J. Agric. Food Chem. 2026|基于蛋白质工程策略的酶学性质改造研究进展
今天介绍的是发表在 J. Agric. Food Chem. 上的一篇综述论文,系统梳理了基于蛋白质工程策略对酶学性质进行理性改造的最新研究进展。文章围绕酶稳定性、催化活性与底物选择性三大核心性能,深入总结了定向进化、半理性设计与理性设计等经典方法,并重点讨论了人工智能尤其是蛋白质语言模型在酶工程中的快速崛起及其带来的方法学变革。通过结合结构建模、能量计算、高通量筛选与机器学习预测,该工作展示了现代酶工程如何逐步从经验驱动走向数据与计算驱动,为食品科学、绿色化学及生物制造领域中高性能生物催化剂的开发提供了系统而前瞻性的参考框架。

Huang, Y.; Wen, L.; Yang, B. Advances in the Modification of Enzymatic Properties Based on Protein Engineering Strategies. J. Agric. Food Chem. 2026. https://doi.org/10.1021/acs.jafc.5c13434.
0 摘要
酶是一类环境友好的生物催化剂,在催化生化反应过程中发挥着至关重要的作用。然而,天然酶的催化性能往往难以充分满足工业生产的需求。随着人工智能工具辅助的蛋白质工程改造策略迅速发展,通过理性设计手段显著提升酶的催化性质已成为可能。该综述重点介绍了不同蛋白质语言模型的功能特征及其代表性工具,并系统梳理了用于分析酶催化性能评价指标的多种软件工具,对不同工具的成功率和使用权限进行了详细比较。最后,文章强调了人工智能技术在蛋白质工程应用中面临的挑战与未来发展方向,以强化理性计算在蛋白质设计与个性化改造中的作用。该综述为相关研究人员推动蛋白质工程领域的进一步发展提供了全面的参考视角。
1 引言
酶作为生物催化剂,具有高度专一性、极高的催化效率以及在温和条件下运行的能力。这些特性使其在制造过程中相较于传统化学催化剂具备显著优势。因此,酶催化目前已被广泛应用于生物医药、环境保护和合成生物学等多个领域。早期的工业生物催化主要依赖易于获取的天然野生型酶,这些酶通常来源于食品或其他成熟工业体系,并被用于洗涤剂、半合成抗生素以及药物用简单手性前体的生产。相比之下,现代工程化生物催化剂需要被定向设计,以实现特定反应的催化、接受非经典底物,并在既定工艺条件下保持稳定性与活性。
然而,天然酶在工业应用条件下仍存在显著局限性。其功能稳定性往往受到削弱,因为许多工业过程所需的高温条件容易引发酶的变性并导致不可逆的活性丧失。此外,其固有的催化活性常常不足以满足工业尺度动力学的需求。尽管高底物专一性在某些情境下具有优势,但也会因限制对非天然或结构多样化底物的加工能力而缩小其应用范围。蛋白质工程作为一门成熟学科,在生物技术领域中占据关键地位,通过基于结构引导的突变设计,能够理性地重塑酶功能,以克服工业应用中的性能瓶颈。蛋白质的催化机制及其相关改造过程如图1所示。目前主流的蛋白质工程方法主要包括三种策略:定向进化、半理性设计和理性设计,三种策略在不同特征上的比较见表1。
人工智能技术的突破正推动蛋白质设计突破天然进化的限制,使得全新蛋白质结构与功能的创造成为可能。借助机器学习算法的迭代优化,人工智能驱动的从头设计策略摆脱了对天然模板的传统依赖,能够自主优化催化位点与整体稳定性,从而显著提升酶的性能与适用性。此外,新兴的蛋白质语言模型及相关人工智能工具可以生成具有定制功能的创新蛋白质架构,为生物分子工程提供了新的技术路径。文中对人工智能工具驱动的蛋白质工程与传统基于生物信息学的蛋白质工程方法进行了比较,相关细节汇总于表2。
工业生物技术的未来有望系统性地突破酶催化所面临的基础性限制。该综述连接了两个相互协同的重要方向:一是人工智能驱动的酶设计工具的持续革新,二是经典蛋白质工程策略的不断完善。通过对这些前沿方法的综合分析,阐明了它们的融合如何推动新一代生物催化剂的产生。文章首先系统整合并总结了蛋白质语言模型及其衍生的计算工具体系,随后有序梳理了提升关键酶学性质的既有策略,包括稳定性、催化活性和底物选择性。在每一类策略中,对相应的计算与实验工具进行了评估,分析其优势与局限,并进一步展望了人工智能在蛋白质工程领域中的潜在发展方向。最后,对高通量筛选技术进行了批判性评估,核心概念以图2的形式进行了图示总结。
总体而言,该综述对当前酶工程领域的发展前景与挑战进行了系统分析,并提出了一套可操作的人工智能驱动生物催化剂设计框架,从而在食品加工、环境修复和生物医学等实际应用场景中,搭建起计算创新与工程实践之间的桥梁。
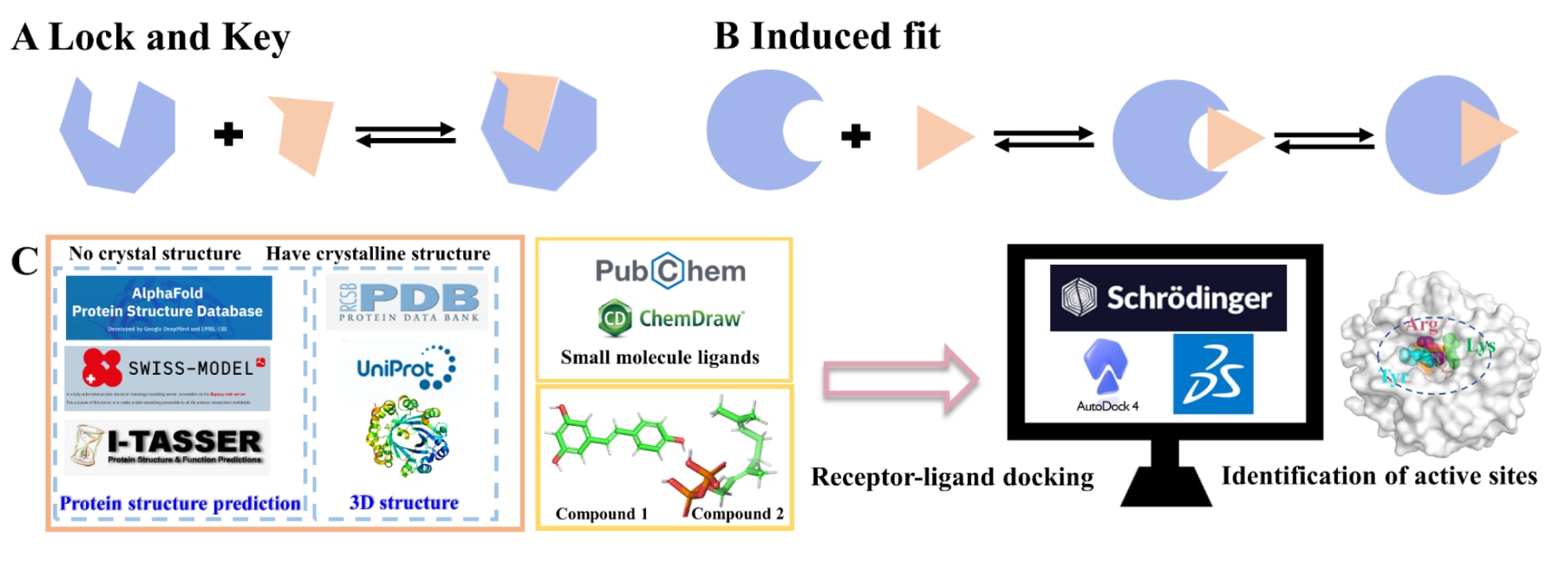
图1|酶催化理论。 (A)锁钥模型,(B)诱导契合模型,(C)酶改造的常见流程。AlphaFold、Swiss-MODEL和I-TASSER是蛋白质结构预测工具。PDB和UniProt是与蛋白质相关的数据库。Schrodinger、AutoDock和Discovery Studio是三种不同的分子对接工具。PubChem和ChemDraw分别是化合物数据库和化合物结构绘制软件。
2 蛋白质语言模型
蛋白质语言模型将人工智能的预测能力与生成能力整合到生物学研究中,使具有特定功能的蛋白质理性设计成为可能。该类模型通常基于Transformer等深度学习架构,并在大规模天然蛋白质序列数据集上以无监督方式进行训练。通过这一过程,模型能够内化氨基酸序列中蕴含的进化模式、结构约束和功能规律,从而为单个残基或完整蛋白质生成具备上下文感知能力的表征。蛋白质语言模型在蛋白质工程中的不同功能如图3所示。本节将蛋白质语言模型划分为三类,这一分类不仅有助于理解不同模型的优势及其适用场景,也为研究人员在具体应用中选择合适模型提供了依据。蛋白质语言模型的整体工作流程如图4所示。在此分类框架下,不同蛋白质语言模型的特征及其在酶工程中的应用被系统总结于表3。
