展整合其他组学数据以提升性能。该方法在推断TF–基因与蛋白–蛋白互作方面均优于传统模型,并可用于因果推断与功能分类任务。
Fu等人提出了单细胞因子分析网络(scFAN),用于预测单细胞水平的全基因组TF结合位点。scFAN首先在整体数据上预训练模型,然后结合DNA序列、聚合的scATAC-seq数据及可映射性信息预测细胞层面的TF结合。该方法克服了scATAC-seq稀疏与噪声限制,能准确识别富含特定序列基序的结合峰,并提出“TF活性评分”用于细胞类型分类。结果显示,scFAN能在单细胞尺度上将开放染色质状态与TF结合活性联系起来,为理解细胞调控动态提供了有力工具。
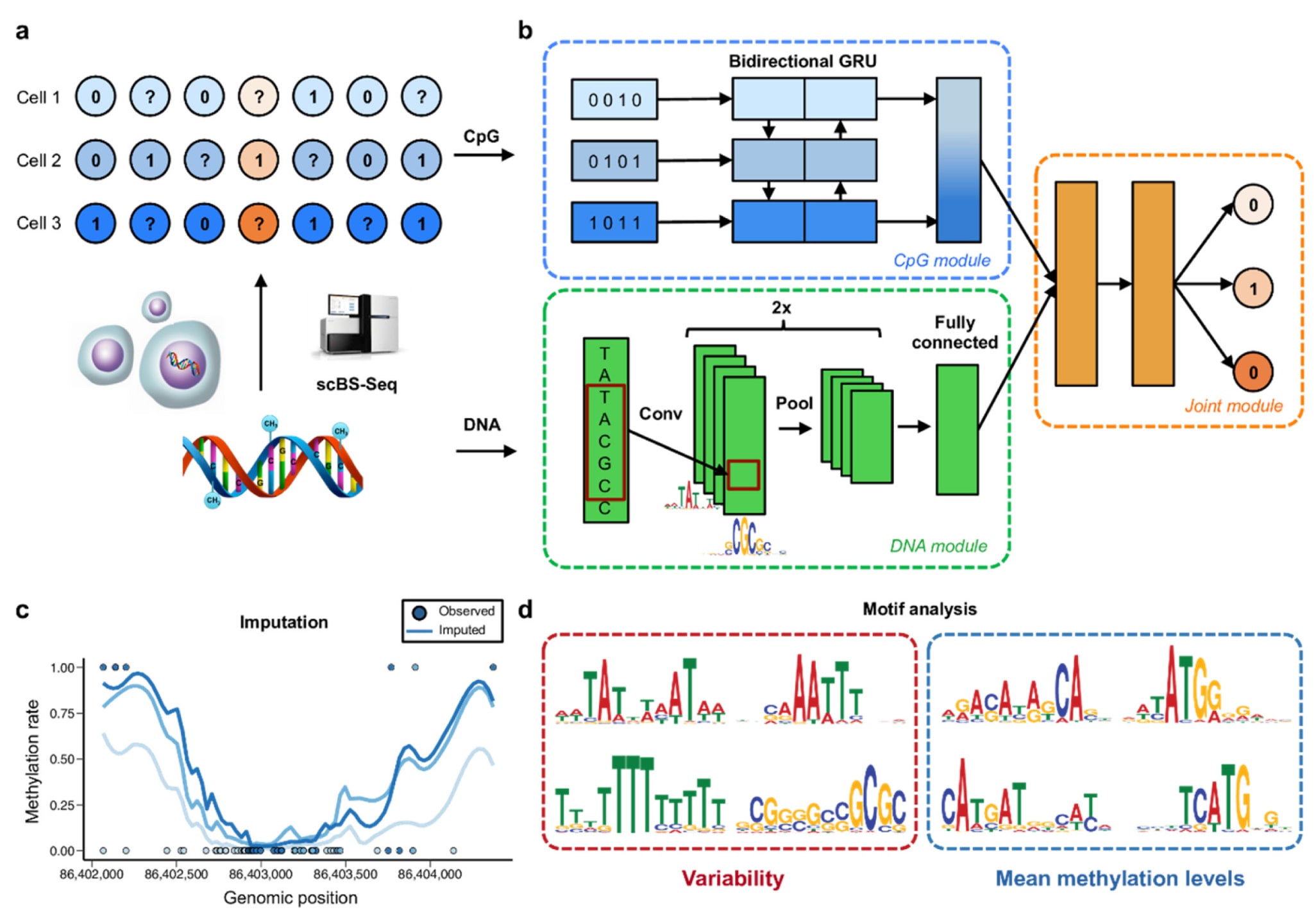
图5 | DeepCpG模型示意图(引自Angermueller等人)。 (a) 由Smallwood等人开发的scBS-seq与Farlik等人提出的scRRBS-seq可获得稀疏的单细胞CpG甲基化图谱,这些数据经过预处理后被编码为二值形式:甲基化位点标记为1,未甲基化位点标记为0,而甲基化状态未知(缺失数据)的CpG位点以问号表示。(b) 在DNA模块中,模型通过两个卷积层与池化层检测局部序列上下文中的预测性基序,并利用一个全连接层对不同基序间的相互作用进行建模。在CpG模块中,采用双向门控循环单元(GRU)扫描多个细胞的CpG邻域(图中每行代表一个细胞),并将提取的信息压缩为固定长度的向量。联合模型进一步学习DNA模块与CpG模块生成的高层特征之间的关联,以预测所有细胞的甲基化状态。(c, d) 经过训练后的DeepCpG模型可用于多种下游任务,例如全基因组范围内的CpG位点缺失值插补(c),以及识别与DNA甲基化水平或细胞间变异相关的DNA序列基序(d)。
4.2.4 拷贝数变异(CNV)与单核苷酸多态性(SNP)预测
全基因组关联分析(GWAS)是鉴定遗传生物标志物(如单核苷酸多态性SNP和拷贝数变异CNV)的标准方法,这些标志物通常与疾病或性状相关。CNV指相较于参考基因组被重复或缺失的DNA片段,长度通常超过1000个碱基对。然而,GWAS在处理CNV与SNP时面临高维度数据带来的挑战:由于需进行大量单独关联检验,必须采用严格的显著性阈值以控制错误率,从而削弱了检测灵敏度。虽然已有多项研究表明深度学习(DL)可应用于基因组数据,但针对CNV集合构建的DL研究仍较有限。
目前,已有多种用于检测单细胞DNA数据中CNV的方法,如dudeML、DeepCNV、RDAClone和rcCAE。dudeML是一种基于深度学习的CNV检测方法,能在低覆盖度样本中准确识别CNV,尤其适用于样本混合或测序深度不足的情况。传统CNV检测通常依赖启发式规则和人工筛选,但在大样本条件下,人工区分真阳性与假阳性既耗时又易产生偏差。DeepCNV通过层次结构压缩高维数据,使其自动化地完成过滤过程,从而减少主观干扰。RDAClone是一种基于自编码器的非线性深度学习模型,可应用于基因组学分析,也能扩展至细胞与基因网络建模。rcCAE方法则利用卷积自编码器从单细胞DNA测序(scDNA-seq)数据中学习细胞的潜在表示,同时提升测序读数质量,有效去除非生物学噪声,从而在低维空间中准确识别细胞亚群及其拷贝数变化。