2.1 序列模型
序列模型在训练和推理阶段仅以蛋白质的氨基酸序列作为输入。通过对序列的分析,模型能够识别其中固有的模式并提取进化信号,从而实现对突变如何影响蛋白质功能的准确预测。基于序列的模型大体可分为两类:依赖多序列比对的模型以及不依赖多序列比对的模型。依赖多序列比对的模型通过比较多个相关序列来获取进化信息,从而捕捉残基之间的协同进化关系。相较之下,不依赖多序列比对的模型直接处理单条序列,借助深度学习方法识别复杂的序列模体以及蛋白质内部的长程相互依赖关系。此类模型的代表包括AlphaMissense、FusionProt和S-PLM等。
尽管依赖多序列比对的蛋白质语言模型在捕获进化信息方面具有显著优势,并在基因突变效应预测中积累了丰富的理论和实践经验,但其在处理与多序列比对坐标体系不兼容的序列时性能受到限制,例如包含插入或缺失的序列。这一局限在一定程度上制约了该类模型的广泛应用。此外,蛋白质组中还存在大量无法通过多序列比对有效对齐的无序区域。研究表明,约50%的人类蛋白质至少包含一个长度不小于40个氨基酸的本征无序区段。相比之下,不依赖多序列比对的蛋白质语言模型通过直接在原始蛋白质序列上进行训练,克服了传统模型的上述限制,在突变效应预测方面表现出较强能力,其代表模型包括ESM-1v、ESM-1b等。
表1|蛋白质工程策略对比

2.2 结构模型
结构模型通过捕获蛋白质精细的三维构象信息来阐明蛋白质结构与功能之间的关系。此类模型的代表包括Rosetta、FoldX和GVP-GNN。这些模型不仅能够根据蛋白质结构反推出对应的氨基酸序列(即逆折叠),还为预测突变适应性建立了新的研究范式。然而,结构模型仍然面临一些长期存在的挑战,例如如何充分考虑蛋白质的柔性与动态特性,以及如何更有效地整合序列信息与结构信息。展望未来,引入分子动力学模拟有望进一步提升预测精度,从而协同推动蛋白质突变效应预测领域的发展。
2.3 序列结构模型
序列-结构一体化模型同时融合序列域与结构域的信息,构建了一个利用多模态数据进行更全面、更精确预测的统一框架。这类模型在保留蛋白质语言模型序列分析优势的同时,引入空间构象信息,从而在突变效应预测方面实现更高的准确性。ESM-3是序列-结构模型中的一项重要突破,该模型能够基于功能需求生成全新的蛋白质序列,并成功设计出与已知序列差异显著且具有功能性的蛋白质。常见的序列-结构模型还包括ProSST、SaProt等。
蛋白质语言模型正在蛋白质工程中发挥日益重要的作用。其中一个研究热点是对酶动力学参数进行建模,以更好地理解和预测催化活性。尽管该方向受到广泛关注,其实际应用仍面临多方面限制。首要问题在于,高质量且大规模的突变数据集相对匮乏,而这类数据对于模型的稳健训练与验证至关重要。未来的研究可通过发展融合多组学信息的迁移学习策略,以缓解大规模数据中噪声较高的问题。此外,由于许多模型预测结果主要依赖计算输出而缺乏实验支撑,研究人员在解读这些结果时需保持谨慎,并结合生物学知识与实验验证加以判断。值得期待的研究方向包括引入带有结构与功能监督的多模态训练方式,以及基于功能或结构提示推进蛋白质的定制化设计。
表1|不同蛋白质工程策略对比

3 蛋白质稳定性方法
酶自身固有的结构不稳定性是其工业应用中的基础性限制因素,因此稳定性工程成为蛋白质工程中的核心目标。半理性设计通过将理性设计的靶向精准性与定向进化的广泛探索能力相结合,构建出高度聚焦且质量较高的突变体文库。这种整合策略既能够实现针对性的结构改造,又可显著降低筛选负担。在该框架下,人工智能可从蛋白质三维结构中提取并整合关键特征,包括B因子、盐桥以及氢键网络,用于预测具有稳定化效应的突变位点。本节系统综述了蛋白质稳定性工程中的关键策略,比较了不同方法在生物催化剂优化中的优势,并对各类方法当前面临的挑战及未来发展方向进行了分析。提升蛋白质热稳定性的经典策略如图5所示。
目前,定向进化通常需要数月至数年的实验周期,筛选通量约为10^3–10^4个变体,而其理想状态是将周期缩短至数周至数月,通量提升至超过10^6个变体。计算机辅助的理性设计一般需要数天至数周时间,处理的变体数量约为10^1–10^2个,其理想周期仍为数天至数周,但通量可提高至10^2–10^3个变体。人工智能驱动的蛋白质设计目前可在数天至数周内完成,典型通量为10^2–10^4个变体,而其理想目标是实现实时或按小时级别的设计反馈,并具备几乎无限的计算机模拟设计能力。总体而言,当前酶热稳定性工程仍存在周期长、通量低的问题,严重制约了蛋白质在工业生产中的应用,未来发展高通量蛋白质热稳定性检测方法仍是该领域的重要研究方向。
图2|关键组分综述
3.1 B因子
B因子是蛋白质晶体结构分析中的关键参数,用于反映原子位置因动态或静态无序所产生的波动幅度。通常,结构柔性较高的区域,如酶活性位点、底物结合口袋以及变构调控位点,往往表现出较高的B因子值。在酶工程中,可通过引入脯氨酸残基、二硫键或盐桥等稳定化元件,对这些局部柔性区域进行约束,从而以理性方式提升整体蛋白质稳定性。基于蛋白质语言模型并以B因子作为评价指标的一系列热稳定性工程工具已被开发,例如RONN、Maranas、SCHEMA、FireProt、CAN、RosettaDesign、FoldX、FRESCO和OPUS-BFactor等。
然而,B因子仅能部分反映蛋白质的整体稳定性。蛋白质结构稳定性由其三维折叠中大量弱相互作用的协同贡献所决定。因此,仅针对单个或少数高B因子位点进行突变设计,往往只能带来有限的稳定性提升,在某些情况下甚至可能对蛋白质稳定性产生不利影响。Ban等通过盐桥工程改造支链酶以提升其热稳定性,K137E突变使酶的半衰期提高了36.6%,而K137D突变使稳定性提升了26%。在与活性位点突变相结合后,双突变体L25A/K137E和L25R/K137E的催化活性分别提高了17.12%和31.62%。该基于结构引导的改造策略在不损害酶功能的前提下,实现了热稳定性的有效增强。
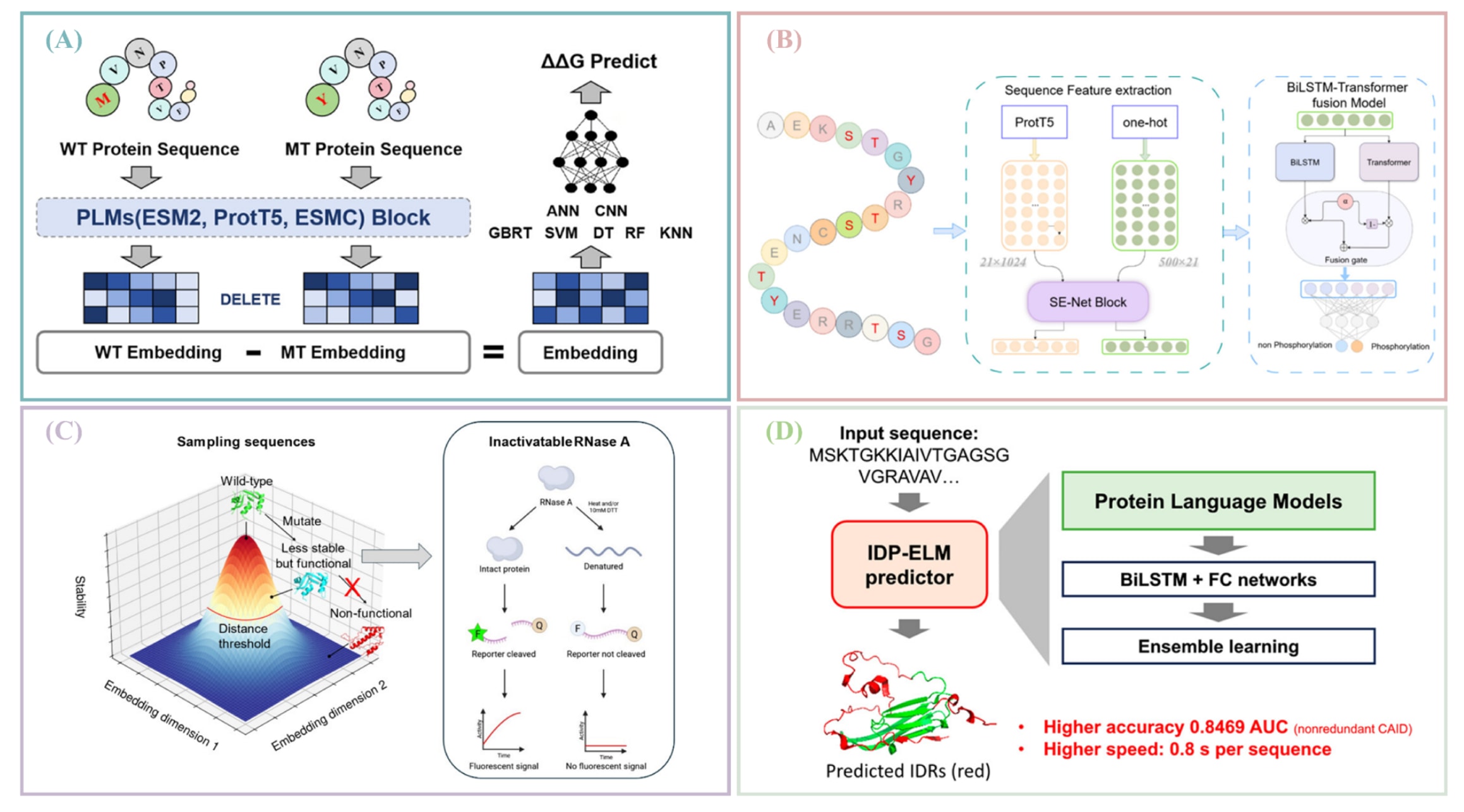
图3|蛋白质语言模型不同功能的总体概览。 (A)蛋白质-蛋白质结合亲和力变化的预测。(B)蛋白质磷酸化位点的判定。(C)不稳定型RNase A的设计。(D)本征无序蛋白的精确预测。
3.2 二硫键
二硫键是由两个半胱氨酸残基的巯基经氧化形成的共价连接。在蛋白质结构中,二硫键在稳定三维折叠构象、提高热稳定性和抗变性能力、调控功能活性以及保护关键活性位点等方面发挥着重要作用。通过将关键功能位点理性突变为半胱氨酸残基,可以在蛋白质结构中人工引入二硫键。Discovery Studio、Disulfide by Design 2.0和Rosetta等计算工具常用于指导二硫键的设计与定位。成功引入二硫键后,通常通过质谱手段确认其连接位置,并结合生物物理和功能实验评估其在热稳定性、酶活性或结合能力方面的改进效果。然而需要注意的是,新引入的二硫键可能会扰动蛋白质的天然构象。因此,在实验验证之前,通常建议采用分子动力学模拟评估此类突变对结构的潜在影响。
聚对苯二甲酸乙二醇酯(PET)因其成本低、便携性好、稳定性高、阻隔性能优异及透明度高等特点,被广泛应用于纺织工业、家用电器和食品包装领域。然而,PET在自然环境中难以降解,由此带来了长期的环境污染问题。利用酶促解聚实现废弃PET塑料的回收,被认为是一种可持续且环境友好的解决方案。在已知的相关酶中,IsPETase在常温条件下对PET表现出最高的水解活性,但其实际应用受到稳定性不足的限制。Li等通过将定点突变与机器学习方法相结合,对高效PET水解酶变体FAST-PETase-N212A进行改造,获得了7种催化活性显著提升的变体,例如ACCT140D和ACC-T140E。这些变体在较高温度下表现出更强的PET降解能力。值得注意的是,引入二硫键的变体PpFAST-ACC在70 °C条件下的活性较野生型酶提高了约10倍。
二硫键在提高蛋白质热稳定性方面具有重要意义。未来研究可结合微流控技术和荧光激活细胞分选等高通量实验平台,以更高效地筛选稳定化蛋白质变体。需要指出的是,尽管二硫键通常被认为具有稳定作用,但在某些情况下,其引入反而可能促进部分折叠或未折叠中间态的形成,从而导致结构破坏。作为替代策略,可在关键结构位置理性引入带相反电荷的残基对,以增强静电相互作用,在不引入共价约束的情况下提高热稳定性。
图4|蛋白质语言模型不同功能的整体概览。 (A)蛋白质-蛋白质结合亲和力变化的预测。(B)蛋白质磷酸化位点的识别。(C)不稳定型RNase A的设计。(D)本征无序蛋白的精确预测。
3.3 非催化区域
蛋白质中的非催化区域是指不直接参与催化反应的结构片段,但在维持整体结构完整性、调节活性、介导蛋白质-蛋白质相互作用或亚基组装等方面发挥着重要辅助作用。对这些区域进行稳定化改造,可间接维持催化位点的正确构象,从而避免活性丧失。这一策略有望在不牺牲高催化性能的前提下,延长蛋白质在工业或医学应用中的使用寿命并提高其稳健性。然而,该方法同样存在局限性,例如过度刚性化可能抑制必需的构象动态变化,从而降低功能效率,而脯氨酸替换也可能无意中破坏关键分子相互作用。未来研究可结合定向进化或计算设计策略,在特定位点精确增强结构刚性,以在稳定性与功能柔性之间实现最优平衡。
Li等通过在β-半乳糖苷酶Aga 0917的V140位点引入脯氨酸突变,显著提升了其热稳定性和催化活性。该突变促进了新的氢键和盐桥形成,稳定了关键环区结构,并使底物结合裂隙变窄。由此带来的结构刚性限制了底物波动,提高了结合自由能并缩短了催化距离,从而整体提升了酶在高温条件下的性能。该研究表明,通过改造非关键、非催化区域,可以在完全保留催化活性的同时显著增强酶的热稳定性。
表3|不同蛋白质语言模型的特点对比

3.4 折叠能
蛋白质稳定性与其折叠过程密切相关,明确的折叠途径和稳定的构象状态是维持功能完整性的基础。基于折叠能量的蛋白质工程策略通常包括识别关键折叠中间体和核心残基、提高折叠动力学效率,以及优化疏水核心堆积和氢键网络。基于折叠机制实施热稳定性工程需要结合系统的动力学分析,其中分子动力学模拟发挥着核心作用,可用于揭示构象波动、描绘自由能景观并解析折叠路径。AMBER、GROMACS和NAMD等分子动力学程序包被广泛应用于此类研究。在模拟过程中,均方根波动(RMSF)是一个关键指标,用于量化各残基α碳原子在整个模拟轨迹中相对于其平均位置的偏离程度,从而反映局部柔性与结构稳定性。
PROSS是一个基于进化分析和结构稳定性的计算设计服务器,其核心逻辑在于引入稳定化突变,并通过整合Rosetta能量函数实现综合评分,在方法论上已内嵌人工智能相关思想。通过训练深度学习模型,该平台可将蛋白质序列或突变序列作为输入,直接预测其折叠自由能或热稳定性变化。色氨酸羟化酶(TPH)能够催化L-色氨酸生成5-羟基色氨酸。Wang等以ΔΔG作为设计准则,获得了两个TPH突变体M1(S422V)和M30(V275L/I412K),其热稳定性显著提升。这两个突变体在37 °C条件下的半衰期分别为野生型的5.66倍和6.32倍,其Tm值相较于野生型分别提高了4.2 °C和6.0 °C。Tian等基于定点突变数据构建了支持向量机模型,对枯草芽孢杆菌脂肪酶A进行了工程改造。该模型分析了181个突变位点,成功识别出4个已知的稳定化残基(G80V、G111D、M134D、N161Y),并预测了其他具有高稳定性的候选变体。
尽管如此,基于分子动力学模拟的方法仍存在一些内在局限性:其一,力场精度不足会在疏水相互作用、氢键和离子相互作用建模中引入系统性偏差,从而影响预测可靠性;其二,该类方法对实验验证依赖较强,而高通量实验在大规模应用中成本较高。未来的发展方向应聚焦于构建计算与实验深度融合的闭环体系,借助自动化平台实现“模拟-实验-模型修正”的迭代循环,以加速蛋白质设计的验证与优化过程。