总体而言,基于深度学习的单细胞基因组分析展现出巨大潜力,能够推动对DNA结构复杂性及表观遗传机制与疾病关系的理解。由于单细胞基因组数据固有的稀疏性、噪声及高维特征,构建更强健的DL模型对于推进该领域的发展至关重要。
4.3 深度学习在空间转录组学中的应用
自被评为“年度方法”以来,空间转录组学(Spatial Transcriptomics,ST)已成为单细胞RNA测序(scRNA-seq)的自然延伸,能在不解离组织的情况下实现全转录组范围的空间表达分析。ST为传统RNA测序添加了空间信息,有望弥合细胞状态刻画与组织结构复杂性之间的鸿沟。通过在保留细胞空间位置的同时测定基因表达,ST揭示了细胞间相互作用、器官功能及病理变化,为组织层级的生物学研究带来新的视角。
当前空间分辨的转录组技术可分为两类:(i)实现单细胞分辨率的循环RNA成像技术;(ii)基于阵列的空间RNA测序技术,如Visium、Slide-seq及高清空间转录组(HDST)。前者能精确定位细胞但多重检测能力有限,后者则利用微阵列或微珠阵列在组织切片上捕获mRNA,实现高通量测序。由于阵列捕获信号可能覆盖多个细胞,测得的信号通常为多细胞混合表达。因此,需要计算方法将单细胞转录组与空间信息整合,以在组织中重建高分辨细胞分布。
Lähnemann等人指出,识别空间基因表达模式是单细胞组学计算中的核心挑战之一,这类模式有助于揭示细胞群体的空间分布、标志基因及稀有细胞亚群。此外,ST能将基因表达与组织图像结合,使研究者利用图像处理技术分析组织形态特征,从而更精确地推断组织结构与基因功能的对应关系。
近年来,出现了一系列基于深度学习的ST分析模型。Xu等人提出DeepST框架,可识别空间结构域,在人脑前额叶皮层及乳腺癌组织数据中均优于传统方法。DeepST不仅能整合多批次及多平台数据,还可扩展至其他空间组学类型。Maseda等人开发了DEEPsc算法,可利用参考空间图谱为scRNA-seq数据推断空间位置信息,在斑马鱼、果蝇、大脑皮层及卵泡系统中表现出高精度与稳健性。Biancalani等人提出Tangram框架,可将scRNA-seq或单核RNA-seq数据与组织空间信息精确映射,生成高分辨基因表达空间图谱。
Tan等人开发了SpaCell工具,结合组织空间条码的基因表达与像素强度信息,实现高分辨图像预测与细胞类型识别。Fu等人提出SEDR模型,将空间信息与转录组数据共同嵌入,通过变分图自编码器构建低维潜在空间,提升了聚类准确度并成功重建人脑发育轨迹。O’Connor等人提出的DeLTA 2.0系统则利用深度卷积神经网络自动分析细胞图像,实现无人工干预的基因表达与生长追踪。
尽管ST的深度学习模型仍处早期阶段,但随着数据规模增长与图像技术发展,DL有望成为ST数据整合与分析的核心方法,其未来将大量借鉴计算机视觉领域的创新。