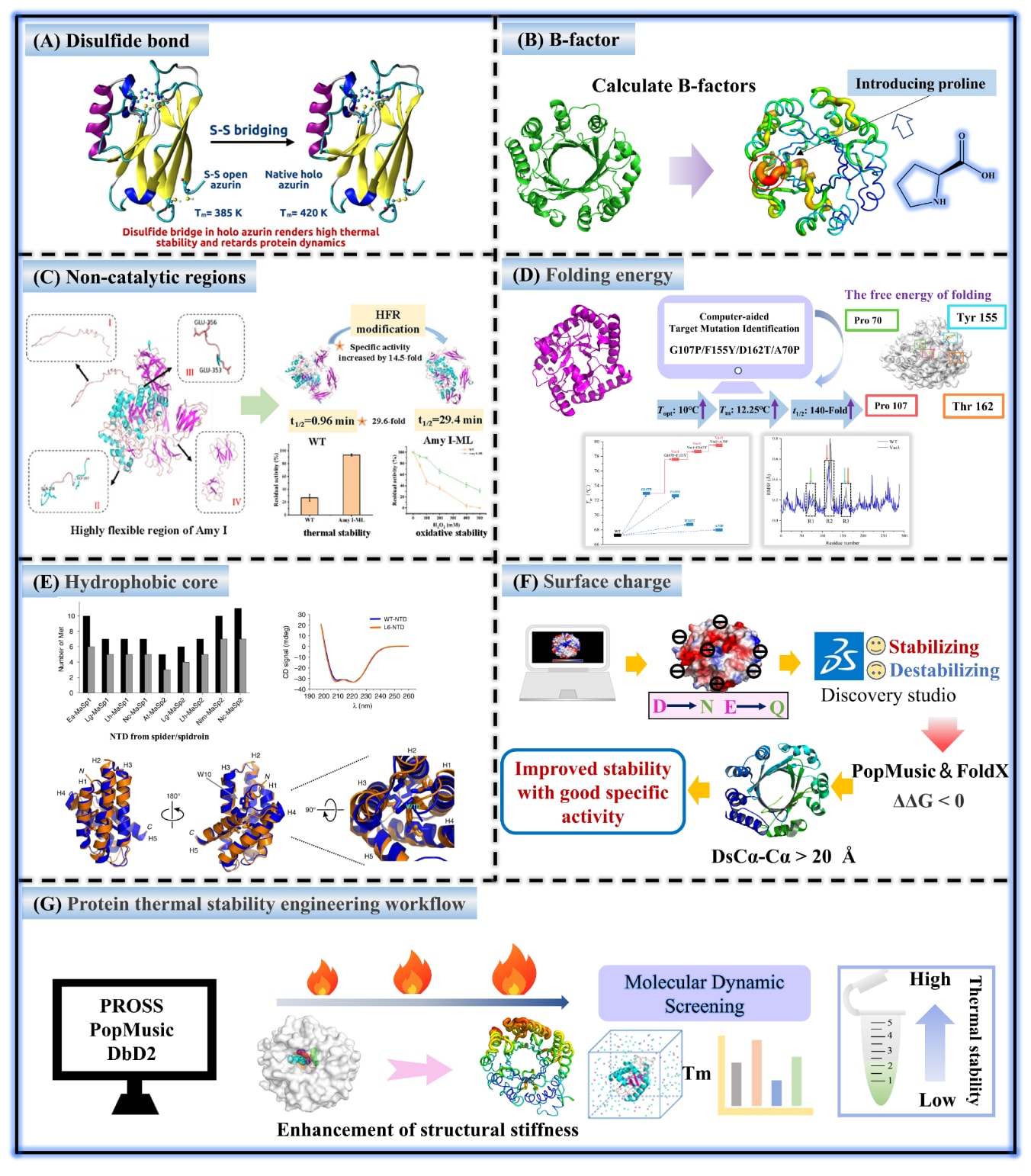
图5|酶热稳定性的工程化策略。 (A)二硫键工程。(B)基于B因子的脯氨酸扫描。(C)增强非催化区域的结构刚性。(D)折叠能量。(E)疏水核心。(F)表面电荷。(G)蛋白质稳定化的一般工程流程。
3.5 表面电荷分布
优化蛋白质表面电荷分布是稳定性工程中的核心策略之一。基于蛋白质表面电荷分布引入盐桥,是提升蛋白质稳定性的重要方法。盐桥是蛋白质中带正电的阳离子基团与带负电的阴离子基团之间形成的静电吸引作用,通过连接蛋白质的不同区域来稳定其天然构象。人工智能可通过以蛋白质结构为输入训练深度学习模型,例如三维卷积神经网络,直接生成蛋白质表面的静电势分布图。与传统数值计算方法相比,该策略在计算效率上提升了数个数量级,可实现对海量突变体的快速筛选。该方法主要聚焦于蛋白质表面的带电氨基酸残基,在不改变酶学活性的前提下提高其热稳定性,在工业制造中展现出良好的应用前景。
Vidya等通过表面电荷工程改造提高了大肠杆菌L-天冬氨酸酶II的热稳定性。将带正电的K139和K207残基替换为中性的丙氨酸后,所得变体在稳定性上均优于野生型酶及保持电荷不变的突变体,表明表面电荷优化是一种有效提升蛋白质稳定性的策略。
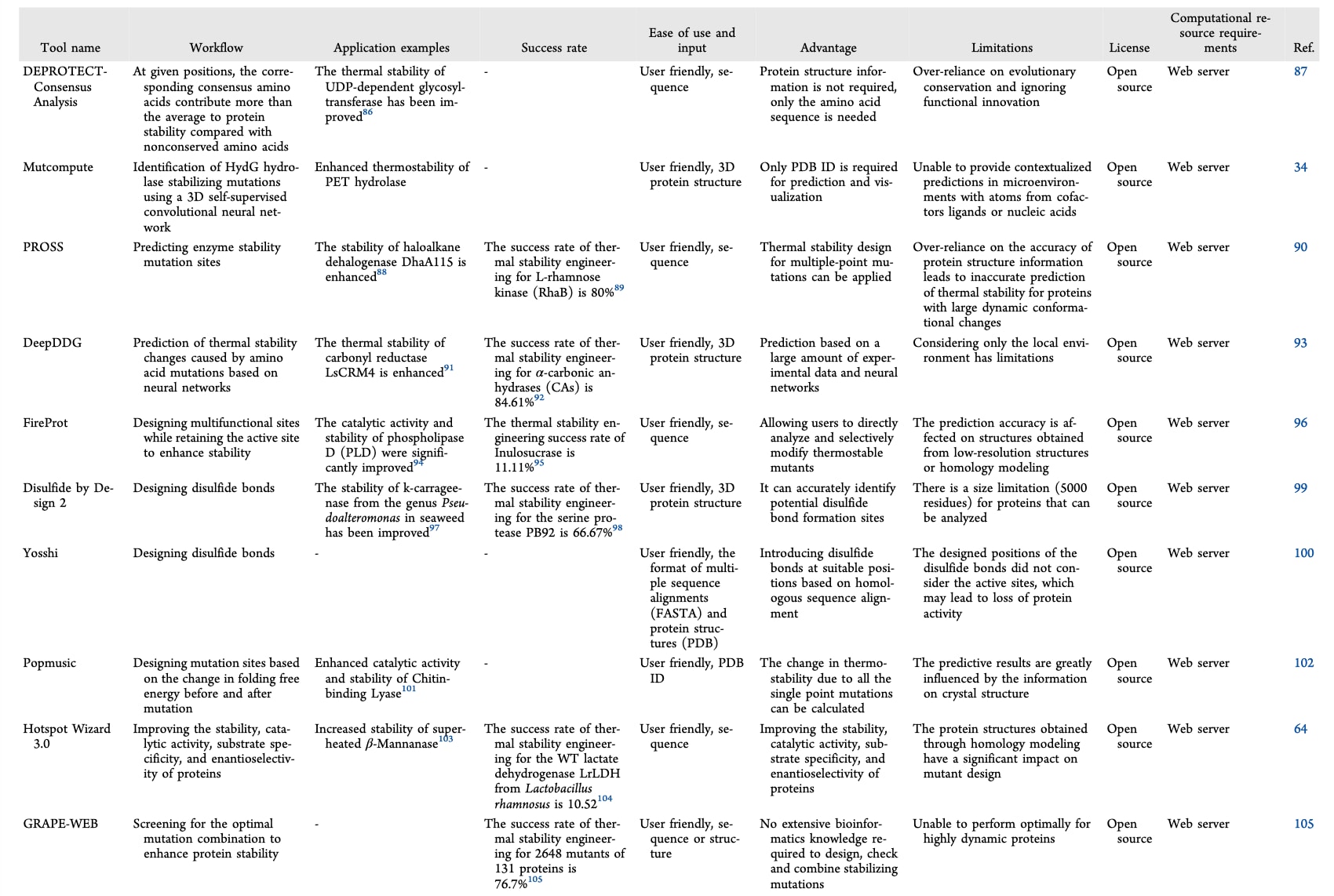
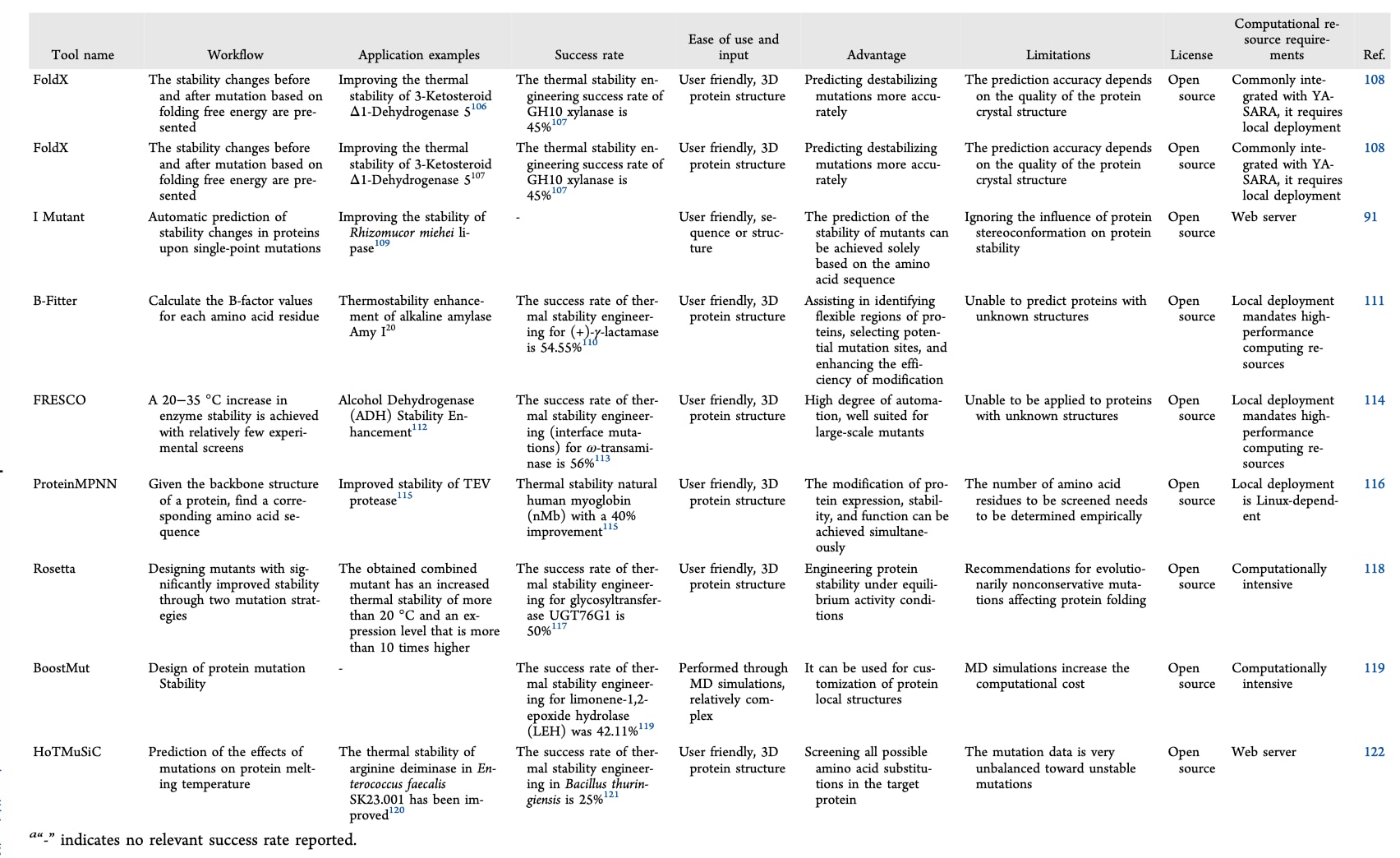
表4|基于理性设计的突变型蛋白质稳定性工程预测工具
3.6 计算工具
当前用于提升蛋白质稳定性的计算工具主要基于多序列比对和蛋白质折叠能量变化等原理。突变对稳定性的影响通常通过计算折叠自由能变化ΔΔG来评估,常用工具包括FoldX和Rosetta。这些程序基于物理化学力场构建能量函数,用于模拟氨基酸替换所引起的构象变化。多序列比对在稳定性设计中同样发挥着重要作用,通过系统发育分析识别保守残基,并采用“回归共识序列”策略选择高频残基以提高稳定性。例如,FireProt通过序列进化分析筛选出具有进化稳定性的突变,并进一步结合FoldX进行验证。
此外,通过将几何向量、残基间距离等三维结构特征与序列信息相结合,可训练机器学习模型预测单点或多点突变对稳定性的影响。将基于能量的计算与进化分析相结合,有助于筛选具有协同效应的多位点突变并降低拮抗效应,从而实现更加稳健和高效的蛋白质稳定化设计。Peccati等提出了一种结合AlphaFold结构集合与Rosetta-ddG的计算方法用于预测酶的热稳定性,该方法能够准确估计突变体的ΔΔG值,并将蛋白质工程的研发周期从数年缩短至数周。表4总结了多种常见人工智能工具在酶热稳定性工程中的应用。
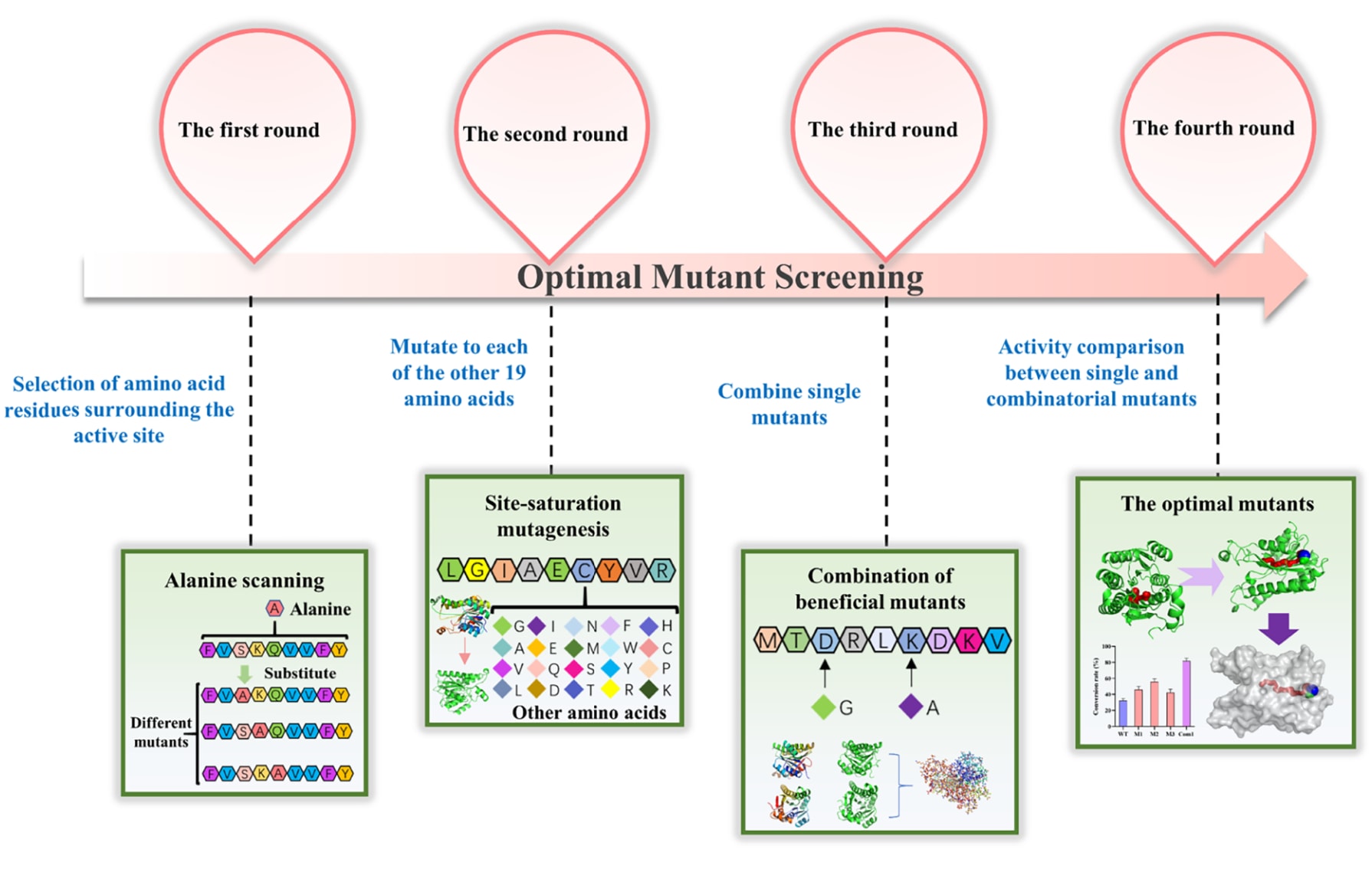
图6|酶催化活性工程的一般工作流程。
4 提升蛋白质催化活性的工程化策略
催化活性是评估酶性能的关键指标。然而,天然酶由于自身结构与功能上的限制,往往表现出较低的催化效率,导致产物转化率低、生产周期长,从而限制其工业应用。提高酶的催化活性可显著缩短反应时间、降低酶用量、提高产率,并最终实现更高效、更环保且更具成本优势的生物催化过程。围绕蛋白质结构和序列信息,研究人员已发展出多种用于改造酶催化活性的策略,并取得了显著成效。人工智能通过机器学习回归模型预测点突变对酶活性的影响,从而实现虚拟筛选。本节对多种新兴的酶活性增强策略进行了系统评述。
目前,机器学习与计算模型正被广泛应用于酶催化工程研究中,并展现出推动生物技术发展的巨大潜力。例如,利用ProteinMPNN设计TEVd变体,成功获得了催化效率显著提升的酶分子。未来研究可进一步结合人工智能和量子计算等新兴技术,在蛋白酶的理性设计中实现前所未有的效率提升与原子尺度精度。
4.1 酶活性位点
酶活性位点中的关键催化残基对酶功能至关重要。基于配体结合的晶体结构,可系统识别围绕配体分布的残基,并通过丙氨酸扫描突变评估其对活性的贡献。对于突变引起显著活性变化的位点,进一步采用NNK简并密码子进行饱和突变,其中N代表A/C/G/T,K代表G/T,可覆盖95%以上的氨基酸替换类型。针对每一个目标残基,通常需要筛选约100个突变克隆,从而获得催化活性增强的变体。
Du等通过突变位于催化位点附近的A339和Q442残基,对Baeyer-Villiger单加氧酶进行了工程改造。A339E变体对特定环戊酮底物的活性提高了2.4至3倍,而Q442N突变体的活性提升幅度达到2.7至3.8倍,该研究强调了在酶工程中需平衡活性提升与潜在稳定性损失之间的关系。Lu等基于卷积神经网络方法设计水解酶变体,获得了活性分别提高3.4倍和29倍的突变体,展示了计算引导蛋白质设计的巨大潜力。然而,活性位点突变往往会降低酶的整体稳定性,且天然结合口袋对非天然底物可能并非最优。因此,该策略的实施需要在催化增强与结构稳定性之间进行谨慎权衡。未来研究应聚焦于同时提升酶活性与稳定性的综合工程化策略。
表5|用于提升酶催化性能的先进工具
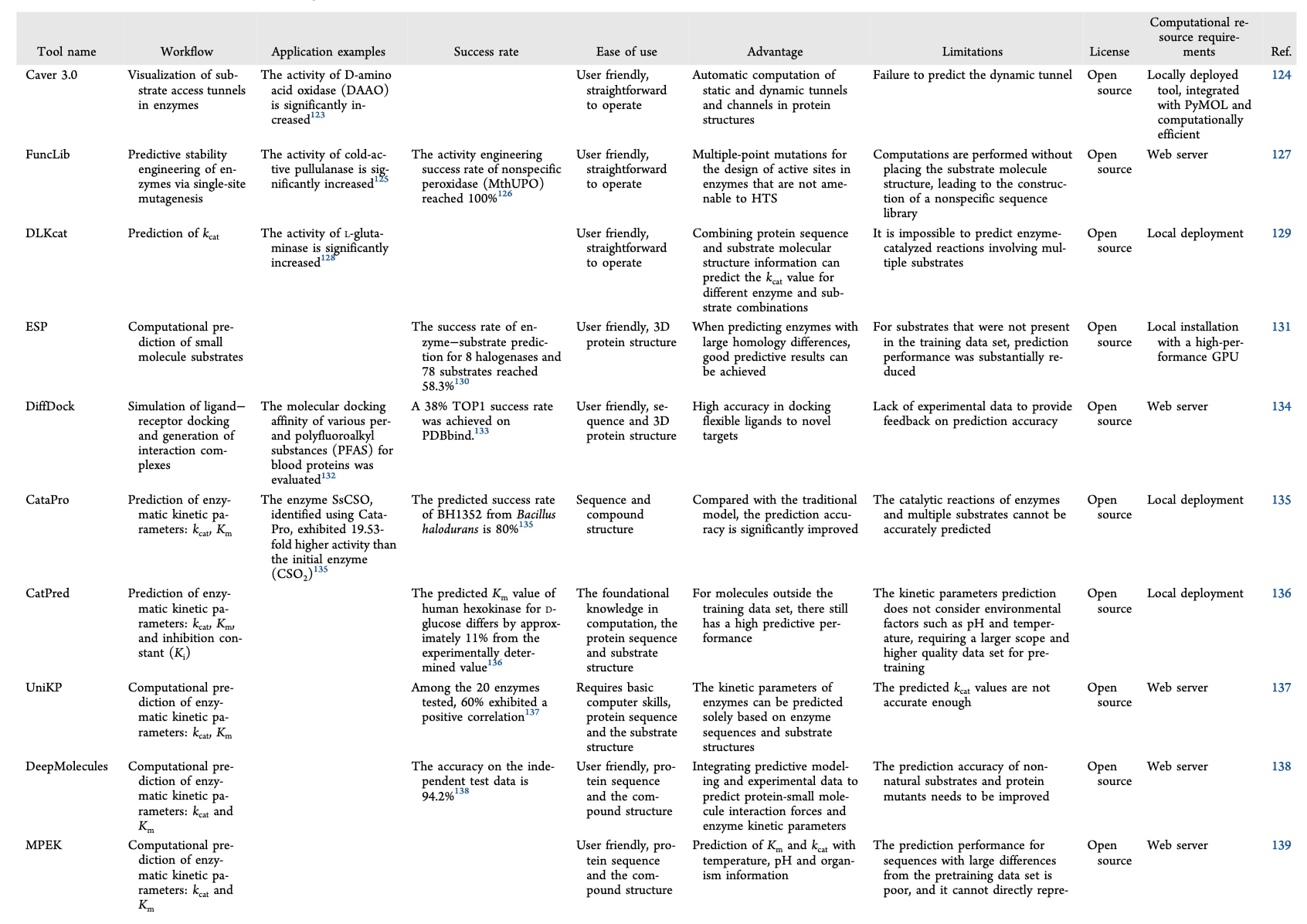
4.2 构象调控
蛋白质的动态构象主要通过X射线晶体学、冷冻电镜或时间分辨光谱等技术加以解析,从而揭示酶在不同催化阶段的构象差异。底物结合可诱导酶发生构象变化,使活性位点与底物形状精确匹配,并形成催化所需的微环境。与此同时,酶在溶液中通常处于多种构象平衡状态,底物选择性结合以及具有催化活性的构象共同推动反应向前进行。通过揭示动态构象与催化活性之间的内在联系,基于动力学与构象调控的蛋白质工程策略得以有效应用于酶催化活性的改造过程。然而,过度增加酶的刚性可能阻碍产物释放,而远端突变也可能意外影响蛋白质的折叠途径或整体稳定性。Kaczmarski等通过对多种酶中催化残基动力学特征的比较分析,表明远端突变可通过重塑构象动力学来增强酶催化活性。在某种脱水酶的进化过程中,此类突变限制了非生产性构象,使现代酶仅在具有催化能力的构象状态之间取样,凸显了动态变构调控在活性优化中的重要作用。
4.3 序列比对
在同源蛋白序列比对中,高度保守的残基往往直接参与催化反应,对其结构与动力学特性的精细调控可有效提升酶活性。序列比对能够揭示进化过程中的保守性、适应性与协同进化模式,从而为催化性能优化提供潜在靶点。将结构生物学与机器学习相结合,可实现“局部活性位点优化”与“整体动力学网络重构”的协同策略,不仅提高了蛋白质工程效率,也有助于发掘在功能上具有重要意义的远端位点。人工智能可借助强大的基因组数据库和搜索工具,收集数十万甚至数百万条同源序列,构建深度多序列比对,并从中提取关键特征,进而开展智能化设计。然而,该策略高度依赖高质量的同源序列数据,且在进化上高度保守位点进行突变时,可能会无意中降低酶的稳定性。
根癌农杆菌Agrobacterium radiobacter D3来源的酰胺酶AmdA能够催化酒精饮料中致癌物氨基甲酸乙酯的降解。Yao等通过对AmdA保守催化三联体附近位点进行定向突变,构建了I97L/G195A双突变体,其水解活性提高了3.1倍,乙醇耐受性提高了1.5倍,该提升源于底物结合氢键的增强。Galmes等比较了两种酯酶的活性位点结构,发现CalB中的Trp104形成了对底物定位至关重要的疏水口袋,其功能类似于Bs2中的苯丙氨酸残基。借助卷积神经网络模型,研究人员预测了影响结构的突变,并展示了对催化中心进行三维可视化在改良催化剂设计中的重要价值。
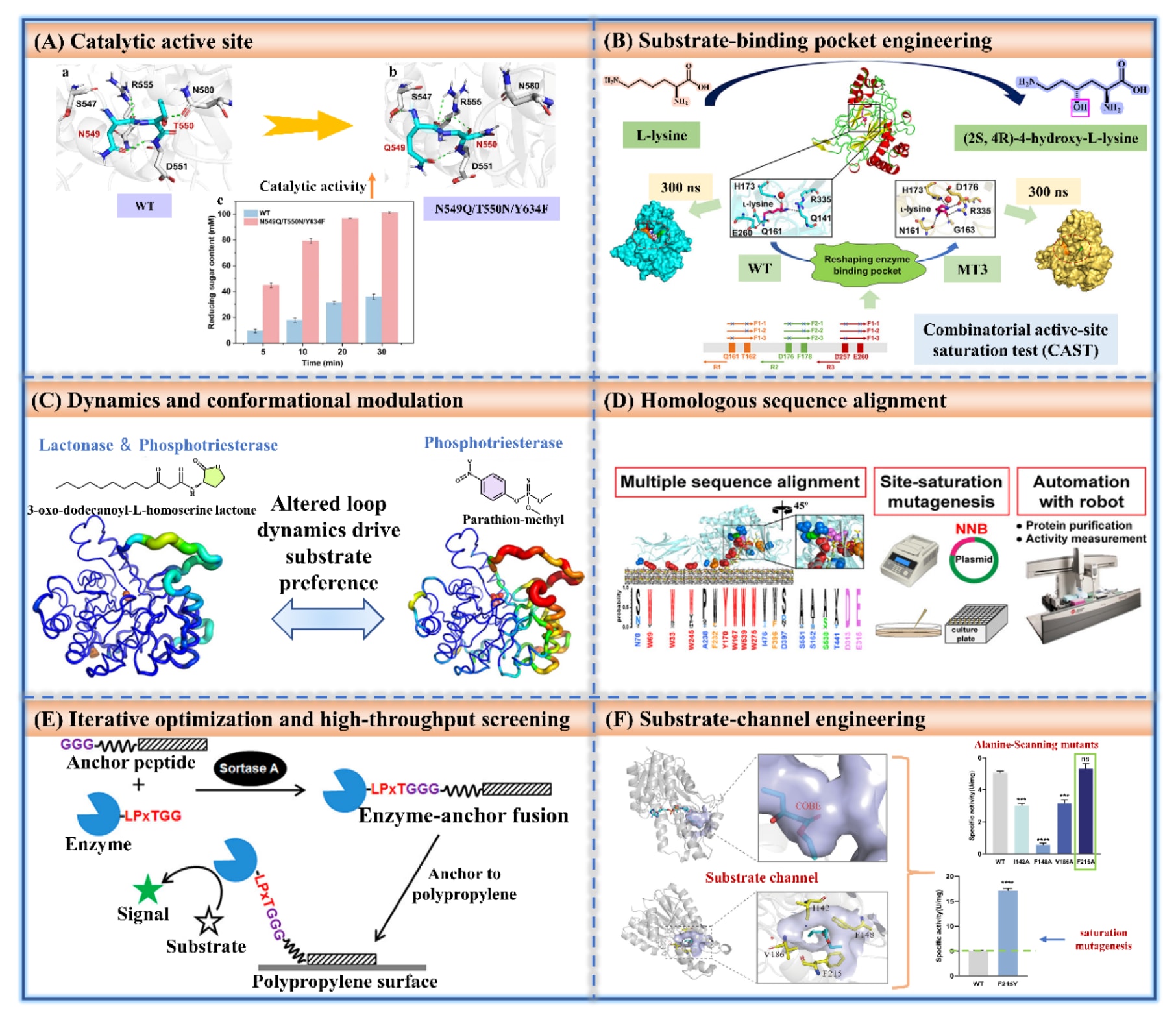
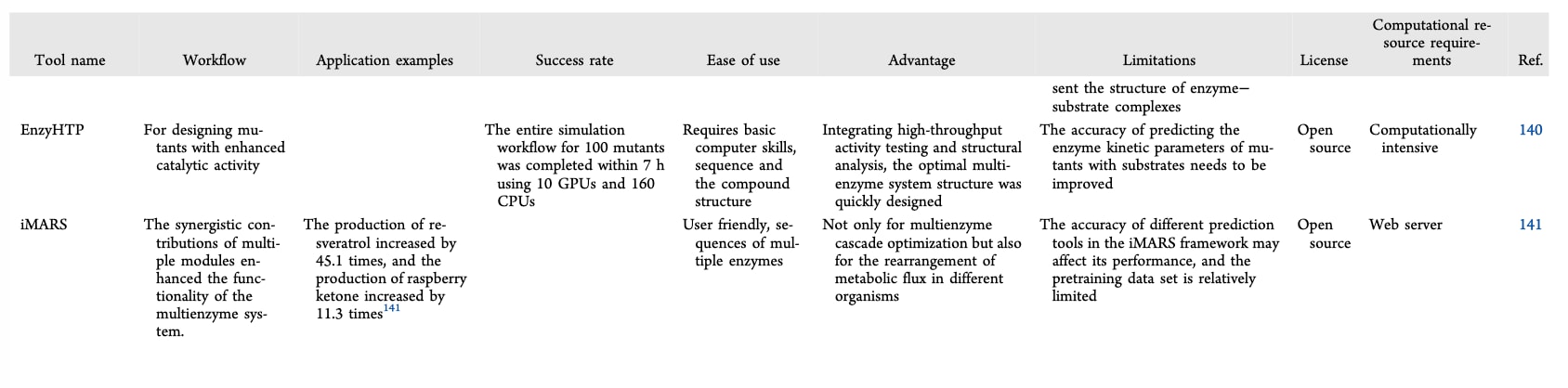
图7|酶催化活性工程策略的工作流程。 (A)关键催化活性位点。(B)底物结合口袋工程。(C)动力学与构象调控。(D)同源序列比对。(E)迭代优化与高通量筛选。(F)底物通道工程。
4.4 迭代优化
迭代突变策略是指在已获得有利突变体的基础上,连续引入多轮突变。该方法可逐步累积多种有利于活性提升的替换,从而获得催化性能显著增强的突变体。当与高通量筛选技术相结合时,该策略能够快速识别活性进一步优化的变体,并显著加快工程化改造周期,其整体流程如图6所示。Li等利用基于过渡态类似物引导的计算迭代饱和突变方法对酶活性位点进行工程改造,经过三轮优化获得了一个三突变体,其催化活性提高了29.3倍。该策略可同时优化酶的多种性质,如活性与稳定性。然而,该方法通常需要构建并筛选大量突变体文库,实验周期较长且资源投入较高,同时活性提升有时会伴随稳定性下降。为应对这一问题,未来可采用多种综合策略,包括利用DLKcat和CatPro等人工智能工具对设计的稳定性或底物选择性位点进行初步筛选,以识别同时提升活性与热稳定性的热点突变;在远离活性口袋的位置设计与热稳定性和底物选择性相关的突变位点,以降低对催化功能的干扰;以及系统性组合各自独立提升活性和稳定性的单点突变,构建在两方面性能均显著增强的组合变体。
4.5 底物通道
底物通道工程是一种理性蛋白质设计策略,旨在通过改造酶分子中的物质传输路径,优化底物向活性位点的定向输送并提高中间体转移效率。与底物结合口袋不同,底物进入通道作为专门的分子通路,负责引导配体进入催化中心。在天然酶中,底物进入往往依赖随机扩散,分子传输效率较低,从而限制反应速率。通过系统性优化底物通道结构,可实现底物的定向输送,显著降低扩散限制并提升催化效率。然而,该策略在实施过程中面临诸多挑战,成功设计需要将分子动力学模拟、深度学习预测等计算方法与实验验证相结合,以精确调控通道结构与功能。此外,为改变通道性质而进行的结构改造可能无意中削弱整体蛋白质稳定性,因此需在催化效率与结构完整性之间谨慎权衡。该策略的进一步发展有赖于结构生物学、生物信息学和化学工程等多学科的深度融合。
底物通道所形成的空间限制可防止底物在非目标位点发生非特异性反应,如异常氧化或分解,从而提高催化反应的区域选择性。细胞色素P450酶即为典型实例,其能够以高度特异性催化多种类固醇化合物的羟基化反应。在P450催化的二羟基化反应中,合成效率的主要限制来自单羟基化中间体在活性位点的积累,其根源在于底物和产物在通道中的传输效率不足,阻碍了中间体的及时释放并抑制后续氧化反应。通过对P450酶通道结构进行工程化改造,可有效缓解这一问题并提升整体催化性能。Deng等通过构建D182K/E143D/V178A三突变体,在P450酶中设计了一条新的产物出口通道,显著促进了中间体释放。研究表明,通道的尺寸、极性和空间位阻特性是提升催化效率的关键因素,为酶通路的理性设计提供了范例。此外,部分腈水合酶、蛋白酶、糖苷酶和醇脱氢酶也已通过底物通道工程成功实现了活性改造。
图8|酶底物选择性的工程化改造策略。 (A)关键残基设计。(B)计算工具引导的预测与优化。(C)结合高通量筛选的定向进化。(D)动态调控与构象工程。(E)结构域工程。(F)用于迭代优化的集成式DBTL框架。(G)底物通道优化。(H)辅因子结合位点工程。
4.6 动力学模拟
分子动力学模拟可通过在不同条件下对蛋白质构象变化进行建模,识别影响酶活性的关键残基或柔性区域,从而阐明酶-底物之间的构效关系。在实际应用中,通常先通过分子对接对高亲和力突变体进行初筛,再结合分子动力学模拟验证其稳定性,最终获得兼具高活性与高稳定性的突变体。将人工智能引入分子动力学模拟中,可构建“设计-模拟-学习-优化”的闭环体系。基于分子动力学轨迹,图神经网络可分析残基间的动态相关性和能量传递路径,从而识别由底物结合位点通向催化中心的关键信号通路。然而,分子动力学模拟在整合多尺度效应、刻画远端残基对活性位点的间接调控作用以及利用特定力场准确描述量子效应或弱相互作用方面仍存在局限。未来可将分子动力学与其他工程化策略相结合,实现更加全面而精确的酶理性重设计。