4.4 单细胞转录组与空间转录组整合(空间去卷积)
由于空间转录组信号通常来源于多个细胞的混合,且无法精确对应细胞边界,因此需结合scRNA-seq数据进行解卷积分析,以推断各空间位置中不同细胞类型的比例。SPOTlight模型采用带标记的非负矩阵分解(NMF)回归方法进行空间信号去卷积,通过细胞类型特异性基因表达特征拟合每个位置的基因计数。尽管SPOTlight在准确度和效率上表现良好,但在整合不同批次或平台数据方面仍有限制。
Stereoscope模型采用负二项分布建模基因表达计数,利用贝叶斯推断估计每种细胞类型在不同空间点的贡献。其后,Cell2location进一步扩展该框架,引入超参数以调节不同技术间的灵敏度差异,提高跨平台整合性能。Lopez等人提出的DestVI模型利用变分推断实现多分辨率空间分析,可在不同位置推断每种细胞类型的基因表达变化,并在肿瘤模型中精确重建空间组织结构。
4.5 深度学习在单细胞多组学整合中的应用
单细胞测序(sc-seq)能在单细胞层面测定DNA与RNA,被选为2013年度方法。随着技术进步,多组学测定成为可能,使研究者能在同一样本中同时获取多种分子层面的信息。多组学整合可连接不同生化维度的数据,放大关键生物信号,为药物响应预测、基因依赖性推断及疾病分型提供新思路。
深度学习在多组学整合中的优势在于其高度灵活的结构和跨模态建模能力。例如,Zuo等人提出的scMVAE模型利用三种联合学习策略同时整合scRNA-seq与scATAC-seq数据,生成非线性联合嵌入表示,显著优于传统VAE模型。Amodio等人提出的MAGAN模型通过生成对抗网络(GAN)实现不同组学流形的对齐,用于CyTOF与scRNA-seq数据整合。其他模型如UnionCom、SMILE、SCIM及GLUER则利用图匹配、互信息学习与神经网络映射实现跨模态数据融合。
近年来的代表性模型包括scArches与ExpiMap。前者利用迁移学习实现参考与查询数据集的高效整合,后者基于条件VAE,在保持生物学可解释性的同时显著提升跨物种与跨组织整合能力。
5 结论与展望
总体而言,深度学习正推动单细胞数据分析进入快速发展阶段。然而,该领域亟需系统化的基准研究,以比较不同模型在复杂数据集上的表现。目前,大多数研究仅在特定数据上展示优越性,缺乏对模型适用场景与局限性的深入分析。未来,需进一步明确不同DL结构在特定任务中的性能优势,并建立标准化的人类细胞图谱以实现全面验证。
尽管当前单细胞测序数据集规模相对较小,但随着数据共享与技术普及,深度学习模型将在更大规模的生物样本中展现潜力。迁移学习等策略将进一步促进模型知识迁移,使研究者能在有限数据条件下获得可靠结果。
此外,多组学整合与空间组学的发展将推动DL方法在揭示疾病机制、细胞互作及病理演化中的应用。未来,具有生物学可解释性与跨模态泛化能力的DL模型将成为生命科学研究的重要工具,助力精准医学与系统生物学的深入发展。