Yin等通过分子动力学模拟引导的定向进化策略,对黄素依赖型酶进行了工程改造。通过对来源于Parageobacillus thermantarcticus的黄素酶PtOYE进行结构优化,获得了高效变体ADes-5。该工程化催化剂相较于初始突变体PtOYE-Y28F,其催化效率(kcat/Km)提高了70倍以上,实现了1-芳基-2-四氢萘酮的轴选择性去饱和反应。此外,将该体系整合至动态动力学拆分过程中,成功高产率合成了非C2对称的双芳基轴手性分子,并表现出优异的对映选择性。
4.7 更多策略
研究人员正日益采用集成化计算工具体系开展酶催化活性工程研究。通过对动力学参数的预测,此类工具能够对突变体进行优先级排序筛选,从而显著缩小突变文库规模并降低实验工作量。如表5所示,多种关键计算资源已被广泛整合进酶优化流程。其中,Caver 2.0被广泛用于不同酶家族中底物通道的解析,可识别在几何结构上具有关键意义的残基,并对通道尺寸进行定量表征,包括表面积和体积等参数。
Zhao等利用Caver引导的突变策略,通过重新设计水通道对脂肪酸羟化酶进行了工程改造。将关键残基替换为体积更小或更具亲水性的氨基酸后,所得V456G变体的活性提高了13倍以上,而双突变体D266A/V456A和D266T/V456G的催化周转率较野生型提高了约15倍,充分展示了通道工程在增强催化性能方面的潜力。图7总结了酶工程中多种用于调控催化活性的策略。
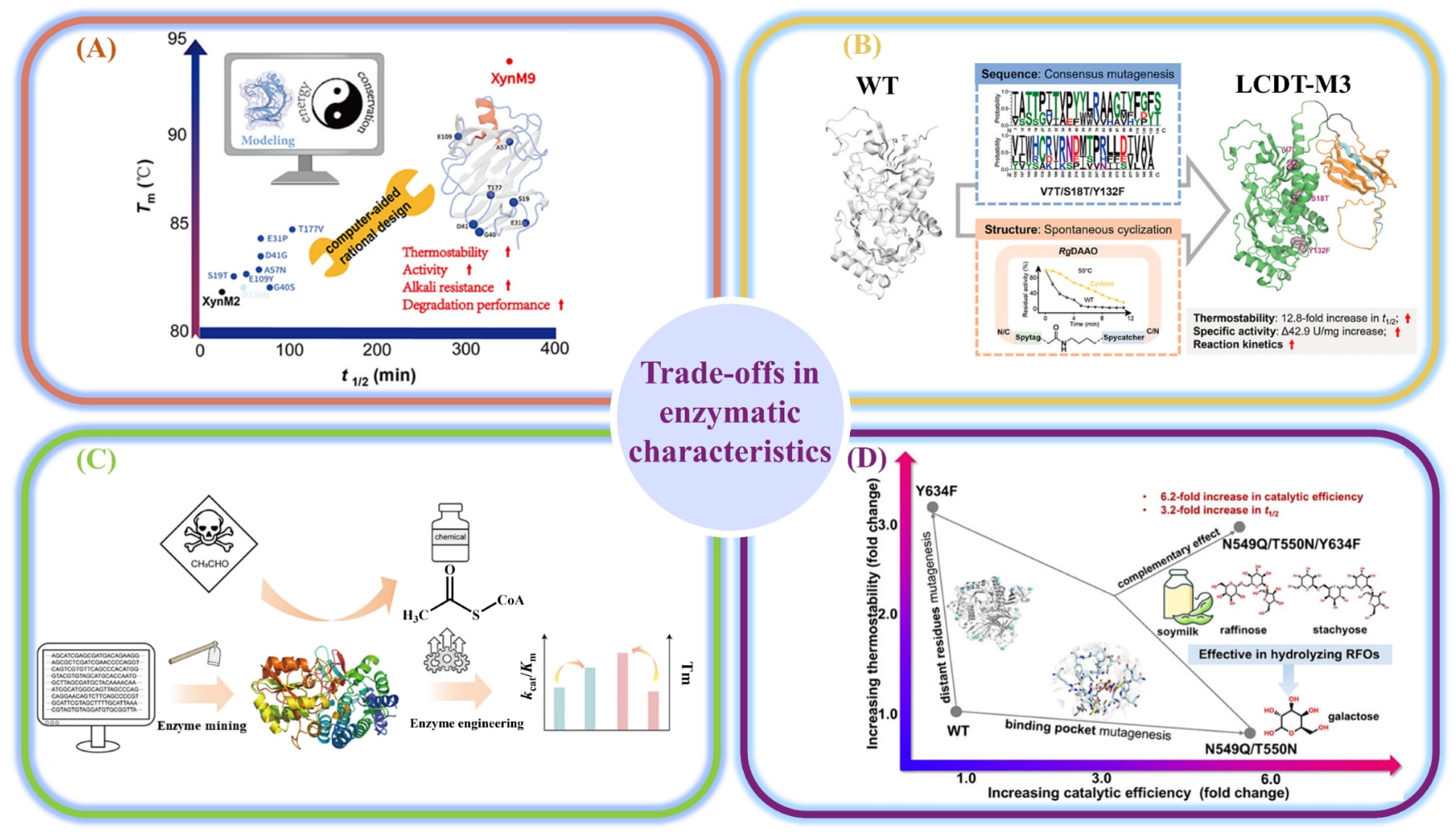
图9|不同酶学性质协同优化的权衡策略。 (A)通过结合折叠自由能分析与进化保守性分析,同步提升木聚糖酶的催化活性与热稳定性。(B)将共识序列设计与结构改造相结合,提高D-氨基酸氧化酶的热稳定性和催化效率。(C)对一种新型醛脱氢酶同时进行热稳定性与催化活性工程化改造。(D)通过选择性靶向并改造远端催化微环境与关键残基,提升α-半乳糖苷酶的催化活性与热稳定性。
5 蛋白质底物选择性的工程化改造策略
天然酶往往具有一定的催化宽容性,容易引发非期望的副反应,因此需要通过底物选择性工程来减少副产物生成。此外,工业生物过程常常要求酶催化非天然底物,而野生型酶固有的狭窄底物特异性在很大程度上限制了其实际应用。将酶的底物偏好重新定向至更具成本优势的原料,同时避免对宿主关键代谢物产生非特异性催化,是当前亟需解决的重要问题。底物选择性工程涉及底物结合口袋构型、活性中心几何结构、底物通道以及整体结构稳定性等多个维度的协同优化,因此面临较大挑战。目前该领域仍存在突变文库规模庞大、实验周期重复且催化结果不稳定等问题。人工智能模型通过学习酶序列、结构及催化效率数据之间的复杂映射关系,可实现对酶底物选择性的精准预测。随着人工智能预测精度的提升以及合成生物学工具的不断成熟,对酶选择性的精确调控有望推动生物制造从酶的直接利用迈向定制化生物催化剂设计,从而释放定向生物催化的全新潜力。图8概述了该领域中常见的工程化策略。
5.1 关键残基设计
酶底物选择性可通过对活性位点口袋几何结构的定向重塑来实现。典型策略包括引入体积较大的侧链残基,例如以Y或F替换G或A,构建更为狭窄的口袋以在空间上排斥较大底物;同时通过移除产生空间阻碍的残基,如将L突变为G,以扩展腔体容积从而容纳体积较大或支链化底物。该方法已成为重编程蛋白质底物特异性的经典范式。β折叠片通常一侧紧密堆积于蛋白质核心,另一侧则暴露于溶剂环境中。溶剂暴露残基对蛋白质稳定性具有重要贡献,其氨基酸偏好由局部主链构象及邻近残基类型共同决定。这种结构依赖性表明,β片层表面设计需要综合考虑多种能量因素,包括侧链构象偏好、范德华相互作用、静电贡献以及去溶剂化效应。在该策略中,人工智能可通过结合交叉注意力机制与三维结构信息,实现对酶-底物关系的精准预测。
环区在底物结合、引导底物进入活性位点以及介导构象转变过程中发挥着关键作用。Heinemann等通过改造异丙苯双加氧酶活性位点上方的环区结构,获得了具有新型底物通道的变体。这些突变产生了新的进入路径,使酶能够催化三种不同底物的全新反应,成功实现了底物特异性的重编程。然而,该方法也存在局限性。单个关键残基的改造通常只能实现底物选择性的微调,难以在两种截然不同的底物之间实现根本性转换。此外,底物偏好的改变可能引发活性位点几何结构或静电环境的细微变化,从而导致催化效率显著下降。未来研究可从单点突变转向针对突变网络的多位点组合突变,并通过将结构信息与序列比对数据相结合,先理性锁定目标区域,再在这些区域内进行随机或半随机突变并结合定向进化筛选,以获得性能最优的变体。
5.2 定向进化
当前用于重编程蛋白质底物选择性的定向进化策略仍高度依赖大规模突变文库的构建。高通量筛选技术在很大程度上缓解了文库评估所需的实验负担和时间成本。典型的高通量筛选平台包括基于吸光度和荧光信号的酶活性检测、用于单细胞分析的微流控液滴分选技术,以及针对细胞表面展示酶的荧光激活细胞分选。酵母内质网隔离筛选系统将蛋白酶工程与广谱底物分析相结合,在蛋白酶优化过程中实现了催化效率、灵敏度和动态范围的同步提升。借助该进化平台,工程化TEV蛋白酶变体eTEV的催化效率较其母体TEV-EAV提高了2.25倍,显著拓展了其在生物催化过程中的应用潜力。
5.3 动态与构象工程
在活性位点环区中引入或替换脯氨酸残基,可显著改变其构象动力学特性,从而调控底物结合行为。这一策略通过在稳定性与可进化性之间实现精细平衡,为酶功能优化提供了有效途径。对催化至关重要的环区参与底物引导、结合以及构象转换过程。PSIPRED、JPred和AlphaFold 2等计算工具可用于精确识别这些环区。底物选择性的重编程源于酶构象能量景观的重塑,凸显了结构适应性在功能可塑性中的核心作用。在此过程中,人工智能以已知变构位点作为训练数据,学习其结构-动力学特征,从而预测新蛋白中潜在的变构调控位点。
St-Jacques等通过计算手段重塑天冬氨酸转氨酶的构象能量景观,成功改变了其开放-闭合构象平衡。该多态构象设计策略获得的变体在底物选择性上实现了约1900倍的改变,并显著提高了对非天然底物的催化效率,显示出该方法在蛋白质选择性工程中的有效性。然而,酶结构本身的高度动态性使关键调控残基的识别与工程化面临困难,因为催化过程往往依赖跨结构域的协同运动。此外,传统设计方法多基于静态结构模型,在针对动态调控机制时存在明显局限。未来研究可将增强采样技术如Metadynamics与AlphaFold-Multimer等机器学习方法相结合,以识别关键动态残基并设计能够稳定目标构象状态的突变。
5.4 结构域替换
结构域替换是一种通过重组不同功能结构域来构建杂合酶的工程化方法,这些结构域包括底物识别区域、催化结构域以及变构调控模块。其中一种具有代表性的实现方式是结构域互换,即用来源于异源蛋白的类似结构域替换天然的底物识别模块。例如,在近期多项研究中,研究人员将融合标签引入辅助结构域中,以增强对特定底物的结合亲和力。该策略可实现对蛋白质底物选择性的精准重编程,但其成功实施依赖于完善的结构与功能数据支撑,因此需要实验流程与计算设计的紧密结合。未来的发展方向应聚焦于通过蛋白质结构解析与理性设计方法的协同应用,进一步提升工程化变体预测的准确性。Kraus等通过诱导结构域位移的定点突变,成功重编程了蔗糖磷酸化酶,使其能够接受白藜芦醇和槲皮素等体积较大的多酚类受体分子。重新设计的结合位点通过新的π-π堆叠和疏水相互作用得到稳定,从而实现了这些芳香底物的高效糖基化,展示了如何利用结构动力学调控来改变催化特异性。
5.5 辅因子结合位点
辅因子结合在决定酶底物选择性方面发挥着关键作用。通过对辅因子结合位点进行理性设计或定向进化,可以精确调控辅因子亲和力,优化其在底物通道中的空间匹配性,并对催化微环境进行精细调节,从而实现酶选择性的定制化增强。辅因子通常包括金属离子和辅酶,它们通过稳定过渡态并在催化循环中实现底物的精准定位,提高催化效率和特异性。在这一过程中,人工智能可利用图神经网络分析辅因子结合口袋结构,并结合FoldX等快速力场工具,大规模计算成千上万种虚拟突变对辅因子结合自由能变化ΔΔG的影响,从而高效筛选出既能稳定辅因子结合又不破坏整体结构完整性的突变方案。
Pan等通过突变辅因子结合位点中的T15和R16残基,对羟类固醇脱氢酶进行了工程化改造。所得变体T15A、R16A和R16Q的催化活性分别提高了7.85倍、2.50倍和4.35倍,并伴随底物偏好的改变,其性能提升源于氢键网络的重构以及催化三联体相互作用方式的调整。Ge等结合高通量筛选与人工智能方法,对伯克霍尔德菌脂肪酶进行了工程化改造,通过分析关键生物物理性质,识别出对对映选择性影响最大的残基L167,并成功实现了从S型到R型偏好的显著反转。然而,选择性增强往往会以催化活性下降为代价,可通过CAST策略同时优化多个残基以缓解这一问题。此外,合成辅因子常因空间位阻与天然酶结合口袋不匹配,可通过将体积较大的残基替换为甘氨酸等小残基来扩大腔体体积,从而引入更大的构象灵活性以适配非天然辅因子。
5.6 底物通道
作为关键结构要素,底物通道在酶的底物选择性和催化效率中起着重要作用。对通道内衬残基进行精确定点突变,可微调通道几何形态与疏水性,从而依据底物尺寸或化学性质实现选择性区分。将通道工程与活性位点重设计相结合,可实现对底物特异性的双重调控。常见策略包括引入疏水残基以促进芳香烃等非极性底物的选择性富集。然而,此类改造也可能干扰催化中心或远端功能区域。未来研究可借助深度学习模型评估底物与通道的相容性,并结合强化学习框架实现通道结构与化学特性的自主优化。人工智能可通过机器学习回归模型,基于分子模拟或实验数据提取的特征,预测突变对通道通透性的影响。此外,还可构建端到端深度学习模型,直接以野生型和突变体结构作为输入,输出目标底物与干扰底物之间的相对通透性评分。但需要注意的是,通道工程可能因改变底物扩散动力学而降低催化周转率。
Lu等通过重塑底物通道结构对苯甲酸脱羧酶进行了工程化改造。利用CAVER引导的分析设计了Q302Y/I303Y双突变体,该变体在保持对苯甲酸近乎100%活性的同时,将体积更大的肉桂酸转化率降低了90%以上,清晰展示了通过空间位阻效应重塑通道结构以实现底物选择性精准控制的可行性。
图9|不同酶学性质协同优化的权衡策略。 (A)通过结合折叠自由能分析与进化保守性分析,同步提升木聚糖酶的催化活性与热稳定性。(B)将共识序列设计与结构改造相结合,提高D-氨基酸氧化酶的热稳定性和催化效率。(C)对一种新型醛脱氢酶同时进行热稳定性与催化活性工程化改造。(D)通过选择性靶向并改造远端催化微环境与关键残基,提升α-半乳糖苷酶的催化活性与热稳定性。
6 不同酶学性质之间的优化权衡
酶工程中的一个根本性难题在于催化活性与稳定性之间反复出现的权衡关系。提高催化活性的改造往往会导致稳定性下降,而增强结构稳定性的策略又可能削弱酶功能。这种反向关系源于酶在结构与功能最优需求之间复杂且相互竞争的内在约束。实现最佳催化效率需要精细调控的结构柔性,以支持底物结合和过渡态稳定所必需的构象变化。然而,当柔性超出功能需求时,会破坏催化结构的稳定性,导致底物取向不合理及中间体稳定性下降,从而降低催化效率。另一方面,酶也需要足够的结构刚性以维持整体构架和功能完整性。刚性结构有助于在高温、非生理pH及有机溶剂等极端条件下保持稳定,但过度刚性会限制必要的构象变化,进而损害催化活性。因此,通过增加刚性来提升稳定性通常不可避免地伴随着催化效率的牺牲,其分子基础在蛋白质科学中仍未被完全阐明。
为在活性与稳定性之间取得平衡,常采用以下策略:一是对活性位点残基进行定向改造以提升催化性能;二是对远离活性中心的区域进行工程化改造以减少对功能的干扰;三是对柔性结构片段进行理性重设计,在不影响催化功能的前提下提高热稳定性。相关示意图如图9所示。Xu等通过结合深度学习与理性设计,构建了腺苷脱氨酶突变体P443C,其在热处理后残余活性提高了80.7%,底物转化率达到93.2%,成功实现了热稳定性与催化性能的同步提升。Zhao等采用半理性设计策略,获得了RrCuZnSOD的两个双突变体D25/A115T和A115T/S135P,在80 °C条件下的半衰期分别延长了1.2倍和1.6倍,熔解温度分别提高了3.4 °C和2.5 °C,同时完全保持了野生型水平的催化活性。
在实际酶工程中,常通过策略性调控结构动力学来实现性能平衡,例如增强活性位点周围的柔性以促进底物结合,同时提高核心区域或二级结构元件的刚性以改善热稳定性。此外,还可通过引入盐桥来增强结构完整性,并通过精心设计靠近催化口袋的柔性环区以维持催化效率。借助位点饱和突变,可系统性替换活性位点周围或其他关键结构区域的残基,评估其对活性和稳定性的单独贡献。在某些应用场景中,当稳定性的大幅提升能够弥补轻微的活性下降时,这种取舍往往是可以接受的。
7 高通量平台
对大规模酶突变文库进行充分覆盖筛选,需要构建专用的蛋白质工程平台。这类系统必须在保持基因型-表型关联的前提下,提供远高于传统微孔板方法的通量,从而显著降低突变筛选的时间和成本。酶工程中高通量筛选的示意流程如图10所示。基于特定酶类别的荧光活性检测方法,超高通量筛选策略已成功应用于酯酶、PET水解酶、羧化酶以及依赖NAD(P)的氧化还原酶等多类酶的鉴定与改造。常见的高通量筛选技术包括光学检测、流式细胞分选以及液滴微流控。
液滴微流控技术已成为改变酶工程实践的重要高通量工具。该技术将传统在试管或微孔板中进行的生化反应和分析转移至体积均一的微小液滴中,液滴体积通常处于皮升级至纳升级范围,每个液滴相当于一个微型反应器。Su等利用基于液滴的微流控筛选平台筛选耐热漆酶,该平台集成了加热模块和荧光激活液滴分选技术,从大规模漆酶突变文库中获得了12个热稳定性增强的变体,展示了该技术在发现远端有利突变方面的重要价值。然而,该方法也存在局限性,例如对液滴稳定性要求极高,必须在整个实验过程中保持液滴中试剂浓度一致,且不适用于长期细胞培养或细胞间相互作用的筛选。
近年来,荧光激活液滴分选技术迅速发展为一种强大的超高通量筛选平台,被广泛应用于酶、代谢物和抗体的筛选。其关键支撑技术在于高灵敏度的荧光耦联策略,将酶活性转化为可检测的荧光信号,从而实现目标分子的定量监测。荧光原底物分析是其中最常用的方法之一,该策略通过将荧光基团与猝灭基团共价连接抑制荧光,当底物被酶切割后猝灭基团释放,荧光恢复,信号强度与酶活性直接相关,从而实现定量筛选。Agresti等在液滴微流控系统中使用商业化底物Amplex Red,对辣根过氧化物酶进行了十个群体的定向进化筛选,获得的变体其催化效率较野生型提高了10倍,kcat/Km达到2.5 × 10^7 M^−1·s^−1,接近理论扩散极限。
基于微流控装置生成的单分散液滴进行单细胞筛选,已成为识别高性能酶变体的有效超高通量策略。通过将单个细胞封装在液滴中,可限制胞外目标分子的扩散,从而高效维持表型与基因型的对应关系,在显著降低筛选时间和成本的同时,实现对大规模文库中优良突变体的快速富集。然而,该技术仍面临一些挑战,包括多组分液滴在反应启动过程中的精确融合控制,以及防止不同隔室之间发生交叉污染。未来可通过调控底物疏水性实现荧光信号在液滴内的空间限制,从而实现对反应启动和检测过程的精确时空控制。
8 理性蛋白质工程的发展趋势
理性蛋白质工程已发展为连接合成生物学与结构生物学的核心研究领域,其发展轨迹正由早期的单一功能优化,逐步迈向更加智能化、动态化和多功能化的蛋白质体系。机器学习与蛋白质设计方法的深度融合,有望从根本上加速酶工程领域的创新进程。未来,人工智能引导的理性工程策略预计将沿多条并行路径演进,推动新一代生物催化剂的开发。
首先,人工智能与机器学习的深度融合将成为酶工程发展的关键。目前多数预测模型仍侧重于分析静态的蛋白质-配体对接构象,未来应更加重视对配体结合前后动态构象变化的模拟。同时,提升酶序列-功能预测的准确性对于减少对实验试错的依赖至关重要,有助于显著简化设计流程。其次,自动化与高通量实验平台的广泛应用将极大推动酶工程的发展。将高通量筛选技术与自动化工作站相结合,可加速“设计-构建-测试-学习”循环,并实现突变文库的快速筛选。未来研究应重点发展针对酶热稳定性、底物选择性和催化活性评价的专用高通量方法。再次,系统性扩展多样化酶学性质的实验数据库也是未来的重要方向。将酶动力学参数数据库与蛋白质语言模型相结合,有望开发用于预测酶动力学性质的专用人工智能工具,从而显著提升预测精度并降低突变文库规模及筛选负担。
9 总结和展望
不断演进的蛋白质工程策略正在实现对多种蛋白酶学性质的理性调控,推动其在多个领域中的应用拓展。在食品加工领域,该技术可用于特定风味肽的精准制备、食品质构改善、货架期延长、微生物生长抑制以及食品污染物和毒素的高效降解。在环境生物修复中,其可实现多种塑料废弃物的高效解聚以及工业废水中特定污染物的降解。在生物基材料生产过程中,农业副产物可被转化为高附加值材料,实现生物基材料的闭环循环利用。
然而,人工智能在酶工程中的应用仍面临多项挑战,限制了其更广泛的实际推广。人工神经网络中隐含层神经元数量是影响模型性能的关键因素,数量不足会导致欠拟合,而数量过多则因模型复杂度增加而引发过拟合。具有特定功能的蛋白质序列的可控生成仍然存在技术难题。此外,蛋白质语言模型在数据获取和建模方面仍面临挑战,尤其是在多底物酶的功能数据收集和进化分析方面。未来研究将致力于开发更加易用且成本更低的蛋白质工程工具,以支持更复杂蛋白质的设计,并探索引入非天然氨基酸的新型化学结构。人工智能辅助的酶工程改造将进一步推动酶设计和多功能酶制剂的发展,从而促进食品工业和绿色化学领域的技术升级与可持续发展。